wave
常见的语音信号处理python库有librosa, scipy, soundfile等等。wave库是python的标准库,对于python来说相对底层,wave不支持压缩/解压,但支持单声道/立体声语音的读取。
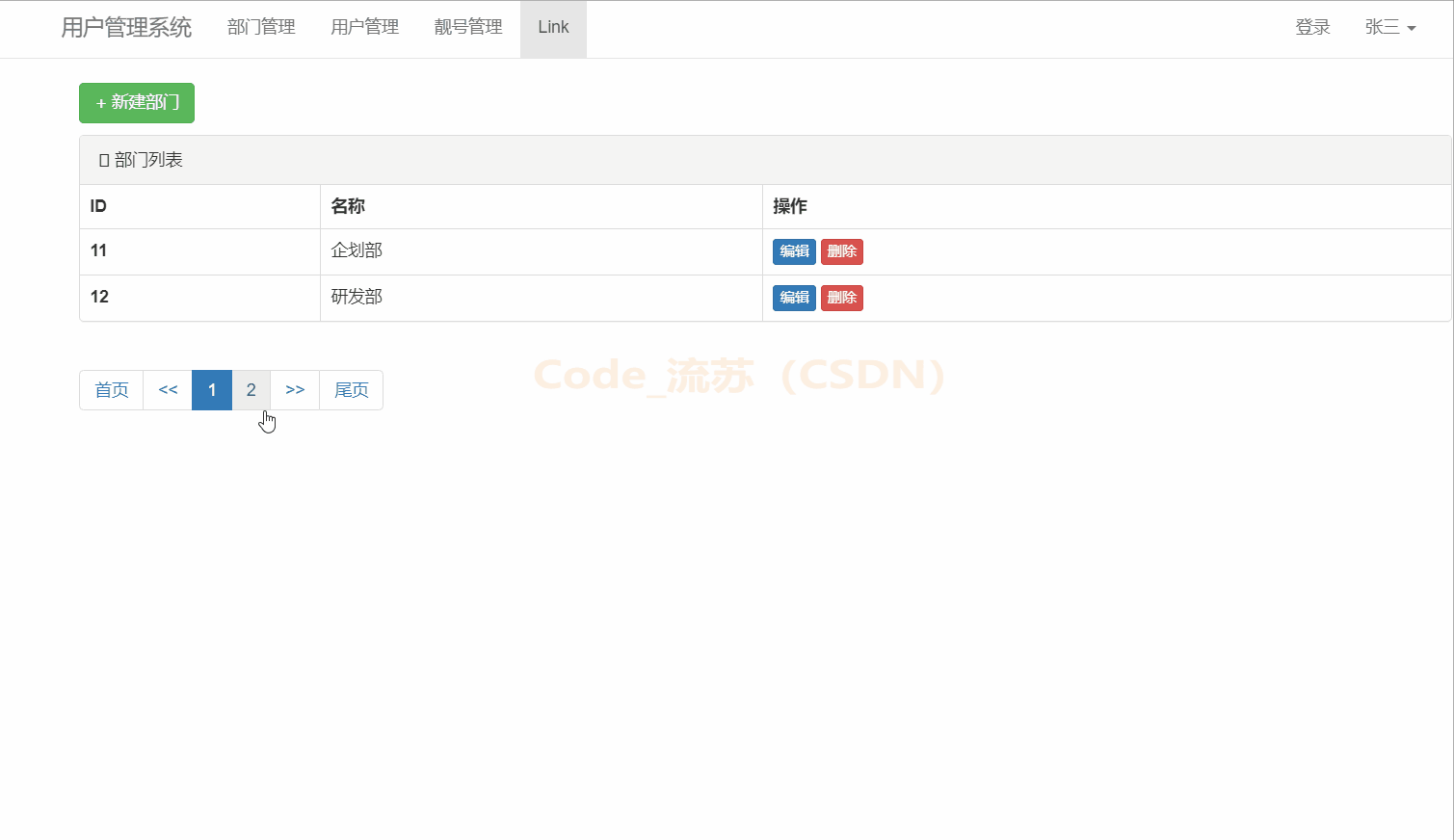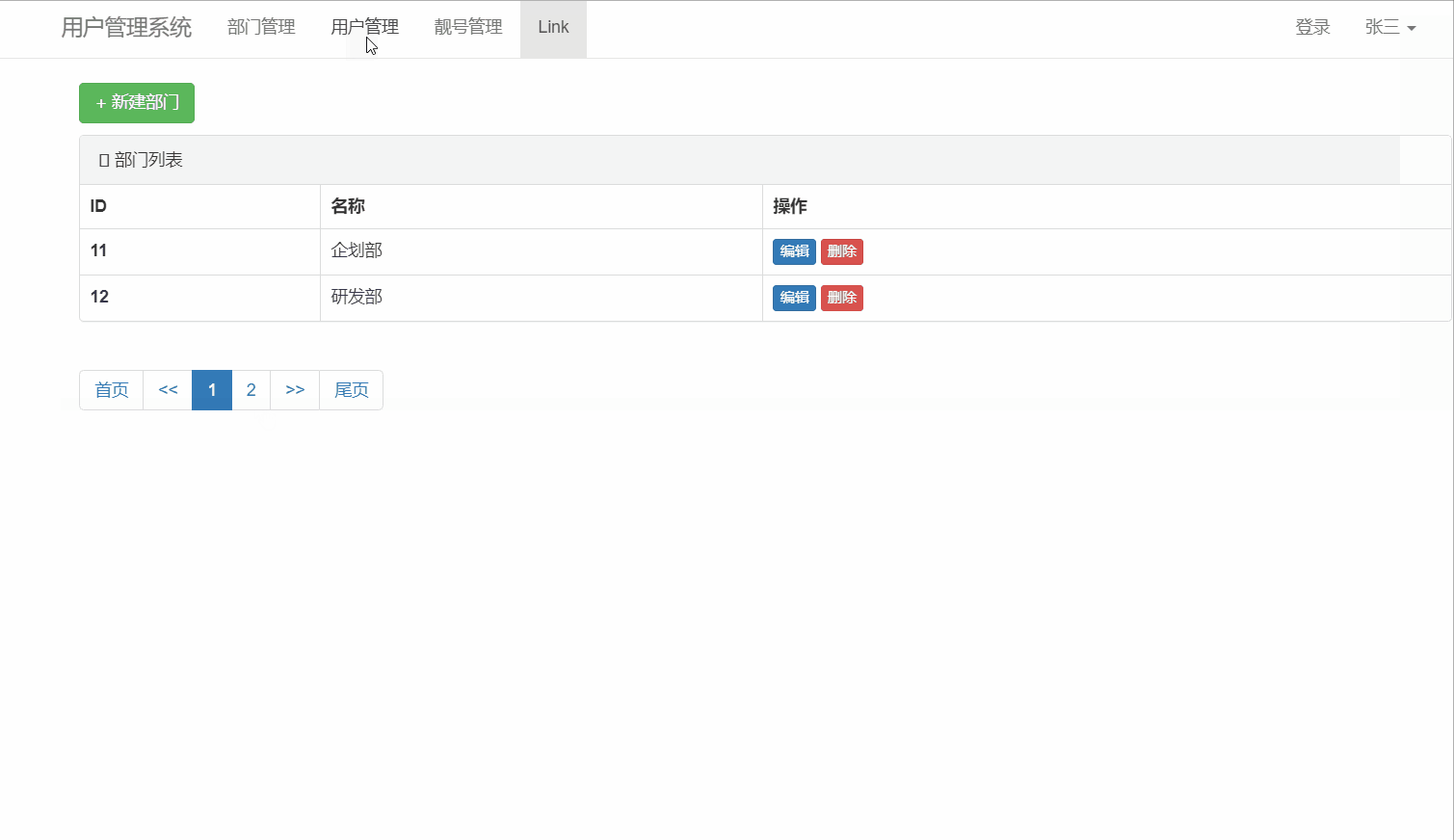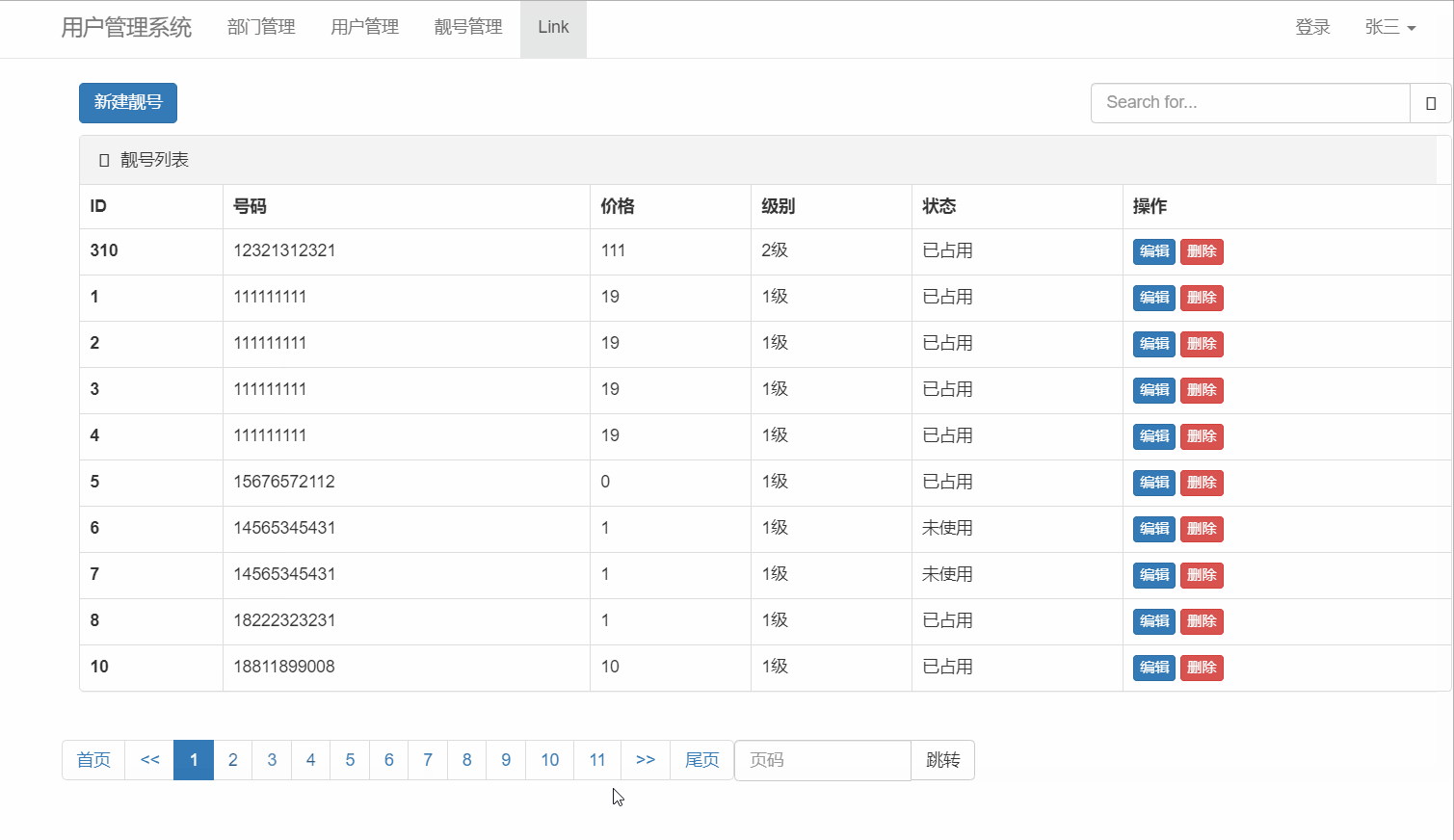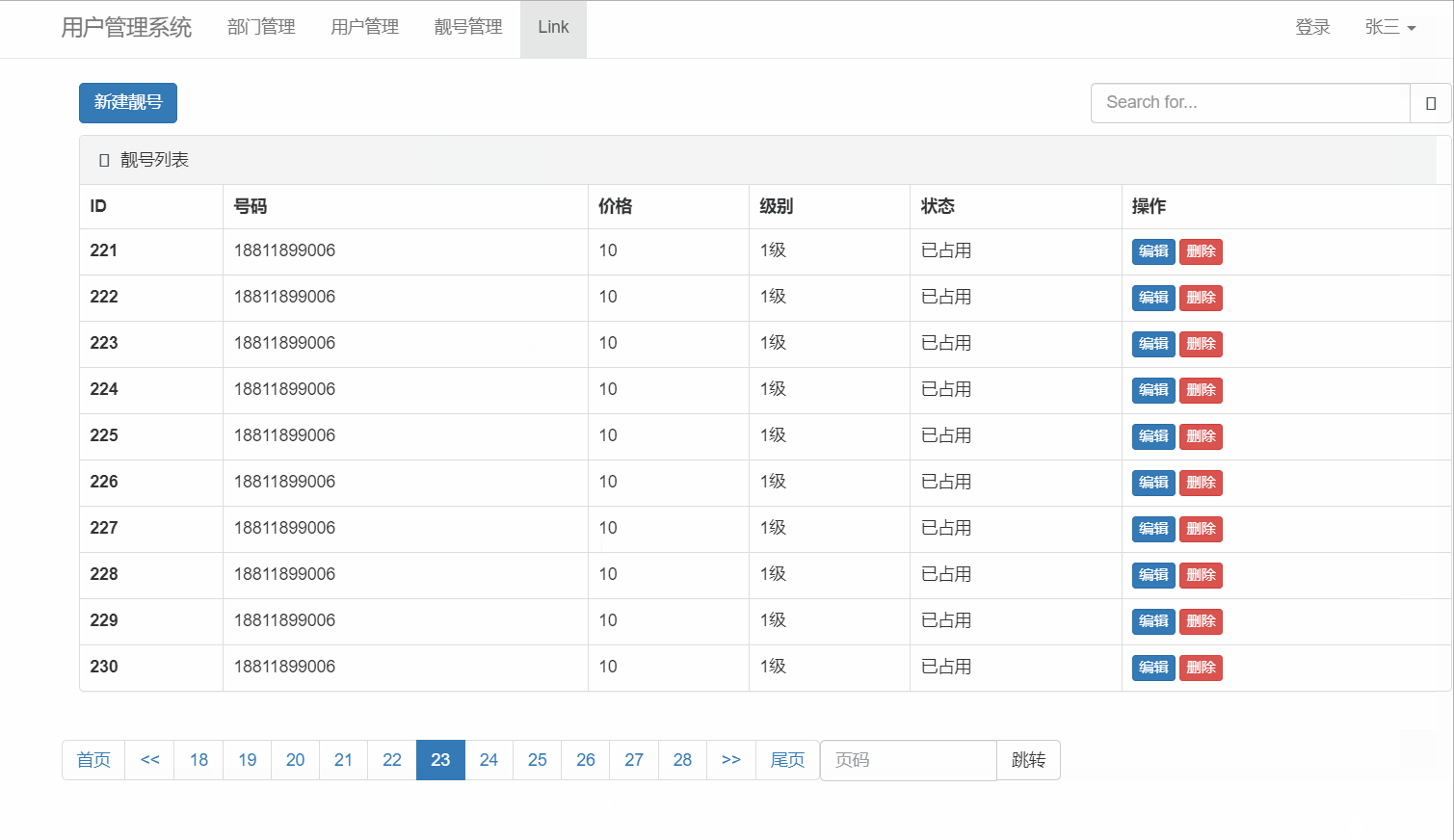
读取音频
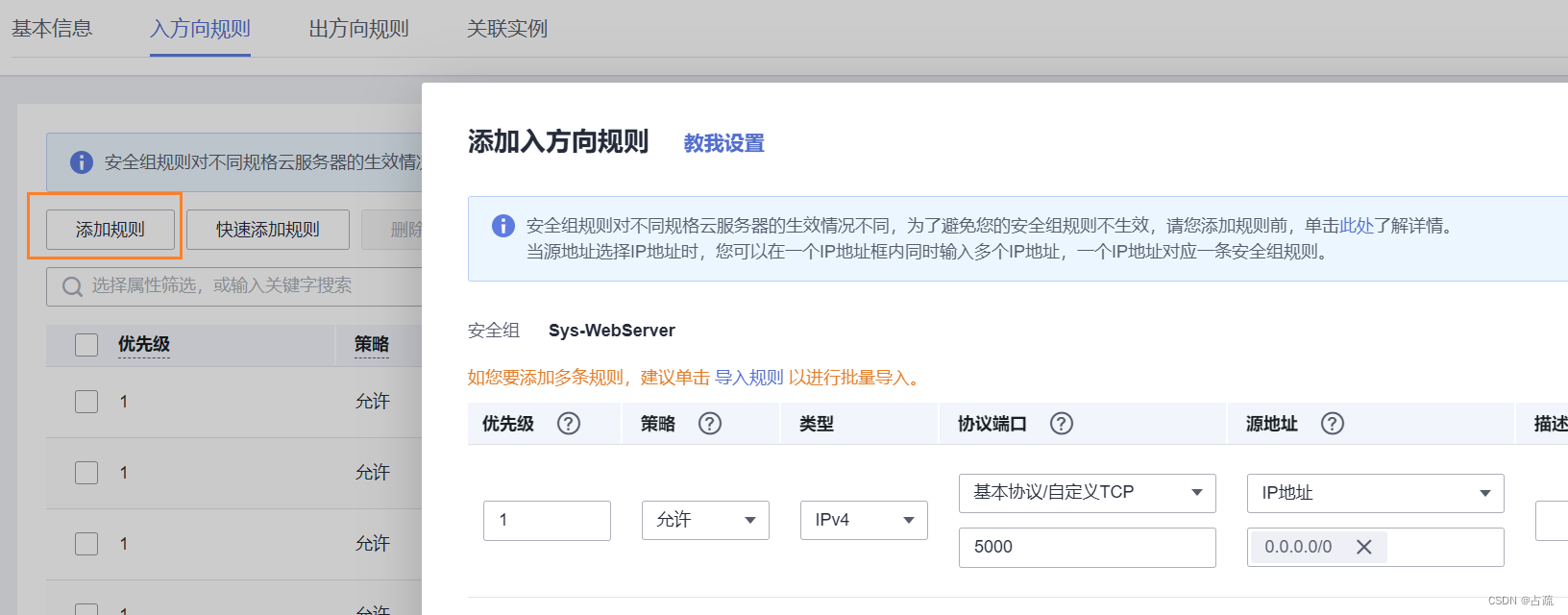
import wave #导入库file_path = 'D:/ba.wav' #文件路径
