每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

屏幕用户界面(UI)和信息图表,例如图表、图解和表格,在人类沟通和人机交互中发挥着重要作用,因为它们促进了丰富和互动的用户体验。用户界面和信息图表共享类似的设计原则和视觉语言(例如,图标和布局),这提供了建立单一模型的机会,该模型能够理解、推理并与这些界面交互。然而,由于它们的复杂性和多样的呈现格式,信息图表和用户界面呈现了一个独特的建模挑战。
为了应对这一挑战,研究者们介绍了“ScreenAI:一个用于用户界面和信息图表理解的视觉-语言模型”。ScreenAI在PaLI架构的基础上进行了改进,采用了pix2struct中引入的灵活打补丁策略。研究者们在包括一项新颖的屏幕注释任务在内的独特数据集和任务组合上训练了ScreenAI,该任务要求模型识别屏幕上的用户界面元素信息(即,类型、位置和描述)。这些文本注释为大型语言模型(LLMs)提供了屏幕描述,使它们能够自动生成问答(QA)、用户界面导航和摘要训练数据集。仅在5亿参数的情况下,ScreenAI就在基于用户界面和信息图表的任务(WebSRC和MoTIF)上达到了最先进的结果,并且在与相似大小的模型相比,在Chart QA、DocVQA和InfographicVQA上表现最佳。研究者们还发布了三个新的数据集:Screen Annotation,用于评估模型的布局理解能力,以及ScreenQA Short和Complex ScreenQA,用于更全面地评估其问答能力。
ScreenAI的架构基于PaLI,包含一个多模态编码器块和一个自回归解码器。PaLI编码器使用视觉变换器(ViT)创建图像嵌入,并且多模态编码器将图像和文本嵌入的连接作为输入。这种灵活的架构使ScreenAI能够解决可以重新构想为文本加图像到文本问题的视觉任务。
在PaLI架构之上,研究者们采用了pix2struct中引入的灵活打补丁策略。不使用固定的网格模式,而是选择网格尺寸以保留输入图像的原生宽高比。这使ScreenAI能够很好地适应各种宽高比的图像。
ScreenAI模型在两个阶段进行训练:预训练阶段和微调阶段。首先,自监督学习被应用于自动生成数据标签,然后使用这些标签来训练视觉变换器和语言模型。在微调阶段,视觉变换器被冻结,大多数使用的数据是由人类评估员手动标记的。
为了为ScreenAI创建一个预训练数据集,研究者们首先编译了来自各种设备(包括桌面、移动和平板电脑)的大量屏幕截图。这是通过使用公开可访问的网页和遵循用于移动应用的RICO数据集的程序化探索方法来实现的。然后他们应用一个基于DETR模型的布局注释器,它能识别和标记广泛的用户界面元素(例如图像、图示、按钮、文本)及其空间关系。图示进一步使用一个能够区分77种不同图标类型的图标分类器进行分析。这种详细的分类对于解释通过图标传达的细微信息至关重要。对于未被分类器覆盖的图标,以及信息图表和图像,研究者们使用PaLI图像标题生成模型来生成描述性标题,提供上下文信息。他们还应用光学字符识别(OCR)引擎来提取和注释屏幕上的文本内容。研究者们将OCR文本与前述注释结合起来,创建了每个屏幕的详细描述。
