VGG网络的程序实现完全根据配置表来实现。
全连接层之前的部分属于特征提取部分,后三部分全连接层用来分类。
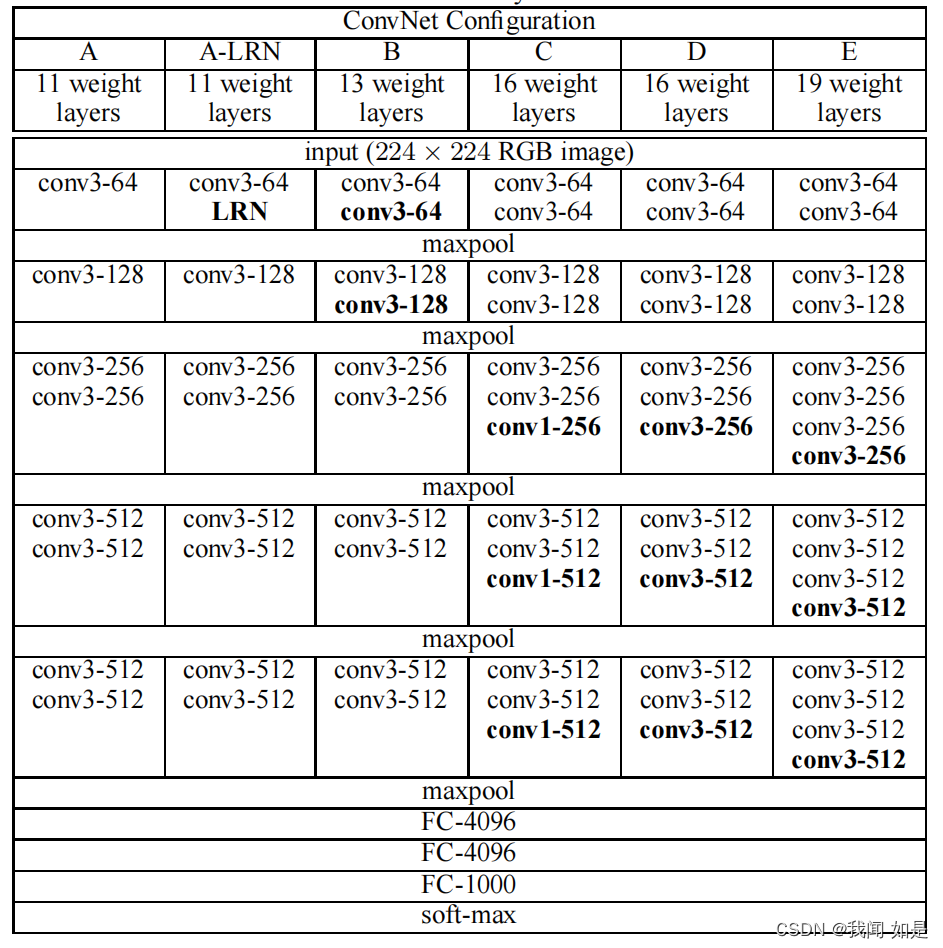
1、模型
import torch.nn as nn
import torch# official pretrain weights
#预训练的权重下载地址
model_urls = {'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth','vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth','vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth','vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}#进行分类的代码
class VGG(nn.Module):def __init__(self, features, num_classes=1000, init_weights=False):super(VGG, self).__init__()self.features = featuresself.classifier = nn.Sequential(nn.Linear(512*7*7, 4096),nn.ReLU(True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(p=0.5),nn.Linear(4096, num_classes))if init_weights:self._initialize_weights()def forward(self, x):# N x 3 x 224 x 224x = self.features(x)# N x 512 x 7 x 7x = torch.flatten(x, start_dim=1)# N x 512*7*7x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')nn.init.xavier_uniform_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)# nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)#进行特征提取部分的代码
def make_features(cfg: list):layers = []in_channels = 3for v in cfg:if v == "M":layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)layers += [conv2d, nn.ReLU(True)]in_channels = vreturn nn.Sequential(*layers)cfgs = {'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}def vgg(model_name="vgg16", **kwargs):assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)cfg = cfgs[model_name]model = VGG(make_features(cfg), **kwargs)return model定义了VGG11、VGG13、VGG16和VGG19。调用的时候只需要输入模型名字就可以。比如model=vgg("vgg16")
2、预处理
data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]),"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])}3、数据集及可视化
数据集使用的是眼睛疾病的数据集,分别包括四类:cataract(白内障)、diabetic_retinopathy(糖尿病性视网膜病变)、glaucoma(青光眼)、normal(正常)。
可视化:
代码:
fig = plt.figure()for i in range(4):plt.subplot(1,4,i+1)# plt.tight_layout()# plt.imshow(test_image[i][0],cmap='CMRmap', interpolation='none')plt.imshow(test_image[i][0])# plt.title("Ground Truth: {}".format(test_label[i].item()))plt.xticks([])plt.yticks([])plt.show()输出: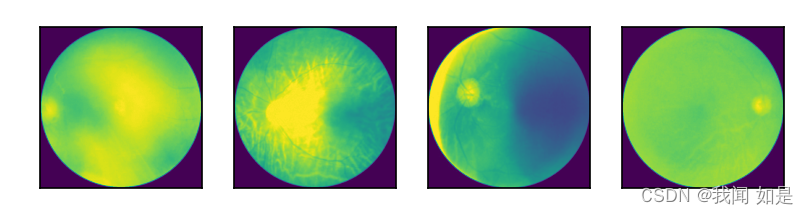
4、加载数据:
