本文由清华大学和理想汽车共同发布于2024年2月25日,论文名称DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models.
DriveVLM是一种新颖的自动驾驶系统,旨在针对场景理解挑战,利用最近的视觉语言模型VLM,在视觉理解和推理方面表现出非凡的优势。DriveVLM模型具有三个关键模块:场景描述、场景分析和分层规划。
个人觉得本文偏工程性质,以点带面,可以窥探到很多东西。
- 17个自动驾驶meta-action元操作的定义。
- 40个自动驾驶场景定义。
- 全面的数据挖掘和标注, 形成了场景理解和规划SUP-AD 数据集。
- 长尾目标挖掘
- 挑战场景挖掘
- 关键帧选择
- 场景标注
- 场景描述,包括环境描述和关键目标识别。
- 场景分析,对场景的全面把握,分析关键目标的特征和对自车潜在影响,总结环境描述。
- 分层规划,进一步与路线、自车姿势和速度相结合,形成规划提示。
- 利用官方GPT-4 API进行打分、评估。
- 利用性能较好的开源大视觉语言基础模型如Qwen-VL。
本文由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑。如有错误,欢迎在评论区指正。
Abstract
城市环境中自动驾驶的一个主要障碍是理解复杂和长尾驾驶场景,如具有挑战性的道路情况和微妙的人类行为。我们推出了 DriveVLM,这是一种利用视觉语言模型 (VLM) 的自动驾驶系统,以增强场景理解和规划能力。DriveVLM集成了独特的用于场景描述、场景分析和分层规划的思维链 (CoT) 模块。此外,认识到VLM在空间推理和需要大量计算的局限性,我们提出了DriveVLM-Dual,这是一种混合系统,它将DriveVLM的优势与传统的自动驾驶pipeline相结合。DriveVLM-Dual 实现了强大的空间理解和实时的推理速度。在nuScenes数据集和我们的SUP-AD数据集上,大量实验证明了DriveVLM的有效性和DriveVLM-Dual的增强性能,在复杂和不可预测的驾驶条件下超过了现有的方法。
Introduction
自动驾驶在过去二十年中一直是最活跃的研发领域之一,它有望彻底改变交通和城市出行方式。完全自动驾驶系统的一个主要障碍是场景理解,它涉及复杂的导航、不可预测的场景,如恶劣天气、复杂的道路布局和不可预见的人类行为等等。现有的自动驾驶系统,通常包括 3D 感知、运动预测和规划,难以应对理解这些场景的挑战。具体来说,3D感知仅限于检测和跟踪熟悉的对象,忽略了稀有对象及其独特属性;运动预测和规划侧重于轨迹级别动作,通常忽略物体和车辆之间的决策级别交互。我们介绍了 DriveVLM,这是一种新颖的自动驾驶系统,旨在针对场景理解挑战,利用最近的视觉语言模型 (VLM),它们在视觉理解和推理方面表现出非凡的优势。
具体来说,DriveVLM 包含一个 Chain-of-Though (CoT) 过程,具有三个关键模块:场景描述、场景分析和分层规划。场景描述模块在语言上描述了驾驶环境并识别场景中的关键目标;场景分析模块深入研究了关键目标的特征及其对自车的影响;分层规划模块逐步制定计划,从元操作和决策描述到航路点。这些模块分别对应于传统perception-prediction-planning组件,但不同之处在于,它们处理的是目标感知、意图层面的预测和任务层面的规划,这些在过去都是极具挑战性的。
虽然VLM擅长视觉理解,但它们在空间锚定和推理方面存在局限性,并且计算强度对机载推理速度提出了挑战。因此,我们进一步提出了 DriveVLM-Dual,这是一种结合了 DriveVLM 和传统驾驶系统优势的混合系统。DriveVLM-Dual 可选地将 DriveVLM 与传统的 3D 感知和规划模块(例如 3D 对象检测器、占用网络和运动规划器)集成,使系统能够实现 3D grounding and high-frequency planning 能力。这种双系统设计,类似于人脑 slow-fast 的思维过程,有效地适应驾驶场景中不断变化的复杂性。
