Node携手MongoDB探险旅行⛏️
本篇文章,学习记录于:尚硅谷🎢 文章简单学习总结:如有错误 大佬 👉点.
本篇不适合纯新手,因为本人已经使用很多数据库,很多数据库概念…就不会进行解释,请宝贝们~耐心观看📺
本篇文章并不深入MongoDB学习,仅仅是一个入坑小案例,并不会介绍MongoDB的索引、数据类型、等深入内容;
前置知识:需要掌握了解: JavaScript基础语法 、Node.JS环境API 、前端工程\模块化、Express… ….
作为一个Java程序员,我接触的数据库有: SQL_SERVER、Oracle、Mysql、达蒙、H|Gbase... 很多,且都应用适合不同场景;
-
在后端领域数据库的存在尤为重要,任何程序的增删改查,数据收集最终都会存储在数据库中. . . 可以说属于程序的核心存在;
-
在前端领域数据库的概念并不大,那么如果使用:
node+Express后端开发,应该使用什么呢❓ ——》》MongoDB ❗ ❗
MongoDB 概述:
MongoDB是一种流行的开源文档数据库,基于分布式文件存储的数据库;
是一个介于关系数据库和非关系数据库之间的产品,它属于NoSQL数据库的一种,由C++语言编写;
与传统的关系型数据库:MySQL、PostgreSQL... ,它不遵循传统的表格结构,类似json的bson格式 正因如此,对于JavaScript有天然的优势;
主要特点:
高性能: 设计追求高性能和低延迟,使用内存映射文件Memory-mapped Files 实现数据持久化,同时支持索引、查询优化等功能来提升性能;
可扩展性: MongoDB具有很好的水平扩展性,可通过添加更多的节点来扩展存储容量和吞吐量 支持分片Sharding水平拆分数据将其分布到多个节点上;
文档数据库: MongoDB存储的数据以文档的形式存在,以类似JSON的BSON (Binary JSON 格式存储,文档的灵活性使得数据模型可以更好适应程序需求;
灵活的数据模型: 与关系型数据库不同,MongoDB不需要严格的预定义模式,文档都可以根据需要包含不同的字段,这使得数据结构的变化更加容易应对;
强大的查询语言: MongoDB提供了丰富而灵活的查询语言,支持复杂的查询操作,包括范围查询、排序、聚合等;
分布式数据库: MongoDB是一个分布式数据库系统,可以部署在多个服务器上以实现高可用性和容错性;
社区支持和生态系统: 拥有庞大的社区支持,丰富的文档、教程和论坛、三方工具和库等资源;
核心概念:
Mongodb 中有三个重要概念需要掌握: 数据库、 集合、 文档 借鉴文章🔗
文档:
MongoDB中最小记录是一个文档,它是由{字段: 值} 组成数据结构,单|多个{键:值} 放在一起就构成了文档;
文档中的值支持多种数据类型:整型、布尔型等,也可以是另外一个文档,即文档可以嵌套,文档中的键类型只能是字符串;
集合:
MongoDB中集合就是一组文档,类似于关系数据库中的表:[ {字段:值},{字段:值},{.:.} ]
集合是无模式的,集合中的文档可以是各式各样的:键|值的类型不同,也可以存放在同一个集合中,即:不同模式的文档都可以放在同一个集合中
数据库:
MongoDB中多个文档组成集合,多个集合组成数据库:{ [{字段:值}],[{字段:值}] }
一个MongoDB实例可以承载多个数据库,它们之间可以看作相互独立,每个数据库都有独立的权限控制,磁盘上:不同的数据库存放在不同的文件中
数据模型:
一个MongoDB 实例可以包含一组数据库,
一个DataBase(数据库)可以包含一组Collection(集合),
一个Collection(集合)可以包含一组Document(文档),一个Document(文档)包含一组field字段,每一个字段都是一个k:v 下列一个DEMO👇
{"accounts": [{ "id": "3-YLju5f3", "title": "买电脑", "time": "2023-02-08", "type": "-1", "account": "550", "remarks": "为了上网课" },{ "id": "3-YLju5f4", "title": "请吃饭", "time": "2023-02-08", "type": "-1", "account": "540", "remarks": "情人节聚餐" }],"users": [{ "id": 1, "name": "zhangsan", "age": 18 },{ "id": 2,"name": "lisi", "age": 20 }]
}
- 假设一个记账流水的一个数据库:
accounts、users分别是两个集合存储了:流水记录、用户信息的文档集合;
MongoDB 安装 :
网络上有许多 MongoDB 的教程,本篇就不过多介绍了:MongoDB下载地址
推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB
MongoDB服务端可运行在Linux、Windows平台,支持32位和64位应用,默认端口:27017 配置步骤👇
-
MongoDB官网下载:zip压缩包
