文章结尾有视频和连接
背景知识
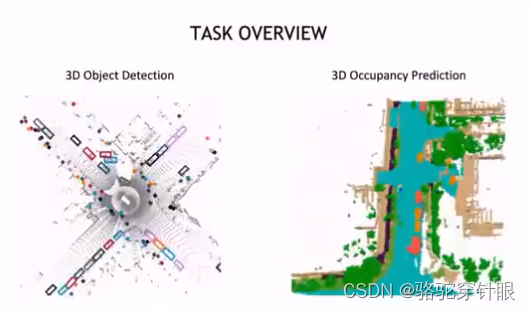
Occupancy 更像是一个语义分割任务,但是它是 3D 空间的语义分割它的我们对 Occupancy 分自己的期望是它能够具有通用的这种目标建模的能力,才能够不是不受制于这种目标框这种几何的矩形的这种约束而能够建模任意形状的这种物体,或者这种其他类别。

(1) LiDAR 方法
(2)RGB-D 方法
(3)相机方法
只用前两种方案,因为它们有深度信息,它们整体的这个难度会更小一点,因为对于 3D 场景建模最大的挑战其实就是对于精确的几何信息的建模,然后这个正是这个摄像头所缺失的,所以只依赖于相机来进行Occupancy问题的重建,其实是最大的这个挑战。
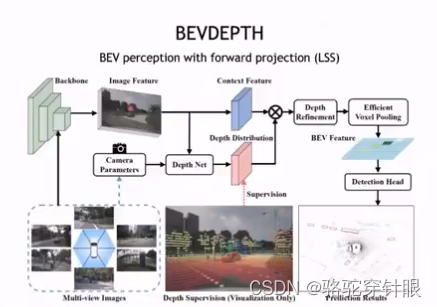
forward project 方案
基于就是指依据图像的是每个 Pixel 的深度,然后将依靠深度把 Pixel 从 2D 空间投影到 3D 空间,因为我们把这个看作是一个forward的过程。
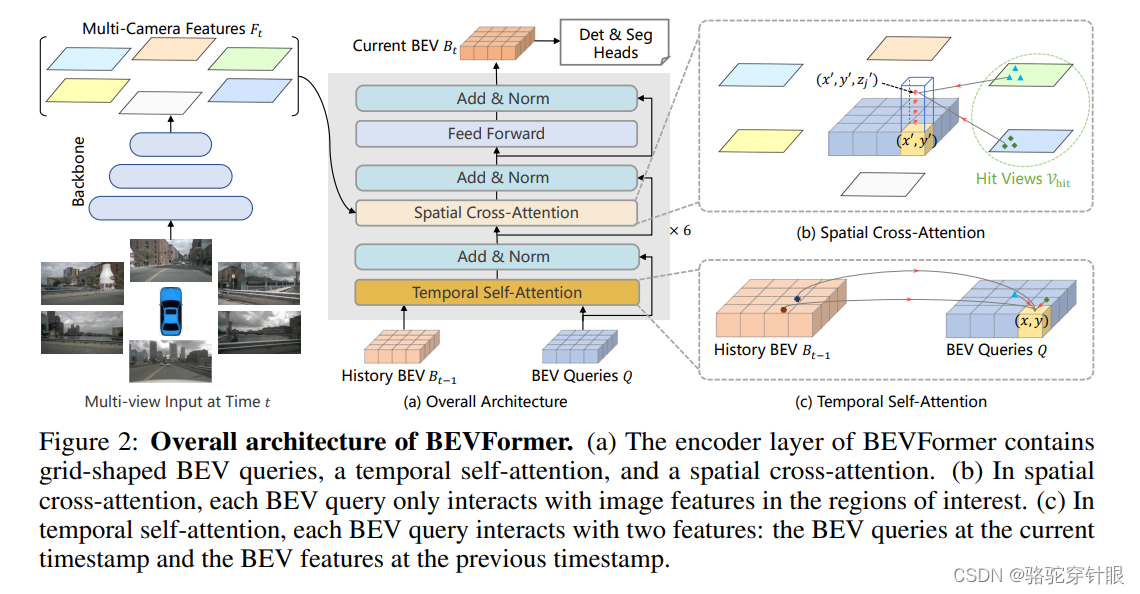
backward projection 方案
从 3D 空间出发,我们从既定好的3D 空间上点依靠相机参数投运回 2D 空间,相当于是一个查询的过程。这样从 3D 到 2D 的过程我们叫做 backward protection,然后它的优点在于它能够以任意精度和任意稠密的这种方式去建模这种 BV 或者 voxel,但它的缺点在于现有的这种方案还没有能够把这个深度信息给利用上,
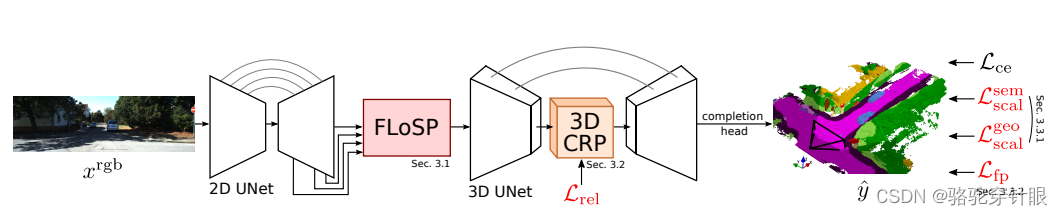
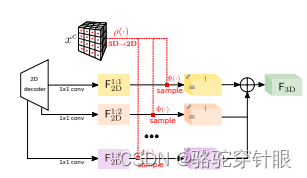
MonoScene:它发表就发表在 CPR 2022 上。他的做法跟我们熟知的 BV 方案其实很像,就它的也涉及到一个 view transformation 的模块,它要把图像从 2D 空间转移到 3D 空间,稍微不同的就是它需要建模 3D 空间的 voxel 的表征,然后最后用一个分割的头来预测 occupancy 这个最后的输出。
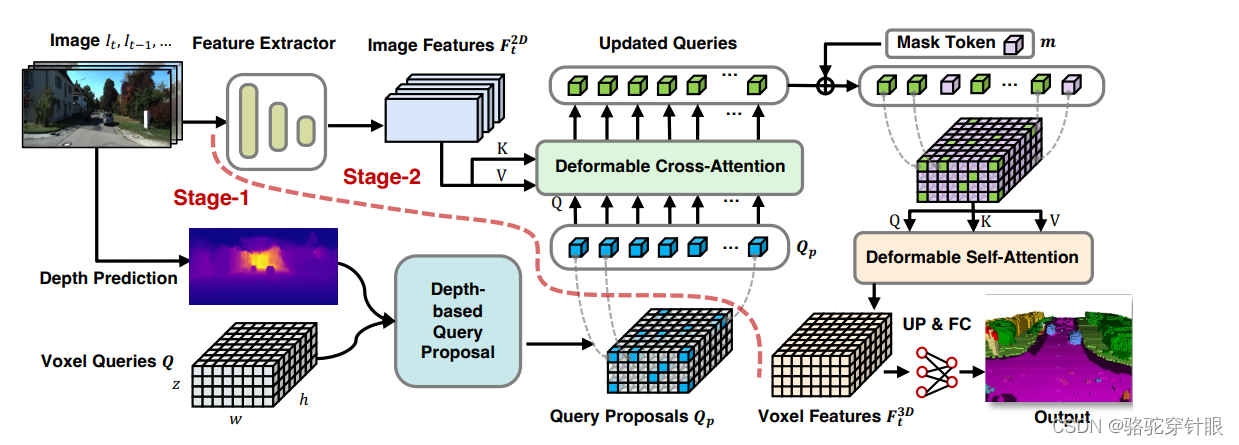
是一个两阶段的方案,在第一个阶段它用到深度信息建模了一个相对稀疏的 query proposal,然后在第二阶段他用到了类似于 bevfromer 这种反向投影机制来更新这个 query proposal
比赛概要
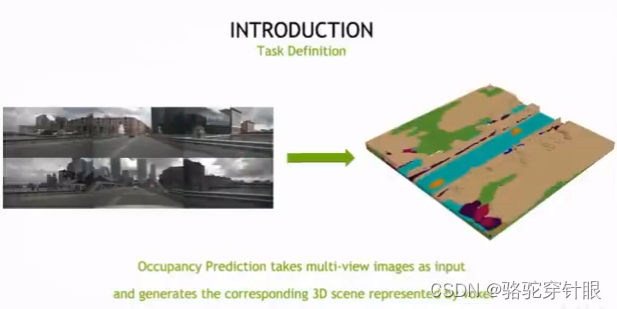