同时,我们正式定义了场景理解和规划(SUP)任务,并提出了新的评估指标来评估 DriveVLM 和 DriveVLM-Dual 的场景分析和 meta-action planning 元操作规划能力。此外,我们进行了全面的数据挖掘和标注,为 SUP 任务构建了一个内部 SUP-AD 数据集。在nuScenes数据集和我们的SUP-AD数据集上进行的大量实验,特别是在few-shot的情况下证明了DriveVLM的优越性。此外,DriveVLM-Dual 超越了最先进的端到端运动规划方法。总之,本文的贡献有四个方面:
- 我们引入了 DriveVLM,这是一种新颖的自动驾驶系统,它利用 VLM 进行有效的场景理解和规划。
- 我们进一步介绍了DriveVLM Dual,这是一种混合系统,融合了DriveVLM和传统的自动驾驶pipeline。DriveVLM-Dual 实现了改进的空间推理和实时规划能力。
- 我们提出了一个全面的数据挖掘和标注pipeline来构建场景理解和规划数据集SUP-AD,以及评估 SUP 任务的指标。
- 大量实验表明,在nuScenes和SUP-AD数据集上,DriveVLM和DriveVLM-Dual在复杂驾驶场景中有优越的性能。
Related Work
Vision-Language Models,VLMs
最近,人们对大型视觉语言模型 (VLM) 的研究激增,例如 MiniGPT-4、LLAVA、Qwen-VL 等作品。这些模型将预训练视觉编码器与大型语言模型相结合,使大型语言模型能够处理许多涉及图像作为输入的任务。一般来说,这些方法通过 Q-former 或线性映射将图像特征与语言模型的输入embedding 空间对齐。训练过程中的一个关键步骤是使用包含图像和文本的指令数据进行监督微调,提高了视觉语言模型的整体性能。VLM 可用于各种场景,尤其是机器人。具体来说,给定指令、输入图像和机器人状态,视觉语言模型输出相应的动作,可以是高级指令或低级的机器人动作。DriveVLM 专注于利用 VLM 来辅助自动驾驶,从而建立了一个新颖的框架。在我们工作的同时,DriveGPT4也具有相似的动机。
Learning-based Planning
自 Pomerleau的开创性工作以来,学习框架集成到运动规划中一直是一个活跃的研究领域。一种很有前途的工作是强化学习和模仿学习。这些方法可以学习端到端规划策略,该策略直接将原始感官输入映射到控制动作。它们特别适合高维状态和动作空间,这是运动规划的一个常见挑战。然而,从传感器数据直接生成控制输出对鲁棒性和安全保证提出了重大挑战。一些作品通过明确构建源自基于学习模块的密集cost maps来提高可解释性。虽然密集cost maps有效地整合了对交通代理的未来运动和环境因素预测,但它们的性能在很大程度上取决于通过人类经验和轨迹抽样分布量身定制的cost。最近的趋势是以端到端的方式训练多个块。这些方法提高了整体性能,但在不太可解释的决策过程中,依赖于未来轨迹预测损失的反向传播。我们的模型 DriveVLM 通过利用视觉语言模型的泛化和推理能力,解决了长尾驾驶场景的复杂性。此外,用户可以通过视觉语言模型提供的直观语言界面轻松地与我们的模型交互,增强了可解释性。
Driving Caption Datasets
最近的工作认为语言提示是将人类知识与驾驶目标联系起来的重要媒介,这有助于告知决策和行动。为了支持这一趋势,一些工作增强了主流驾驶场景数据集。
- reference -KITTI用语言提示符对KITTI数据集目标进行标注,这些语言提示符可以引用目标集合。
- Talk2Car、NuPrompt和 nuScenes-QA 将free-form的题注和 QA 标注引入到 nuScenes 数据集。然而,这些作品丰富了以感知为中心的数据集,并且通常包含简单的交通场景。
- BDD-X 和BDD-OIA 没有扩充现有的数据集,而是为数据集提供了对自车行为的自然语言解释。
