说明
遗传算法是一个很有用的工具,它可以帮我们解决生活和科研中的诸多问题。最近在看波束形成相关内容时了解到可以用这个算法来优化阵元激励以压低旁瓣,于是特地了解和学习了一下这个算法,觉得蛮有意思的,于是把这两天关于该算法的学习和实践的内容总结成了一篇博文。
遗传算法核心的思想/步骤在于迭代。这篇博文第一次写作(2024.3.15)只包含了一些关于该算法基本且必要的概念的介绍,以及两个相关应用的实践,后面有更多相关的应用实践(比如波束形成的优化)、细节的积累和理解,我会不定期迭代该博文。
Blog
20240315 博文第一次撰写
目录
说明
目录
一、遗传算法概述
1.1 遗传算法的来源及应用领域
1.2 与遗传算法有关的基本名词概念
二、基于遗传算法求解各类问题的基本思路和流程
三、基于遗传算法求解调度问题
3.1 问题描述
3.2 问题建模及参数预设
3.3 求解过程几个核心代码模块解读
3.3.1 如何寻找父辈染色体
3.3.2 如何交叉
3.3.3 如何变异
3.4 求解结果
3.5 小结与思考
四、基于遗传算法求解旅行商问题
4.1 问题描述
4.2 问题建模及参数预设
4.3 求解过程几个核心代码模块解读
4.3.1 如何交叉
4.3.2 如何变异
4.4 求解结果
4.5 小结与思考
五、其它应用问题
六、总结
七、参考资料
八、代码参考
一、遗传算法概述
1.1 遗传算法的来源及应用领域
百度百科上的介绍很宽泛,但是也有诸多有用信息:遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世纪70年代提出,该算法是根据大自然中生物体进化规律而设计提出的。是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法通过数学的方式,利用计算机仿真运算,将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程。在求解较为复杂的组合优化问题时,相对一些常规的优化算法,通常能够较快地获得较好的优化结果。遗传算法已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。
1.2 与遗传算法有关的基本名词概念
理解该算法,首先从与其有关的基本概念入手,在后文的应用实践中我会将这些概念在应用问题的数学建模以及求解流程中一一对应。参考资料[1]中对这些概念的介绍很棒,本节内容主要参考该资料。
1. 基因与染色体
求解各类应用问题时,我们首先需要将要解决的问题映射成一个数学问题,也即:数学建模!该数学问题的一个可行解便被称为一条“染色体”,一个可行解可能由多个元素(多个变量)构成,该解的每个元素(变量)就被称为染色体上的一个“基因”。
2. 适应度
遗传算法求解问题的本质我觉得就是一个在不断的迭代中逼近最优解的过程。我们每次迭代都会有很多的染色体(可行解)产生,那我们如何衡量这些染色体的优劣呢?在遗传算法中我们用适应度来衡量每条染色体的优劣,我们构造一个适应度函数来给每次迭代中生成的所有染色体“打分”,得到每条染色体的适应度。在后续处理过程中,我们可能会将适应度较低的染色体淘汰掉,只保留适应度较高的染色体,从而使得若干次迭代后染色体的质量越来越优。[类似达尔文进化论中的观点,一些无法适应环境的个体(等价于这里一些适应度低的染色体)会被淘汰掉]。