通用性更强; msi安装则直接无脑下一步安装即可; -
将压缩包解压—至—安装目录,手动创建 data 和 log 两个文件夹
不要使用中文路径,配置环境变量: Path 盘符\解压路径\bin -
在data的目录下,创建一个db文件,因为启动 MongoDB 服务之前需要必须创建数据库文件的存放文件夹,命令不会自动创建,启动失败;
🆗 很简单吧,没看明白?好吧举个栗子》 安装目录在:D:\CodeWord\MongoDB
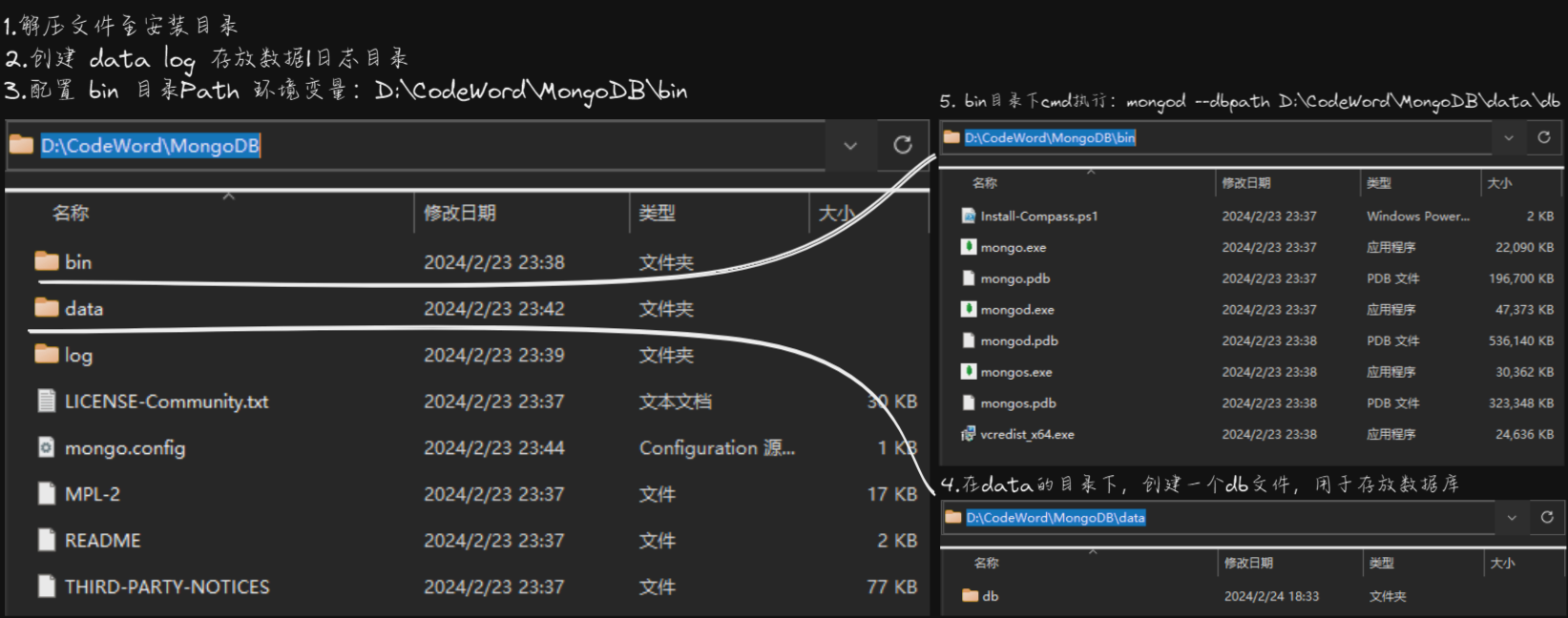
# bin目录下:启动mongodb服务,并指定数据库目录;
mongod --dbpath D:\CodeWord\MongoDB\data\db# 浏览器URL:测试服务启动成功
http://localhost:27017/# bin目录下:启动客户端
mongo.exe #用于输入MongoDB命令;
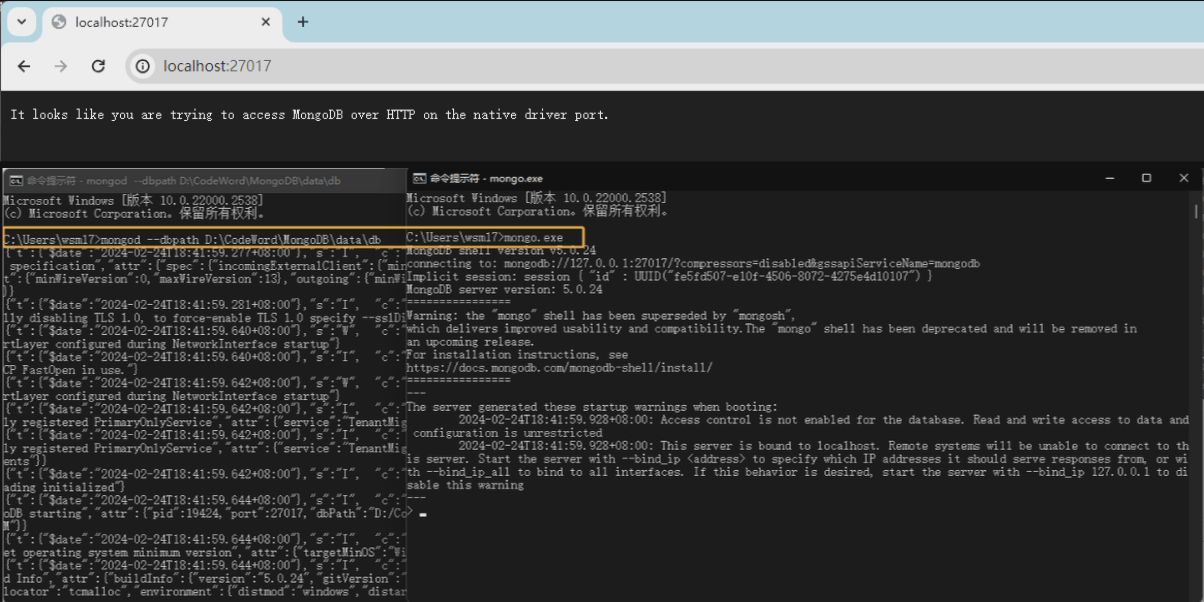
👌如此一个简单 MongoDB就安装部署好了
MongoDB常用命令:
MongoDB 命令行中执行命令严格区分大小写 此处介绍一些简单的命令,更多命令操作学习可以关注:MongoDB 手册
数据库命令:
| 命令 | 描述 |
|---|---|
| show dbs | 显示当前MongoDB实例中的所有数据库列表,如果库中没数据则不会展示; |
| use 数据库 | 切换到指定名称的数据库,如果不存在则自动创建 |
| db | 显示当前所在的数据库,初使数据库test 不建议操作 |
| db.stats() | 返回当前数据库的统计信息,如数据大小、集合数量等 |
| db.dropDatabase() | 删除当前数据库,默认最上层数据库test 无法删除,删除操作前注意db 查看所在数据库; |
集合命令:
| 命令 | 描述 |
|---|---|
| show collections | 显示当前数据库中所有集合列表 |
| db.集合名.drop() | 指定存在的 集合名 删除指定集合 |
| db.createCollection(‘集合名’) | 创建一个新的集合,参数指定集合名称 |
| db.集合名.renameCollection(‘新集合名’) | 重命名集合,指定存在的 集合名 并设置新的名称 |
文档命令:
| 命令 | 描述 |
|---|---|
| db.集合名.find([查询条件]); | [可选,查询条件],如果没有查询条件则直接查询全部,条件则是一个{key:'v'} |
| db.集合名.insert({文档对象}); | 向指定集合中插入一个文档对象:{key:'value',key2:'value'} _id 是 mongodb 自动生成的唯一编号,用来唯一标识文档 |
| db.集合名.update({查询条件},{新的文档}) db.集合名.update({查询条件},{$set:{修改的文档属性}}) | 根据查询条件,更新匹配的文档,默认全替换 全替换:新文档完全覆盖之前文档,可以通过 $set:{k:'v'} 指定修改文档属性; |
| db.集合名.remove({查询条件}); | 根据查询条件,删除匹配的文档对象 |
下面是一个简单的代码案例:
> db #查看当前所在数据库,初始数据库test
test
> show dbs #查看当前所有数据库,没有数据则不会显示
admin 0.000GB #默认数据库,管理所有数据库权限
config 0.000GB #默认数据库,存储本地服务器信息
local 0.000GB #默认数据库,内部数据库,用于保存分片信息
> use wsm #切换到指定名称的数据库,如果不存在则自动创建
switched to db wsm
> db.createCollection('wlist'); #在当前数据库下创建一个新的集合,参数指定集合名称 wlist
{ "ok" : 1 }
> show dbs #查看当前所有数据库,并发现新增的数据库 wsm
admin 0.000GB
config 0.000GB
local 0.000GB
wsm 0.000GB
> show collections #显示当前数据库中所有集合列表 wlist
wlist
> db.wlist.renameCollection('newWlist') #根据集合名重命名集合: wlist => newWlist
{ "ok" : 1 }
> show collections ##显示当前数据库中所有集合列表 newWlist
newWlist#指定集合并新增集合数据
> db.newWlist.insert({name:'wsm',age:18,status:true})
> db.newWlist.insert({name:'wss',age:18,status:true})
> db.newWlist.insert({name:'540',age:20})#查询集合数据,没有查询条件则直接查询全部,根据条件查询
> db.newWlist.find();