这个比赛,因为这个比赛是既有 nuScenes 数据集构建的 Occupancy,它的输入是 6 个环视摄像机,那我要根据 6 个环视量级的输入构建最后的 occupancy 表征
想法分享
在这里插入图片描述
你其实想要构建一个 Occupancy 跟自己的方法,嗯,其实是一个相对来说比较容易的过程。我们最简单的,我们只需要把 prediction head 从检测头换成一个分割头就可以做到,但我们会发现你只用 BV 表征,比如你先得到 BV 表征,最后再来支持这种 3D 的 occupancy 的任务,它的表征能力有所欠缺,所以现有的 occupancy prediction model 基本都是使用 Voxel 的表征,这样它会有更好的性能。但是我们前面看到的 forward project 或者 backward project,他们从你构建 BV 表征或者 构建 voxel 表征,其实都是可以相对容易的这种转换的,他们之间的转换都是很容易的啊。
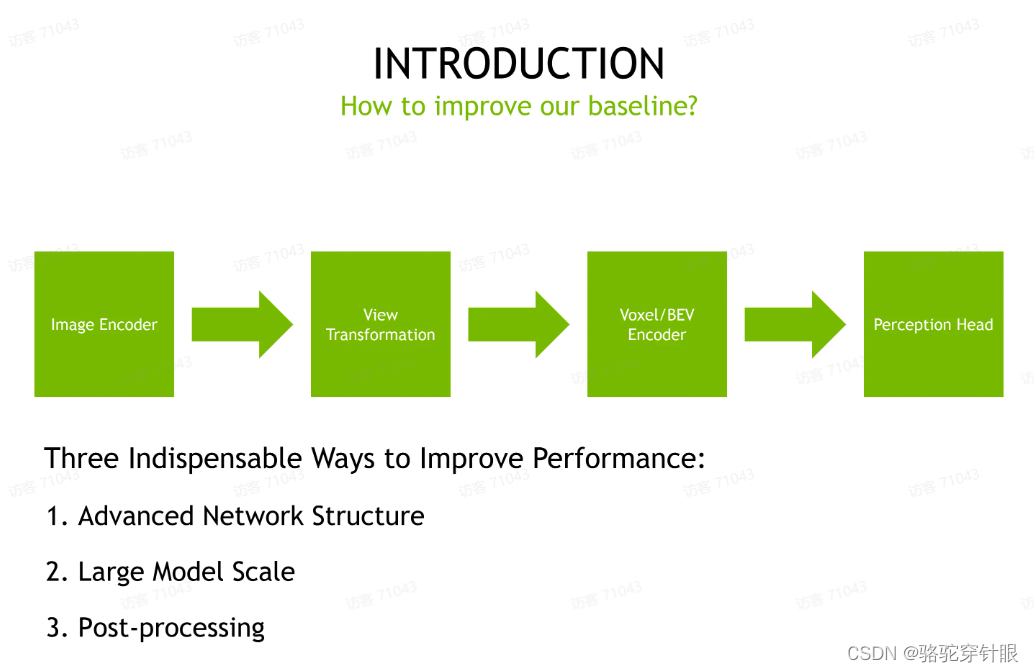
第一个就是我们要在模型结构上设计,设计的应该是最先进的模型结构。
第二个就是我们要把我们的模型尺度放到最大,我们做一个大模型肯定会比小模型,轻而易举的提升性能。
第三个就是我们也比较关注后处理的过程。
在这里插入图片描述
我们会看到在比赛之初我们其实就已经有了不少的这种 occupancy tradition 的开源方案。有的方案比如他们会用到对于表征层面来说,他们有的会用到 Voxel,有的甚至比如 TPV.
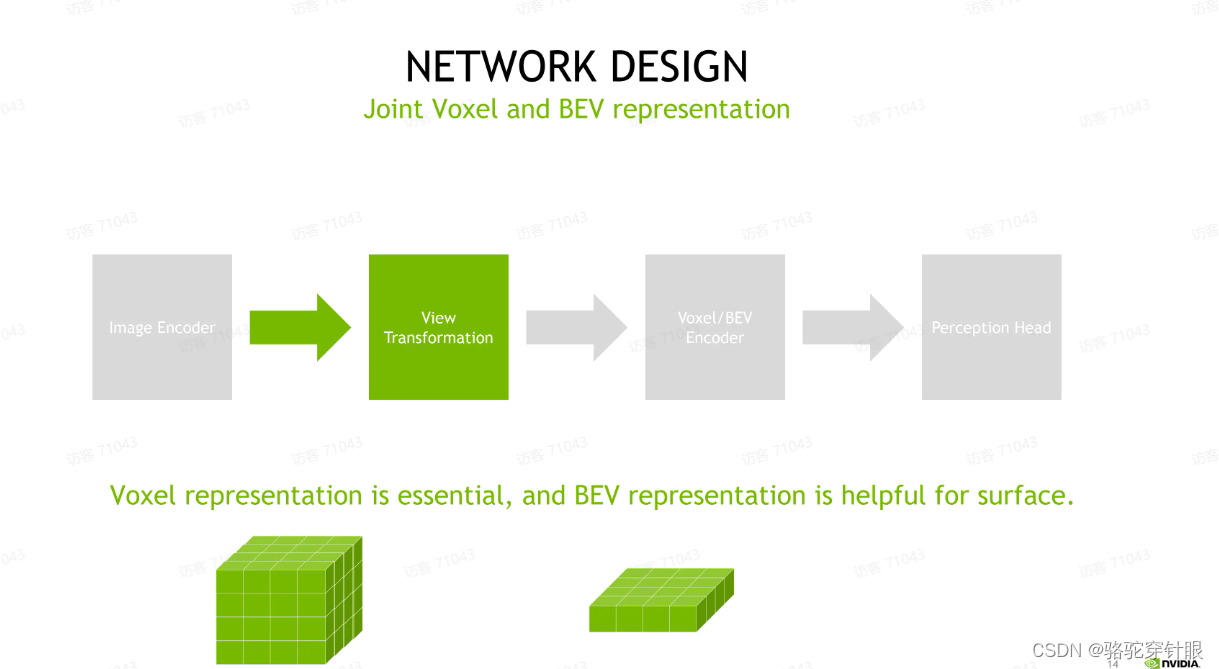
做的首先就是对于表征层面来说:
1.我们会认为一个 voxel 的表征是必要的,因为毕竟最后的 occupancy 输出你需要在高度层面上它是一对有要求的。
2.我们会发现如果我们在 voxel 表征之外,我们额外添加一个 BV 的表征,但是它也是会有一定的益处的。它对于重建,比如路面这些, surface 这种类别的这种会有一定的帮助。所以我们最后是用到了一个 voxel 表征,联合 BV 表征这样一个方案啊。

对于投影,我们前面介绍的,不管是 forward project 或者 backward project,他们都有各地各自的优势或者劣势。对于 for 的project,我们讲到了他产生的这个表征会很稀疏,我们统计了一下,比如用到常见的 setting 的话,用 forward project 产生 3D voxel 表征,它会有 75% 的 voxel 是空的,也就是它的 Feature 是全零。因为它接收不到来自任何图像的信息,所以这种稀疏跟我们,比如我们见到的LiDAR点云那种稀疏是不一样的,这种稀疏是由于投影机制和透视关系导致的稀疏,这种吸出是需要我们去稠密化这种稀疏的,
那我们怎么去稠密化这种稀疏呢?