f = wave.open(file_path, "rb") #读取参数
params = f.getparams()nchannels, sampwidth, framerate, nframes = params[:4]
str_data = f.readframes(nframes)
f.close()audio_data = np.frombuffer(str_data, dtype=np.short)
audio_data1 = audio_data*1.0/(max(abs(audio_data)))#归一化到[-1,1]
time = np.arange(0, nframes) * (1.0 / framerate)
“WAV”格式文件由“fmt”和“data”,两个部分组成,其中“fmt”的存储块用来存音频文件的格式,“data”的存储块用来存实际的声音信息,物理上描述的振幅和时间:长度(时间)和振幅。
我们看看读取到的参数params:

里面包含6个子参数:
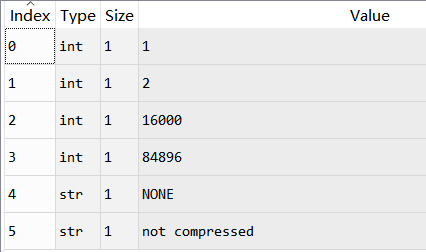
getparams()得到的params,返回6个参数分别是:(nchannels,sampwidth,framerate,nframe,comptype,compname)
- nchannels:返回音频通道的数量(单声道为1,立体声为2)。
- sampwidth:返回以字节为单位的样本宽度。(2字节byte)
- framerate:返回采样频率。
- nframe:返回音频帧数。(这里应该是点数,看后面解释)