- HAD 使用自然语言指令从驾驶员的注视数据中生成显著图。
- Rank2Tell和DRAMA对交通场景的语言解释和风险定位进行了注释。虽然这些数据集为使用自然语言提供了量身定制的场景,但缺乏足够的数据来捕捉场景。而这些场景对于识别自动驾驶系统中可能导致安全的问题,至关重要。
- 相比之下,SUP-AD数据集有目的地收集了各种具有挑战性的长尾场景,这些场景对于解决复杂的场景理解和规划至关重要。
DriveVLM
Overview
DriveVLM 的整体流程如图 1 所示。

DriveVLM and DriveVLM-Dual model pipelines
DriveVLM 接受图像序列作为输入,并通过思维链 (CoT) 机制输出场景描述、场景分析和分层规划结果。DriveVLM-Dual进一步结合了传统的3D感知和轨迹规划模块,实现了空间推理能力和实时轨迹规划。
Scene Description
场景描述模块由环境描述和关键目标识别组成。
Environment description
驾驶环境,如天气和路况,对驾驶难度有不可忽视的影响。因此,首先提示模型输出驾驶环境的语言描述 E,包括几个条件:E ={Eweather, Etime, Eroad, Elane},每个条件代表驾驶环境的一个关键方面。
- Eweather 详细介绍了天气条件,从晴天到雪天不等。由于能见度降低和道路打滑,雨或雾等条件需要更谨慎的驾驶方法。
- Etime 封装了一天的时间,区分白天和夜间驾驶场景。例如,以能见度降低为特征的夜间驾驶需要谨慎的驾驶策略。
- Eroad 对道路类型进行分类,包括城市、郊区、农村或高速公路,每种道路类型都会带来独特的挑战。
- Elane对车道条件的描述,识别车辆当前车道和机动的潜在备选方案。这些信息对于车道选择和安全变道至关重要。
Critical object identification
除了环境条件外,驾驶场景中的各种目标也会影响驾驶行为。与传统驾驶感知模块检测特定范围内的所有目标不同,我们受驾驶过程中人类认知过程的启发,只关注识别最有可能影响当前场景的关键目标。每个关键目标,表示为 Oc,包含两个属性:图像上的目标类别 c 及其近似边界框坐标 b(x1, y1, x2, y2)。类别和坐标被映射到它们在语言模态中的相应语言 token_id,从而能够无缝集成到后面模块中。此外,利用预先训练的视觉编码器,DriveVLM可以识别长尾关键目标,这些目标可能避开典型的3D目标检测器,如道路碎片或不寻常的动物。
Scene Analysis
在传统的自动驾驶pipeline中,预测模块通常专注于预测物体的未来轨迹。高级视觉语言模型的出现为我们提供了对当前场景进行更全面的分析能力。
Critical Object Analysis
在识别关键目标后,我们分析了它们的特征和对自车潜在的影响。特征包含关键目标的三个方面:静态属性Cs、运动状态Cm和特定行为Cb。
静态属性 Cs 描述了目标固有属性,例如路边广告牌的视觉提示或卡车的超大货物,这对于抢占和导航潜在危害至关重要。
运动状态 Cm 描述了物体在一段时间内的动态,包括位置、方向和动作——这些特征对于预测物体未来轨迹和与自车的潜在相互作用至关重要。
特殊行为 Cb 是指可以直接影响自下一个驾驶决策对象的特殊动作或手势。例如,交通官员的手部信号在这种情况下至关重要,因为它们可以覆盖标准交通规则,并且需要来自驾驶系统的相应响应。我们不需要模型分析所有目标的三个特征(Cs,Cm,Cb)。在实践中,只有一个或两个适用于关键目标。
在分析这些特征后,DriveVLM 预测每个关键目标对自车的潜在影响 I。例如,路边drunken行人可能会踩到行驶路上,并阻止我们的道路。与传统pipeline中的轨迹级预测相比,关键目标潜在影响分析对于系统适应现实世界和长尾驾驶场景至关重要。
Scene-level Summary S
场景级分析概括总结了所有关键目标和环境描述。该总结提供了对场景的全面理解,linking随后的规划模块。
Hierarchical Planning