所以我们就看到我们前面讲到了 backward projection,它就是天然的具有这种优势,我们可以从任意 3D 点出发投影回图像层面,然后获取到对应的这种即刻信息。
然后我们这种backward projition,它其实也不受制于,比如说你的,你必须,你的 query 必须组织成一个 BV 或者 3D voxel,这种层面我们可以建立起任意形状、任意形式的这种backward的 project query,获取到我们所需的这个信息。
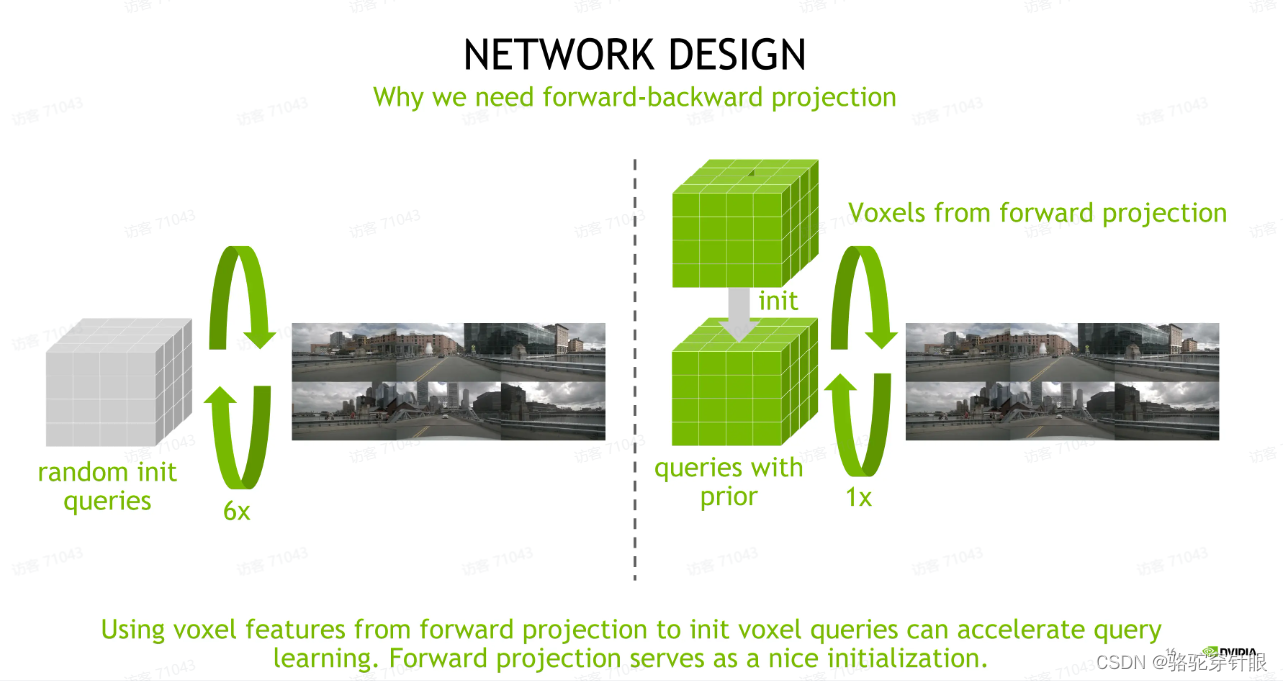
bevformer这种建立使用随机初始化的快位,它需要比较多次的这种反复交互。如果我们能够用 follow projection 产生的 query 来初始化,我们带过了 project 所用到的跨位,我们会大大降低这个跨位它的学习难度。我们在这个FB-OCC 方案里面,我们只用一次反向投影就可以有很好的效果。所以我们可以知道 forward projection 和 backward projection,他们有非常好的这种互补的性质

可以看到我们上面介绍了 forward projection,它会产生这种空白的,这种稀疏的这种 voxel 表征或者 BV 表征。但 forword projection 的缺陷是它没有能够利用到深度,导致它产生的 BV 特征或者 forwork 特征中有很大的 false positive,所以我们将这两种不同的投影机制结合起来,建立一种 forward-backward projection 投影方式。
1.我们先用 forward projection 来构建一个 BV query 的初始化.
2.我们用这个初始化作为 backward projection,query 来反向投影回图像来填充这些系数的特征,
所以这两种机制我们看到它们是极其互补的。
我们介绍到了刚上面介绍的 backward position 的一个缺点,不能有效的利用深度,所以也就导致了我们可以看到现在 Bevformer 这种性能是劣于 Bevdepth,所以我们能不能想办法把 depth 也用到 backword projection 里面呢?
