文章目录
- 简介
- 摘要
- 引言
- 多模态思维链推理的挑战
- 多模态CoT框架
- 多模态CoT模型架构细节
- 编码模块
- 融合模块
- 解码模块
- 实验结果
- 总结
简介
本文主要对2023一篇论文《Multimodal Chain-of-Thought Reasoning in Language Models》主要内容进行介绍。
摘要
大型语言模型(LLM)通过利用思想链(CoT)提示生成中间推理链作为推断答案的基本原理,在复杂推理方面表现出了令人印象深刻的性能。然而,现有的CoT研究主要集中在语言模态上。这篇文章提出了多模态CoT,将语言(文本)和视觉(图像)模式结合到一个分为两个阶段的框架中,该框架将基本原理生成和答案推理分开。通过这种方式,答案推理可以利用基于多模式信息的更好生成的理由。使用多模CoT,模型在10亿个参数下的性能比以前最先进的LLM(GPT-3.5)高出16个百分点(75.17%→91.68%的准确率),甚至超过了ScienceQA基准的人类表现。
引言
阅读一本没有数字或表格的教科书。通过联合建模不同的数据模式,如视觉、语言和音频,我们的知识获取能力大大增强。大型语言模型(LLM)通过在推断答案之前生成中间推理步骤,在复杂推理中表现出了令人印象深刻的性能。这种有趣的技术被称为思维链推理(CoT)。
然而,现有的与CoT推理相关的研究在很大程度上是孤立在语言模态中的,很少考虑多模态场景。为了在多模态中引出CoT推理,文章提倡多模态CoT范式。
给定不同模态的输入,多模态CoT将多步骤问题分解为中间推理步骤(基本原理),然后推断答案。由于视觉和语言是最流行的模式,我们在这项工作中重点关注这两种模式。
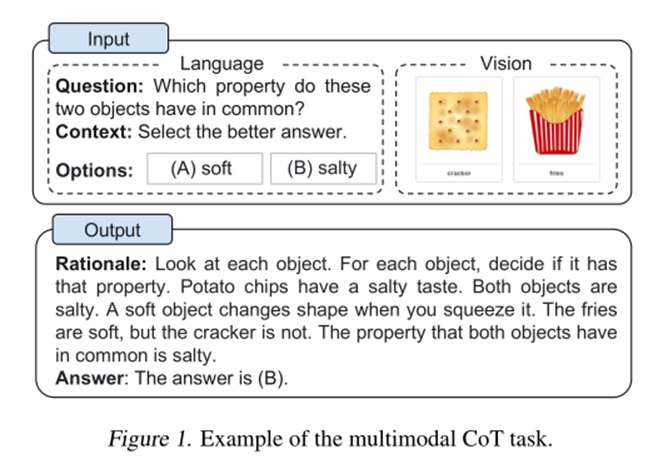
一个示例如图1所示。
通常,有两种方法可以引发多模式CoT推理:
(i)提示LLM
(ii)微调小模型
执行多模式CoT的最直接方法是将不同模态的输入转换为一个模态,并提示LLM执行CoT。例如,可以通过字幕模型提取图像的字幕,然后将字幕与要输入LLM的原始语言连接起来。然而,在字幕制作过程中存在严重的信息丢失;因此,使用字幕(与视觉特征相反)可能会在不同模态的表示空间中缺乏相互协同作用。
为了促进模态之间的交互,另一个潜在的解决方案是通过融合多模态特征来微调较小的语言模型。
由于这种方法允许灵活地调整模型架构以包含多模式特征,在这项工作中研究了微调模型,而不是提示LLM。
我们都知道1000亿参数(100B)下的语言模型往往会产生幻觉推理,误导答案推理。
为了减轻幻觉的挑战,文章提出了多模态CoT,将语言(文本)和视觉(图像)模式结合到一个分为两个阶段的框架中,该框架将原理生成和答案推理分开。通过这种方式,答案推理可以利用基于多模式信息的更好生成的理由。我们的实验是在ScienceQA基准上进行的,这是最新的带有注释推理链的多模式推理基准。实验结果表明,我们的方法比以前的GPT-3.5模型提高了+16%(75.17%→91.68%)。文章的贡献总结如下:
(i) 这项工作是第一次以不同的方式研究CoT推理。
(ii)提出了一个两阶段框架,通过微调语言模型来融合视觉和语言表示,以执行多模式CoT。该模型能够生成信息理性,以便于推断最终答案。
(iii)文章的方法在ScienceQA基准上实现了最先进的新性能,比GPT-3.5的精度高出16%,甚至超过了人类的性能。
多模态思维链推理的挑战
现有研究表明,CoT推理能力可能在一定规模的语言模型中出现,例如超过100B参数的大模型。然而在1B模型中激发这种推理能力仍然是一个悬而未决的挑战,更不用说在多模式场景中了。
这篇文章的重点是在1B左右模型,因为这样可以与常规消费级GPU(例如,32G内存)一起进行微调和部署。接下来将阐述1B模型在CoT推理中失败的原因,并研究如何设计一种有效的方法来克服这一挑战。
下面有个有趣的现象:
在ScienceQA基准上微调了CoT推理的纯文本基准模型。采用UnifiedQA-Base作为主干语言模型。任务为文本生成问题,其中模型将文本信息作为输入,并生成由基本原理和答案组成的输出序列。如图1所示的示例,该模型将问题文本(Q)、上下文文本(C)和多个选项(M)的标记串联作为输入。
为了研究CoT的影响,我们将其与三种变体的性能进行了比较:
(i) 直接预测答案,无CoT(QCM→A)
(ii) 推理,其中答案推理以基本原理为条件(QCM→RA);
(iii) 使用基本原理解释答案推理的解释(QCM→AR)。

令人惊讶的是,我们观察到准确性下降12.54%(80.40%→67.86%),如果模型在回答之前预测理性(QCM→RA)。结果表明,这些理由可能不一定有助于预测正确的答案。
其中的原因可能是模型在获得所需答案之前超过了最大token限制,或者提前停止生成预测。
然而,文章发现生成的输出(RA)的最大长度总是小于400个token,这低于语言模型的长度限制。因此,对理性危害答案推理的原因进行更深入的探讨是值得的。
为了进一步探究上述情况形成的原因,并深入研究原理如何影响答案预测,本文将CoT问题分为两个阶段,即原理生成和答案推理。基本原理生成使用RougeL分数来评估和答案推理使用准确性评估。表3显示了基于两阶段框架的结果。尽管两阶段基线模型在基本原理生成方面获得了91.76的RougeL分数,但答案推理的准确率仅为70.53%。
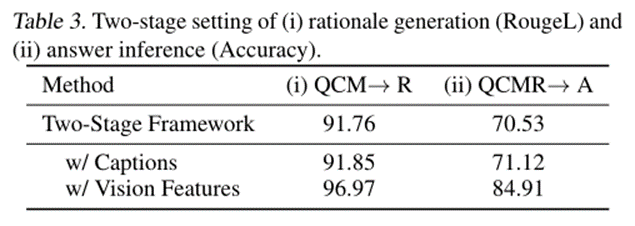
与表2中的QCM→A(80.40%)相比,结果表明,在两阶段框架中生成的基本原理并不能提高答案的准确性。

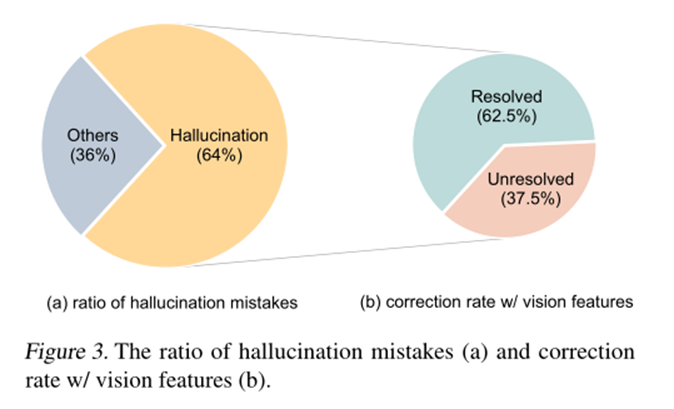