3. 交叉
假定每次迭代都会生成N条染色体,交叉则是用来解决如何生成新染色体的问题:交叉的过程需要从上一代的染色体中随机寻找两条染色体,然后将这两条染色体通过一些算法生成新的染色体(比如有单点交叉、双点交叉、顺序交叉等,不同的应用场景可能会使用不同的交叉算法,这里的概念读者可以参考资料[2],后文的实际应用时会对这里再展开讲),此外,还有一个问题是:如何选择这两条染色体?在上一个步骤中的适应度评价中,我们计算得到了每条染色体的适应度,在交叉时,我们会基于适应度概率(通过比如轮盘赌等算法来进行挑选)优先选择适应度更大的染色体来进行交叉。适应度概率的计算: 染色体i的适应度概率(被挑选的概率) = 染色体i的适应度/所有染色体的适应度之和。
4. 变异
交叉时因为我们优先选了适应度高的染色体,所以能保证每次进化能留下优良的基因,但它仅仅是对原有的结果集进行选择,基因还是那么几个,只不过交换了他们的组合顺序,这只能保证经过N次进化后,计算结果更接近于局部最优解,而可能永远没办法达到全局最优解。为了解决这一个问题,我们需要引入变异。变异的方法:对于前述交叉过程生成的染色体,我们可以适当地(这里牵扯到一个叫变异率的参数设置问题:如果对每条交叉后的染色体进行变异其实很难收敛的,所以选择其中的多少条进行变异,是一个需要考虑的问题)选择其中的几条,在这些染色体上随机选择若干个基因,然后随机修改基因的值(变异的方法有很多,如:位翻转突变、交换突变、反转突变、倒换突变等,同样,参考资料[2]中有比较详细的说明,后文的实际应用中我也会结合流程做细节介绍),从而给现有的染色体引入了新的基因(或改变了基因的排序),突破了当前搜索的限制,更有利于算法寻找到全局最优解。
5. 复制
每次进化中,为了保留上一代优良的染色体,需要将上一代中适应度较高的几条染色体直接原封不动地复制给下一代。假设每次进化都需生成N条染色体,那么每次进化中,通过交叉方式需要生成N-M条染色体,剩余的M条染色体通过复制上一代适应度最高的M条染色体而来。
6. 关于迭代的结束
在基于遗传算法求解各类问题时,我们应该迭代(进化)多少次才结束?一般有两种方式来确定迭代何时结束:一是预设迭代次数,在一些实际应用中,可以事先统计出达到较好效果时的进化次数。比如,你通过大量实验发现:不管输入的数据如何变化,算法在进化K次之后就能够得到最优解,那么你就可以将进化的次数设成K。然而,实际情况往往没有那么理想,因为不同的初始输入会导致得到最优解时的迭代次数相差甚远。二是限定精度范围,如果算法要达到全局最优解可能要经过很多很多次进化,这会极大影响系统的性能。那么我们可以在算法的精确度和系统效率之间寻找一个平衡点。我们事先设定一个可以接收的结果范围,当算法进行k次进化后,一旦发现了当前的结果已经在误差范围之内了,就终止算法。不过这种方式下也有缺点:有些情况下可能稍微进化几次就进入了误差允许范围,但有些情况下需要进化很多很多很多很多次才能进入误差允许范围。这种不确定性导致算法的执行效率不可控。
二、基于遗传算法求解各类问题的基本思路和流程
