
论文题目:Vision Transformers Need Registers
论文链接:https://arxiv.org/abs/2309.16588
视觉Transformer(ViT)目前已替代CNN成为研究者们首选的视觉表示backbone,尤其是一些基于监督学习或自监督学习预训练的ViT,可以在诸多下游视觉任务上表现出卓越的性能。但目前针对ViT中间特征图的可解释研究相对较少,本文介绍一篇Meta与INRIA(法国国家信息与自动化研究院)合作完成的论文,目前该文已被国际表征学习顶级会议ICLR 2024录用。本文的研究人员们对ViT网络特征图中出现的伪影进行了研究,并且认为这些伪影对应于模型表征图像背景区域中的高范数token,模型在推理阶段时丢弃了这些token中包含的局部信息。为此,本文提出了一个简单有效的寄存器方法(Registers)来将这些伪影token进一步送入到模型中进行内部运算以提高性能。作者通过一系列实验证明,Registers可以解决监督或自监督ViT丢失局部信息的问题,提高其在密集型下游视觉任务上的综合性能,同时产生更加平滑的特征图和注意力图。
01. 引言
本文的动机从目前流行的DINO[1],DINOv2[2]等ViT模型的内部表征出发。DINO算法目前已被证明可以生成包含图像语义布局的特征图,尤其是其最后一个注意力层可以生成可解释的注意力图。基于这些特性,目前已有研究通过收集注意力图中的语义信息在缺少明确监督的情况下检测目标。DINOv2是DINO的后续升级版本,提供了处理密集型预测任务的能力,但DINOv2在生成注意力方面的效果却不尽如人意。下图左侧第三列展示了DINOv2模型生成的注意力图,可以看到,其中出现了大量的噪声伪影。
