HashSet底层剖析
前言:
我们知道Set中所存储的元素是不重复的,那么Set接口的实现类HashSet在添加元素时是怎么避免重复的呢?
★ HashSet在添加元素时,是如何判断元素重复的?
● 在底层会先调用hashCode(),注意,Object中的hashCode()返回的是对象的地址,此时并不会调用;此时调用的是类中重写的hashCode(),返回的是根据内容计算的哈希值,遍历时,会用哈希值先比较是否相等,会提高比较的效率;但哈希值会存在问题:内容不同,哈希值相同;这种情况下再调equals比较内容,这样既保证效率又确保安全。
案例:
- 这是错误写法,此时默认调用的是Object类中hashCode( ),返回对象地址
import java.util.HashSet;
import java.util.Objects;public class Student {private String name ;private String num;public Student(String name, String num) {this.name = name;this.num = num;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", num='" + num + '\'' +'}';}public static void main(String[] args) {HashSet<Student> set = new HashSet<>();Student s1 = new Student("小王1","10001");Student s2 = new Student("小王2","10002");Student s3 = new Student("小王3","10003");Student s4 = new Student("小王1","10001");set.add(s1);set.add(s2);set.add(s3);set.add(s4);System.out.println(set);}}
- 此时之所以出现重复,因为默认调用的是Object类中hashCode( ),返回对象地址,s1和s4内容虽然相同,但作为两个对象,地址肯定不同。

- 正确写法应该是,在Student类中重写hashCode()和equals()
package Demo;import java.util.HashSet;
import java.util.Objects;public class Student {private String name ;private String num;@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return num.equals(student.num);}@Overridepublic int hashCode() {return Objects.hash(num);}public Student(String name, String num) {this.name = name;this.num = num;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", num='" + num + '\'' +'}';}public static void main(String[] args) {HashSet<Student> set = new HashSet<>();Student s1 = new Student("小王1","10001");Student s2 = new Student("小王2","10002");Student s3 = new Student("小王3","10003");Student s4 = new Student("小王1","10001");set.add(s1);set.add(s2);set.add(s3);set.add(s4);System.out.println(set);}}- 这样就能避免重复了(此图是s1,s4重复,但只输出s1)| 注意:HashSet: 元素是无序的

补充:
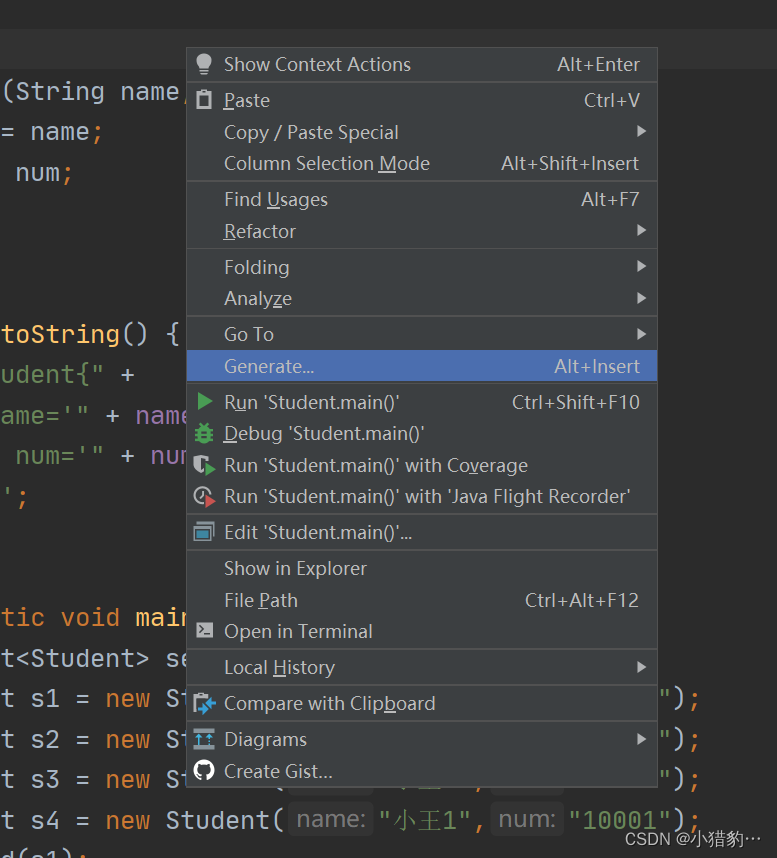
- 如何快速生成hashCode()和equals()的重写方法?
右键选择Generate,选择equals()and hashCode(),选择重写的属性。



