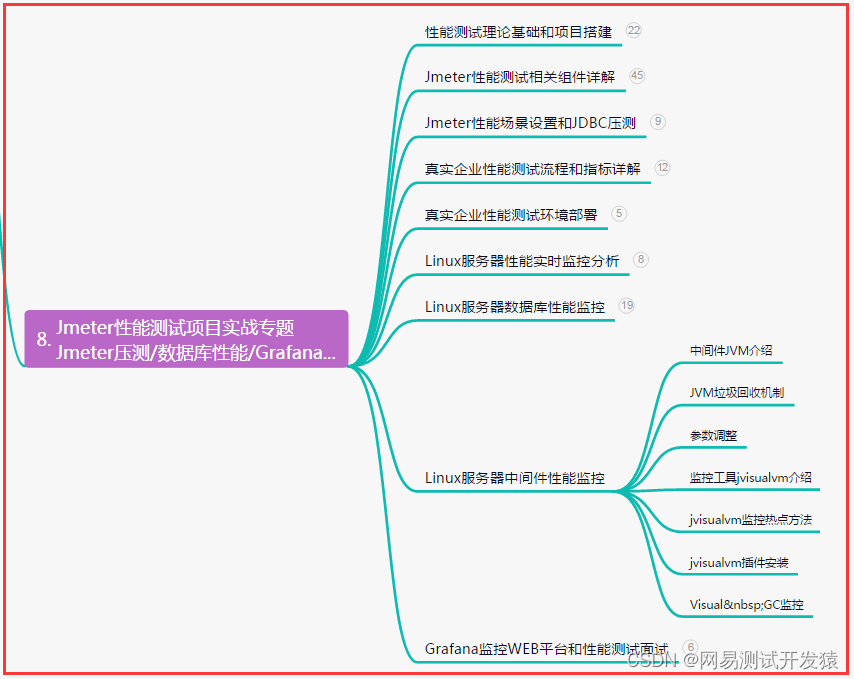
从MySQL数据库导入数据到Elasticsearch有几种方式,主要包括以下几种:

1. 使用Logstash:
Logstash是一个开源的数据收集引擎,可以用来从不同的数据源导入数据到Elasticsearch。它具有强大的数据处理能力和插件生态系统,可以方便地实现数据的解析、转换和丰富。
例子:
在Logstash的配置文件中定义输入、过滤器和输出插件:
input {jdbc {jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"jdbc_user => "myuser"jdbc_password => "mypassword"jdbc_driver_class => "com.mysql.cj.jdbc.Driver"jdbc_driver_library => "/path/to/mysql-connector-java.jar"schedule => "* * * * *"statement => "SELECT * FROM articles"}
}
filter {# 在这里可以进行数据解析、转换和丰富
}
output {elasticsearch {hosts => ["localhost:9200"]index => "articles"}
}
2. 使用Elasticsearch的Bulk API:
Elasticsearch的Bulk API允许你一次性执行多个索引和删除操作,这样可以提高数据导入的效率。你可以从MySQL数据库中查询数据,然后将数据转换为JSON格式,最后使用Bulk API将数据导入到Elasticsearch。
例子:
使用Python脚本查询MySQL数据库并将数据导入到Elasticsearch:
import pymysql
from elasticsearch import Elasticsearch
# 连接到MySQL数据库
mysql_connection = pymysql.connect(host='localhost', user='myuser', password='mypassword', db='mydb')
cursor = mysql_connection.cursor()
# 查询数据
cursor.execute("SELECT * FROM articles")
# 连接到Elasticsearch
es = Elasticsearch(hosts=["localhost:9200"])
# 使用Bulk API导入数据
actions = []
for row in cursor.fetchall():action = {"_index": "articles","_type": "_doc","_source": {"title": row[1],"content": row[2],"author": row[3]}}actions.append(action)
# 执行Bulk API
es.bulk(actions)
# 关闭连接
cursor.close()
mysql_connection.close()

3. 使用ELK栈(Elasticsearch、Logstash和Kibana):
ELK栈是一套完整的解决方案,可以将数据从MySQL数据库导入到Elasticsearch,并进行可视化和分析。Logstash负责数据导入和预处理,Elasticsearch负责存储和搜索数据,Kibana提供可视化界面。
例子:
配置Logstash和Kibana以导入MySQL数据:
# Logstash配置文件
input {jdbc {# ...}
}
filter {# ...
}
output {elasticsearch {# ...}
}
# Kibana配置文件
elasticsearch.url: "http://localhost:9200"
这些方法之间的主要区别在于使用场景和操作复杂性。Logstash提供了强大的数据处理能力和插件生态系统,但需要额外的配置和资源。Elasticsearch的Bulk API直接与Elasticsearch交互,效率较高,但需要手动处理数据的转换和格式化。ELK栈是一套完整的解决方案,可以方便地进行数据的导入、存储、搜索和可视化,但需要安装和配置多个组件。
每种方法都有其优势和特点。Logstash适用于复杂的数据处理和转换场景,可以灵活地处理不同格式的数据。Elasticsearch的Bulk API适用于高效的数据导入,特别是对于大量数据的导入。ELK栈提供了一个端到端的解决方案,可以方便地进行数据的导入、存储、搜索和可视化。
总的来说,选择哪种方法取决于具体的需求和场景。如果需要进行复杂的数据处理和转换,Logstash是一个不错的选择。如果需要高效地导入大量数据,Elasticsearch的Bulk API可能更合适。如果需要一个完整的解决方案,包括数据的导入、存储、搜索和可视化,ELK栈可能更适合。