前文对遗传算法可能涉及的各参数及其用途(在算法中的角色)做了说明,将这些概念串起来,便构成了典型的遗传算法处理流程。
对于各类应用问题,首先需要明确问题并进行数学建模。
然后预设参数:比如我们需要预设多少条染色体、预设多少的迭代次数、预设多少的变异率、预设多少的染色体是从父辈直接复制的?
随后基于数学建模的结果,针对该应用问题,初始化染色体、设计适应度函数来计算这些初始化染色体的适应度和被选取概率。
接着就可以进入迭代的循环里:交叉 ---> 变异 ---> 复制 ---> 交叉 ---> 变异 ---> 复制 … 直至达到预设的迭代次数,或者满足其它预设迭代终止条件。
典型的遗传算法流程如下:
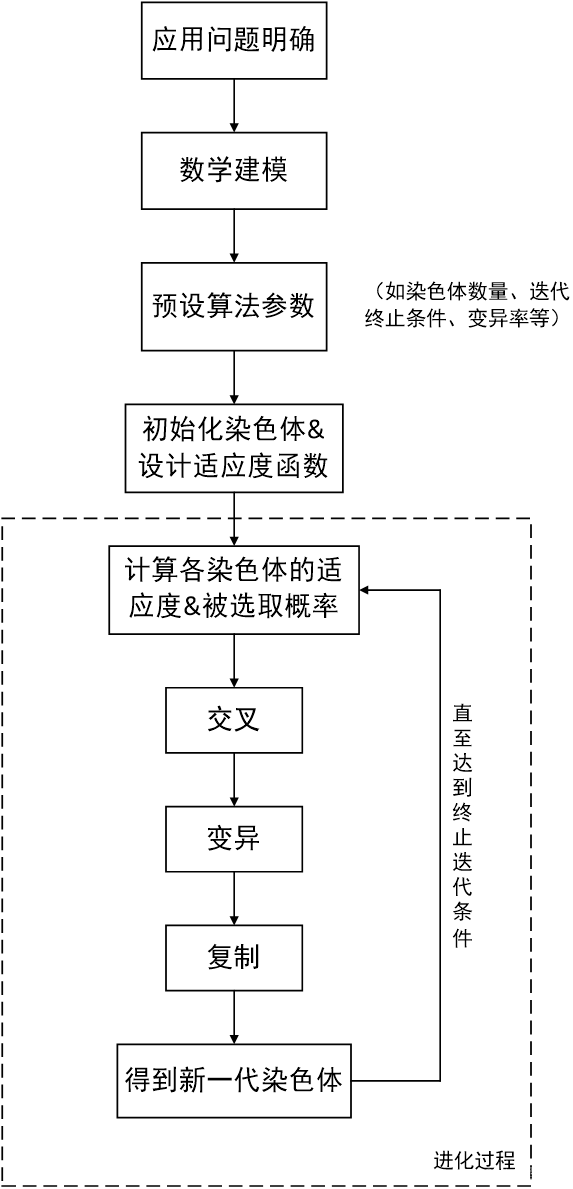
图2.1 典型的遗传算法流程图
在本章以及上一章的指导下,我们可以尝试将该算法部署至各类应用问题上。
三、基于遗传算法求解调度问题
3.1 问题描述
假设有N个任务,需要负载均衡器(你)分配给M个服务器节点去处理。每个任务的任务长度(任务量)、每台服务器节点的处理速度已知,请给出一种任务分配方式,使得所有任务的总处理时间最短。[与该服务器调度类似的各种问题的解答方法一样]
3.2 问题建模及参数预设
问题建模:(调度问题的建模相对简单),假设我们已知问题中每个任务的长度为:Task = [Task(1),Task(2),… Task(N)],每个节点的处理速度为:Nodes = [Node(1),Node(2),… Node(M)]。我们可以构造每个任务和每个节点之间对应的处理时间矩阵:
![]() (3-1)
(3-1)
表示将第i个任务交给第j个节点处理所需的时间。
初始化染色体:我们预设初始染色体数(或者常说的初始种群数)为K,因为每条染色体对应一个可行解,所以容易理解的是:每条染色体是一个长度为N的一维向量:A = [A(1),A(2),… A(N)],向量中的每一个元素A(n)对应一个基因,其物理意义是我们将第N个任务分配给第A(n)个服务器节点。我们可以基于随机分配的方法完成对K条染色体的初始化,此时我们可以得到一个染色体对应的矩阵,其大小为:K*N。
设计适应度函数:适应度是我们用来评价每条染色体优劣的指标,在本问题中,容易想到可以用每条染色体对应的任务分配下的总耗时来构建适应度函数:
TimeNeed(k) = max(节点1耗时、节点2耗时、… 节点M耗时) (3-2)
我们对K条染色体分别求其完成任务所需时间(求解过程中我们可以从前面的TimeMatrix矩阵中查找时间),最终可以得到一个长度为K的一维向量:TimeNeed = [TimeNeed(1),TimeNeed(2),… TimeNeed(K)],向量中的每个值对应第k条染色体对应的任务分配下完成任务的耗时。需要注意的是:在该任务中,耗时越少对应的任务分配(染色体)越优,其适应度也越高,所以这里我们可以对总耗时取倒数得到每条染色体的适应度:
Adaptability = 1./TimeNeed (3-3)
得到适应度后,求每条染色体在交叉时被挑选的概率就简单多了:
SelectionProbability = Adaptability(k)/(sum(Adaptability)) (3-4)