我们整合场景描述和场景分析,形成驾驶场景的总结,进一步与路线、自车姿势和速度相结合,形成规划提示。最后,DriveVLM 逐步生成驾驶规划,分为三个阶段:元操作、决策描述和轨迹航路点。
Meta-actions A,元操作,表示为 ai,表示驾驶策略的短期决策。
这些操作分为 17 个类别,包括但不限于加速、减速、左转、改变车道、微小的位置调整等。
为了在一定时期内规划自车的未来操作,我们生成了一系列元操作。该序列中的每个元操作都至关重要,为车辆在场景中的策略性导航做出累积贡献。
Decision description D
决策描述 D 阐明了自车应该采用的细粒度驾驶策略。
它包含三个元素:操作 A、主体 S 和持续时间 D。操作与诸如“turn”、“wait”或“accelerate”之类的元操作有关。
主体是指交互对象,例如行人、交通信号或特定车道。
持续时间表示操作的时间方面,指定应该如何执行或何时应该开始的时间方面。
决策描述的一个例子是:“行人 (S) 到交叉 Wait (A),然后 (D) 继续加速 (A) 并合并到右车道 (S)。这种结构化决策描述允许对自治系统进行清晰、简洁和可操作的说明。
Trajectory waypoints W
在建立决策描述 D 后,我们的下一阶段涉及生成相应的轨迹航路点。这些航路点,用 W = {w1, w2,.., wn},wi = (xi, yi),以预定间隔 Δt 描述车辆在特定未来时间段内的路径。我们将这些数值航路点映射到语言tokens以进行自回归生成。通过这种方式,DriveVLM 实现了其语言处理模块与空间导航的无缝集成。轨迹航路点是元操作和决策描述的空间表现,可以直接输入到后续的控制模块中。
DriveVLM-Dual
尽管VLM擅长识别长尾目标和理解复杂场景,但它们通常难以准确理解物体的空间位置和详细的运动状态。在以前的研究和我们的试点研究中指出,这种不足带来了重大挑战。更糟糕的是,VLM的巨大模型尺寸导致了高延迟,阻碍了它们对自动驾驶的实时响应能力。为了应对这些挑战,我们提出了 DriveVLM-Dual,即 DriveVLM 和传统自动驾驶系统之间的协作。此种方法包含两个关键策略:结合 3D 感知进行关键目标分析,以及高频轨迹细化。
Integrating 3D Perception

使用相应3D物体的中心坐标、方向和历史轨迹作为模型的语言提示,辅助目标分析。相反,对于Ocunmatched 分析仅依赖于从图像派生的语言符号。这种新颖的3D感知结果作为提示,使DriveVLM-Dual能够更准确地了解关键目标的位置和运动,从而提高整体性能。
High-Frequency Trajectory Refinement
与传统的规划器相比,由于视觉语言模型(VLMs)固有的巨大参数尺寸,DriveVLM产生轨迹时,速度明显变慢。为了实现实时、高频的推理能力,我们将其与传统规划器集成,形成一个slow-fast双系统,将DriveVLM先进功能与传统高效率的规划方法相结合。从DriveVLM中获得低频的轨迹(记为Wslow)后,我们将其作为传统规划器高频轨迹细化的参考轨迹。对于基于优化的规划器,Wslow作为优化求解器的初始解决方案。对于基于神经网络的规划器,使用Wslow作为输入查询,结合额外的输入特征f,然后解码成一个新的规划轨迹,表示为Wfast。这一过程的表述可以描述为:

这一细化步骤确保了DriveVLM-Dual:
- 生成的轨迹达到更高的轨迹质量。
- 满足实时性要求。
在实际应用中,这两个分支以 slow-fast 的方式异步运行,其中传统自动驾驶分支中的规划器模块可以选择性地从 VLM 分支接收轨迹作为附加输入。
(备注:目前自动驾驶端到端大模型范式都是这样部署。为了确保安全,传统规划模块保底,增加了智能的新模型作为附加输入。这样,改动感知、预测和规控模块的开发量也最小,传统范式更换为端到端是一个渐进过程。)
Task and Dataset