因为 forward projection 和 backword projection 他们可以看作是那种相机成像的函数,相机成像函数的左右两端,所以我们所有 forward projection 能用到的性质,理论上 backward projection 都能够用到。
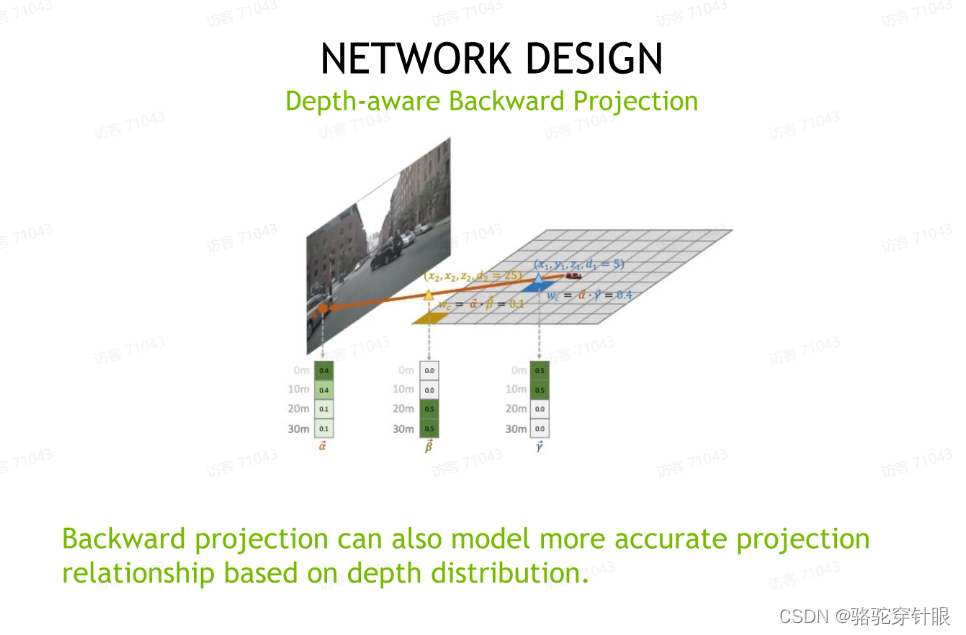
为了在 backword projection 里面用到深度信息,我们构建了一个深度的深度匹配的性质。
对于任意一个 3D 点,一个给定的 3D 空间上的一个点,其实我们可以就直接计算出来它在图像上对应的深度,有了这个深度之后,我们可以把这个深度信息电转换成一个深度的分布。
同时我们也知道我们能够预测图像上对应点它的一个深度信息的分布,我们通过计算两个深度分布的这个相似度就可以计算出来这个 3D 空间的点和 2D 空间上的点它的匹配程度,通过我们抑制掉这些匹配程度低的这样一个投影点,我们可以相当于建立起来更加精准的这样一个投影的匹配关系,这样就很像 LSS 它利用,它可以利用到深度的权重那样一个机制。
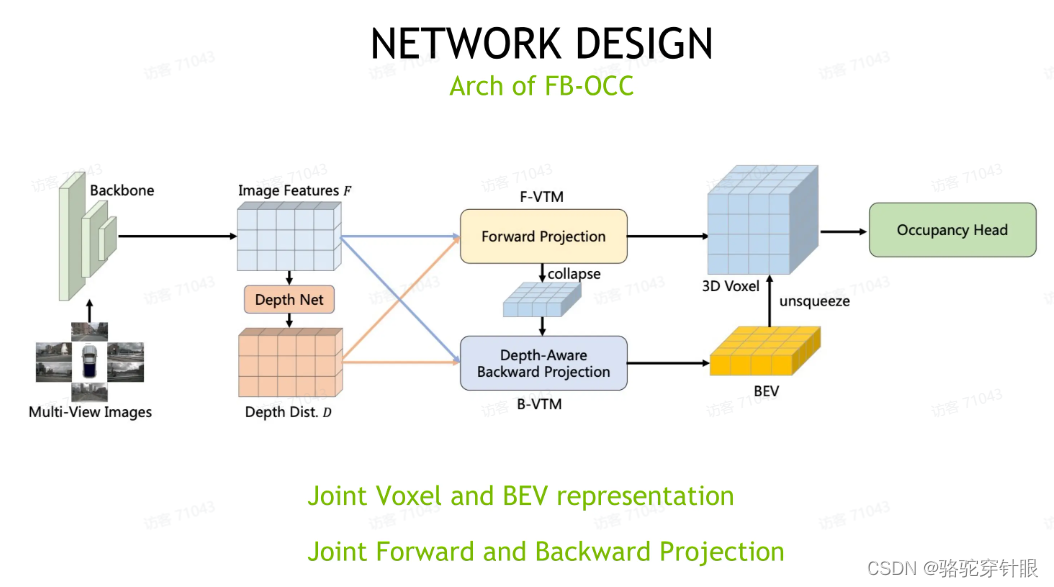
所以接下来就是我们整个的这个网络结构图,我们可以看到,首先对于多视图,我们用 backbone 之后,我们会有图像信息和对应的深度信息。对于 backward projection 机制,我们在 forward projection 上会用到图像进行一个深度信息,生成一个 3D 的 voxel 表征,同时也是出于计算量的考虑,在 backward projection 阶段,我们会把 voxel 表征给压缩成一个 BEV 的表征,作为 backward projection 的初始化。在backward projection 的阶段,我们也会用到图像特征和深度信息来相当于稠密化这个 BEV 表征。