在完成上面的准备工作后,我们可以进入迭代部分。在后面的几个应用实践中,我将不再如此细致做该部分的讲述。
3.3 求解过程几个核心代码模块解读
3.3.1 如何寻找父辈染色体
在做交叉之前,需要从上一代中寻找父&母两条染色体。在1.2节中,是这样描述该过程:“我们会基于适应度概率(通过比如轮盘赌等算法来进行挑选)优先选择适应度更大的染色体来进行交叉。”在3.2中已经给出了适应度概率(被挑选概率的计算方法),本小节介绍如何基于轮盘赌算法来完成对父母辈染色体的挑选,代码块如下:
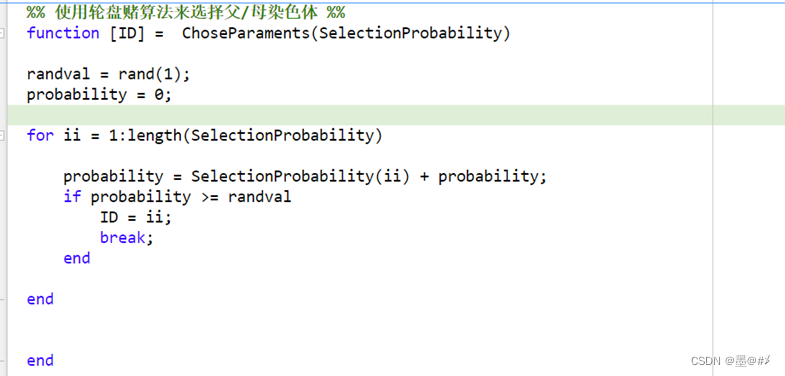
图3.1 轮盘赌算法函数
该算法的基本原理其实很简单:首先在[0 1]内随机生成一个概率值randval,然后对之前得到的染色体对应的被挑选概率数组进行遍历和概率累加,当在第k个概率处累加的结果:(SelectionProbability(1)+ SelectionProbability(2)+ … SelectionProbability(k)) ≥ randval时,就将k对应的染色体挑出来。该函数的调用模块代码如下:

图3.2 轮盘赌算法的调用模块(选择父&母染色体)
ChromosomeOld对应上一代染色体数组。为确保两次选择的不是同一条染色体,代码中增加了一个判断模块。
轮盘赌算法是一个简单且经典的选择父辈染色体的方法,当然,可能还有其它的方法,总之这些方法的主要目的是优先选择被挑选概率大(适应度高)的父辈染色体,但又不失随机性。
3.3.2 如何交叉
寻找父辈染色体其实是交叉的一部分,本小节聊更后面的步骤:得到父辈染色体后如何生成新的染色体?在1.2节中,这样描述该过程:“交叉的过程需要从上一代的染色体中随机寻找两条染色体,然后将这两条染色体通过一些算法生成新的染色体(比如有单点交叉、双点交叉、顺序交叉等,不同的应用场景可能会使用不同的交叉算法”。
在本章探讨的调度问题中,我们不需要考虑每个基因的唯一性:基因之间是可以重复的,或者说不同的任务是可以分配给同一个服务器节点的。(不过可能其它的应用问题并不是这样,比如后面章节将要讨论的旅行商问题。)。不需要考虑每个基因的唯一性可以使我们这里设计交叉算法时选择更多。本次我在代码中使用了最简单的单点交叉方法:

图3.3 单点交叉算法模块
实现很简单:我们在随机选择一个任务点,然后把父染色体在该节点前面的部分给到子染色体,把母染色体该节点后面的部分给到子染色体,便可以得到(生成)一条拼接好的新的染色体。
3.3.3 如何变异
在1.2节中对变异部分的描述为:“变异的方法:对于前述交叉过程生成的染色体,我们可以适当地(这里牵扯到一个叫变异率的参数设置问题:如果对每条交叉后的染色体进行变异其实很难收敛的,所以选择其中的多少条进行变异,是一个需要考虑的问题)选择其中的几条,在这些染色体上随机选择若干个基因,然后随机修改基因的值(变异的方法有很多,如:位翻转突变、交换突变、反转突变、倒换突变等”。
同样,调度问题不考虑各基因的不可重复问题,所以方法的选择上更加灵活,本次我在代码中随机选择了其中一个基因进行突变:

图3.4 变异模块代码
