一、HAProxy基础知识
(一)HAProxy概述
HAProxy是一款基于事件驱动、单进程模型设计的四层与七层负载均衡器,它能够在TCP/UDP层面以及HTTP(S)等应用层协议上实现高效的流量分发。HAProxy不仅适用于Web服务器负载均衡,还能应用于数据库、邮件服务器、缓存服务器等多种场景,支持高达数百万级别的并发连接,并具有极低的延迟。
(二)核心特性
高性能负载均衡: HAProxy通过优化的事件驱动引擎,能够以最小的系统资源开销处理大量并发请求。它支持多种负载均衡算法,如轮询、最少连接、源IP哈希等,可根据实际业务需求灵活配置。
健康检查与故障恢复: HAProxy具备完善的后端服务器健康检查机制,可以根据响应时间、错误率等因素自动剔除不健康的后端节点,并在节点恢复时重新将其加入到服务池中,确保服务连续性。
会话保持与亲和性: 为了保证用户的会话一致性,HAProxy支持基于cookie或源IP地址的会话保持功能,确保同一客户端的请求被转发到同一台后端服务器进行处理。
安全性与SSL卸载: HAProxy支持SSL/TLS加密传输,可对HTTPS流量进行解密并透明地分发至后端服务器,同时也能终止SSL连接以减轻服务器的加密计算压力。
高级路由与策略: 根据HTTP请求头、URL路径、内容类型等条件,HAProxy可以执行复杂的路由规则和ACL策略,使得负载均衡更加智能化和精准化。
日志记录与监控: HAProxy提供丰富的日志记录选项,可通过syslog、CSV格式输出等方式收集统计数据,便于运维人员实时监控系统状态和性能指标
(三)支持调度算法
官方文档:HAProxy version 2.4.15 - Configuration Manual
静态调度算法:不管后端,按照调度器的算法进行 分配
动态调度算法:会考虑后端服务器的负载情况
(1) roundrobin,表示简单的轮询 rr
(2) static-rr,表示根据权重
(3) leastconn,表示最少连接者先处理
( 4) source,表示根据请求源IP
(5) uri,表示根据请求的URI,做cdn需使用;
(6) url param,表示根据请求的URl参数' balance url param’requires an URL parameter name
(7) hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;
(8) rdp-cookie (name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
二、安装haproxy
(一)下载源码包
本地yum源的版本比较老旧,可以从官方下载较新版本的源码包进行编译安装
官方链接:HAProxy - The Reliable, High Perf. TCP/HTTP Load Balancer
将源码包解压后,可以看到,与之前的nginx、php等编译安装不同,它没有configure执行文件
configuse执行文件主要生成的是Makefile文件,解压完源码包后就已经生成了该文件。

可以查看INSTALL文件,查看如何安装

make clean
#清除之前编译过程中产生的目标文件和临时文件,确保从一个干净的状态开始新的编译过程。
make -j $(nproc) TARGET=linux-glibc USE_OPENSSL=1 USE_LUA=1 USE_PCRE=1 USE_SYSTEMD=1
-j $(nproc)
#使用系统的逻辑处理器数量同时进行编译,以加快编译速度。
TARGET=linux-glibc
#指定目标平台为基于glibc的Linux系统。
USE_OPENSSL=1
#启用OpenSSL库支持,使得软件可以利用OpenSSL提供的加密和安全功能。
USE_LUA=1
#启用Lua脚本语言支持,允许在软件中编写和运行Lua脚本来扩展功能。
USE_PCRE=1
#启用PCRE(Perl Compatible Regular Expressions)库支持,提供强大的正则表达式处理能力。
USE_SYSTEMD=1
#启用Systemd支持,使软件能够更好地与Systemd初始化系统集成,例如注册systemd服务等。
sudo make install
#完成编译后,使用管理员权限执行此命令将编译好的软件安装到系统预设的安装路径下。
在安装之前,需要解决依赖环境的问题
(二)解决依赖环境
1.安装编译环境
yum -y install gcc openssl-devel pcre-devel systemd-devel

