第三天 Kubernetes进阶实践
本章介绍Kubernetes的进阶内容,包含Kubernetes集群调度、CNI插件、认证授权安全体系、分布式存储的对接、Helm的使用等,让学员可以更加深入的学习Kubernetes的核心内容。
-
ETCD数据的访问
-
kube-scheduler调度策略实践
- 预选与优选流程
- 生产中常用的调度配置实践
-
k8s集群网络模型
- CNI介绍及集群网络选型
- Flannel网络模型的实现
- vxlan Backend
- hostgw Backend
-
集群认证与授权
- APIServer安全控制模型
- Kubectl的认证授权
- RBAC
- kubelet的认证授权
- Service Account
-
使用Helm管理复杂应用的部署
- Helm工作原理详解
- Helm的模板开发
- 实战:使用Helm部署Harbor仓库
-
kubernetes对接分部式存储
-
pv、pvc介绍
-
k8s集群如何使用cephfs作为分布式存储后端
-
利用storageClass实现动态存储卷的管理
-
实战:使用分部署存储实现有状态应用的部署
-
-
本章知识梳理及回顾
ETCD常用操作
拷贝etcdctl命令行工具:
$ docker exec -ti etcd_container which etcdctl
$ docker cp etcd_container:/usr/local/bin/etcdctl /usr/bin/etcdctl
查看etcd集群的成员节点:
$ export ETCDCTL_API=3