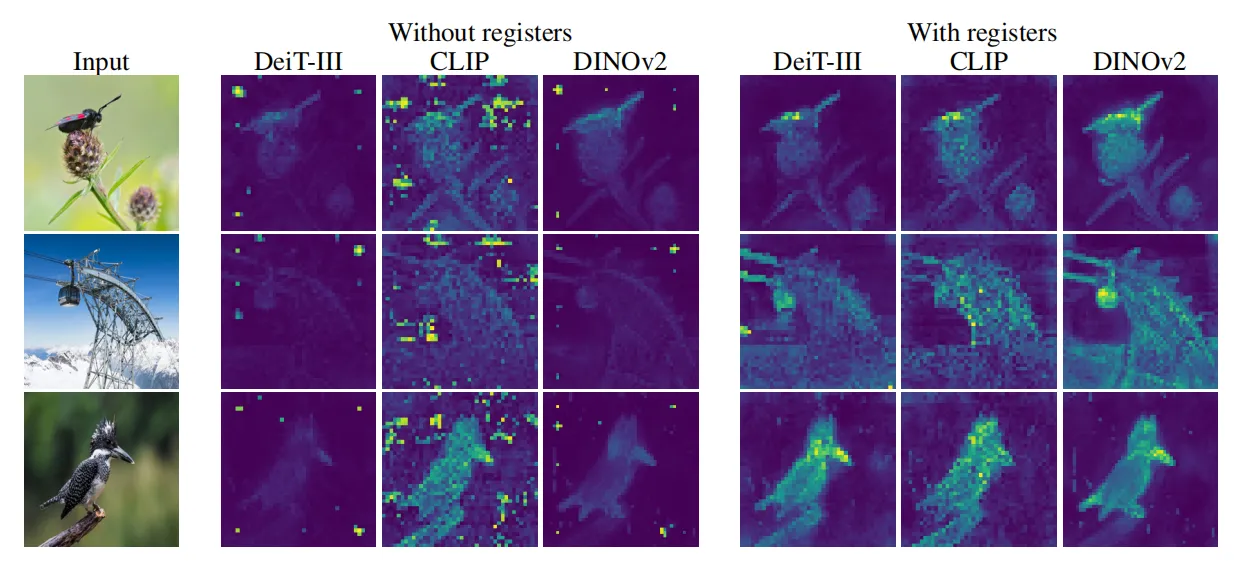
此外,作者也在其他监督学习训练的ViT中发现了类似的伪影现象,如下图中的DeiT、CLIP等,本文对这些伪影的出现原因和固有性质进行了研究,通过测量发现,这些伪影相比其他token的范数大约高10倍,并且其数量仅占token总序列的一小部分(2%)。
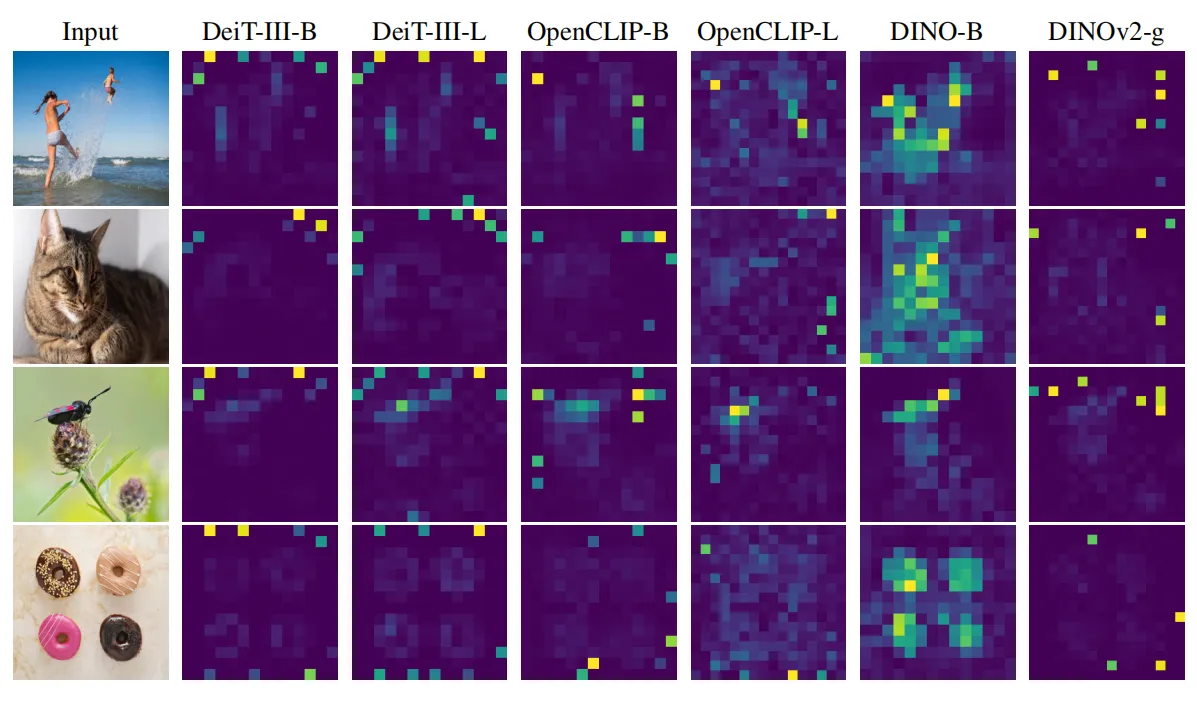
随后作者使用简单的线性模型对这些伪影token进行评估,作者观察到,这些token保留其在图像中的原始位置的信息较少,这表明模型在推理过程中丢弃了这些token中包含的局部信息。此外,在这些伪影token上学习图像分类器比在其他token上学习图像分类器的准确性要高得多,这表明它们可能也包含有关图像的全局信息。因而作者引入了一种寄存器方法(Registers)来将这些token附加到ViT的输入序列中,而独立于输入图像。经过Registers优化后的ViT模型,其产生的token序列中,伪影token已经完全消失,同时模型在下游密集预测任务中的性能得到提高,并且生成的特征图明显更加平滑。
02. 本文方法
2.1 DINOv2局部特征中伪影
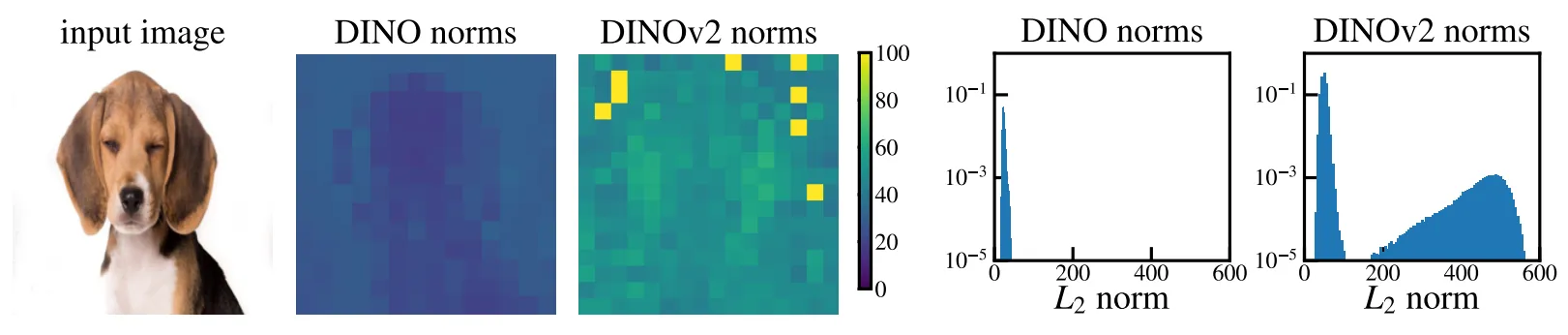