由于CentOS7 之前版本自带的lua版本比较低并不符合HAProxy要求的lua最低版本(5.3)的要求,因此需要编译安装较新版本的lua环境,然后才能编译安装HAProxy

下载方法在官方文档:Lua: download

2.安装LUA

(三)编译安装
make ARCH=x86_64
#指定要构建的目标处理器架构为x86_64,即适用于64位Intel/AMD处理器的版本。
TARGET=linux-glibc
#设置目标平台为基于glibc的Linux系统,glibc是Linux系统中最常用的C语言标准库实现。
USE_PCRE=1
#启用PCRE支持,这将允许软件使用复杂的正则表达式进行匹配和处理。
USE_OPENSSL=1
#启用OpenSSL支持,提供加密算法、SSL/TLS协议等功能。
USE_ZLIB=1
#启用Zlib支持,用于数据压缩和解压缩功能。
USE_SYSTEMD=1
#启用Systemd支持
USE_LUA=1
#启用Lua脚本语言支持,允许在软件中编写和运行Lua脚本来扩展功能。
LUA_INC=/usr/local/lua/src/
#指定Lua头文件目录,编译时需要用到这些头文件来链接到Lua库。
LUA_LIB=/usr/local/lua/src/
#指定Lua库文件目录,编译时会链接到这个目录下的库文件以支持Lua功能

(四)配置system管理文件
需要在/usr/lib/systemd/system/目录下建立管理文件
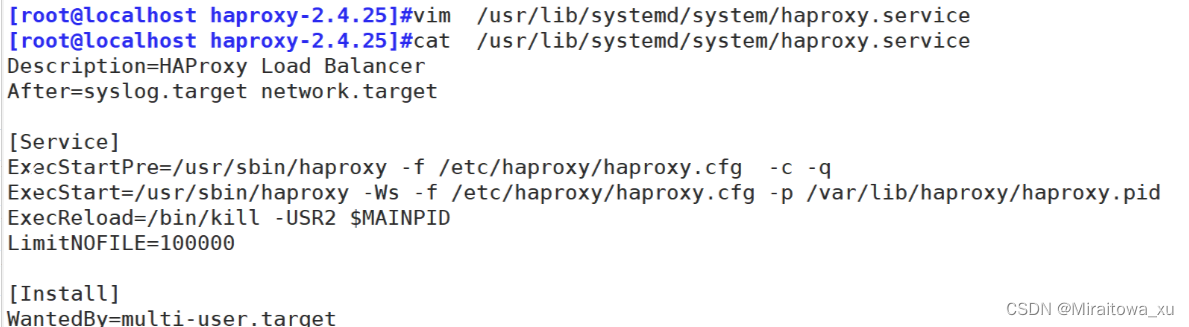
Description=HAProxy Load Balancer
#这一行定义了服务的简要描述,说明该服务是用于提供负载均衡功能的HAProxy
After=syslog.target network.target
#表示此服务在syslog日志系统和网络服务完全启动之后开始启动。
[Service] #服务部分包含了与服务运行相关的各种设置。
ExecStartPre=/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -c -q
#指定服务启动前执行haproxy命令。表示启动HAProxy前检查配置文件/etc/haproxy/haproxy.cfg
#是否有效,-c表示仅检查配置文件,-q表示静默模式,不输出多余信息。
#该文件需要手动建立并配置信息。
'具体信息在下一目录介绍'
ExecStart=/usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /var/lib/haproxy/haproxy.pid
#执行haproxy命令,并指定配置文件路径为 /etc/haproxy/haproxy.cfg,
#-Ws:表示以守护进程模式运行并打开Unix套接字以便进行管理操作,
#同时将PID写到/var/lib/haproxy/haproxy.pid 文件中。该文件也需要手动创建
ExecReload=/bin/kill -USR2 $MAINPID
#设置当服务收到reload信号时需要执行的操作,这里是发送USR2信号给主进程($MAINPID),
#使得haproxy能够平滑重载配置文件而无需停止服务。
LimitNOFILE=100000
#服务的最大打开文件数量限制为100000
[Install]
#安装部分定义了如何将此服务与系统的启动目标关联
WantedBy=multi-user.target
#表明该服务应随多用户目标启动,即在系统进入多用户模式时自动启动haproxy服务
建立system管理时需要加载的文件,及相关配置信息 建立完毕后,启动服务:systemctl enable --now haproxy
建立完毕后,启动服务:systemctl enable --now haproxy