代码中muteNum对应在预设的变异率下计算得到的我们应该设置多少条需变异的染色体,staynum表示我们需要从上一代复制多少条染色体,这些染色体不参与变异。然后我们从新生成的染色体中去挑选一条染色体,并随机选择其一个基因,将之变成随机的另外一个基因。
3.4 求解结果
本次仿真中,预设了10个任务,5个服务器节点,每个任务的长度Task为在[1 20]内随机生成,每个服务器节点的速度Nodes在[1 10]内随机生成,预设染色体数100条,预设变异率为0.02,预设迭代次数为100次,预设每次从上一代中直接复制的染色体数10条。
得到的仿真结果如下:
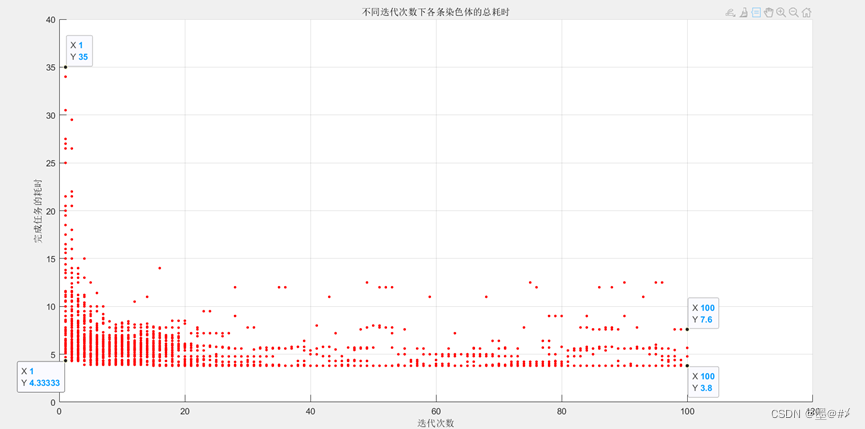
图3.5 每次迭代下每条染色体的耗时
如果我们从每次迭代的结果中选择耗时最少的那条染色体作为我们的最终解,其实可以看到在经过8次左右的迭代后就已经有很接近最终耗时3.8的染色体产生了。
3.5 小结与思考
本章按照第二章所给算法流程的指导,对基于遗传算法解决调度问题完成了全流程的仿真实践和部分算法模块的细节刨析,调度问题算是遗传算法应用领域中相对简单、用作入门和熟悉该算法比较合适的一个方向,希望本章的工作内容可以对读者有所帮助。
此外,在解决该问题的流程中,其实还有诸多的细节可供思考:比如,1、变异率设置成多少可以更快速地完成迭代? 2、变异的过程中如果多点变异是否会加速迭代? 3、交叉时对父辈染色体的选择中,我们如果只从概率低的(K-staynum)条染色体中进行选择(因为前staynum条染色体我们会直接复制给下一代),对迭代的影响是什么?4、有无其它更优的父辈染色体选择算法、交叉算法?等等。 这些问题都是很有意思的研究方向。
四、基于遗传算法求解旅行商问题
考虑到第三章中我已经给出了诸多细节,且在理解第三章调度问题的基础上再对后续应用问题进行理解时应该更简单了,所以第四章以及后续可能增加的各类应用问题的实践,我将主要介绍重点&区别点。
4.1 问题描述
旅行商问题是一个十分经典的问题(于我而言在接触遗传算法前我就有了解过)。该问题的描述很简单:旅行商问题(Travelling Salesman Problem, 简记TSP,亦称货郎担问题):给定一系列城市和每对城市之间的距离,求解访问每一座城市一次并回到起始城市的最短回路。[在基于遗传算法解决该问题时,我们需要时刻注意:每座城市只访问一次!]
4.2 问题建模及参数预设
问题建模:我们已知有N座城市,以及每座城市的坐标CityX = [CityX(1),CityX(2),… CityX(N)]、CityY = [CityY(1),CityY(2),… CityY(N)]。我们可以构造两两城市之间的相对距离矩阵:
![]()
(4-1)
表示第i个城市与第j个城市之间的相对距离。该矩阵的大小为N*N。
初始化染色体:我们预设初始染色体数(或者常说的初始种群数)为K,因为每条染色体对应一个可行解,所以容易理解的是:每条染色体是一个长度为N的一维向量:A = [A(1),A(2),… A(N)],向量中的每一个元素A(n)对应一个基因,其物理意义是我们的旅行商在第n次访问的城市。我们可以基于随机分配的方法完成对K条染色体的初始化,此时我们可以得到一个染色体对应的矩阵,其大小为:K*N。不过需要注意的是:每条染色体中的各个基因都有唯一性!