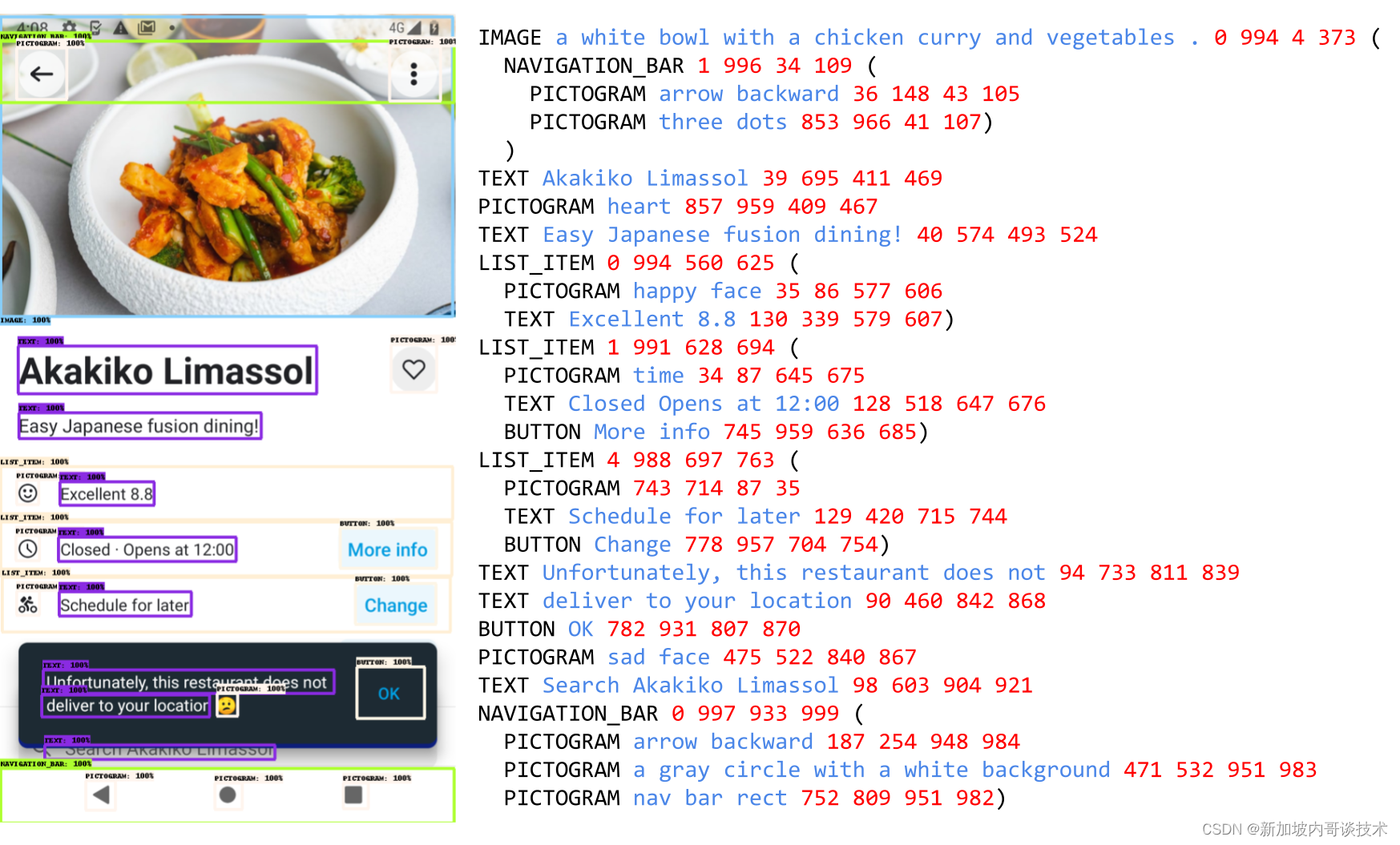
通过使用PaLM 2增强预训练数据的多样性,研究者们在两步过程中生成输入-输出对。首先,使用上述技术生成屏幕注释,然后他们围绕这个架构为大型语言模型创建一个提示,以生成合成数据。这个过程需要提示工程和迭代细化来找到有效的提示。研究者们通过人类验证对生成数据的质量进行评估,以达到一个质量阈值。
ScreenAI在两个阶段进行训练:预训练和微调。预训练数据标签是通过自监督学习获得的,而微调数据标签来自人类评估员。
You only speak JSON. Do not write text that isn’t JSON.
You are given the following mobile screenshot, described in words. Can you generate 5 questions regarding the content of the screenshot as well as the corresponding short answers to them? The answer should be as short as possible, containing only the necessary information. Your answer should be structured as follows:
questions: [
{{question: the question,answer: the answer
}},...
]{THE SCREEN SCHEMA}研究者们使用公开的问答、摘要和导航数据集对ScreenAI进行微调,并使用与用户界面相关的多种任务。对于问答,他们使用多模态和文档理解领域中建立良好的基准,如ChartQA、DocVQA、多页DocVQA、InfographicVQA、OCR VQA、Web SRC和ScreenQA。对于导航,使用的数据集包括Referring Expressions、MoTIF、Mug和Android in the Wild。最后,他们使用Screen2Words进行屏幕摘要,使用Widget Captioning描述特定用户界面元素。除了微调数据集,研究者们还使用三个新的基准测试来评估微调后的ScreenAI模型:
- Screen Annotation:用于评估模型的布局注释和空间理解能力。
- ScreenQA Short:ScreenQA的一个变体,其真实答案已缩短,仅包含与其他问答任务更一致的相关信息。
- Complex ScreenQA:与ScreenQA Short相辅相成,包含更难的问题(计数、算术、比较和无法回答的问题),并包含具有各种宽高比的屏幕。