然后最后我们会把 BV 表征恢复到 3D voxel 表征这个形式作为一个加权融合,最后会得到一个相对来说比较稠密的 3D voxel表征,这样整个方案我们相当于既融合了voxel和 BEV 表征,也同时融合了 backward forward 和 forward projection 两种不同的投影方式,是一个比较综合的方案。
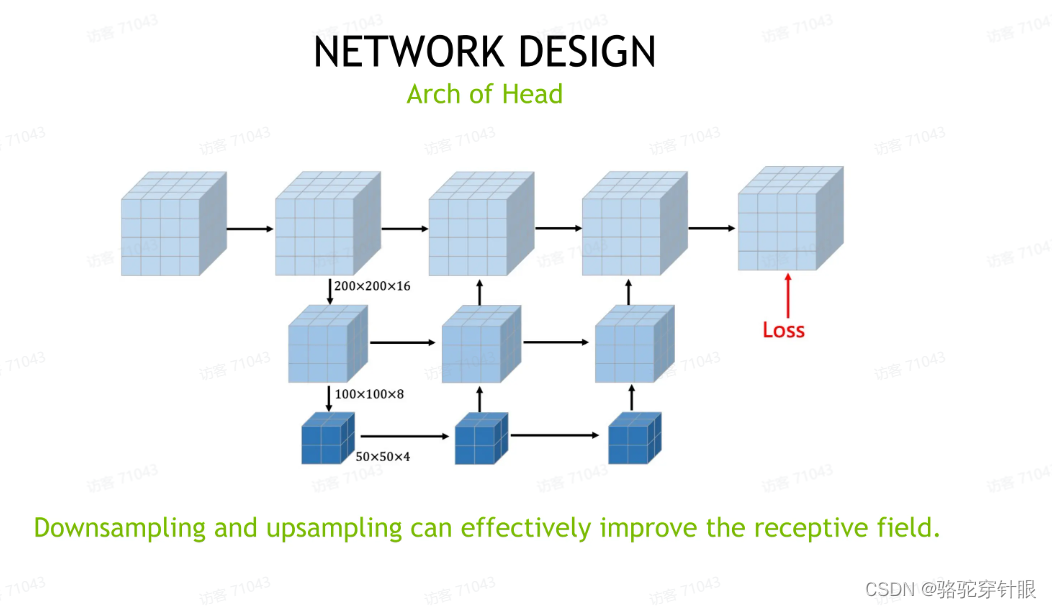
接下来就是我们这个occupancy,这个 head 的构建,我们在 head 的构建上其实并没有花过多的精力,基本都是沿用现有的方案,对于给定一个 voxel 表征来说,其实它就是相当于做一个 3D 层面的语义分割。这里面比较关键的模块在于类似于一个 U-net 或者 backbone FPN 这样一个结构,它需要这个层面它的作用。
首先第一个层,第一个作用是扩大这个表征的感受野。另一个我们能想到的点就是这个表征,我们建立这个表征的时候是从 2D 特征里面投影过来的,在 3D 层面他们的特征很有可能会,他们没有那么连续的性质,所以我们会用一个比较深层的 encoder 来恢复这个特征层面的连续性。
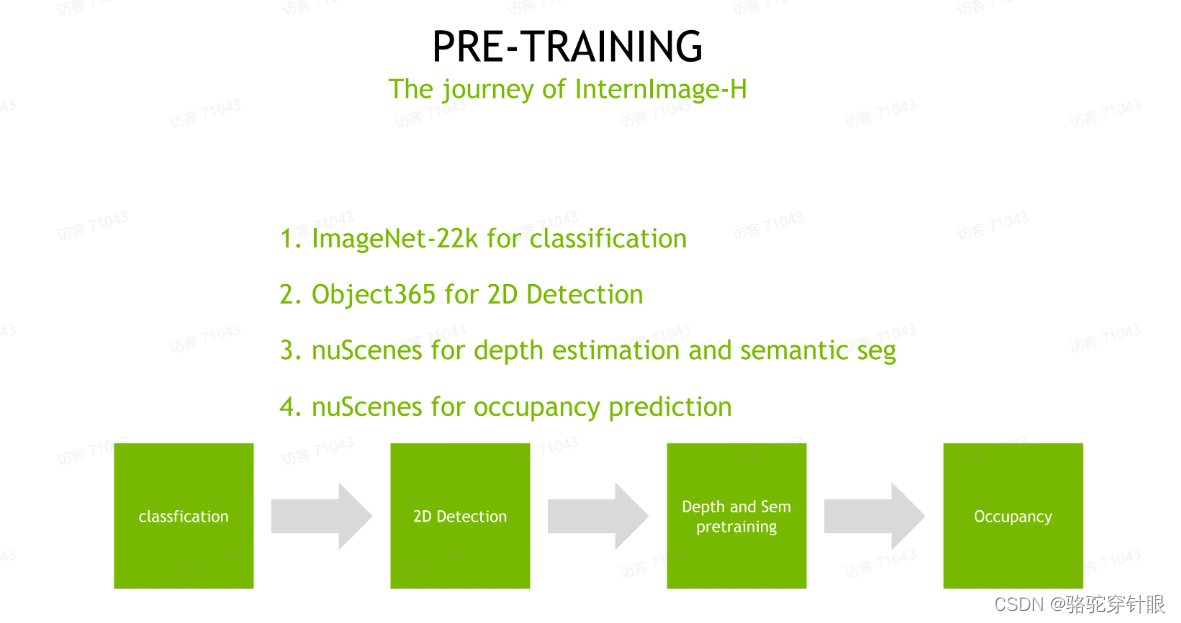
scaling-size
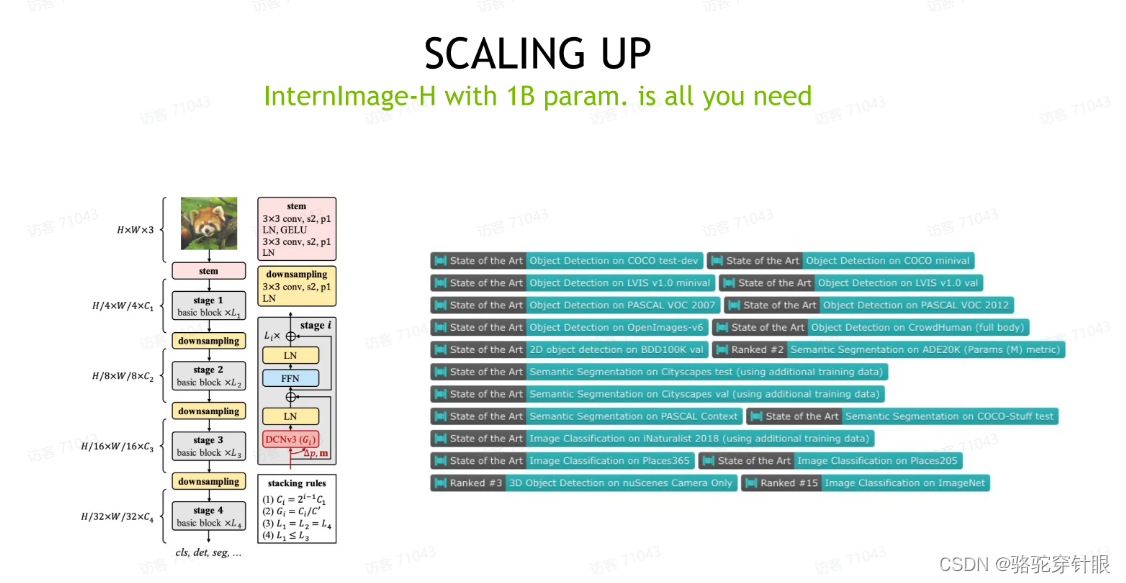
Internlmage-H 1B量级这个 image in code 给用起来,但直接用这个 1B 量级的参数肯定是不太合理的,因为我们有一个 10 亿参数的模型,
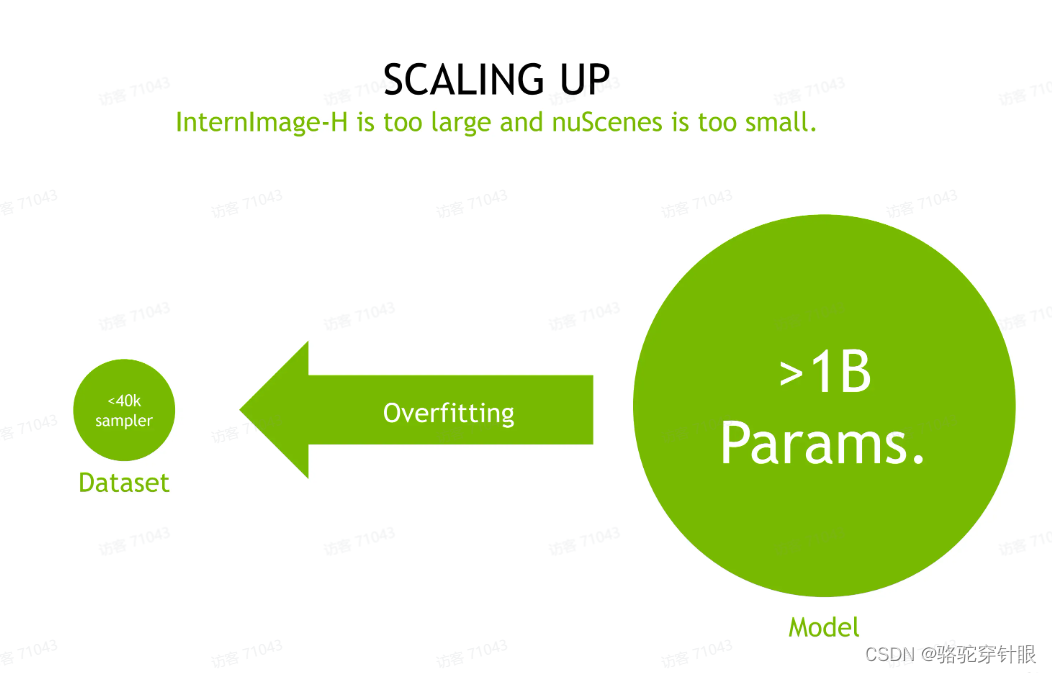
但我们的数据集 nuScence 这个数据集它的样本其实是少于 40K 的。你直接应用这么一个大的数据,大的模型,训练这么少的数据,它很容易导致过拟合的问题。