{ "_id" : ObjectId("65ec8dd942cf5007e0c707af"), "name" : "wsm", "age" : 18, "status" : true }
{ "_id" : ObjectId("65ec8e1342cf5007e0c707b0"), "name" : "wss", "age" : 18, "status" : true }
{ "_id" : ObjectId("65ec8e3842cf5007e0c707b1"), "name" : "540", "age" : 20 }
> db.newWlist.find({name:'wsm'});
{ "_id" : ObjectId("65ec8dd942cf5007e0c707af"), "name" : "wsm", "age" : 18, "status" : true }#根据查询条件,更新匹配的文档,默认全替换,可以通过 $set:{k:'v'} 指定修改文档属性;
> db.newWlist.update({name:'wsm'},{age:19})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.newWlist.update({name:'wss'},{$set:{age:19}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })#根据查询条件,删除匹配的文档对象;
> db.newWlist.remove({name:'540'})
WriteResult({ "nRemoved" : 1 })#最后查看操作后端数据验证结果;
> db.newWlist.find();
{ "_id" : ObjectId("65ec8dd942cf5007e0c707af"), "age" : 19 }
{ "_id" : ObjectId("65ec8e1342cf5007e0c707b0"), "name" : "wss", "age" : 19, "status" : true }
find(条件,[查询列])
关于查询,是很多数据库最重要的一个操作,且操作复杂存在很多规则定义 MongoDB find(条件,[查询列])中主要分为两种:
查询条件: 通过查询条件规则,我们可以快速定位需要的数据;
| 条件 | 语法 |
|---|---|
| 查询所有的数据 | {} 不指定默认查询所有数据: |
查询匹配的数据 k=v | {k:'v'} 条件查询 k等v的数据进行返回,支持多个进行匹配 {k1:'v',k2:'v'} |
| 对于条件范围判断规则 | 除了支持数据类型的值全量匹配,还有对数值类型的范围判断匹配:$gt 大于 、$gte 大于等于 、$lt 小于、$lte 小于等于$ne 不等于、$in in多值匹配、nin not in匹配 |
要查询的列: 故名思意,数据查询过程中并不是需要所有的列进行展示;
| 查询的列(可选参数) | 语法 |
|---|---|
| 查询全部列 | {} 不指定默认查询所有数据列: |
只显示k列(字段 | {k:1} 通过列设置1,判断查询所需展示列,支持多个列设设置; |
除了k列(字段都显示 | {k:0} 通过列设置0,判断查询所不需展示的列,则没有设置0的都展示; |
#仅展示 name 和 age字段的查询
> db.newWlist.find({},{name:1,age:1});
{ "_id" : ObjectId("65ec8dd942cf5007e0c707af"), "age" : 19 }
{ "_id" : ObjectId("65ec8e1342cf5007e0c707b0"), "name" : "wss", "age" : 19 }#查询条件name=wss且age≥19的结果:
#_id字段默认设置1 可以通过设置不进行查询展示;
> db.newWlist.find({name:'wss',age:{$gte:19}},{_id:0,name:1,age:1});
{ "name" : "wss", "age" : 19 }
Mongoose 对象文档模型库:
Mongoose 是一个基于 Node.js 的对象数据模型ODM库 Mongoose中文网,它为 MongoDB 提供了一种模式化、文档导向的解决方案:
模式定义:通过 Schema 定义数据结构和类型,可以为 MongoDB 文档提供清晰的结构和验证
模型创建:Model 是基于 Schema 编译而来,代表数据库中的集合,用于处理数据库中的文档
文档操作:Document 表示集合中的单个文档,可以直接在文档上调用保存、查询、更新、删除等方法
中间件:Mongoose 允许你定义在操作过程中可应用的预处理和后处理逻辑
类型转换:自动将查询结果转换为 JavaScript 对象,方便操作
查询构建:提供链式查询构建器,使得构建复杂查询变得简单
安装 Mongoose
Mongoose本质就是一个NPM的工具包,可以帮助我们使用代码,快速高效的操作MongoDB数据库,🆗下面就让我们开始Mongoose的旅行吧!