$ etcdctl --endpoints=https://[127.0.0.1]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key member list -w table$ alias etcdctl='etcdctl --endpoints=https://[127.0.0.1]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key'$ etcdctl member list -w table
查看etcd集群节点状态:
$ etcdctl endpoint status -w table$ etcdctl endpoint health -w table
设置key值:
$ etcdctl put luffy 1
$ etcdctl get luffy
查看所有key值:
$ etcdctl get / --prefix --keys-only查看具体的key对应的数据:
$ etcdctl get /registry/pods/jenkins/sonar-postgres-7fc5d748b6-gtmsb添加定时任务做数据快照(重要!)
$ etcdctl snapshot save `hostname`-etcd_`date +%Y%m%d%H%M`.db
恢复快照:
-
停止etcd和apiserver
-
移走当前数据目录
$ mv /var/lib/etcd/ /tmp -
恢复快照
$ etcdctl snapshot restore `hostname`-etcd_`date +%Y%m%d%H%M`.db --data-dir=/var/lib/etcd/ -
集群恢复
https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/recovery.md
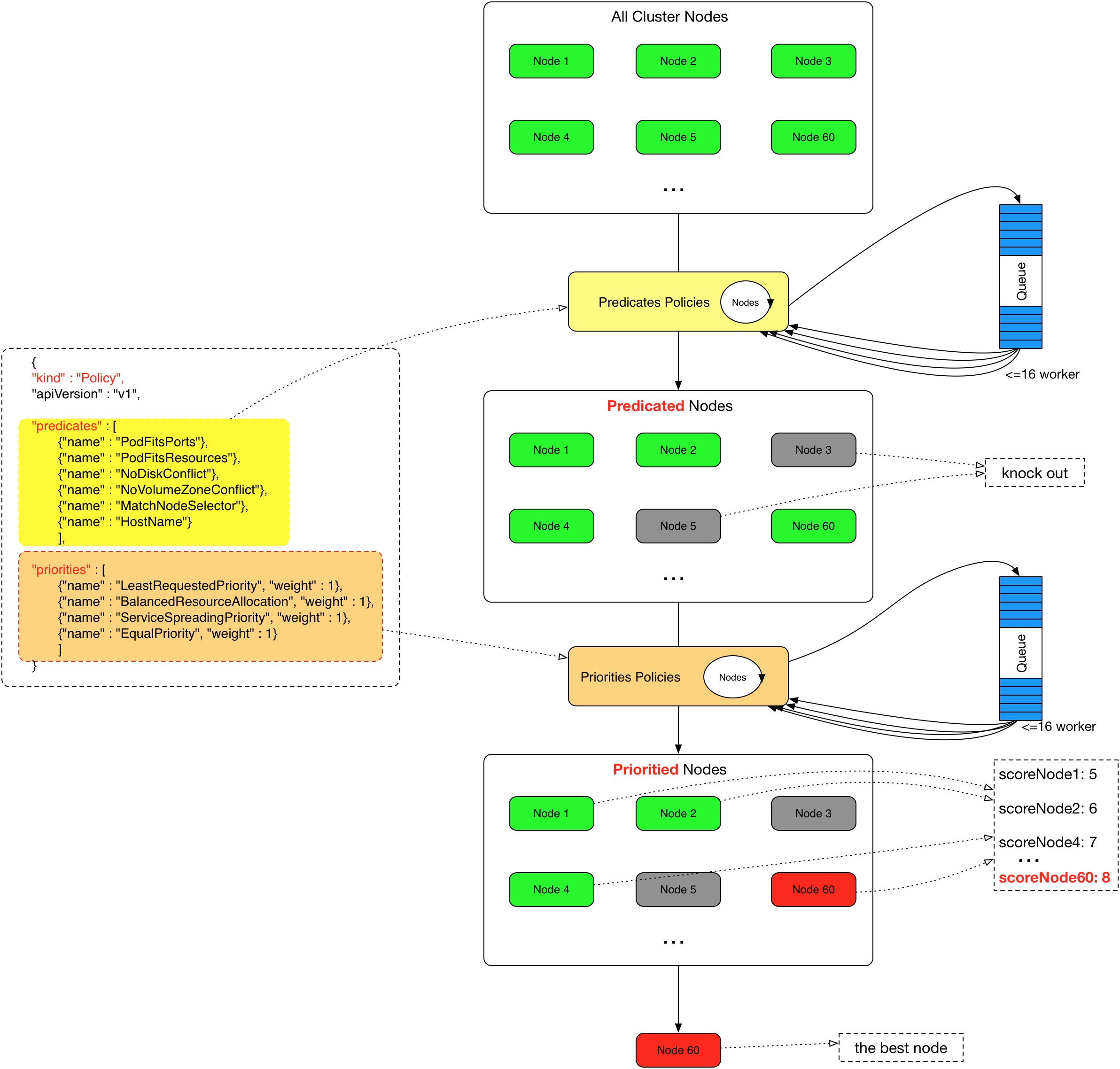
Kubernetes调度
为何要控制Pod应该如何调度
- 集群中有些机器的配置高(SSD,更好的内存等),我们希望核心的服务(比如说数据库)运行在上面
- 某两个服务的网络传输很频繁,我们希望它们最好在同一台机器上
- …
Kubernetes Scheduler 的作用是将待调度的 Pod 按照一定的调度算法和策略绑定到集群中一个合适的 Worker Node 上,并将绑定信息写入到 etcd 中,之后目标 Node 中 kubelet 服务通过 API Server 监听到 Scheduler 产生的 Pod 绑定事件获取 Pod 信息,然后下载镜像启动容器。

调度的过程
Scheduler 提供的调度流程分为预选 (Predicates) 和优选 (Priorities) 两个步骤:
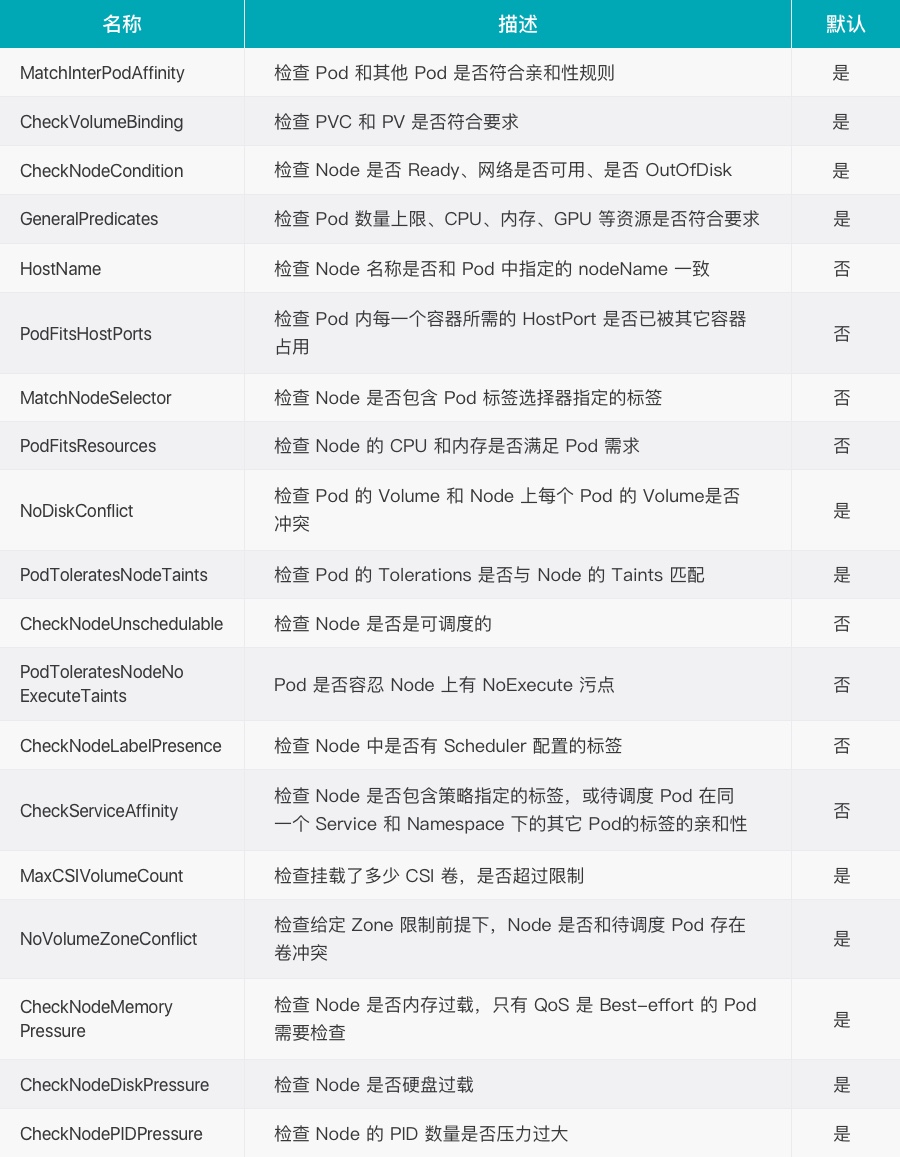
- 预选,K8S会遍历当前集群中的所有 Node,筛选出其中符合要求的 Node 作为候选
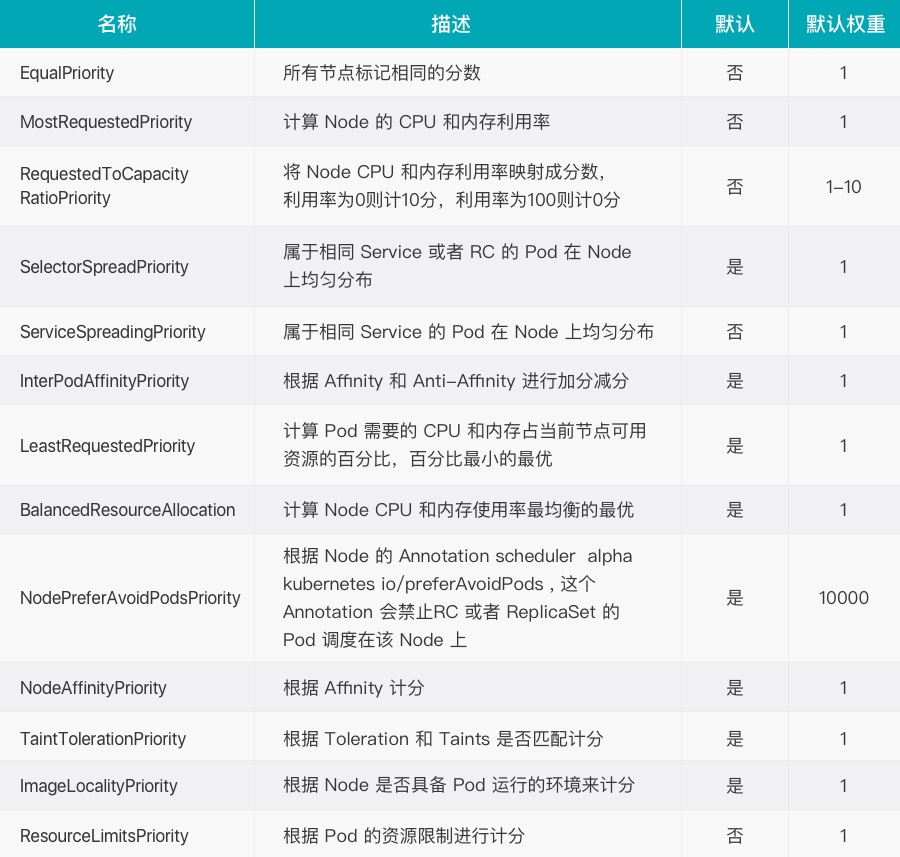
- 优选,K8S将对候选的 Node 进行打分