为了充分利用DriveVLM和DriveVLM-Dual在处理复杂和长尾驾驶场景中的潜力,我们正式定义了一个称为规划场景理解的任务(第4.1节),以及一组评估指标(第4.2节)。此外,我们提出了一个数据挖掘和标注协议来构建一个场景理解和规划数据集(第4.3节)。
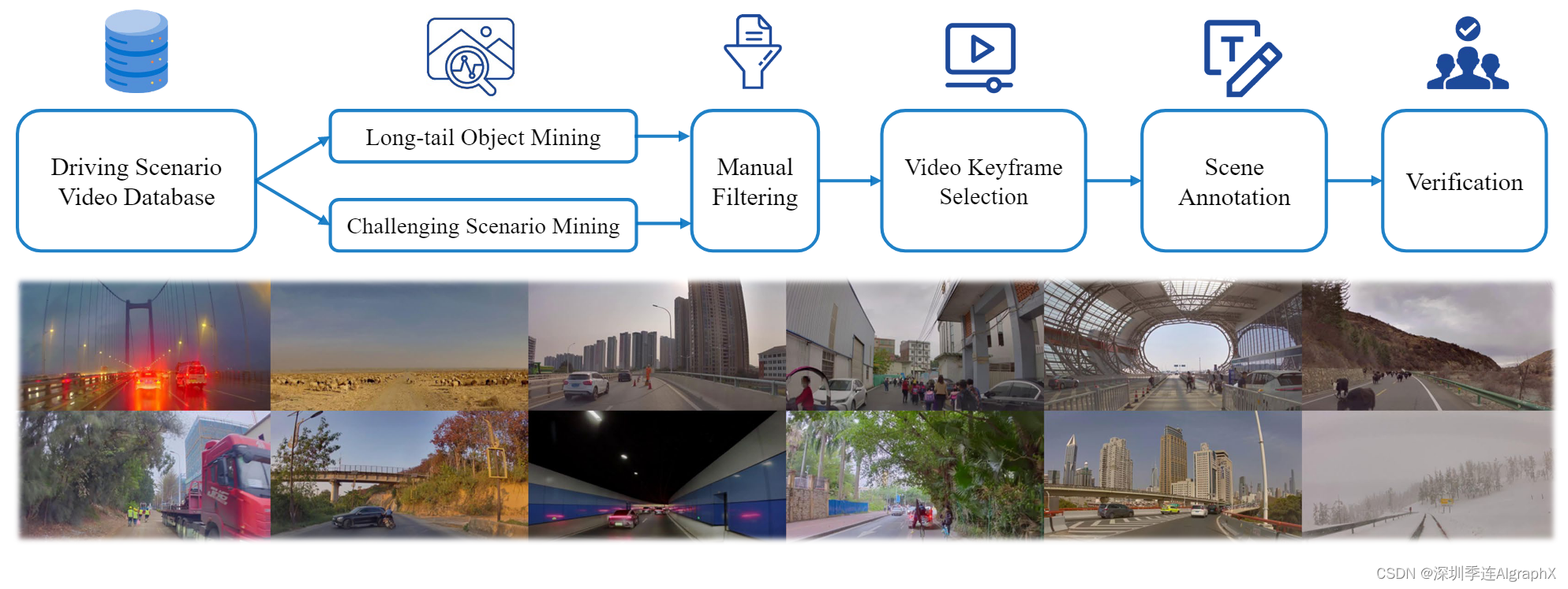
用于构建场景理解和规划数据集的数据挖掘和标注pipeline( 图 3 上);从数据集中随机抽取的场景示例(图 3 下)展示了数据集的多样性和复杂性。
Task Definition
规划任务的场景理解定义如下。输入包括来自周围摄像机的多视图视频V和来自感知模块的可选3D感知结果p。输出内容包括:
- Scene Description E: 由天气条件eweather、时间条件Etime、道路条件Eroad、车道条件Elane组成。
- Scene Analysis S: 包括对象级分析和场景级总结S。
- Meta Actions A: 表示任务级操作的操作序列。
- Decision Description D: 驾驶决策的详细说明。
- Trajectory Waypoints W : 勾勒出自车规划轨迹的航路点。
Evaluation Metrics
为了全面评估一个模型的性能,我们关心的是它对驾驶场景的解释和做出的决策。因此,我们的评价有两个方面: 场景描述/分析评价和元行为评价。
Scene description/analysis evaluation
考虑到场景描述中人类评估的主观性,我们采用了一种使用预训练 LLM的结构化方法。这种方法需要将生成的场景描述与人工注释的ground truth描述进行比较。地面真值描述包含结构化数据,如环境条件、导航、车道信息和具有特定目标、动作及其影响的关键事件。LLM根据生成的描述与地面真值的一致性对其进行评估和评分。
我们利用 GPT-4 来评估模型生成的场景描述与手动标注地面真值之间的相似性。

Meta-action evaluation
元操作是一个决策选择的集合,驾驶决策被表述为一系列元操作。我们的评估方法采用动态规划算法将模型生成的序列与手动注释的地面真值序列进行比较。评估还应该权衡各种元操作的相对重要性,指定一些对序列整体环境影响较小的“保守操作”。另外,我们首先使用LLM生成语义上等效的替代方案来增强地面真值序列的鲁棒性。与这些备选方案相似度最高的序列计算最终的驾驶决策得分。相关指标的详细信息,可查看附录B。

Dataset Construction
我们提出了一个全面的数据挖掘和标注pipeline,如图3所示,为本文提议的任务构建一个场景理解规划(SUP-AD)数据集。具体来说,我们从大型数据库中进行长尾对象和挑战场景挖掘,收集样本,然后从每个样本中选择一个关键帧,进一步进行场景标注。数据集统计,可在附录A中获得。
元操作分为17类,这些元操作旨在包含完整的驾驶策略,并与自车的未来轨迹保持一致。它们可以分为速度控制、转向和车道控制三个主要部分。
- Change lane to the left
- Change lane to the right
- Go straight at a constant speed
- Go straight slowly
- Reverse
- Shift slightly to the left
- Shift slightly to the right
- Slow down
- Speed up
- Speed up rapidly
- Stop
- Turn around
- Turn left
- Turn right
- Wait
SUP-AD数据集涵盖了40多个类别的不同驾驶场景。
- AEB Data: Automatic Emergency Braking (AEB) data.
- Road Construction: A temporary work zone with caution signs, barriers, and construction equipment ahead.