设计适应度函数:在本问题中,容易想到可以用每条染色体对应的总距离来构建适应度函数:
RangeSum(k) = sum(从城市1到城市2的距离 + 从城市2到城市3的距离 + … +从城市N到城市1的距离) (4-2)
我们对K条染色体分别求其所需的总距离时间(求解过程中我们可以从前面的DistanceMatrix矩阵中查找相对距离),最终可以得到一个长度为K的一维向量:DistanceSum = [DistanceSum (1), DistanceSum (2),… DistanceSum (K)],向量中的每个值对应第k条染色体所走的总路程。需要注意的是:在该任务中,距离越短对应的任务分配(染色体)越优,其适应度也越高,所以这里我们可以对总距离取倒数得到每条染色体的适应度:
Adaptability = 1./ DistanceSum (4-3)
得到适应度后,求每条染色体在交叉时被挑选的概率就简单多了:
SelectionProbability = Adaptability(k)/(sum(Adaptability)) (4-4)
在完成上面的准备工作后,我们可以进入迭代部分。
4.3 求解过程几个核心代码模块解读
4.3.1 如何交叉
旅行商问题和前面调度问题的一个主要区别点在于:旅行商下染色体每个基因是各不相同的。所以不能用之前3.3.2节中的单点交叉来实现:因为不能保证父染色体在交叉点前面的基因与母染色体在交叉点之后的基因之间不存在重复。本代码中我选择了顺序交叉算法来实现:

图4.1 顺序交叉的实现
这里实现交叉的思路是:首先随机找一个交叉点,然后我们把父染色体该交叉点前面的基因全部赋值为子染色体,对于子染色体该交叉点往后的基因,我们对母染色体进行遍历,如果有发现子染色体中还没有的基因,就把该基因附在子染色体后面,直至该子染色体的长度为N。
4.3.2 如何变异
同样的理由:旅行商问题下染色体每个基因是各不相同的。这里的变异我们随机选择两个基因进行位置调换来完成变异。

图4.2 变异算法模块
muteNum为基于预设的变异率得到的变异染色体数目。该模块很简单:随机选择一条染色体、随机选择这条染色体不同的两个基因进行互换。
4.4 求解结果
本次仿真中,预设了10个城市,每个城市的横纵坐标为在[1 100]内随机生成,预设染色体数10条,预设变异率为0.02,预设迭代次数为100次,预设每次从上一代中直接复制的染色体数2条。