初始化NPM项目,并安装 mongoose 依赖;
#npm初始化
npm init
#安装依赖包
npm i mongoose@6 #本篇文章是6.0.0版本,新版本修改了很多方法,请关注官方文档=>兼容了: promiss
Node+Mongoose 初始化
/**Mongoose初体验
* 1.初始化npm安装mongoose依赖 *///2.导入mongoose依赖
const mongoose = require('mongoose');//3.连接mongoose数据库服务
mongoose.connect('mongodb://127.0.0.1:27017/WSMM'); //mongodb协议://IP地址:27017(端口)/操作数据库(不存在自动创建)//4.on设置监听mongoose连接回调
//连接成功: 服务连接成功回调执行;
mongoose.connection.on('open', () => { console.log('连接成功'); });
//连接出错: 服务连接失败回调执行,可以通过修改端口验证,重启服务2分钟连接过程,未成功则连接失败;
mongoose.connection.on('error', () => { console.log('连接出错'); }); //可以在回调中设置重新连接|日志记录失败原因;
//连接关闭:
mongoose.connection.on('close', () => { console.log('连接关闭'); }); //当服务关闭执行回调函数;
once 绑定回调函数:
Mongoose绑定回调函数有两种形式:on、once 官方推荐once
- on 用于注册一个事件监听器,当指定的事件多次发生时,监听器会被多次调用
- once 也是注册一个事件监听器,但它只会在事件首次发生时被调用一次,之后即使事件再次发生,监听器也不会被触发
//4.once设置监听mongoose连接回调,once里的代码只会执行一次;
mongoose.connection.once('open', () => { console.log('连接成功'); });
mongoose.connection.once('error', () => { console.log('连接出错'); });
mongoose.connection.once('close', () => { console.log('连接关闭'); });
对于,一些程序在第一次连接成功就会进行一些启动服务的设置,on 可能会出现多次执行操作,所以建议使用 once避免重复的操作;
Mongoose 操作文档:
不同风格的人会有不同的写法: 此处仅仅是一个简单的介绍,当然也存在一些共同特征,想要使用Mongoose 操作文档必须操作:
- 定义 Schema:首先,你需要定义一个 Schema 来指定文档的结构
- 创建 Model:然后,根据 Schema 创建一个 Model,它代表数据库中的集合
为了方便操作数据库,通常操作文档定义在连接成功的回调函数中执行:
//设置监听mongoose连接回调
mongoose.connection.once('open', () => {//mongoDB连接成功//1.设置文档结构对象;const userSchema = new mongoose.Schema({name:String,age:Number,email:String,status:Boolean})//2.根据 Schema 创建一个 Model,它代表数据库中的集合const User = mongoose.model('User', userSchema ); //User表示文档对应的集合,如果库中不存在集合则创建;//最后操作完毕关闭数据库连接,释放资源;// mongoose.disconnect();
});
插入文档:
Model.create({new文档对象},[可选,回调函数]);
-
{new文档对象}: 要插入的文档对象或文档对象数组,如果是数组则批量插入
对于和文档结构对象不匹配的字段,默认无视不进行CRUD操作
与文档结构对象字段类型不匹配的值,则程序报错⚠️
-
[可选,回调函数]: 回调函数,
err异常返回对象,data操作成功返回插入的文档对象(mongoose默认设置_id唯一标识、__v系统维护的版本键
//设置监听mongoose连接回调
mongoose.connection.once('open', () => {//1.设置文档结构对象;const userSchema = new mongoose.Schema({name:String,age:Number,email:String,status1:Boolean,status2:Boolean,})//2.根据 Schema 创建一个 Model,它代表数据库中的集合const User = mongoose.model('User', userSchema ); //User表示文档对应的集合,如果库中不存在集合则创建;//3.通过文档模型对象的 create() 方法创建|新增数据集合文档;User.create({name:'wsm',age:18,email:'123@qq.com',email2:'123@qq.com', //对于和文档结构对象不匹配的字段,默认无视不进行CRUD操作;status1:"true",// status2:"xxxx", //与文档结构对象字段类型不匹配的值,程序则报错;},(err,data)=>{if (err) throw err; //如果错误抛出异常; console.log(data); //输出新增对象;});//最后操作完毕关闭数据库连接,释放资源;// mongoose.disconnect();
});
Model.create([{},{}],[callback]); 还支持批量插入数据;
//create([{},{}],[callback]); 还支持批量插入数据;
User.create([{ name:'one',age:20 },{ name:'two',age:21 }]
,(err,data)=>{ if (err) throw err; });
文档结构对象的字段类型:
在 Mongoose 中定义文档结构时,你可以使用多种字段类型来确保数据的一致性和验证,以下是 Mongoose 中可用的一些常见字段类型:
| 字段类型 | 描述 |
|---|---|
| Number | 用于存储数值 |
| String | 用于存储文本数据 |
| Date | 用于存储日期和时间 |
| Array | 用于存储数组,数组中的元素可以是上述任何类型 |
| Boolean | 用于存储布尔值(true真/false假,因为JavaScript的弱特性,‘true'也可以赋值成功 |
| Buffer | 用于存储二进制数据,可以用于存储图片|视频等文件资源,但目前资源都存放在OSS进行管理,数据库仅保存文件地址 |
| ObjectId | 用于存储文档的 ID,_id就是用该类型进行存储,一般设置外键字段类型;mongoose.Schema.Types.ObjectId |
| Decimal128 | 高精度数字,对于数据精度要求高的字段可以设置此类 mongoose.Schema.Types.Decimal128 |
| Mixed | 用于存储任何类型的数据,该字段属性支持所有的类型赋值 mongoose.Schema.Types.Mixed |
//设置监听mongoose连接回调
mongoose.connection.once('open', () => {//1.设置文档结构对象;const dataSchema = new mongoose.Schema({dnum:Number,dstr:String,dbol:Boolean,dtime:Date,darrs:Array,dmixed1:mongoose.Schema.Types.Mixed,dmixed2:mongoose.Schema.Types.Mixed,})//2.根据 Schema 创建一个 Model,它代表数据库中的集合const Data = mongoose.model('Data', dataSchema ); //User表示文档对应的集合,如果库中不存在集合则创建;//3.通过文档模型对象的 create() 方法创建|新增数据集合文档;Data.create({dnum:1,dstr:"wsm",dbol:false,dtime:new Date(),darrs:[0,"a",true],dmixed1:"支持任何数据类型可以是Str",dmixed2:["也可以是数组类型:",1,2,3,4], },(err,data)=>{ if (err) throw err; console.log(data); });//最后操作完毕关闭数据库连接,释放资源;// mongoose.disconnect();
});
文档结构对象的字段校验:
在Mongoose中,支持字段校验:通过在Schema定义中设置验证规则来实现,这些规则可以确保数据在保存到MongoDB之前符合特定的条件:
required: 标记字段为必需,validate: 定义正则表达式匹配规则,default: 默认值min和max: 为数值字段设置最小和最大值,enum: 限制字符串字段必须匹配预定义的值列表minlength和maxlength: 限制字符串字段的最小和最大长度,match: 要求字符串字段匹配正则表达式
//设置监听mongoose连接回调
mongoose.connection.once('open', () => {//1.设置文档结构对象;const valiSchema = new mongoose.Schema({vnum:{type:Number,unique: true, },vphone:{type: String,required: [true, '电话号码不能为空'],validate: { validator: function(v) { return /^1[3-9]\d{9}$/.test(v); }, message: '{VALUE} 不是一个有效的电话号码!'},}})//2.根据 Schema 创建一个 Model,它代表数据库中的集合const validation = mongoose.model('validation', valiSchema ); //User表示文档对应的集合,如果库中不存在集合则创建;//3.通过文档模型对象的 create() 方法创建|新增数据集合文档;validation.create([{vnum:1,vphone:"17626512541" }, //符号规则新增成功!{ vnum:1,vphone:"12345678900" }], //新增失败: vnum已经存在,vphone不符合规则;(err,data)=>{ if (err) throw err; console.log(data); });//最后操作完毕关闭数据库连接,释放资源;// mongoose.disconnect();
});
👉扩展知识:正则表达式 是由一系列字符和特殊符号组成的模式,用于在文本中搜索、匹配、替换和提取特定的字符或字符组合,后期更新文章...