- Close-range Cut-ins: A sudden intrusion into the lane of the ego vehicle by another vehicle.
- Roundabout: A type of traffic intersection where vehicles travel in a continuous loop.
- Animals Crossing Road: Animals crossing the road in front of the ego vehicle.
- Braking: Brake is pressed by human driver of the ego vehicle.
- Traffic Police Officers: Traffic police officers managing and guiding traffic.
- Blocking Traffic Lights: A massive vehicle obscuring the visibility of the traffic signal.
- Cutting into Other Vehicle: Intruding into the lane of another vehicle ahead.
- Ramp: A curved roadway that connects the main road to the branch road in highway.
- Debris on the Road: Road with different kinds of debris.
- Narrow Roads: Narrow roads that require cautious navigation.
- Pedestrians Popping Out: Pedestrians popping out in front of the ego vehicle, requiring slowing down or braking.
- People on Bus Posters: Buses with posters, which may interfere the perception system.
- Merging into High Speed: Driving from a low-speed road into a high-speed road, requiring speeding up.
- Barrier Gate: Barrier gate that can be raised obstructing the road.
- Fallen Trees: Fallen trees on the road, requiring cautious navigation to avoid potential hazards.
- Complex Environments: Complex driving environments that requiring cautious navigation.
- Mixed Traffic: A congested scenario where cars, pedestrians, and bicycles appear on the same or adjacent roadway.
- Crossing Rivers: Crossing rivers by driving on the bridge.
- Screen: Roads with screens on one side, which may interfere the perception system.
- Herds of Cattle and Sheep: A rural road with herds of cattle and sheep, requiring careful driving to avoid causing distress to these animals.
- Vulnerable Road Users: Road users which are more susceptible to injuries while using roads, such as pedestrians, cyclists, and motorcyclists.
- Road with Gallet: A dusty road with gallet scattered across the surface.
- 其余的场景类别是:摩托车和三轮车,十字路口,带伞的人,载车的车辆,载树枝的车辆,带管道的车辆,婴儿车,儿童,隧道,下坡,人行道摊位,雨天,穿越火车轨道,无保护的u形转弯,降雪,大型车辆入侵,落叶,烟花,洒水器,坑洼,翻倒的摩托车,自燃和火灾,风筝,农业机械。

Long-tail object mining
根据现实世界的道路对象分布,我们首先定义了一个长尾对象类别列表。例如形状怪异的车辆、道路碎片和过马路的动物。
接下来,我们使用基于 CLIP 的搜索引擎挖掘这些长尾场景,该引擎能够使用来自大量日志的语言查询挖掘驾驶数据。
接下来,我们执行手动检查以过滤掉与指定类别不一致的场景。
Challenging scenario mining
除了长尾目标,我们还对具有挑战性的驾驶场景感兴趣,其中自车的驾驶策略需要根据不断变化的驾驶条件进行调整。这些场景是根据记录的驾驶动作变化挖掘来的。
Key frame selection
每个场景都是一个视频剪辑,必须确定“关键帧”进行标注。在大多数具有挑战性的场景中,关键帧是在速度或方向发生重大变化之前的时刻。我们在综合测试的基础上,选择比实际机动早0.5s ~ 15 s的关键帧,以保证决策的最佳反应时间。对于不涉及驾驶行为变化的场景,我们选择与当前驾驶场景相关的帧作为关键帧。
Scene annotation
我们雇佣了一组标注者来执行场景标注,包括场景描述、场景分析和规划。除了航路点,它可以从车辆的IMU记录中自动标注。为了方便场景标注,我们制作了一个视频标注工具,该工具具有以下特点:
- 标注者可以前后滑动进度条来回放视频的任何部分。
- 在对关键帧进行标注时,标注者可以在图像上绘制边框以及语言描述。
- 标注者在标注驾驶规划时,可以从行动和决策候选人列表中进行选择。每个标注都经过3个标注员的精心验证,以确保准确性和一致性,确保模型训练的可靠数据集。图2展示了一个带有详细标注的示例场景。