Depth 和 Semantic 这个联合预训练
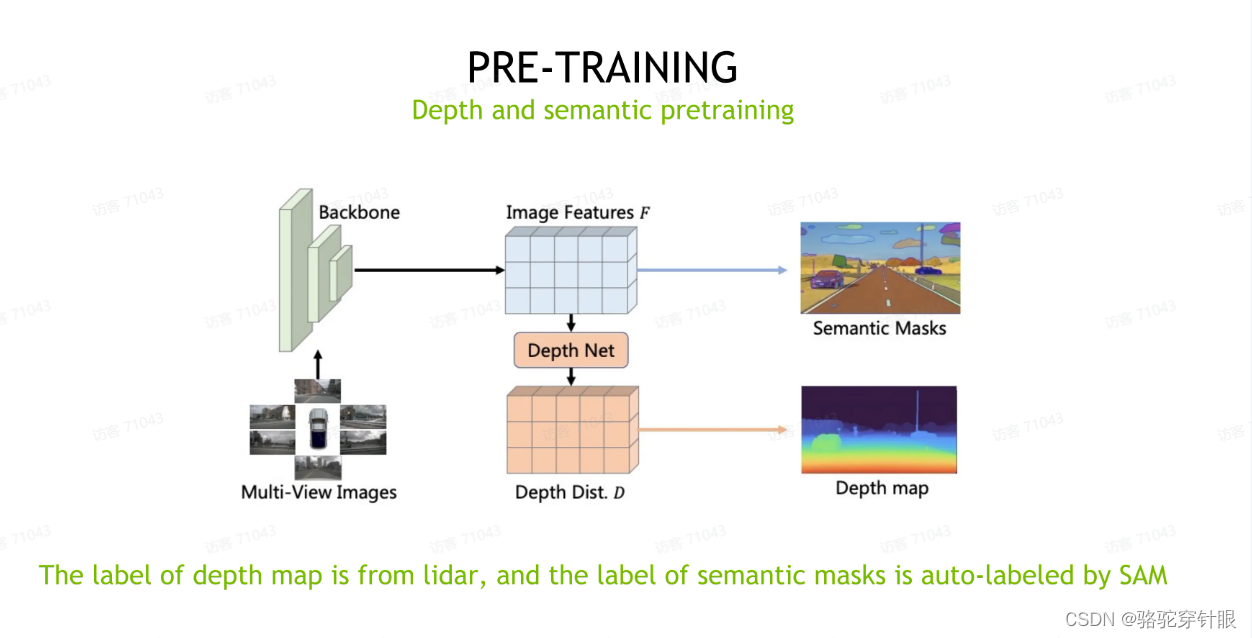
nuScance 它其实没有提供这个图像 2D 的语义分割标签,所以在这次比赛里面我们其实也用到了,就是在那个 SAM_anything 这个模型来帮助我们做这个图像的自动化的比语义分割的这个标注
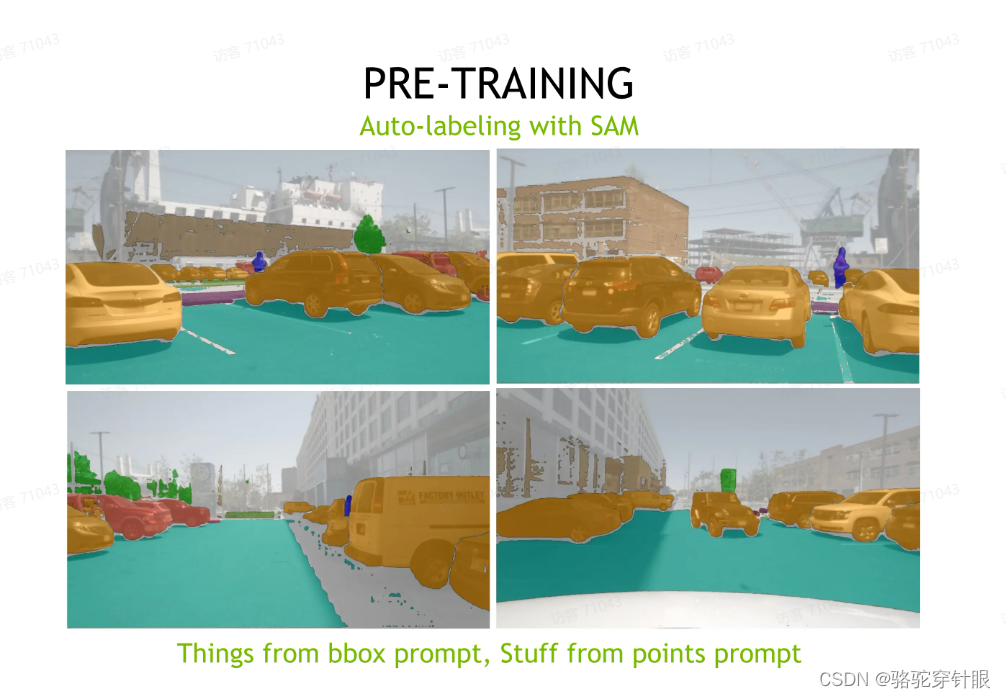
具体做法就是因为 nuScance 它其实提供了对于 sim 类别,它其实提供了 3D call,我们可以把 3D 框变成 2D 框。然后用 SAM 的 box 这个提示就可以得到质量相对来说非常高的这个,这个 instant segmentation 这个标签。
当然是另一方面对于 stars 类别,就是像路面这种类别,路面 building 这种类别其实我们是没有它的框的,然后但是 nuScance 提供了稀疏的 LiDAR 点的分割,我们在这里的做法就是把 LiDAR 点投影到图像上,随机选取几个对和一个类别,我们随机选取几个 LiDAR 点,然后做点提示来生成最优的标签。
其实我们可以看到只用点标签做分割的话,效果其实,嗯,在一定程度上是可以满足要求,但不是那么完美,主要原因就是我们随机的点是不可控的。然后对于树木这些它有可能的点是十分分散,在我们随机三个点是随机到一棵树上就可以看到最后只分割出来一棵树,然后其他树其实是没有分割出来的。但这里我们对于没有分割、没有标签的那些类别,我们其实最后预测过程中是不预测的,相当于我们尽可能保证我们这个 mask 预测在它这个准确率,我们最后的准确率其实是相对来说比较高。
后处理
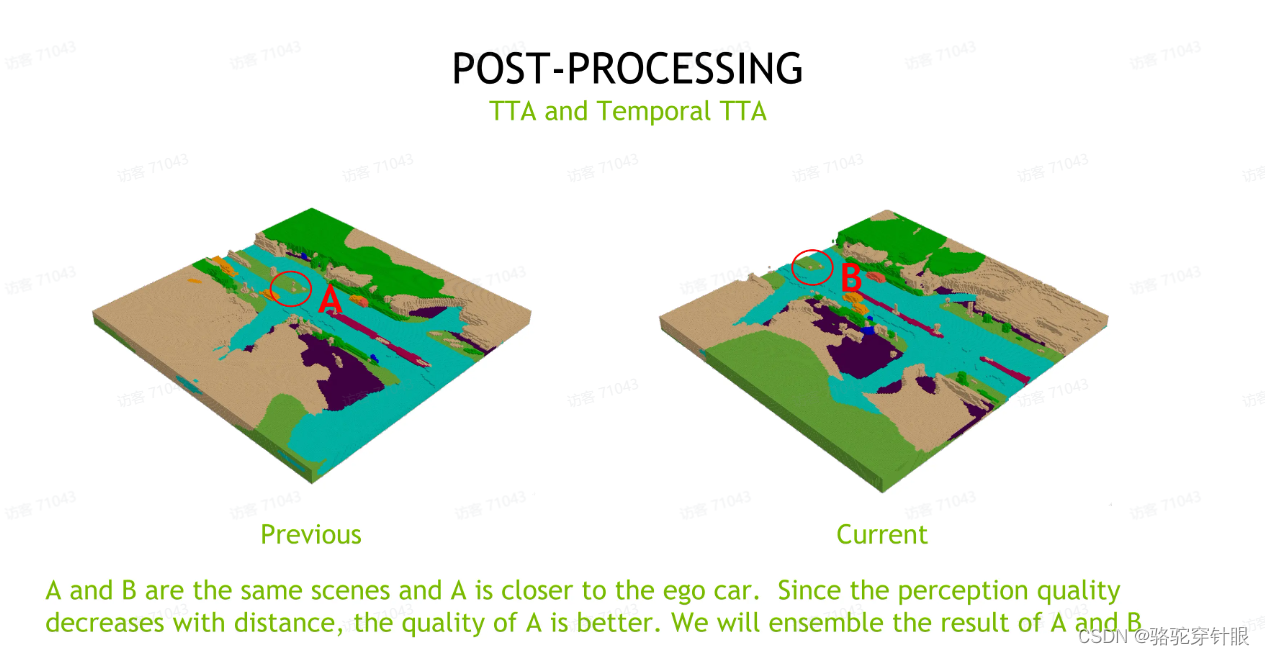
1.最简单的 TTA 其实就是图像空间、 BV 空间这些简单的反转。