接着随机抽样50个错误案例,发现模型倾向于产生幻觉推理,误导答案推理。如图2所示的例子,由于缺乏对视觉内容的参考,模型(左部分Baseline)产生了“一个磁体的南极最接近另一磁体的南极”的幻觉。在错误案例中,此类错误的发生率为64%。
文章推测,这种幻觉现象是由于缺乏执行有效的多模CoT所需的视觉上下文。为了注入视觉信息,一种简单的方法是将配对的图像转换为字幕,然后将字幕附加在两个阶段的输入中。然而,如表3所示,使用字幕只会产生边际性能增益(增加0.59%). 然后,通过将视觉特征纳入语言模型来探索一种先进的技术。具体而言,将配对图像输入到DETR模型中,以提取视觉特征。然后在提供给解码器之前融合视觉特征,使用编码的语言表示。有了视觉特征,基本原理生成的RougeL分数提高到了96.97%(QCM→R) ,这相应地有助于提高84.91%的回答准确率(QCMR→A.有了这些有效的理由,幻觉现象得到了缓解——其中62.5%的幻觉错误已经得到纠正(图3(b))。这表明,视觉特征确实有利于生成有效的理由并有助于准确的答案推断。作为两阶段方法(QCMR→A) 表3中的方法比表2中的所有一阶段方法都获得了更好的性能,在多模态CoT框架中选择了两阶段方法。
多模态CoT框架
基于之前的分析,多模式CoT将语言(文本)和视觉(图像)模式合并到一个两阶段的框架中,以减少幻觉输出,提升模型的效果。
多模式CoT由两个训练阶段组成:
(i) 基本原理生成
(ii) 答案推理
两个阶段共享相同的模型体系结构,但输入X和输出Y不同。
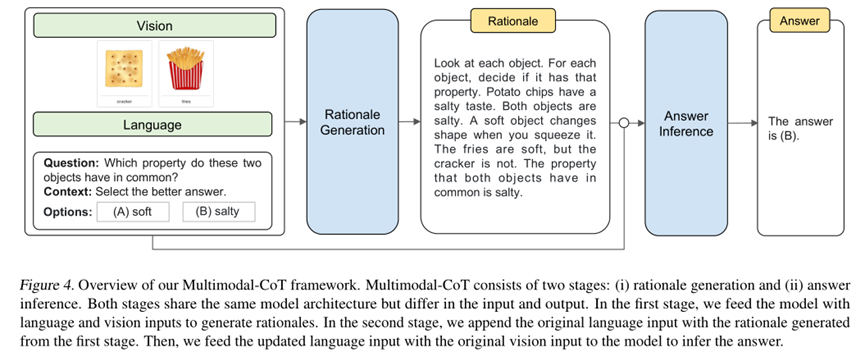
整个过程如图4所示。
在基本原理生成阶段,模型的输入为X,其中X如下:

其中括号中的前者表示第一阶段中的语言输入,后者表示视觉输入,即图像。
X可以看做实例化为多选推理问题的问题、上下文和选项的拼接,如图4所示。目标是学习一个基本原理生成模型R=F(X),其中R是基本原理。
在答案推理阶段,将基本原理R融入到到原始语言输入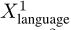 ,因此继续构建第二阶段的语言输入:
,因此继续构建第二阶段的语言输入: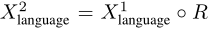 其中◦ 表示拼接。然后,我们将更新后的输入
其中◦ 表示拼接。然后,我们将更新后的输入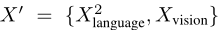 馈送到答案推理模型,以推断最终答案
馈送到答案推理模型,以推断最终答案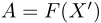 。
。
现在回过头来看图4,应该就比较清晰明了了。
多模态CoT模型架构细节
上面我们已经知道了文章的多模态CoT流程是怎么样的了,接下来将分析其中关键的模型架构细节也就是上文提到的F( ),以便我们能够对多模态CoT有更深入的理解。