HashMap底层剖析
★ HashMap底层存储数据的结构 :(面试高频题)
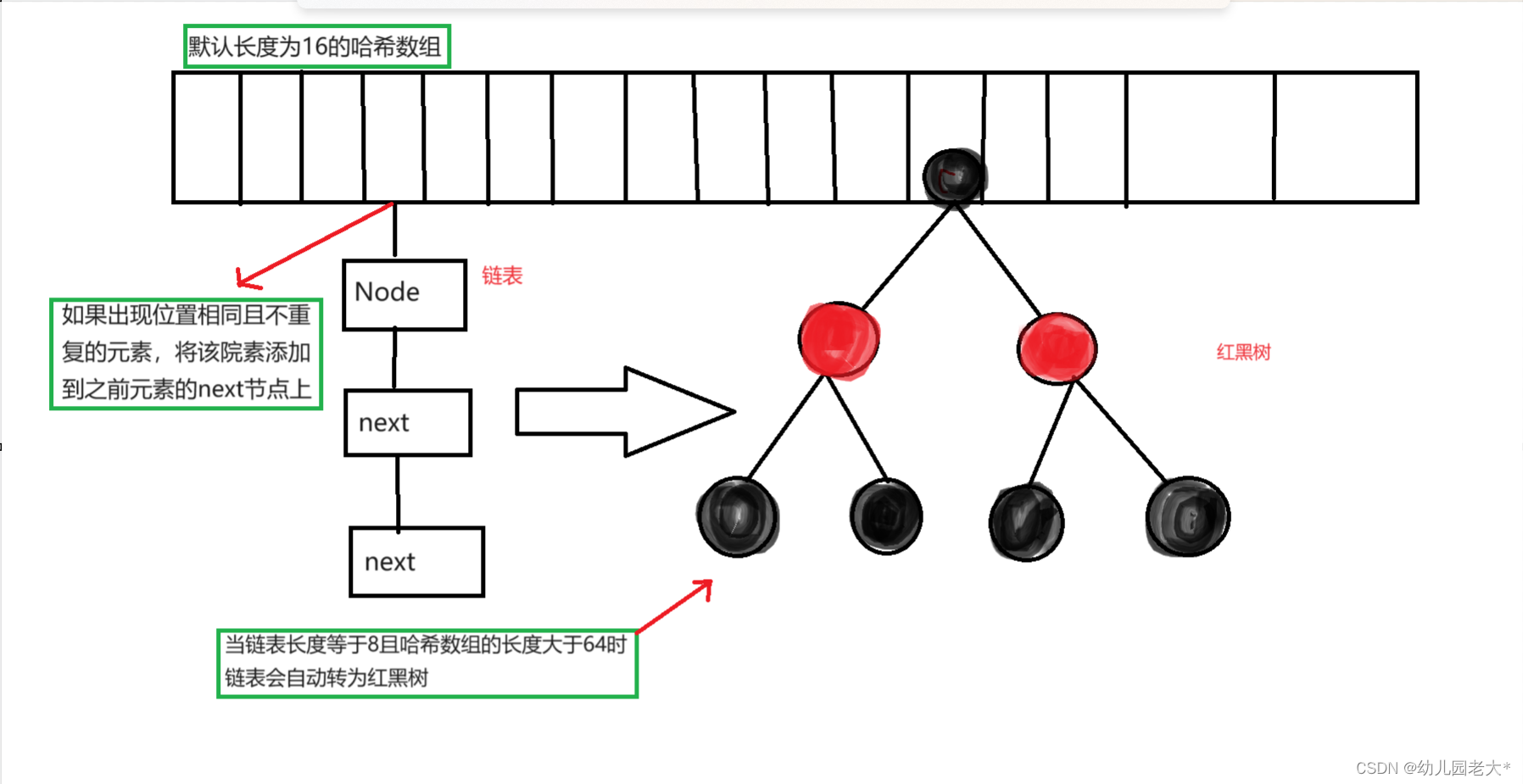
○ 底层使用了一个长度默认为16的哈希数组,用来确定元素的位置,每次用key计算出哈希值,再 用哈希值%数组长度确定元素位置,将元素放在哈希表中指定的位置。
○ 后来继续添加元素,如果出现位置相同且不重复的元素,那么将后来元素添加到之前元素的next 节点。
○ 当链表长度等于8且哈希数组的长度大于64时链表会自动转为红黑树。
补充: 哈希表负载因子为0.75 , 当哈希表使用数组的0.75倍时会自动扩容为原来数组长的2倍。




‘)

上的防火墙工具使用方法)

)
)


)
![[linux] pip install -e . 和 pip install -e “.[train]“分别是什么意思](http://pic.xiahunao.cn/[linux] pip install -e . 和 pip install -e “.[train]“分别是什么意思)




 Midjourney官方发布角色一致性功能;免费且开源的简历制作工具;精确克隆语调、控制声音风格)