得到的仿真结果如下:
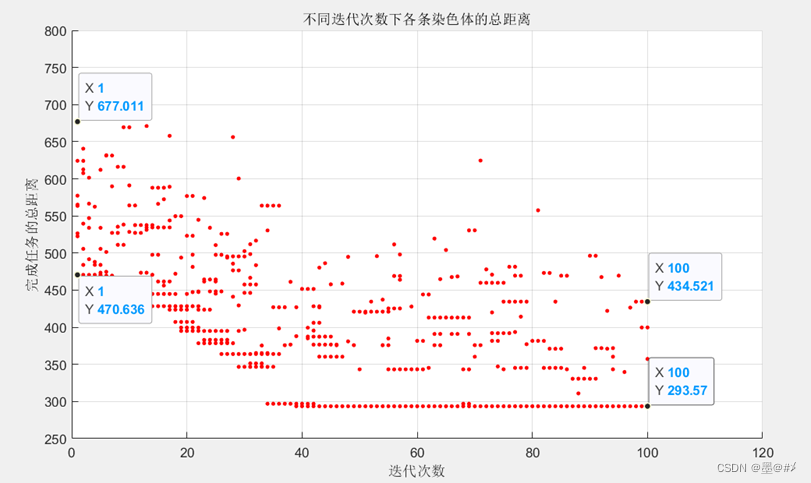
图4.3 不同迭代次数下,各染色体下的总距离
可以看到随着迭代次数的增加,每次生成的染色体对应的总距离整体都在往下移。此外,我选择了初始化时以及迭代100次后总距离最近的染色体对应的路径画图如下:
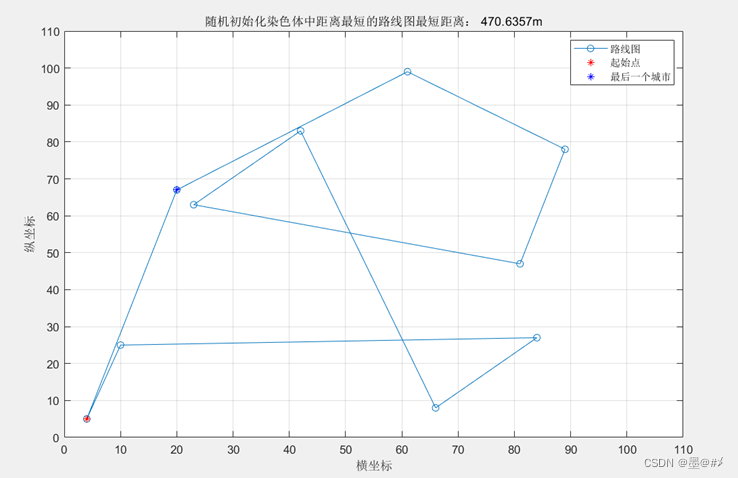
图4.4 初始化染色体中总距离最短的路径选择
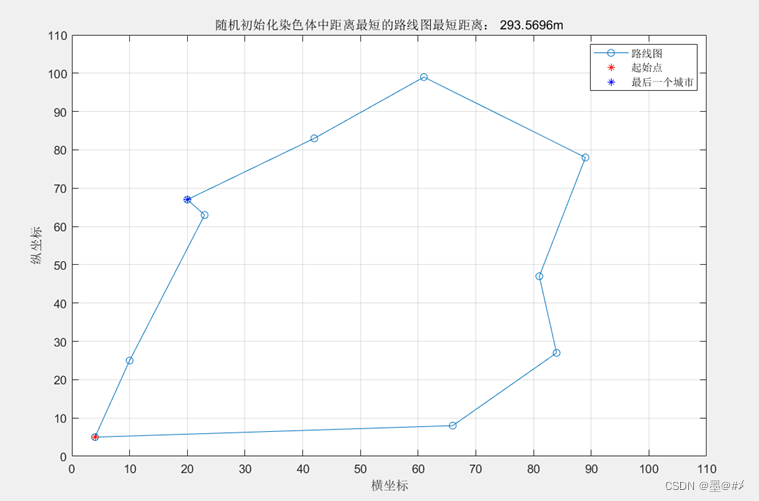
图4.5 迭代100次时所生成的染色体中总距离最短的路径选择
4.5 小结与思考
本章基于遗传算法解决对旅行商问题进行了全流程的仿真实践和部分算法模块的细节刨析,旅行商问题是很经典的组合优化问题,其在运筹学和理论计算机科学中都非常重要。希望本章的工作内容可以对读者有所帮助。
在3.5节中,我抛出了几个在求解过程中比较有意思的几个细节问题,这里再补充两个:1、我们初始化的染色体数量对于迭代的收敛速度有哪些影响? 2、我们设置的直接从上一代复制的染色体数占整体的比率多高时进化的效果更好?
五、其它应用问题
我本来想把基于遗传算法优化波束形成也写进本博文的,但是写到这里看到内容似乎已经够多了。后续基于遗传算法的来解决其它问题的实践,我会将新写的博文以链接的形式附在本章。
六、总结
本博文对遗传算法做了系统性&细节性介绍:包括其相关概念、经典的处理流程等。并以调度问题、旅行商问题作为研究对象,探讨了如何使用遗传算法解决这两个问题(截止2024.3.15)。如前文说明部分所述:最近在看波束形成相关内容时了解到可以用这个算法来优化阵元激励以压低旁瓣,便特地了解和学习了一下这个算法,觉得蛮有意思的,于是把这两天关于该算法的学习和实践的内容总结成了一篇博文。我后续会不定期新增遗传算法在信号处理、自动驾驶、以及人工智能等方向的应用实践示例。
七、参考资料
[1] 10分钟搞懂遗传算法(含源码) - 知乎 (zhihu.com)
[2] 遗传算法中常见遗传算子 - 知乎 (zhihu.com)
八、代码参考
本博文的仿真代码如下(包含.m和.txt版本):
遗传算法及基于该算法的典型问题的求解实践博文对应的代码(Matlab)资源-CSDN文库