F( )可以分为三个模块:编码模块、融合模块、解码模块
编码模块
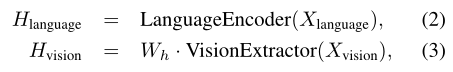
其中
LanguageEncoder(·)指的就是transformer的encoder部分,输出的就是Transformer编码器中最后一层的隐藏状态。
VisionExtractor(·) 用于将输入图像矢量化为视觉特征,使用的应该是现成的视觉提取模型(DETR),其实应该也是类似transformer的encoder,因为计算机视觉中,也有vision transformer。
融合模块
在编码模块获得到文本和图片的表示后,先进行注意力计算,将文本和图像信息联系起来:
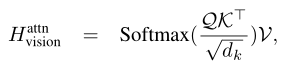
其中Q、K、V分别为
然后使用门控融合机制进行特征融合:
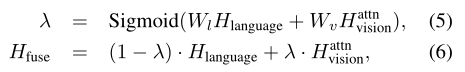
其中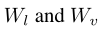 都是可训练的参数。
都是可训练的参数。
解码模块
这里就比较简单,使用的就是transformer的decoder 作为输入,输出为我们需要的Y
作为输入,输出为我们需要的Y
至此,我们对多模态CoT应该有一个比较深入的了解了,关键内容其实就是使用encoder将文本信息和图像信息表示出来,使用门控融合机制进行特征融合,然后预测出我们需要的结果这个过程就是F( )。
所以多模态CoT完整的流程就是先将初始的文本和图像输入F( )得到图片和原始文本融合之后的CoT,然后再使用CoT的结果增强原始文本信息后得到的结果,再和图片信息输入F( )得到我们最终需要的预测结果。此时再去看图4,应该就一目了然了。
实验结果
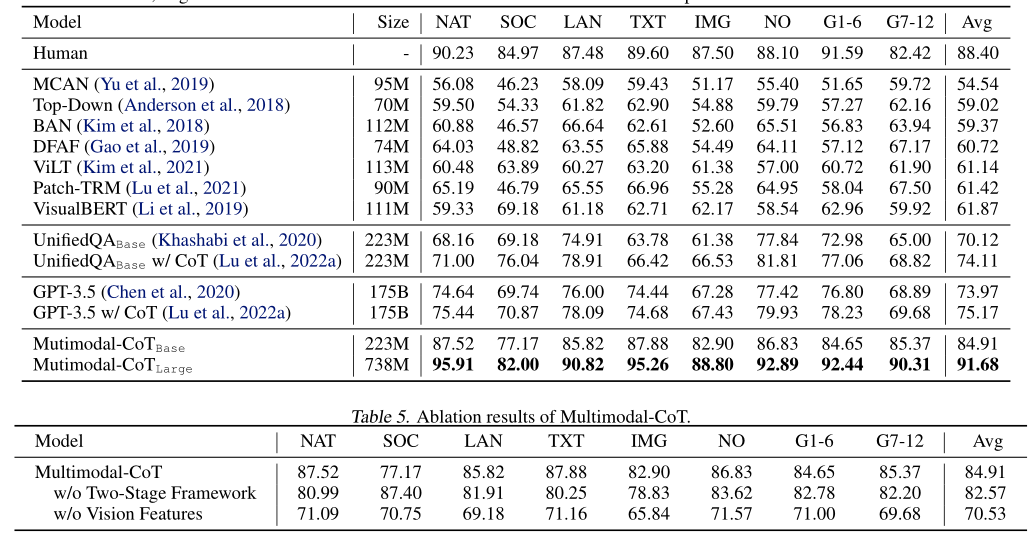
表4显示了主要结果。Mutimodal CoTLarge比GPT-3.5高16.51%(75.17%→91.68%),并超过人类表现。具体而言,在8个问题类别中,Mutimodal CoT Large的得分为21.37%(67.43%→88.80%)的性能增益。与现有的UnifiedQA和GPT-3.5方法相比,这些方法利用上下文中的图像字幕来提供视觉语义,结果表明使用图像特征更有效。此外,根据表5中的消融研究结果,我们的两阶段框架有助于获得优异的结果。总体而言,结果验证了多模态的有效性以及通过两阶段框架使用1B模型实现CoT推理的潜力。
总结
使用图像信息增强文本CoT,减少模型幻觉,提升模型效果,蛮有意思的




![[pcie]通过sysfs访问PCI设备资源](http://pic.xiahunao.cn/[pcie]通过sysfs访问PCI设备资源)







redo 日志)