(五)配置文件介绍
编译安装完毕后。它的默认配置文件位置是源码包目录下的examples/option-http_proxy.cfg文件

而在system管理文件中并没有加载此目录,而是指向了/etc/haproxy/haproxy.cfg,新建的文件,便于自定义信息。
1.全局设置(global)
global #全局,表示该段信息为全局配置
maxconn 100000 #置全局的最大并发连接数为100000
chroot /usr/local/haproxy
#使运行中的haproxy进程被限制在/usr/local/haproxy目录下,以增强安全性。stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin
#创建一个Unix套接字用于本地管理统计信息,权限为0600,只允许管理员访问。uid 99 gid 99 #设置HAProxy进程运行时的用户ID和组ID
daemon #使haproxy以守护进程模式运行于后台。
pidfile /var/lib/haproxy/haproxy.pid
log 127.0.0.1 local3 info
#定义日志记录,将日志信息发送到本地IP地址127.0.0.1,并使用syslog标识符local3,
#记录级别为info以上的日志信息2.默认参数(defaults)
defaults #定义默认的参数设置
option http-keep-alive #用HTTP长连接支持
option forwardfor #开启X-Forwarded-For头部的插入
maxconn 100000 #设置每个frontend或backend的最大并发连接数为100000
mode http #指定默认的模式为HTTP
timeout connect 300000ms #设置建立连接超时时间为300秒
timeout client 300000ms #设置客户端超时时间也为300秒
timeout server 300000ms #置后端服务器超时时间同样为300秒3.监听设置(listen)
listen stats #监听范围mode http #设置监听器的工作模式为HTTP。bind 0.0.0.0:9999 #将监听器绑定到所有网络接口的9999端口,用于接收外部请求。stats enable #启用统计信息收集和展示功能,允许通过HTTP访问查看自身状态信息log global #使用全局日志设置记录与该监听器相关的活动stats uri /status #设置访问统计信息页面的URI路径为/status。stats auth hauser:123456
#配置基本的HTTP身份验证,用户名为 hauser密码为 123456
#这意味着只有知道此凭据的用户才能访问统计信息。listen web_portbind 0.0.0.0:8899 #创建另一个监听器并将其绑定到所有网络接口的8899端口,对外提供服务mode http #设置该监听器也以HTTP模式工作。log global #使用全局日志设置记录与该监听器相关的活动三、haproxy调优
(一)进程
服务启动以后,可以看到默认开启一个主进程,带一个工作进程以及三个线程

可以根据cpu个数来决定开机时启动的work进程数量:在全局配置中添加nbproc参数
nbproc n #开启的haproxy work 进程数,默认进程数是一个
 重启之后打开的工作进
重启之后打开的工作进
(二)cpu亲缘性
CPU亲缘性(CPU Affinity)是指将进程或线程绑定到特定的CPU核心上运行的技术。通过设置CPU亲缘性,可以避免进程在不同核心之间频繁迁移,从而减少缓存失效、上下文切换等开销,提高系统的整体性能和效率
程就是设置的数量

通过添加cpu-map参数将工作进程与cpu绑定:cpu-map n(work) n(cpu)
重启服务后可以看到工作进程与CPU进行了绑定

这样设置后,haproxy的工作进程将会在指定的核心上运行,有利于优化并行处理能力和减少资源竞争。使得每个进程都在固定的核心上执行,有助于提升数据包处理的稳定性和一致性,尤其在多核处理器环境中更为重要。当然,实际应用时需要根据具体的硬件环境和负载情况合理配置CPU亲缘性。
(三)状态页
可以通过http服务来查看状态页,在写配置文件时就已经添加好了