为了分析DINOv2特征图中的伪影,作者首先从定量分析的角度对伪影token进行测量,如下图所示,作者观察到,伪影token与其他token之间的一个重要区别是它们的特征范数值(norms)差异很大。下图右侧分别展示了给定参考图像的DINO和DINOv2 模型的局部特征范数情况。可以看到,伪影token的范数值远高于其他token,且伪影token特征范数的分布是双峰的,因而作者在文章的后续部分将范数值超过150的token均认定为伪影token。
c70f1de7078649b284abfdad7958ca57.png
2.2 伪影通常出现在大型ViT模型的训练过程中
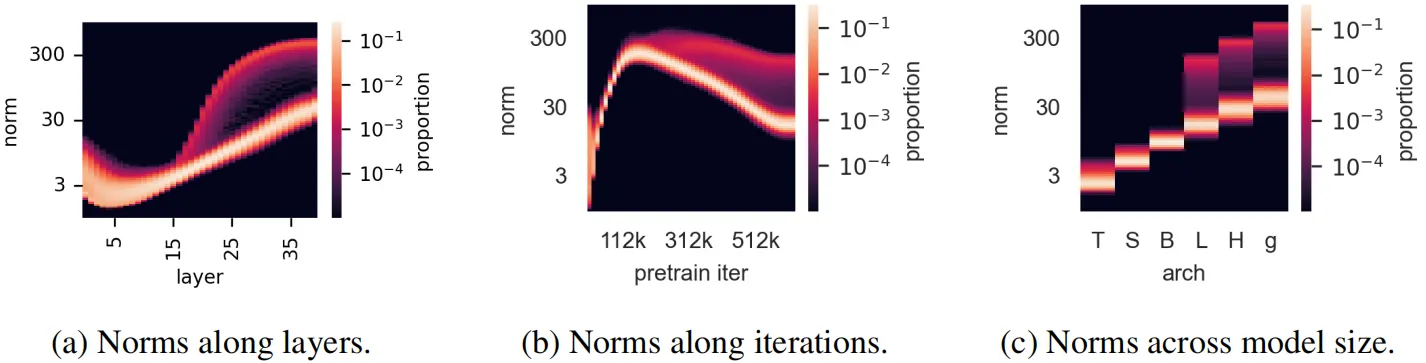
除了定量分析,作者还对DINOv2训练期间出现伪影token的条件进行了观察,分析结果如下图所示。这些token主要出现在ViT的40层左右(下图a),此外,当观察训练过程中token范数的分布时,作者发现这些伪影token仅在训练的后期出现(下图b)。当作者更进一步分析模型不同参数规模(Tiny、Small、Base、Large、Huge 和 Giant)对伪影token的影响时发现,只有较大的三个模型才会出现伪影(下图c)。
2.3 伪影token包含的局部信息和全局信息
为了探索伪影token中所含信息的性质,作者设计了两个不同的实验任务:位置预测和像素重建。对于每一个任务,作者将token嵌入作为输入训练一个线性模型,并测量该模型的性能。
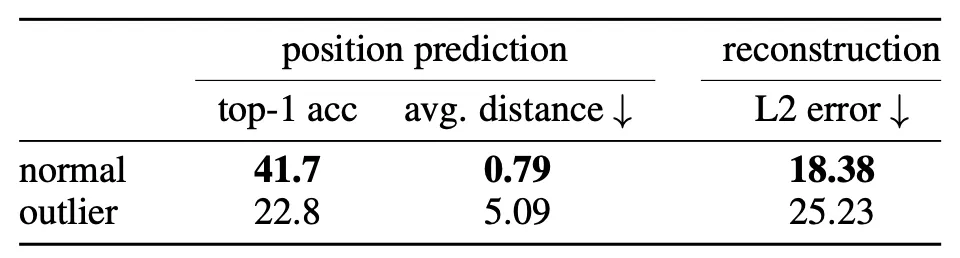
(1)位置预测