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root pathimage_path = os.path.join(data_root, "data_set", "flower_data") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])train_num = len(train_dataset)# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}flower_list = train_dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json filejson_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)batch_size = 32nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=batch_size, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))5、加载模型
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)6、损失函数:
loss_function = nn.CrossEntropyLoss()7、优化器:
optimizer = optim.Adam(net.parameters(), lr=0.0001)8、迁移学习
#迁移学习model_weight_path = "./vgg16-pre.pth"assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)net.load_state_dict(torch.load(model_weight_path, map_location='cpu'),False)for param in net.parameters():param.requires_grad = Falsen_inputs=net.classifier[6].in_featureslast_layer=nn.Linear(n_inputs,4)net.classifier[6]=last_layer9、训练:
epochs = 30best_acc = 0.0save_path = './{}Net.pth'.format(model_name)train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = net(val_images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')
结果:
对vgg11、vgg13、vgg16、vgg19分别进行测试。
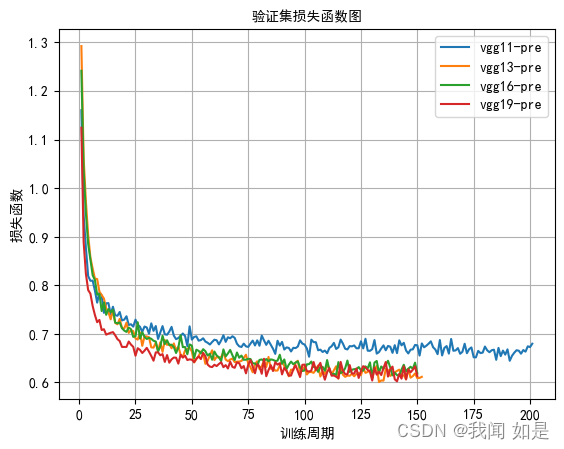
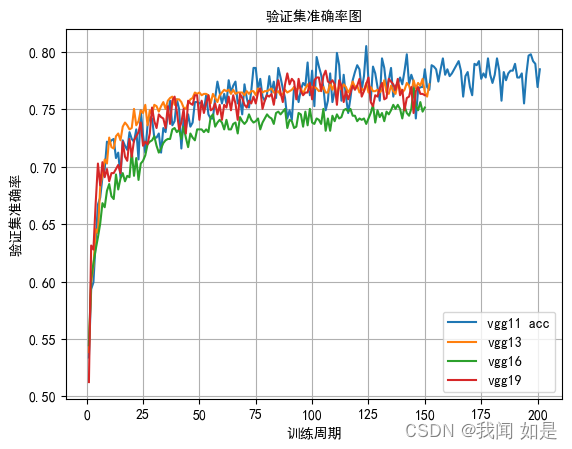
vgg模型训练的时间都比较长,从损失值看vgg19效果好一些。从精度上看,vgg13、vgg11、vgg19都有不错的精确率。
完整代码:
import os
import sys
import jsonimport torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdmfrom model import vggdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root pathimage_path = os.path.join(data_root, "data_set", "flower_data") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])train_num = len(train_dataset)# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}flower_list = train_dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json filejson_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)batch_size = 32nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=batch_size, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))# test_data_iter = iter(validate_loader)# test_image, test_label = test_data_iter.next()model_name = "vgg16"net = vgg(model_name=model_name, num_classes=5, init_weights=True)net.to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0001)epochs = 30best_acc = 0.0save_path = './{}Net.pth'.format(model_name)train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = net(val_images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()
参考资料:
在Pytorch中使用VGG16进行迁移学习-CSDN博客




)




)
—— 认识C++语言)
)







)