使用浏览器访问并登录
可以看到服务的一些状态信息,所以需要妥善保管密码

(四)日志管理
1.本地日志
haproxy服务没有单独的日志管理文件,它的默认日志文件位置在/var/log/messages
由于该文件的日志信息相对比较重要,建议单独存放
在配置文件的第14行已经定义的日志的格式,只需要在rsyslog日志管理的配置文件中指定信息即可
取消/etc/rsyslog.conf文件中的15,16行的注释信息

$ModLoad imudp: 这是在rsyslog配置文件中加载UDP模块的命令。imudp表示输入模块(Input Module)用于处理UDP协议的数据。通过此命令,系统将能够监听并接收通过UDP端口发送过来的日志消息。
$UDPServerRun 514: 这个指令告诉rsyslog服务在指定的UDP端口(这里为514)上启动一个UDP服务器以监听日志事件。默认情况下,许多网络设备和服务会使用514端口通过UDP协议发送syslog日志信息给日志收集服务器
在第74行添加日志配置

修改完毕后,重启服务:systemctl restart haproxy.service rsyslog.service

重启完毕后,会在/var/log/目录下自动生成日志文件

2.远端日志
由于haproxy服务只能做代理服务,对资源消耗较大,建议将日志文件放在远程的日志文件服务器上,专门建立日志文件查看
在haproxy服务的配置文件中,首先定义日志的标识符及信息