作者首先训练了一个线性模型来预测图像中每个token的位置,并测量其准确性。作者观察到伪影token的准确度比其他token低得多(如上表所示),这表明它们包含的有关其在图像中位置的局部信息较少。
(2)像素重建
对于像素重建任务,作者训练了一个线性模型来根据token嵌入预测图像的像素值,并测量该模型的准确性。从上表的实验结果可以观察到,伪影token的准确率同样比其他token低得多。这表明伪影token比其他token包含更少的像素信息。
除了伪影token的局部信息情况,作者还在标准图像表示基准上对其进行了评估,用于分析其中的全局信息。对于分类数据集中的每个图像,作者都直接提取DINOv2的token嵌入,并送入到一个逻辑回归分类器中预测图像类别,结果如下表所示。可以观察到伪影token比其他token具有更高的准确度。这表明伪影token相比其他token包含更多的全局信息。

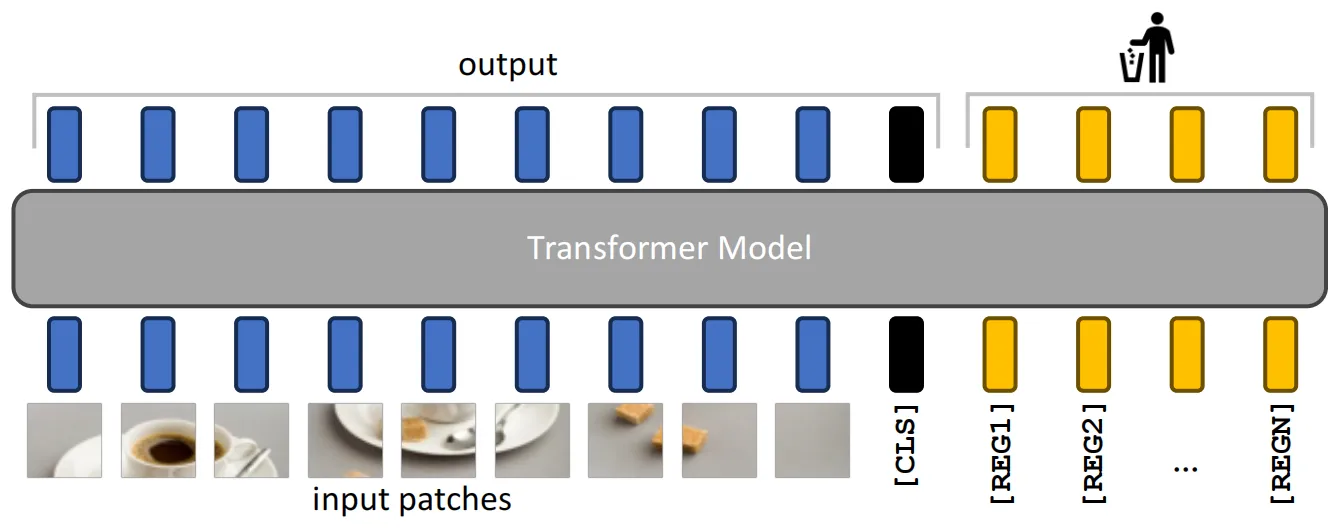
2.4 寄存器Registers设计
经过以上分析,作者认为,出现在大型ViT训练过程中的伪影token实际上包含了输入图像的一部分信息。将其直接丢弃可能会导致模型在密集预测任务上的性能下降。因此作者提出了一个简洁的寄存器(Registers)模块,通过明确地将伪影token添加到序列中,这些token被设计为可学习性的参数,类似于[CLS]token。实际操作过程如下图所示,这些伪影token被标记为[REG]token,随后附加在图像patch和[CLS]token之后一起送入到transformer中进行后续的运算。