^1[3-9]\d{9}$表示: 以1开头,第二位数字是3到9之间的任意数字,后面跟着9位任意数字;
读取文档:
这里需要根据个人需求去设置添加数据🔢
在Mongoose中,读取文档通常是通过模型(Model)的静态方法来完成的:
Mongoose提供了丰富的查询构建器,用于构建和执行数据库查询,查询可以链式调用,支持回调和Promise 本篇文章仅仅是个基础学习
find方法用于检索与给定查询条件匹配的所有文档,它返回一个文档数组,如果没有找到匹配的文档,则返回空数组;findOne方法用于检索与查询条件匹配的第一个文档,它返回单个文档或者在没有找到匹配的文档时返回nullfindById方法是一个便捷方法,用于通过文档的唯一_id字段检索单个文档,如果没有找到,则返回null
findById 实际上是findOne 的语法糖,内部执行的是 findOne({_id: id})当你想通过_id 查询文档时,使用findById 会更方便一些:
//设置监听mongoose连接回调
mongoose.connection.once('open', () => {//1.设置文档结构对象;const userSchema = new mongoose.Schema({name:String,age:Number,email:String,status1:Boolean,status2:Boolean,})//2.根据 Schema 创建一个 Model,它代表数据库中的集合const User = mongoose.model('User', userSchema ); //User表示文档对应的集合,如果库中不存在集合则创建;//3.通过文档模型对象的 find({查询条件},[回调函数]);User.find({},(err,data)=>{ if (err) throw err; console.log(data); });User.findOne({age:20},(err,data)=>{ if (err) throw err; console.log(data); });User.findById("65ed3f9ef20755df5ea45ed1",(err,data)=>{ if (err) throw err; console.log(data); });//最后操作完毕关闭数据库连接,释放资源;// mongoose.disconnect();
});
因为:Mode操作文档函数都是异步的,所以结果有点混乱大致如下:
#find 全查询结果
65ed3f9ef20755df5ea45ed2 two 21 123@qq.com 0
65ed3f9ef20755df5ea45ed0 wsm 18 123@qq.com 0 true
65ed3f9ef20755df5ea45ed1 one 20 123@qq.com 0
65ed6b2477ea7f3a0aaf485d one1 20 0
65ed6c01380bf260b0002b75 one2 20 1223@163.com 0 false false
#findOne 查询age=20的第一个元素;
65ed6c01380bf260b0002b75 one2 20 1223@163.com 0 false false
#findById 查询_id值为65ed6c01380bf260b0002b75 的元素
65ed6c01380bf260b0002b75 one2 20 1223@163.com 0 false false
多条件控制运算:
-
运算符: mongodb 不能
> < >= <= !==等运算符,需要使用替代符号:$eq 等于、> $gt、< $lt、等... -
逻辑运算:
$or逻辑或的情况、$and 逻辑与的情况、$not: 条件不匹配、$nor: 所有条件都不匹配 -
**正则匹配规则: **条件中可以直接使用 JS 的正则语法,通过正则可以进行模糊查询
case案例: find 查询 age≥20且name=one的数据 或 name=wsm 多条件语法:
//设置监听mongoose连接回调
mongoose.connection.once('open', () => {//1.设置文档结构对象;const userSchema = new mongoose.Schema({name:String,age:Number,email:String,status1:Boolean,status2:Boolean,})//2.根据 Schema 创建一个 Model,它代表数据库中的集合const User = mongoose.model('User', userSchema ); //User表示文档对应的集合,如果库中不存在集合则创建;//3.通过文档模型对象的 find({查询条件},[回调函数]);User.find({$or: [{ $and: [{ age: { $gte: 20 } }, { name: 'one' }] },{ name: 'wsm' }]},(err,data)=>{ if (err) throw err; console.log(data); }); //最后操作完毕关闭数据库连接,释放资源;// mongoose.disconnect();