修改完毕后重启服务:systemctl restart haproxy.service
在远端服务器上设置同样修改rsyslog日志管理服务的配置文件

有访问时,日志就会记录在该文件中,想要把只记录在远端服务去,只需要把haproxy服务器中的日志配置删除即可

四、Proxies配置
Proxies"配置通常是指对网络流量进行负载均衡和管理的代理设置。具体选项有以下几种:
defaults [<name>]
#默认配置项,针对以下的frontend、backend和listen生效,可以多个name也可以没有name
frontend <name>#前端servername,类似于Nginx的一个虚拟主机 server和LVS服务集群。frontend是haproxy接收客户端请求的地方,它定义了对外暴露的服务端口、协议以及处理请求的方式。
backend <name>#后端服务器组,等于nginx的upstream和LVS中的RS服务器
#Backend包含了实际提供服务的一组服务器,haproxy会根据预设的负载均衡算法将来自前#端的请求分发到这些后端服务器上。
listen <name>
#将frontend和backend合并在一起配置,相对于frontend和backend配置更简洁,生产常用
(一)defaults配置
defaults配置基本为一些调优选项
option redispatch
#当server Id对应的服务器挂掉后,强制定向到其他健康的服务器,重新派发
option abortonclose#当服务器负载很高时,自动结束掉当前队列处理比较久的连接,针对业务情况选择开启
option http-keep-alive #开启与客户端的会话保持
option forwardfor #透传客户端真实IP至后端web服务器
mode http|tcp #设置默认工作类型,使用TCP服务器性能更好,减少压力
timeout http-keep-alive 120s#session 会话保持超时时间,此时间段内会转发到相同的后端服务器
timeout connect 120s#客户端请求从haproxy到后端server最长连接等待时间(TCP连接之前),默认单位ms
timeout server 600s#客户端请求从haproxy到后端服务端的请求处理超时时长(TCP连接之后),默认单位ms,如#果超时,会出现502错误,此值建议设置较大些,访止502错误
timeout client 600s#设置haproxy与客户端的最长非活动时间,默认单位ms,建议和timeout server相同
timeout check 5s #对后端服务器的默认检测超时时间
default-server inter 1000 weight 3 #指定后端服务器的默认设置
(二)frontend与backend
1.基本服务
frontend与backend定义了haproxy服务的反向代理与负载均衡
在配置文件中添加frontend与backend语句块
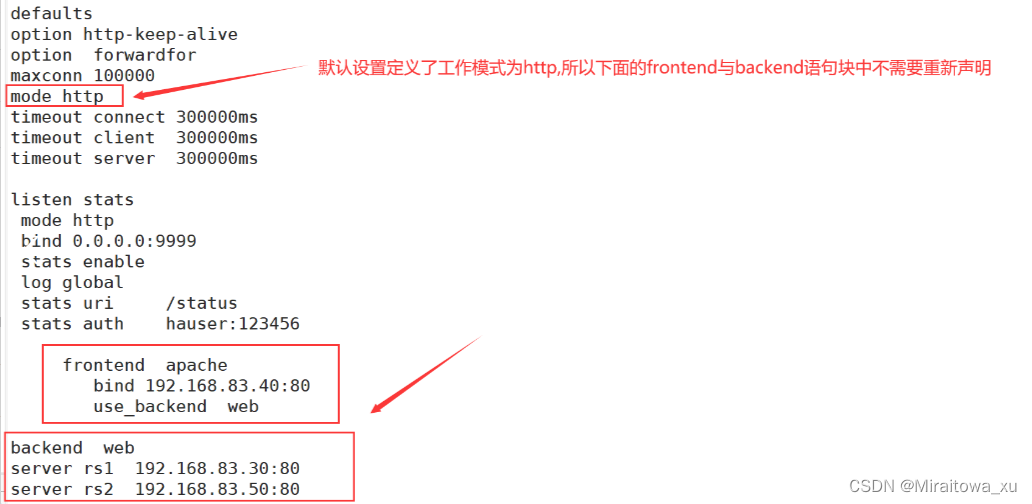
frontend
#定义了一个名为 "apache" 的前端代理,它监听来自客户端的请求。
bind 192.168.83.40:80
#表示该前端代理将绑定到IP地址为 192.168.83.40 的服务器上的80端口,对外提供HTTP服务。
use_backend web
#指定当接收到请求时,应将请求转发到名称为 "web" 的后端集群进行处理。
backend web
#定义了一个名为 "web" 的后端集群
server rs1 192.168.83.30:80 和 server rs2 192.168.83.50:80
#分别定义了两台后端服务器。其中,rs1 对应的实际服务器IP地址是 192.168.83.30,
#并且在该服务器上运行的服务也监听80端口;同样地,rs2 对应的服务器IP地址是 192.168.83.50。
修改完毕后重启服务:systemctl restart haproxy.servic
开服后端服务器
使用客户端进行访问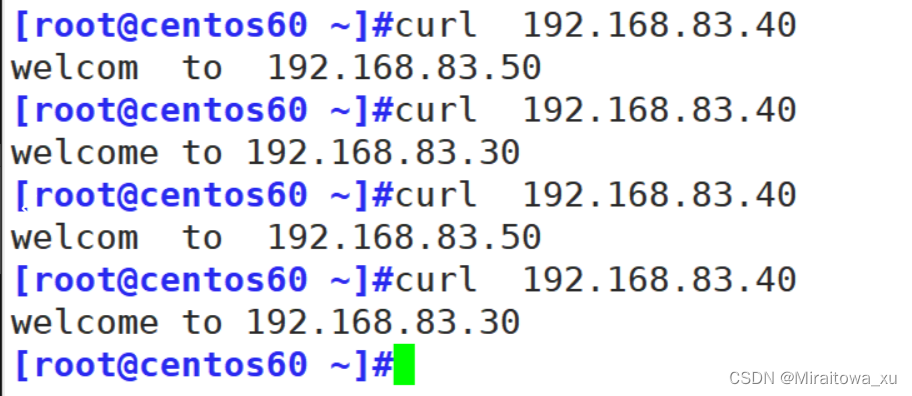
)


)










)

-- 详解)

)
)