An annotated sample of the SUP-AD dataset

Experiments
Settings
Datasets
SUP-AD数据集。SUP-AD数据集是我们提出的数据挖掘和标注pipeline构建的数据集。分为训练集、验证集和测试集,比例为7.5:1:1 .5。我们在训练集上训练模型,并使用我们提出的场景描述和元操作度量,评估模型在验证/测试集上的性能。
nuScenes数据集。nuScenes数据集是一个包含1000个场景的大型城市场景驾驶数据集,每个场景持续约20秒。关键帧在整个数据集上以2Hz的频率均匀标注。根据之前的工作,我们采用位移误差(DE)和碰撞率(CR)作为指标来评估模型在验证集上的性能。
Base Model
我们使用Qwen-VL作为默认的大型视觉语言模型,该模型在问答、视觉定位和文本识别等任务中表现出色。
它总共包含96亿个参数,其中包括视觉编码器(19亿)、视觉语言适配器(0.08亿)和大型语言模型(Qwen, 77亿)。图像在被视觉编码器编码之前被调整为448 × 448的分辨率。在训练过程中,我们随机选择当前时刻T s,T - 1s,T - 2s, T - 3s的图像序列作为输入。所选图像确保包含当前时间帧,并遵循升序时间顺序。

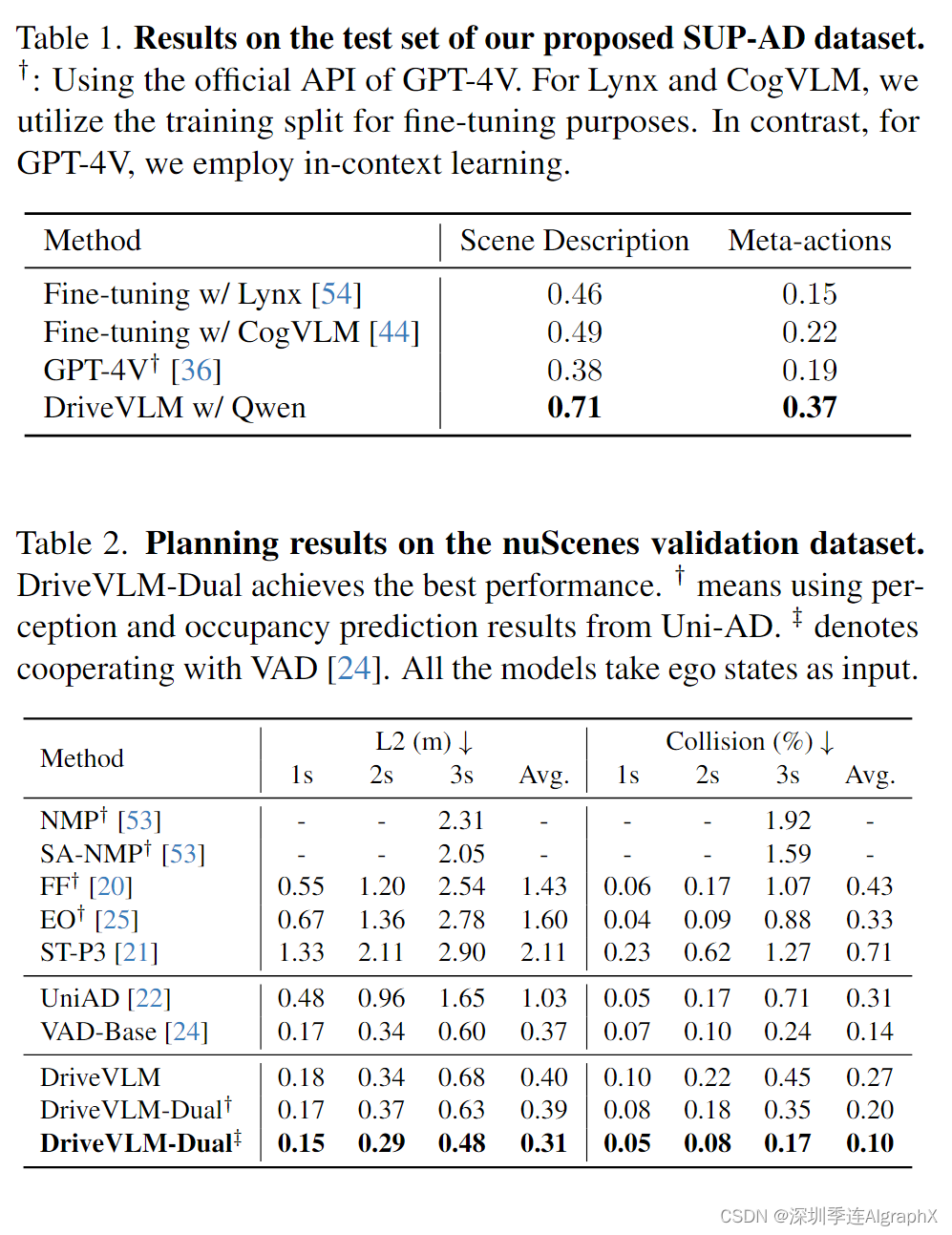
Main Results
Ablation Study
Model Design
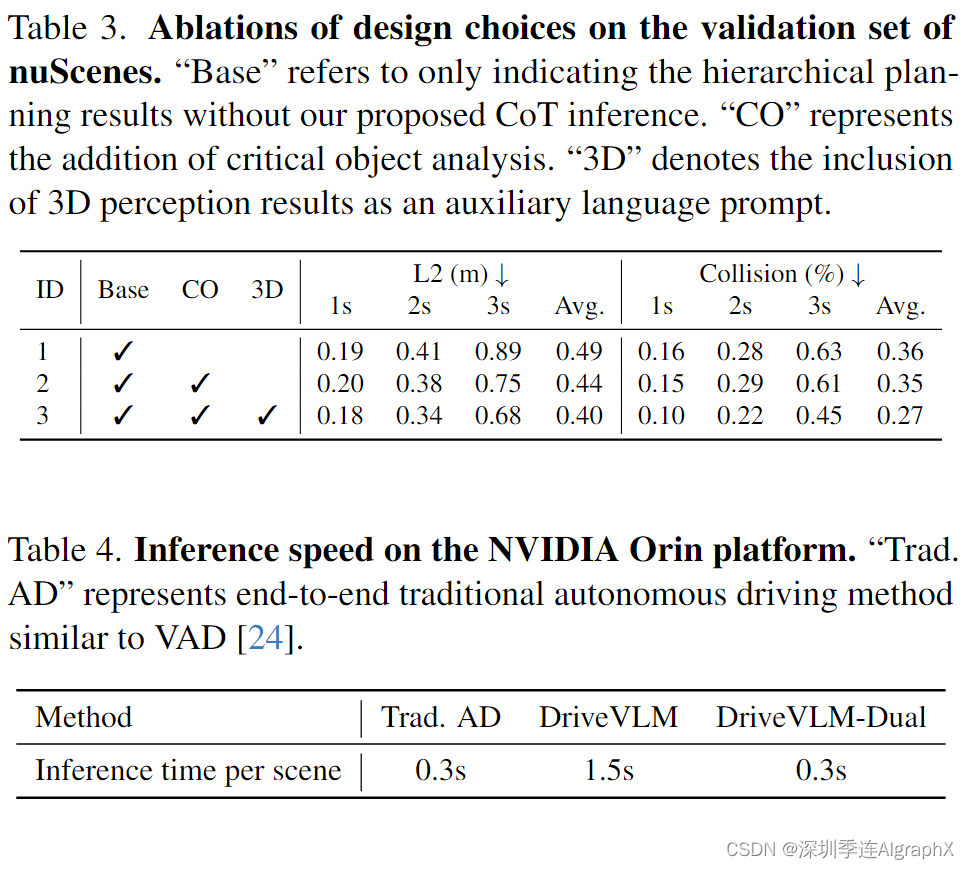
为了更好地理解我们设计的模块在DriveVLM中的意义,我们对模块的不同组合进行了对比,如表3所示。关键目标分析使我们的模型能够识别和优先考虑驾驶环境中的重要元素,提高决策的准确性,以实现更安全的导航。整合3D感知数据,我们的模型获得了对周围环境的精细理解,这对于捕获运动动力学和改进轨迹预测至关重要。
Inference speed
DriveVLM和DriveVLM- dual的推理速度在NVIDIA Orin平台上测量,如表4所示。由于LLM的参数数量庞大,DriveVLM的推理速度比类似VAD的常规自动驾驶方法慢一个数量级,无法在车上运行。然而,在与传统的自动驾驶管道以slow-fast的合作模式合作后,整体延迟取决于快速分支的速度,使得DriveVLM-Dual成为现实部署的理想解决方案。
Qualitative Results

Conclusion
综上所述,我们介绍了DriveVLM和DriveVLM- dual。DriveVLM利用 VLM,在解释复杂驾驶环境方面取得了重大进展。DriveVLM-Dual通过协同现有的3D感知和规划方法进一步增强了这些功能,有效地解决了VLM 固有的空间推理和计算挑战。此外,我们还定义了自动驾驶规划任务的场景理解,以及评估指标和数据集构建协议。经过严格的评估,DriveVLM和DriveVLM-Dual已经证明了它们在自动驾驶方面超越当前最先进方法的能力,特别是在处理复杂和动态场景方面。我们相信,这项研究为未来开发安全和可解释的自动驾驶汽车提供了路线图。
https://arxiv.org/abs/2402.12289







)







)