2.我们也引入了一个时序的TTA。我们因为我们发现,因为对于我们预测结果的准确率是随着这个 voxel 离 EGO car 如果距离变得越远,这个性能是急剧下降,因为越远处它的深度估计会非常的不准确。然后我们就会想到对静态的物体。对于一个静态的物体,我们可以用前一时刻,如果它离 ego car 更近,在当前时刻它离 EGO car 更远,然后我们可以用前一时刻的预测结果来替代当前时刻,然后最后我们也是用到了加权融合的方式。这种 Temporal TTA 也能带来接近一个点的提升,但由于整个数据集它在标注层面的高度没有,它的连续性其实是没有得到保障的。我们相信如果我们有更精准的数据集的标注,最后这个 Temporal TTA 的效果还是能够更进一步的发挥它的这个效果。
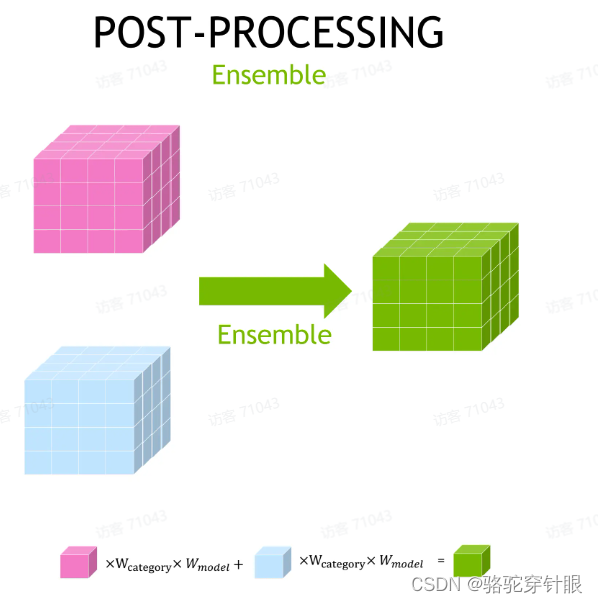
除了 TTA 之外,当然打比赛肯定大家都会用到 Ensemble 策略,在这里面我们的 Ensemble 也是非常简单直接的,对于不同的模型的预测结果,对于每一个 voxel,我们会赋予这个 voxel 两个不同的权重,一个是它的类别权重,另一个是它的模型权重。
模型权重是根据整个结果最后的整体的 IOU 决定的, MIOU 决定的类别权重是根据它这个 voxel 所处的类别,它的特定的这个 IOU 决定的。当然我们对于每个权重,我们都会给它一个可学习的参数,我们会用一个自动搜索的框架 NI 来搜索最佳的参数,来确定最终的这个 Ensemble 的策略。
在比赛里面,我们基本上会把我们所有可能会用的所有训练好的模型结果都会拿进来 Ensemble,我们最后也是用到了大概来 7 个模型的结果来 Ensemble。
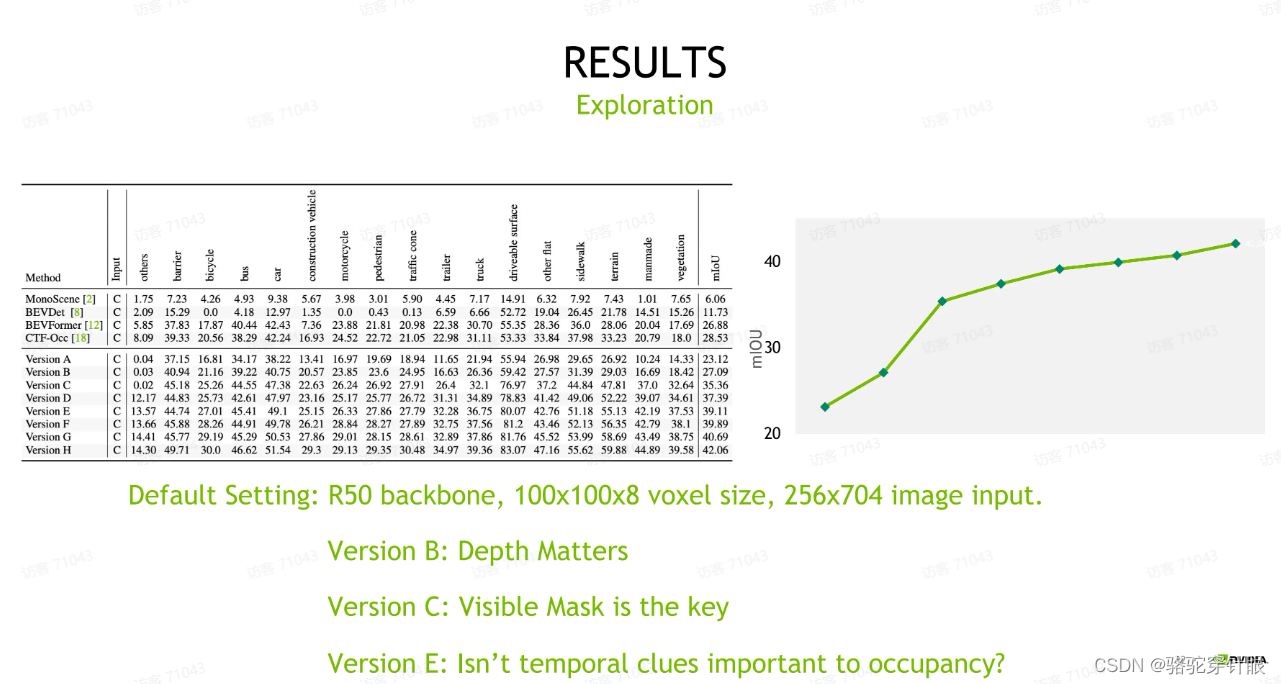
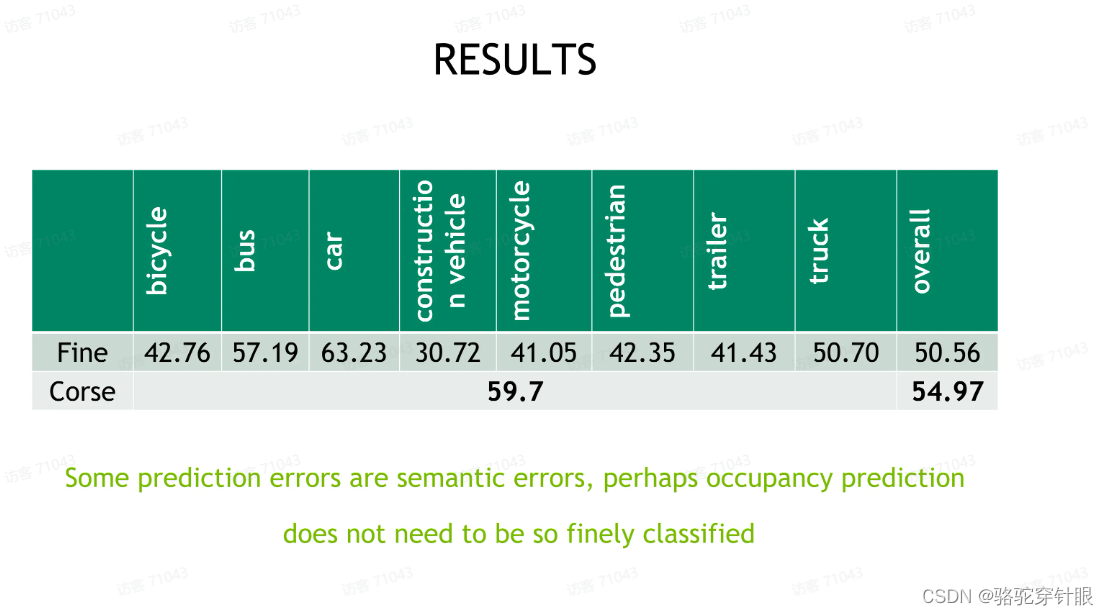