- comptype:返回压缩类型(“ NONE”是唯一受支持的类型)。
- compname:压缩名称。
通过上面信息,我们知道该段音频的采样点数为84896,每点用2byte=16bit保存,那么需要84896*2=169792字节B。
换算单位:
1B(Byte 字节)=8bit,
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
即该音频大小为:169792/1024=165.81KB=0.16MB
注:
疑问:它的帧数是如何计算的?
这条语音长度是多少采样点?我们用librosa库读取音频,发现size和上面是一样的,所以nframe应该是语音采样点数。
data, sr = librosa.load(file_path, sr =None) #必须加sr =None,不然默认采样成22050

首先,可以看到audio_data的值是显示不出来的,进行如下操作:
y=np.asarray(audio_data,'int64')# 类型转换成int64
此时value处就有显示值了,画出来:
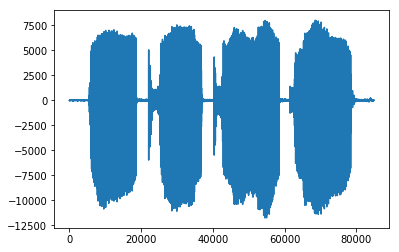
可以看到wavefile读出的数据是一个整型,没有做32767的归一化。
进行归一化:
audio_data1 = audio_data*1.0/(max(abs(audio_data)))#归一化到[-1,1]
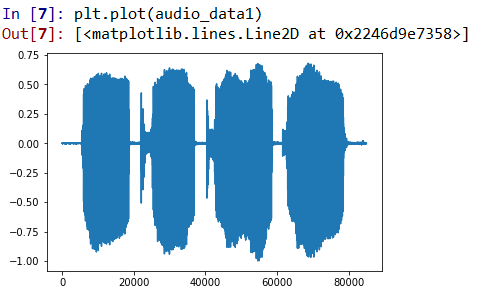
归一化后,和librosad读取出的数据的范围还是不一样。liborsa读取出来的数据,是做了32767的归一化。wavefile的归一化是除以最大值。
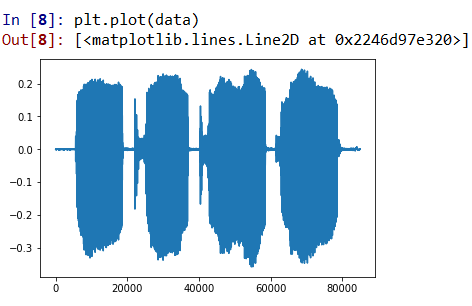
音频重采样
重采样到16000Hz
data = librosa.resample(data.astype(np.float32), fs, 16000) #注意一定要对数据做astype(np.float32),否则会出现下采样无效。
做完重采样后会出现最大值远大于32767的情况,因此需要注意,需要对其进行动态标准化,避免早保存时候出现溢出(np.int16的最大值是32767,多了会削波)。可以添加判断,np.max(abs(x_filted)) / np.max(abs(up_sample_data))