});
65ed3f9ef20755df5ea45ed0 wsm 18 123@qq.com 0 true
65ed3f9ef20755df5ea45ed1 one 20 123@qq.com 0
字段筛选:
字段筛选用于限制查询结果中返回的字段,Mongoose支持指定只返回需要的字段,从而减少数据传输量:
Mongoose中使用 .select()方法来指定要返回的字段:Model.find().select({ k1: 1, k2: 1,... }) 0不要的字段、1要的字段
//查询age=20的数据,并只获取name、age字段
User.find({age:{$eq:20}}).select({_id:0,name:1,age:1}).exec((err,data)=>{ console.log(data); });
[{ name: 'one', age: 20 },{ name: 'one1', age: 20 },{ name: 'one2', age: 20 }]
数据排序:
排序用于根据一个或多个字段对查询结果进行排序:
在Mongoose中,您可以使用Model.sort({k:1,k:-1})方法来指定排序的字段和顺序 1升序、-1降序
//查询age=20的数据,并只获取name、age字段,并根据name倒排
User.find({age:{$eq:20}}).select({_id:0,name:1,age:1}).sort({name: -1}).exec((err,data)=>{ console.log(data); });
[{ name: 'one2', age: 20 },{ name: 'one1', age: 20 },{ name: 'one', age: 20 }]
数据截取:
截取用于限制查询结果的数量或跳过一定数量的结果,这在分页显示数据时非常有用:
在Mongoose中,您可以使用Model.limit(n)和Model.skip(n)方法来实现:
// 限制查询结果只返回前3条数据
User.find().select({_id:0,name:1,age:1}).limit(3).exec((err, data) => { console.log(data); });
// 跳过前3条数据,然后返回结果
User.find().select({_id:0,name:1,age:1}).skip(3).exec((err, data) => { console.log(data); });
// 查询第3条-往后1条记录,然后返回结果
User.find().select({_id:0,name:1,age:1}).skip(3).limit(1).exec((err, data) => { console.log(data); });
修改文档:
在Mongoose中,更新文档可以通过多种方法实现,这些方法提供了不同级别的控制和灵活性,以下是一些常用的更新方法:
Model.updateOne({更新条件},{更新字段},[回调函数])更新单个匹配文档Model.updateMany({更新条件},{更新字段},[回调函数])可以更新所有匹配查询条件的文档
//设置监听mongoose连接回调
mongoose.connection.once('open', () => {//1.设置文档结构对象;const userSchema = new mongoose.Schema({name:String,age:Number,email:String,status1:Boolean,status2:Boolean,})//2.根据 Schema 创建一个 Model,它代表数据库中的集合const User = mongoose.model('User', userSchema );//3.通过文档模型对象的 updateOne更新单个文档|updateMany更新多个文档;//更新第一个匹配的name=wsm的值未newWsmUser.updateOne({name:'wsm'},{name:'newWsm'},(err,data)=>{ if(err) throw err; console.log(data); });//更新所有age>0的文档age值为18User.updateMany({age:{$gt:0}},{age:18},(err,data)=>{ if(err) throw err; console.log(data); });//最后操作完毕关闭数据库连接,释放资源;// mongoose.disconnect();
});
Model.findOneAndUpdate()这个方法查找一个匹配的文档,更新它,并返回更新前或更新后的文档Model.findByIdAndUpdate()如果知道文档的ID,使用方法来更新指定文档的对象,方法的行为类似于findOneAndUpdate()
删除文档:
在Mongoose中,删除文档和修改文档类似,可以通过几种不同的方法实现,以下是一些常用的删除方法:
