博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、Python技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
1 简介
基于Python flask 的豆瓣电影排行榜,豆瓣电影评分可视化,豆瓣电影评分预测系统,本系统包括了影视系统的爬虫与分析。通过采用Python编程语言,使用flask框架搭建影视系统,并使用相关技术实现对豆瓣网站的爬取、数据存储和可视化分析,可以更好地了解影视市场的状况和人们对影视的喜好,为影视制作和推广提供参考。
具体来说,通过编写爬虫程序,采集豆瓣网站上影视的相关信息,并将这些信息存储到数据库中。然后,我们使用Python中的数据分析工具,如pandas、matplotlib等,对数据进行可视化分析,以便更好地了解影视市场的现状和人们对影视的喜好。最后,我们将分析结果呈现在Web界面上,使用户可以更加直观地了解影视市场和人们对影视的评价,从而更好地了解影视市场的趋势和人们的需求。
2 技术栈
- 开发语言:Python
- 后端框架:flask、爬虫
- 前端:html
- 数据库:Sqlite
- 系统架构:B/S
- 开发工具:pycharm
具体实现
1.设计豆瓣电影自动化爬虫程序,自动获取电影数据
其中需要设计一个自动化的爬虫程序,对于豆瓣网站,因为它的反爬措施比较严格,电影页面的数据是采用动态加载的原理进行展示的,初步分析需要采用JSON数据获取豆瓣电影的URL,然后通过请求到具体的电影页面在进行解析和定位具体的电影字段数据。
获取数据的时候,需要模拟浏览器对网站进行请求,需要加入请求头,然后分析不同JSON数据包中的参数,发现具体的规律之后可以设置对应的程序进行获取数据集。如果IP频繁的访问网站不仅会给目标网站带来负载压力,还会被网站识别为恶意爬虫,所以设计爬虫程序的时候需要加入延时函数,采用正态分布的思想模拟人的速度点击和访问网站的频率,可以增强爬虫的稳定性。
其次由于有时候获取数据的时候,会有有一些字段在某些电影中不存在,所以为了保障程序的稳定健壮的持续运行,需要设置智能化爬虫。初步的分析需要对字段的数据值进行一个判断,如果没有获取到数据,那么就自动赋值为空值,这样就可以避免程序中断。
2.对爬取到的数据进行清洗和预处理,包括多维度数据字段清洗和扩充
由于我们获取的大量的数据中,存在一些不规则的字段,比如演员、上映时间、电影时长等这些字段中包含其他的中文字符,我们需要对其进行结构化清洗,保证数据的有效性,便于后续的分析,其次数据中存在一些空值,需要进行处理,然后将其保存为一个新的数据。
其次,在处理时间字段的时候,将中文字段去除之后,然后对数据字段进行扩充,比如年、月、日、周数等,可以方便后续的数据分析,增加分析的维度,保障数据的有效进行。
3.将清洗好的数据存储到Sqlite数据库中
将预处理好的数据存入在MySQL中,便于后续的管理和调用数据,MySQL作为一个结构化的数据库,可以存储大量的数据,并且可以帮助我们采用SQL语句进行查询和数据分析,具有非常高效的特点。
4 具体效果图
首页/电影排行榜
top 电影评分分布

top 电影词云图

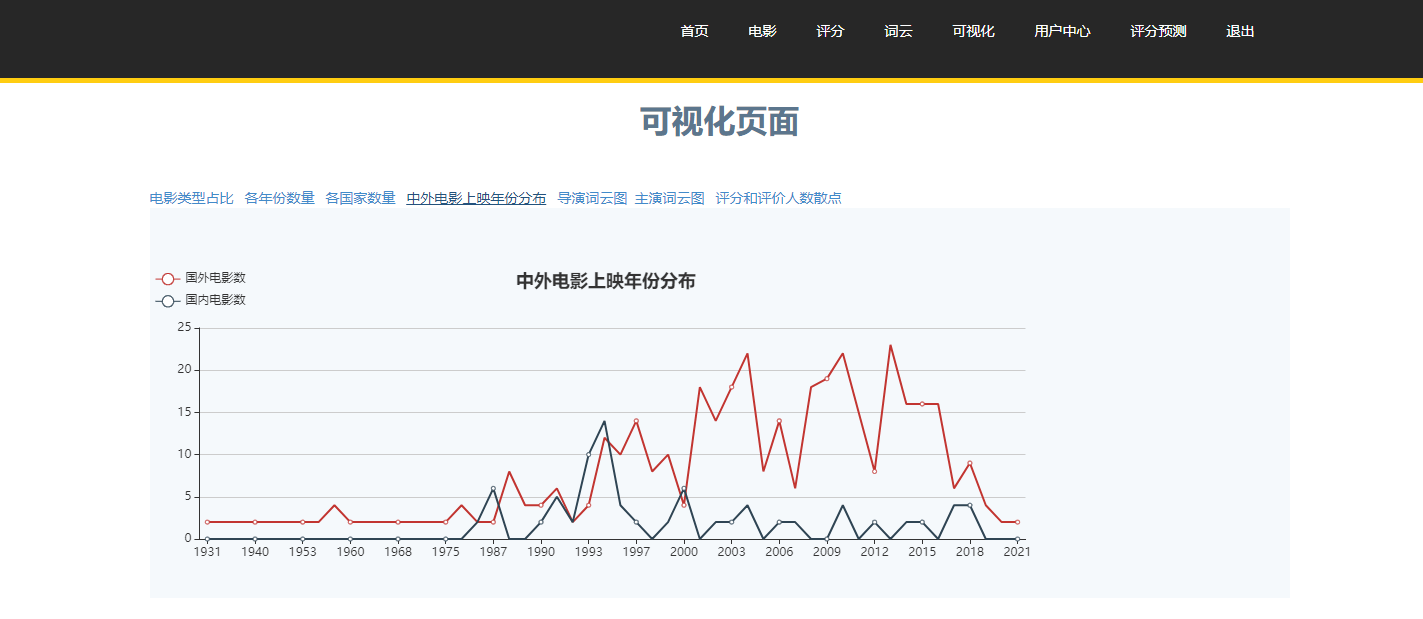
各种可视化

评分预测

5 推荐阅读
基于Python的豆瓣电影排行榜,可视化系统
基于 Python 的个性化电影推荐系统的研究与实现
基于微信小程序的校园失物招领平台的研究
Java 基于微信小程序的汉堡点餐系统的研究与实现
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
6 源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
)






)










的个人博客系统)