03. 实验效果
本文的实验部分选取了三种不同的ViT架构:DeiT-III、OpenCLIP和DINOv2,由于Registers本质上只是一个简单的架构修改方案,因此其可以灵活的应用在多种ViT模型上。其中DeiT-III是监督学习训练的代表模型,使用ImageNet-1k 和 ImageNet-22k进行预训练。OpenCLIP是一种文本监督学习模型,其遵循原始的CLIP模型,仅在文本-图像对齐数据集上进行训练。DINOv2是本文研究的重点模型,该模型是一种基于自监督学习的视觉特征表示模型。
下图展示了Registers应用在上述三种模型上的效果,对于每个模型,作者测量了起输出token的特征范数,可以看到,当加入Registers进行训练时,模型输出的伪影token数量将会大幅度减少。

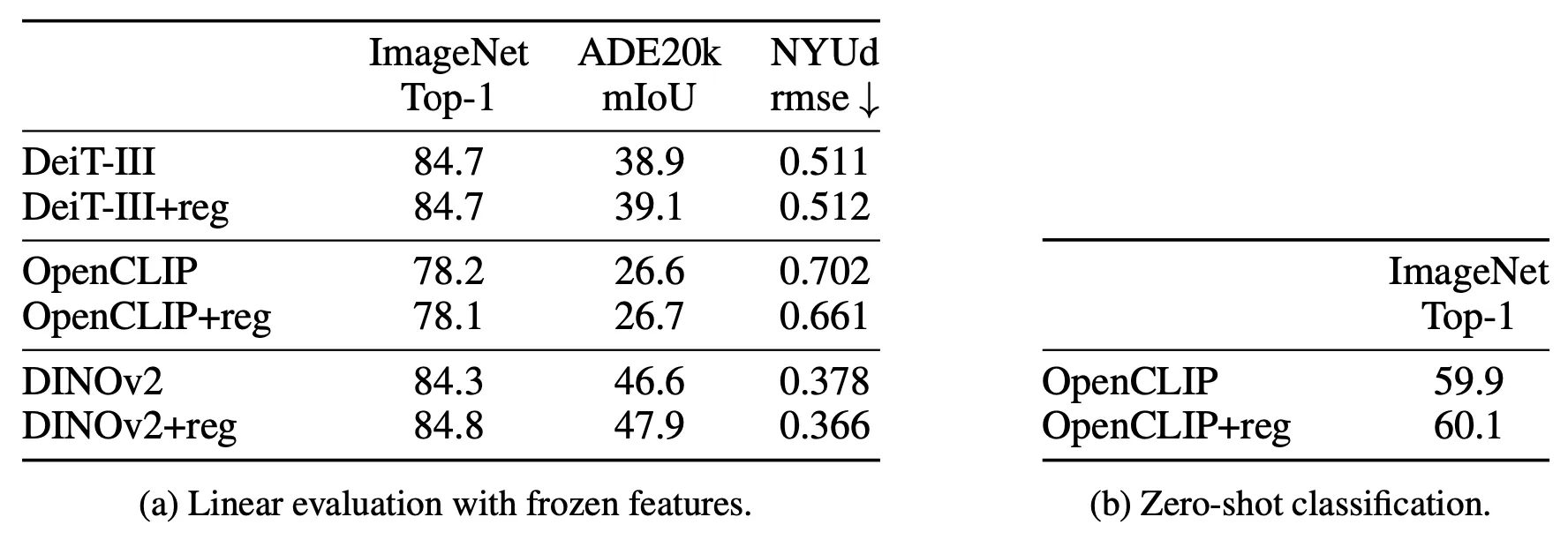
此外,作者还对Registers进行了消融研究,即检查Registers的使用不会影响原始特征的表示质量,作者选择了ImageNet分类、ADE20k图像分割和NYUd单目深度估计三个常规视觉任务进行实验,结果如下表(a)所示。可以发现,当使用Registers进行训练时,模型并不会损失性能,甚至还可以提高性能。为了完整起见,作者还进一步提供了 OpenCLIP 在 ImageNet 上的零样本分类性能,如下表(b)所示,该性能保持不变。
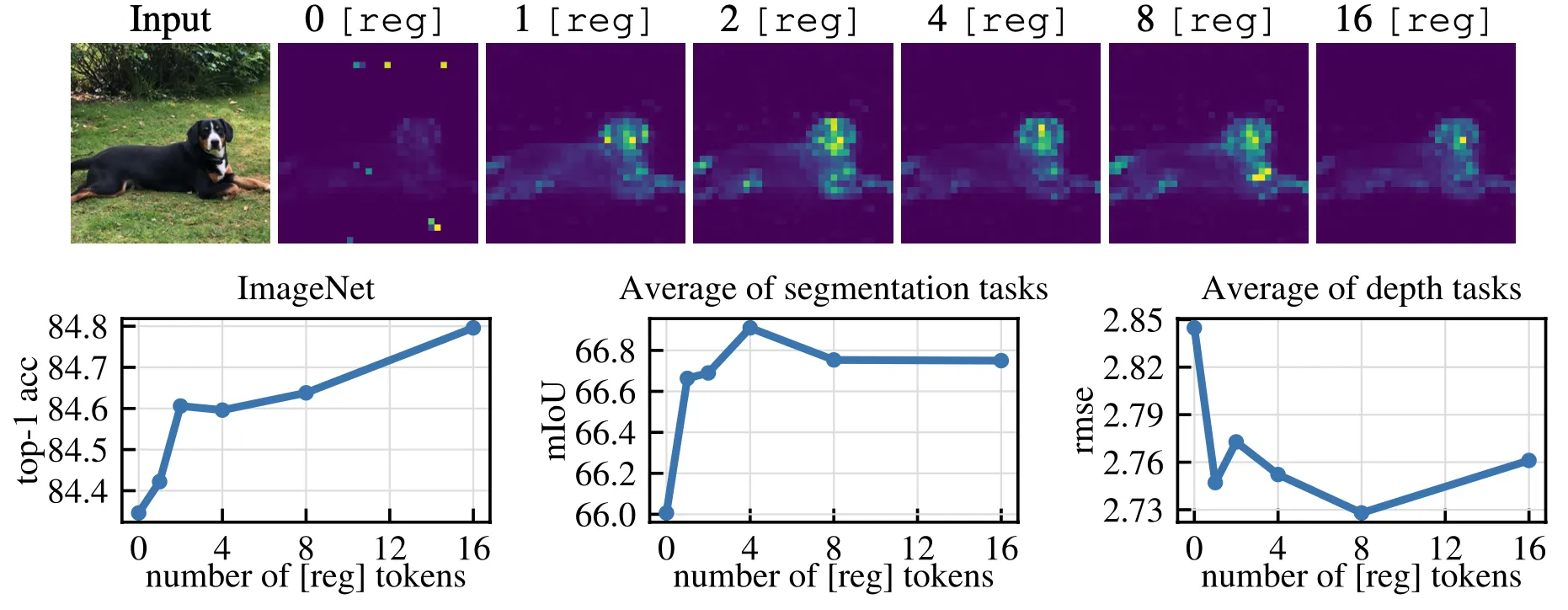