- Model.deleteOne({删除条件},[回调函数]) 删除单个匹配文档
- Model.deleteMany({删除条件},[回调函数]) 可以删除所有匹配查询条件的文档
//设置监听mongoose连接回调
mongoose.connection.once('open', () => {//1.设置文档结构对象;const userSchema = new mongoose.Schema({name:String,age:Number,email:String,status1:Boolean,status2:Boolean,})//2.根据 Schema 创建一个 Model,它代表数据库中的集合const User = mongoose.model('User', userSchema );//3.通过文档模型对象的 deleteOne删除单个文档|deleteMany删除多个文档;//更新第一个匹配的name=wsm的值未newWsmUser.deleteOne({name:'wsm'},(err,data)=>{ if(err) throw err; console.log(data); });//更新所有age>0的文档age值为18User.deleteMany({age:{$eq:20}},(err,data)=>{ if(err) throw err; console.log(data); });//最后操作完毕关闭数据库连接,释放资源;// mongoose.disconnect();
});
Model.findOneAndDelete方法查找并删除与给定查询条件匹配的第一个文档,并返回被删除的文档,没有找到匹配的文档,则返回nullModel.findByIdAndDelete方法通过文档的ID来查找并删除文档,其中查询条件是文档的ID
Mongoose 模块化🧊:
🧊模块化 前端工程\模块化 此篇文章,欢迎路过大佬点评学习;
在Node.js中实现MongoDB的模块化主要涉及到将数据库操作封装成模块,以便在整个应用中重用:
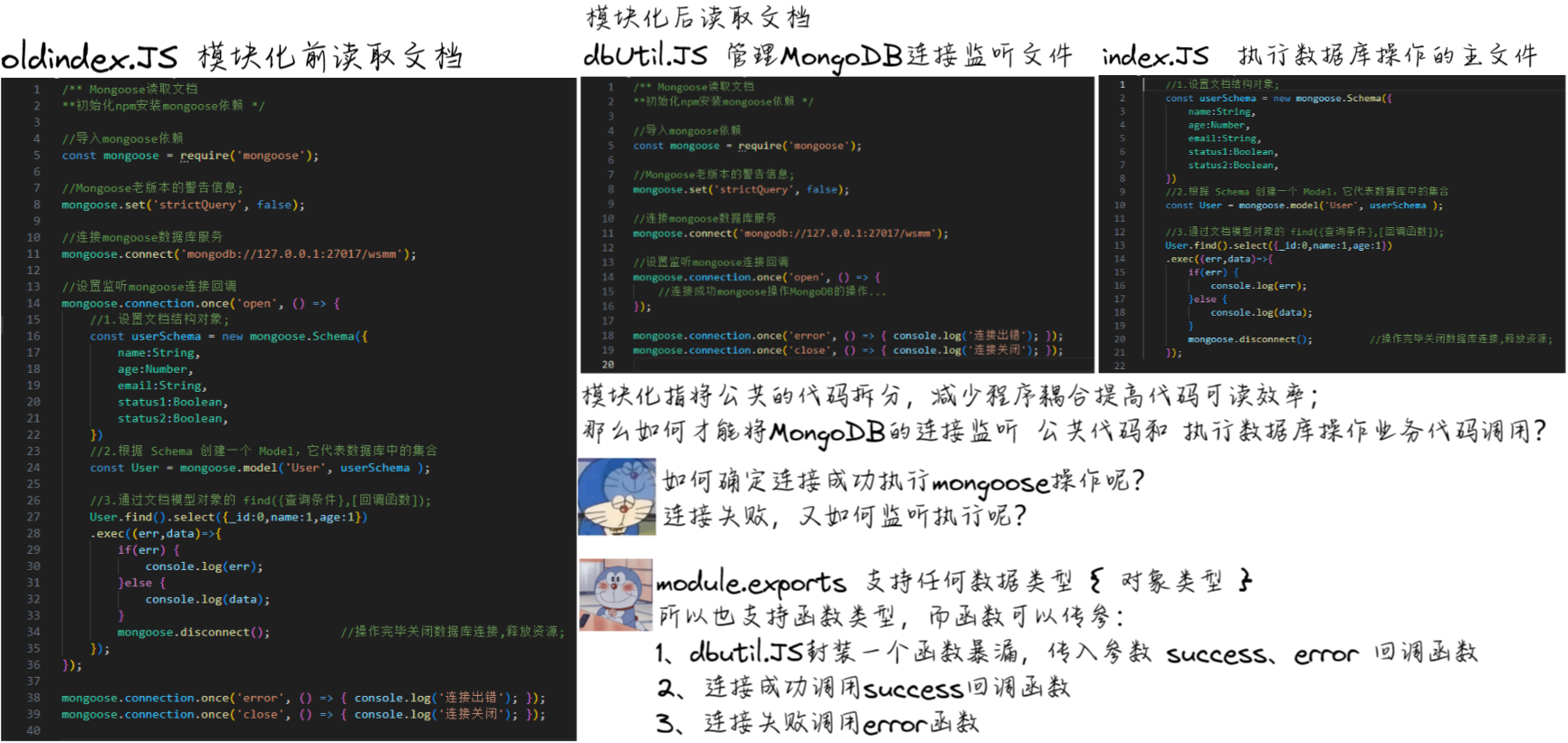
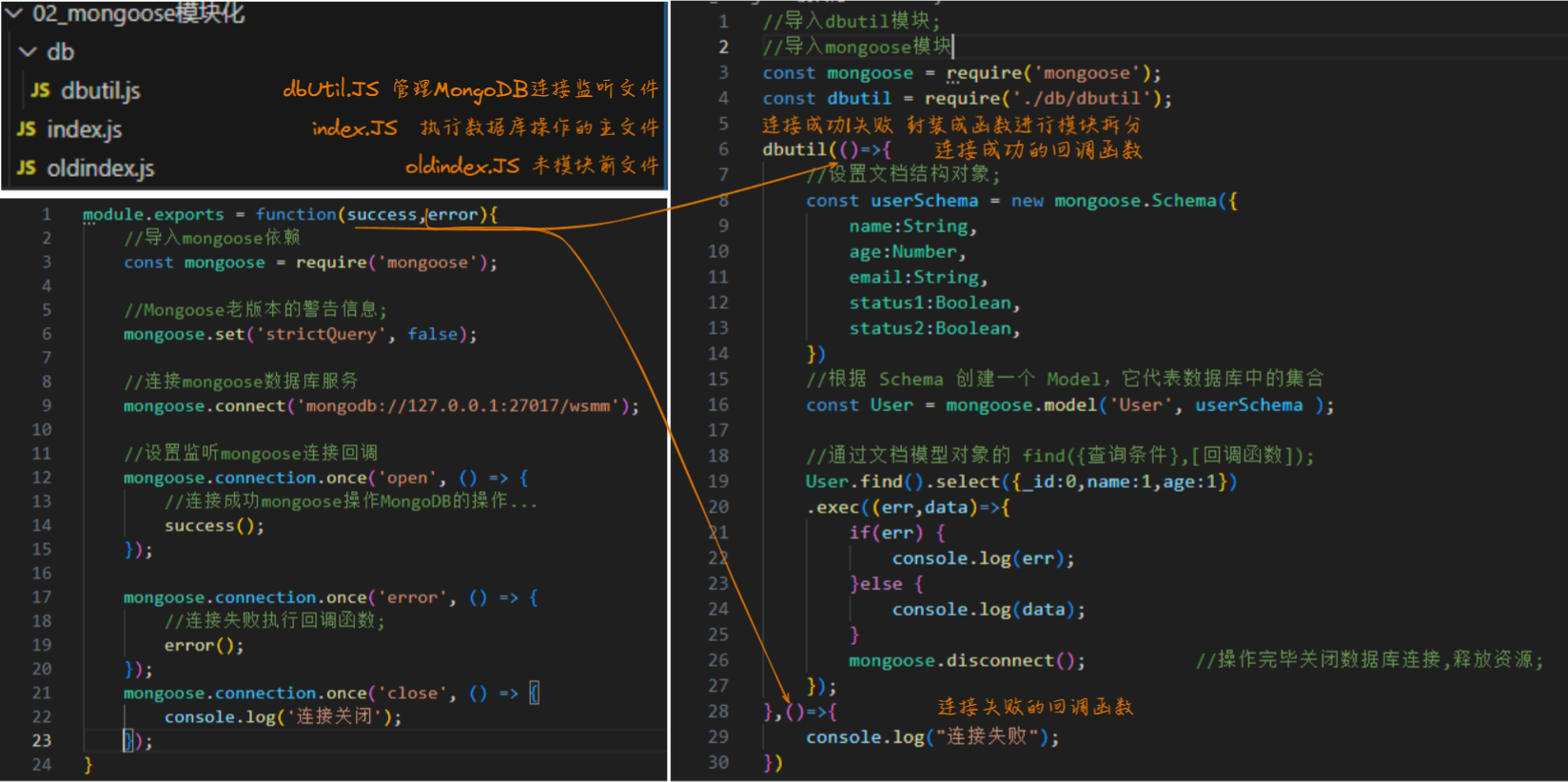
dbUtil.Js: 管理MongoDB连接监听文件,封装模块;
module.exports = function(success,error){//导入mongoose依赖const mongoose = require('mongoose');//Mongoose老版本的警告信息;mongoose.set('strictQuery', false);//连接mongoose数据库服务mongoose.connect('mongodb://127.0.0.1:27017/wsmm');//设置监听mongoose连接回调mongoose.connection.once('open', () => {//连接成功mongoose操作MongoDB的操作...success();});mongoose.connection.once('error', () => { //连接失败执行回调函数;error();}); mongoose.connection.once('close', () => { console.log('连接关闭'); });
}
index.Js: 执行数据库操作的主文件,调用 dbUtil模块 完成操作
//导入dbutil模块;
//导入mongoose模块
const mongoose = require('mongoose');
const dbutil = require('./db/dbutil');dbutil(()=>{//设置文档结构对象;const userSchema = new mongoose.Schema({name:String,age:Number,email:String,status1:Boolean,status2:Boolean,})//根据 Schema 创建一个 Model,它代表数据库中的集合const User = mongoose.model('User', userSchema );//通过文档模型对象的 find({查询条件},[回调函数]);User.find().select({_id:0,name:1,age:1}).exec((err,data)=>{ if(err) { console.log(err); }else { console.log(data); }mongoose.disconnect(); //操作完毕关闭数据库连接,释放资源;});
},()=>{console.log("连接失败");
})
对象文档模型-模块化:
🆗,上述操作完成了一部分的模块化,但好像还可以进行升级: 对文档模型进行模块化
将文档模型事先定义模块化,之后多个地方只需要导入文档模型就可以快速进行集合的CRUD;
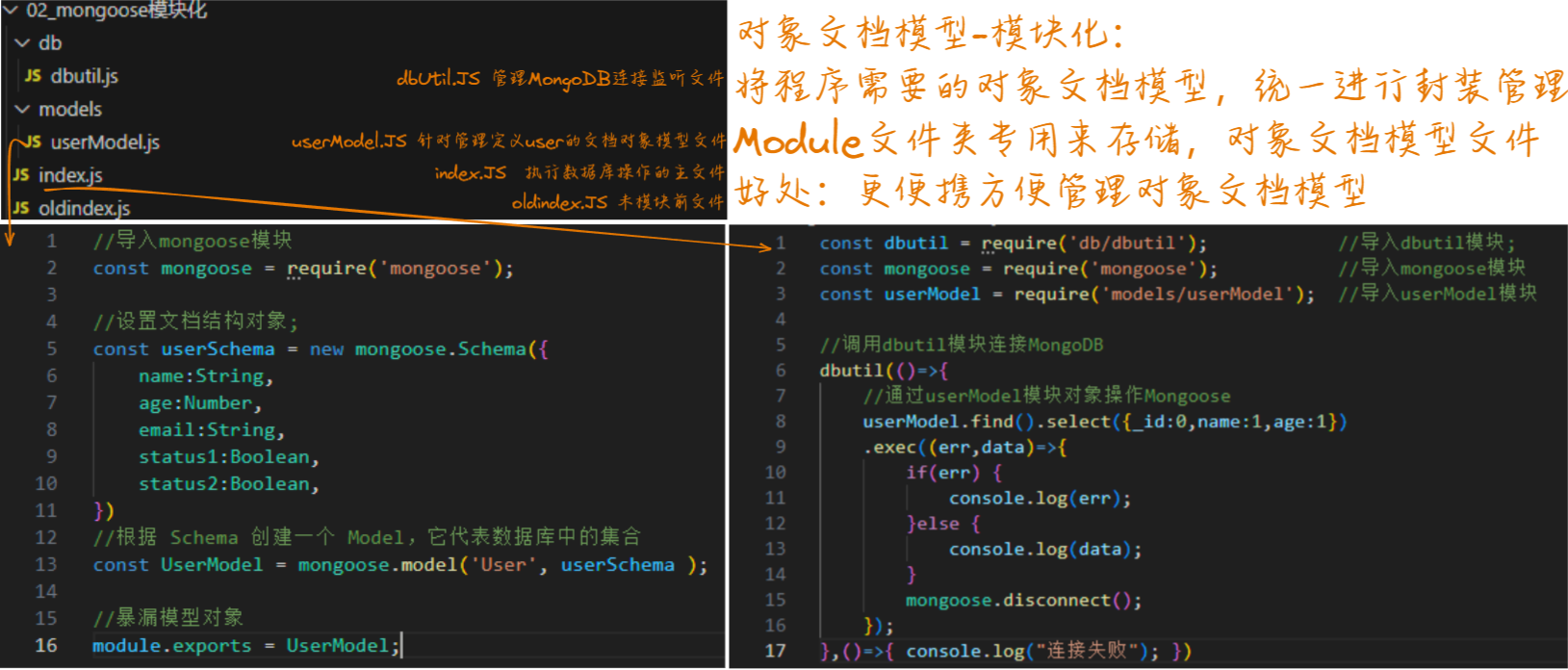
userModel.js
//导入mongoose模块
