1: Pi
百分50%算力确达到了GPT-4水平

Pi 刚刚得到了巨大的升级!它现在由最新的 LLMInflection-2.5 提供支持,它在所有基准测试中都与 GPT-4 并驾齐驱,并且使用不到一半的计算来训练。
地址:https://pi.ai/
2: Moseca
能将音乐轨道中的人声、鼓声、贝斯等音源分离出来的工具

Moseca是一个基于音乐源分割的工具,它专门用于从音乐轨道中提取人声、鼓声、贝斯和其他乐器声音。通过使用预训练模型,Moseca能够分解音乐文件,让你单独获取音乐中的特定成分。
地址:https://github.com/fabiogra/moseca
3: ComfyUI-Flowty-TripoSR
在ComfyUI中直接使用TripoSR进行快速3D重建
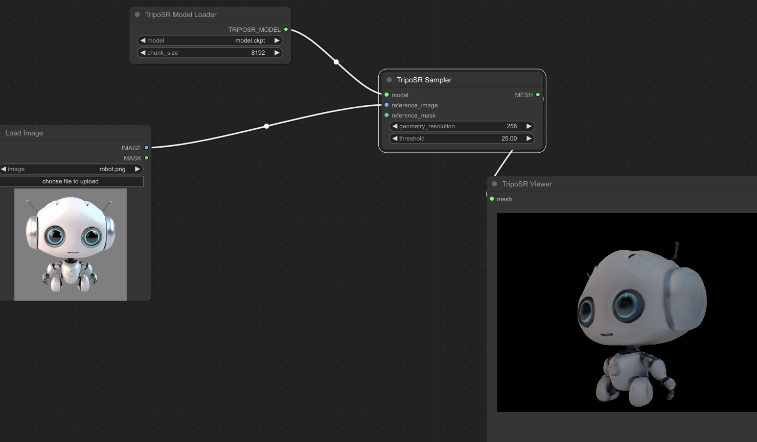
ComfyUI-Flowty-TripoSR是一款将单张图片快速转换成3D模型的工具,它基于开源模型TripoSR构建。TripoSR由Tripo AI与Stability AI共同开发,是在单图像3D重建领域的一款先进模型。通过将这一模型整合进ComfyUI中,用户可以直接在ComfyUI的环境下使用TripoSR功能,从而实现从图片到3D模型的无缝转换。
地址:https://github.com/flowtyone/ComfyUI-Flowty-TripoSR
4: Qwen-Agent
Qwen的指令跟随、工具使用、规划和记忆能力开发LLM应用的框架

Qwen-Agent是一个基于Qwen的大型语言模型(LLM)能力,包括指令执行、工具使用、计划和记忆能力来开发LLM应用的框架。这个框架还提供了一些示例应用,例如浏览器助手、代码解释器和定制助手。
地址:https://github.com/QwenLM/Qwen-Agent
5: PixArt-Σ
华为发布扩散变换模型,能够生成4K分辨率文本到图像的高效训练技术

PixArt-Σ是一种利用扩散变换模型(Diffusion Transformer, 简称DiT)直接生成4K分辨率图像的技术。与它的前任PixArt-α相比,PixArt-Σ在图像的保真度和文本提示的准确对应方面取得了显著的提升。PixArt-Σ的一个主要特点是其训练效率高。它利用PixArt-α的基础预训练,通过引入更高质量的数据,从一个较弱的基线模型演变成更强的模型,这一过程被称为“弱到强训练”。
地址:https://pixart-alpha.github.io/PixArt-sigma-project/

更多AI工具,参考国内AiBard123,Github-AiBard123















)