Registers结构的一个关键超参数是加入到原始序列中的token数量,作者对该数量对模型局部特征和下游性能的影响进行了研究,结果如下图所示。作者分别使用数量为0、1、2、4、8 和 16 的寄存器训练DINOv2模型。下图上半部分的结果表明,随着Registers数量的增加,模型注意力图中的伪影区域逐渐减小。图中下半部分展示了Registers数量改变对下游任务性能的影响情况,对于密集型预测任务(图像分割和单目深度估计)而言,Registers的数量并不是越多越好。而对于图像分类任务来说,使用更多的Registers,模型的性能会一直提升。
04. 总结
在这项工作中,作者对 DINOv2 模型特征图中的伪影进行了详尽的研究,并发现这种现象存在于多个现有的流行ViT模型中。作者提供了一种简单的检测伪影的方法,即通过测量token的特征范数来实现。通过研究这些token的局部位置和全局特征信息,作者发现,这些token对于模型性能损失存在一定的影响,并提出了一种简单的寄存器方案(Registers)来将这些token附加到输入序列中。通过实验表明,这种方法完全消除了ViT特征图中的伪影,并且提高了模型在下游密集预测等任务上的性能。
参考
[1] Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021.
[2] Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区



)










:构造函数、析构函数、对象的销毁顺序)




编程语言)