const mongoose = require('mongoose');//设置文档结构对象;
const userSchema = new mongoose.Schema({name:String,age:Number,email:String,status1:Boolean,status2:Boolean,
})
//根据 Schema 创建一个 Model,它代表数据库中的集合
const UserModel = mongoose.model('User', userSchema );//暴漏模型对象
module.exports = UserModel;
index.js
const dbutil = require('./db/dbutil'); //导入dbutil模块;
const mongoose = require('mongoose'); //导入mongoose模块
const userModel = require('./models/userModel'); //导入userModel模块//调用dbutil模块连接MongoDB
dbutil(()=>{//通过userModel模块对象操作MongooseuserModel.find().select({_id:0,name:1,age:1}).exec((err,data)=>{ if(err) { console.log(err); }else { console.log(data); }mongoose.disconnect();});
},()=>{ console.log("连接失败"); })
error 默认回调:
优化、优化、优化!!! 程序就是要不断的优化中进步的,每次调用:dbUtil 都要传递两个回调函数;
对于连接失败的回调,貌似一般情况都不会发送改变,那么这里也可以进行简便,不用每次都重新写一遍,可以设置一个默认回调; dbUtil.JS ⏫⏫
module.exports = function(success,error){//判断error是否传递,设置默认值: 避免了每次使用dbUtil都要传递error回调函数if(typeof error !== 'function'){ error = ()=>{ console.log('默认连接异常捕获'); } }//导入mongoose依赖const mongoose = require('mongoose');//Mongoose老版本的警告信息;mongoose.set('strictQuery', false);//连接mongoose数据库服务mongoose.connect('mongodb://127.0.0.1:27017/wsmm');//设置监听mongoose连接回调mongoose.connection.once('open', () => { success(); });mongoose.connection.once('error', () => { error(); }); mongoose.connection.once('close', () => { /**...*/ });
}
连接信息模块:
优化、优化、优化!!! 再次优化,将固定的:mongoose.connect('mongodb://127.0.0.1:27017/wsmm'); 进行参数配置文件注入,更方便管理程序;
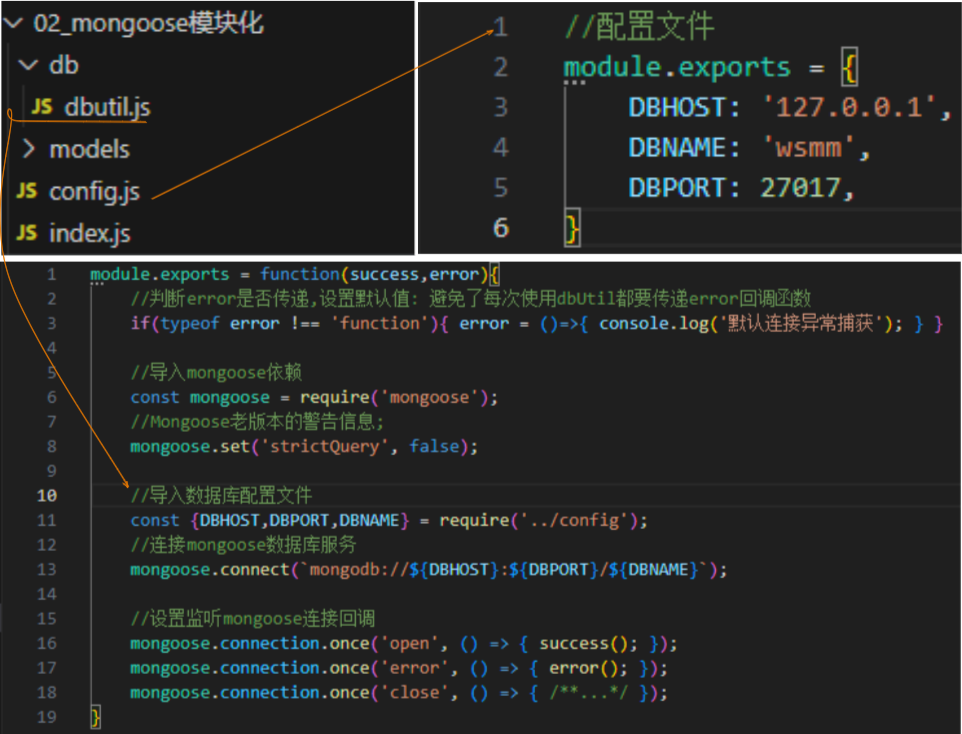
config.Js
//配置文件
module.exports = {DBHOST: '127.0.0.1',DBNAME: 'wsmm',DBPORT: 27017,
}
dbUtil.Js
module.exports = function(success,error){//判断error是否传递,设置默认值: 避免了每次使用dbUtil都要传递error回调函数if(typeof error !== 'function'){ error = ()=>{ console.log('默认连接异常捕获'); } }//导入mongoose依赖const mongoose = require('mongoose');//Mongoose老版本的警告信息;mongoose.set('strictQuery', false);//导入数据库配置文件const {DBHOST,DBPORT,DBNAME} = require('../config');//连接mongoose数据库服务mongoose.connect(`mongodb://${DBHOST}:${DBPORT}/${DBNAME}`);//设置监听mongoose连接回调mongoose.connection.once('open', () => { success(); });mongoose.connection.once('error', () => { error(); }); mongoose.connection.once('close', () => { /**...*/ });
}
开发指南)
)
)



)
)








)
 RAG概念)