微调后的ScreenAI模型在各种基于用户界面和信息图表的任务(WebSRC和MoTIF)上达到了最先进的结果,并且与相似大小的模型相比,在Chart QA、DocVQA和InfographicVQA上表现最佳。ScreenAI在Screen2Words和OCR-VQA上也表现出竞争力。此外,研究者们还报告了在新引入的基准数据集上的结果,作为进一步研究的基线。

研究者们介绍了ScreenAI模型以及一个统一的表示,使他们能够开发利用所有这些领域数据的自监督学习任务。他们还展示了使用大型语言模型进行数据生成的影响,并探讨了通过修改训练混合来提高模型在特定方面的表现。他们将所有这些技术应用于构建多任务训练模型,与公开基准上的最先进方法相比,这些模型表现出竞争力。然而,研究者们也
注意到,尽管他们的方法与公开基准上的最先进方法相比显示出竞争力,但与大型模型相比仍有差距。他们强调,需要进一步的研究来弥合这一差距,并探索新的策略和技术以提升模型性能。
研究者们的工作不仅展示了ScreenAI模型在用户界面和信息图表理解方面的潜力,而且还为未来的研究提供了一个坚实的基础。通过发布新的数据集和展示通过大型语言模型生成数据的能力,他们为解决复杂的人机交互问题开辟了新途径。
此外,ScreenAI模型的开发揭示了跨领域融合的重要性,即将计算机视觉、自然语言处理和人机交互的最新进展结合起来,以解决长期存在的挑战。这种跨学科的方法不仅促进了技术进步,也为研究社区提供了丰富的资源,包括数据集、模型架构和训练策略,这些都是推动未来创新的关键因素。
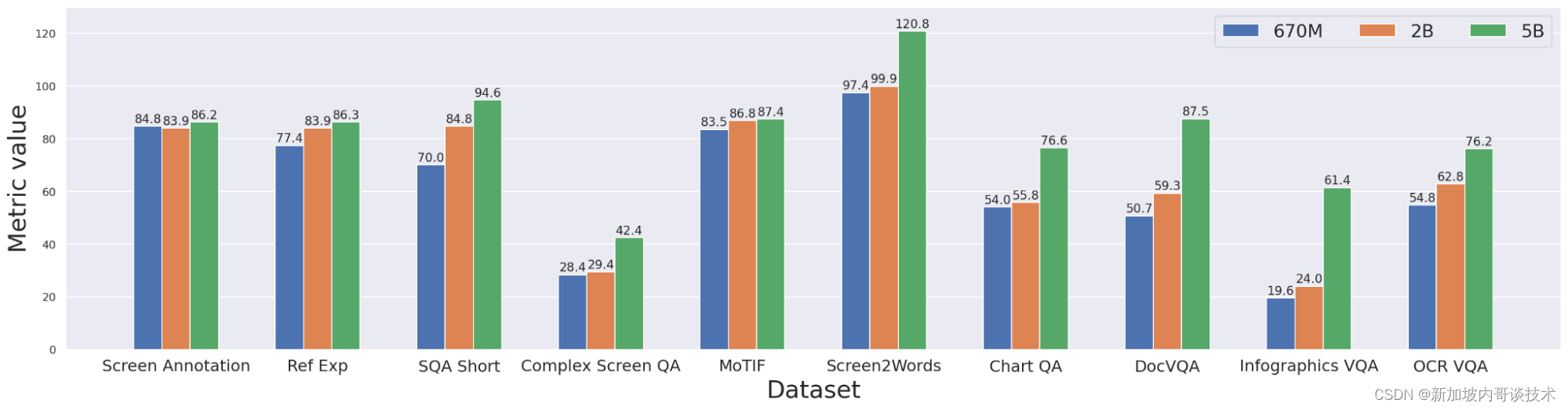
总之,ScreenAI项目标志着在理解和互动与日益复杂的数字界面方面的重要一步。随着技术的不断进步,期待未来的研究能够继续探索这一领域的潜力,解锁更多的应用场景,从而更好地服务于人类与机器的交互。

介绍)






)





![[Halcon学习笔记]在Qt上实现Halcon窗口的字体设置颜色设置等功能](http://pic.xiahunao.cn/[Halcon学习笔记]在Qt上实现Halcon窗口的字体设置颜色设置等功能)
)