第二个,相比于不同于以往, object detection 的结论是在这里边,在对于 occupancy prediction 任务来说,我们需要考虑一个 visible mask,就是我们对于相机不可见的那些 voxel,在训练的时候我们需要把它忽略掉,就是降给模型的学习压力做一个放松。这样一个放松我们可以看到带来,可能带来将近 8 个点的提升,
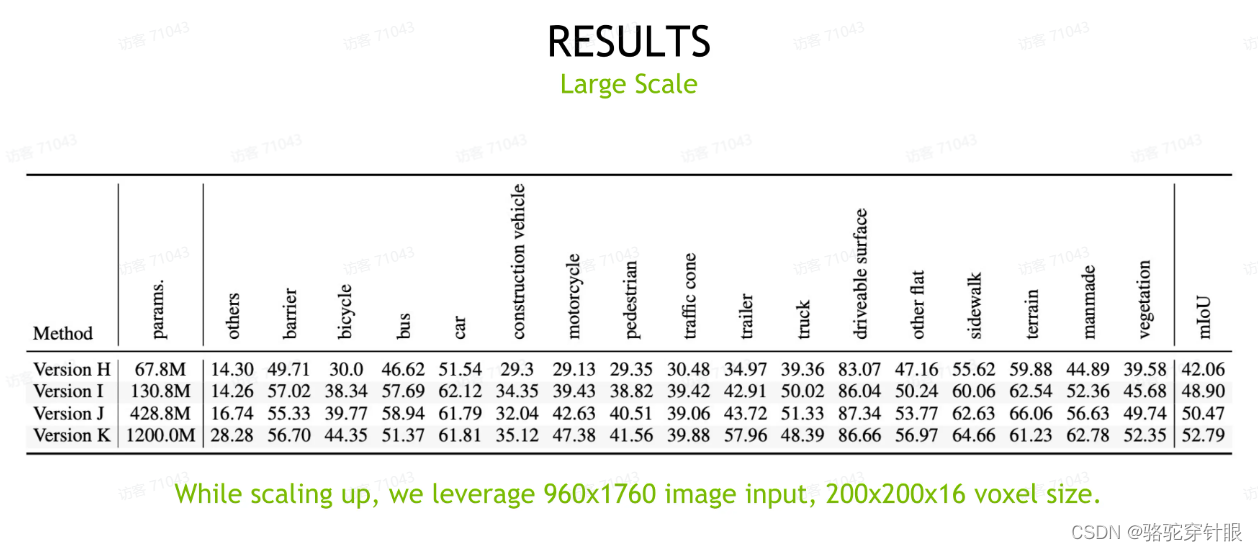
我们可以看到我们最开始的 baseline 用 R50 ,嗯,是有 67.8 兆的参数。最后我们用到了Internlmage-H,一个 11 参数量级的backbone,那我们整体的模型尺度也达到了,你达到了 12 亿参数。在 12 亿参数的量级上面,相比于最开始的R50,我们大一共获得了 10 个点以上的提升,这也是我们。嗯,最后这个大尺度的模型也必须依赖于 80G 的 A100 模型,其实我们也想要证明的就是现有的这个模型它仍然是符合放松规律的,越大的模型仍然会带来更好的效果。
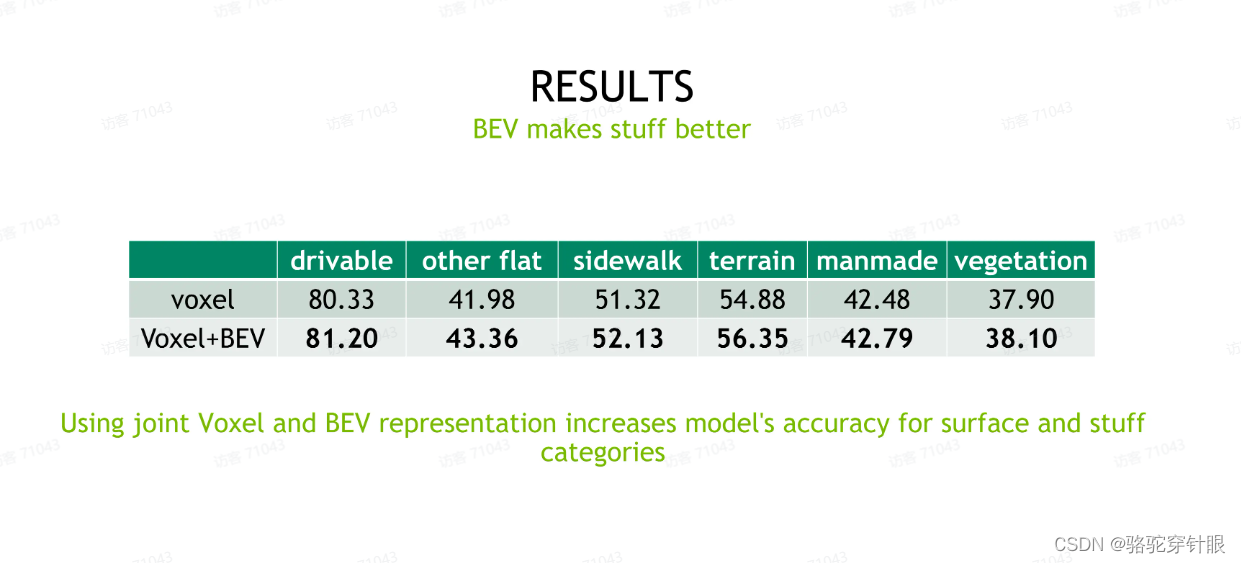 我们证明了就是使用 voxel 和 BEV 的联合表征可以提高模型在 surface 类别,就是 surface 这种路面或者人行道这种类别的这种准确率会看到对于路面、人行道或者绿化带这些基本都会带来可能 0- 1 个点的提升,说明 BV 表征对于最后模型的预测还是有益的。
我们证明了就是使用 voxel 和 BEV 的联合表征可以提高模型在 surface 类别,就是 surface 这种路面或者人行道这种类别的这种准确率会看到对于路面、人行道或者绿化带这些基本都会带来可能 0- 1 个点的提升,说明 BV 表征对于最后模型的预测还是有益的。
视频连接
文档连接





)

学习笔记 18 - 4.4 最短路径)

)


)




 2024区块链开发者大会)

)