经过预选筛选和优选打分之后,K8S选择分数最高的 Node 来运行 Pod,如果最终有多个 Node 的分数最高,那么 Scheduler 将从当中随机选择一个 Node 来运行 Pod。
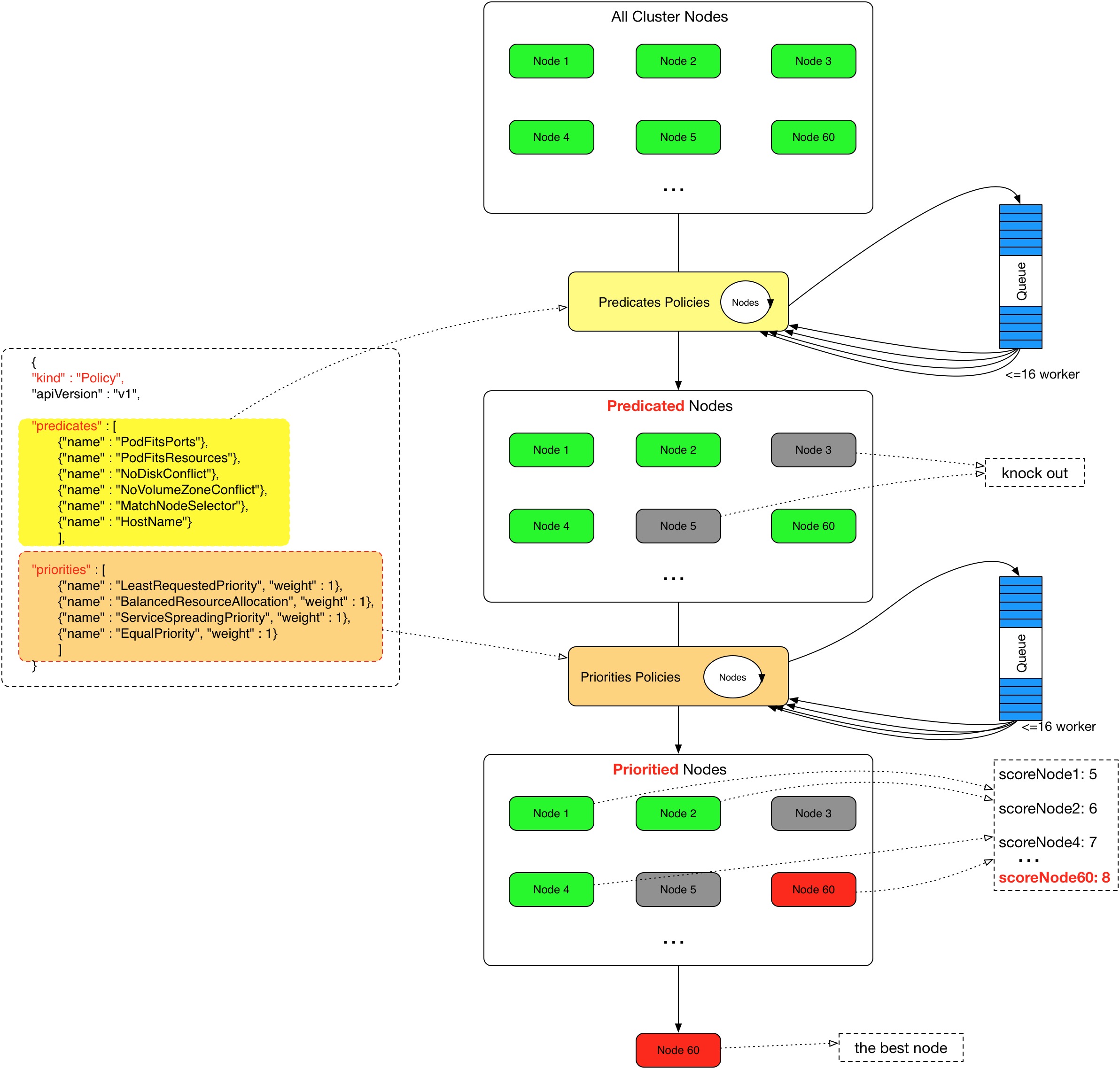
预选:
优选:
Cordon
$ kubectl cordon k8s-slave2
$ kubectl drain k8s-slave2
NodeSelector
label是kubernetes中一个非常重要的概念,用户可以非常灵活的利用 label 来管理集群中的资源,POD 的调度可以根据节点的 label 进行特定的部署。
查看节点的label:
$ kubectl get nodes --show-labels
为节点打label:
$ kubectl label node k8s-master disktype=ssd
当 node 被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在spec 字段中添加nodeSelector字段,里面是我们需要被调度的节点的 label。
...
spec:hostNetwork: true # 声明pod的网络模式为host模式,效果通docker run --net=hostvolumes: - name: mysql-datahostPath: path: /opt/mysql/datanodeSelector: # 使用节点选择器将Pod调度到指定label的节点component: mysqlcontainers:- name: mysqlimage: 192.168.136.10:5000/demo/mysql:5.7
...nodeAffinity
节点亲和性 , 比上面的nodeSelector更加灵活,它可以进行一些简单的逻辑组合,不只是简单的相等匹配 。分为两种,硬策略和软策略。
requiredDuringSchedulingIgnoredDuringExecution : 硬策略,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然我就不会调度Pod。
preferredDuringSchedulingIgnoredDuringExecution:软策略,如果你没有满足调度要求的节点的话,Pod就会忽略这条规则,继续完成调度过程,说白了就是满足条件最好了,没有满足就忽略掉的策略。
#要求 Pod 不能运行在128和132两个节点上,如果有节点满足disktype=ssd或者sas的话就优先调度到这类节点上
...
spec:containers:- name: demoimage: 192.168.136.10:5000/demo/myblog:v1ports:- containerPort: 8002affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: NotInvalues:- 172.21.51.698- 192.168.136.132preferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: disktypeoperator: Invalues:- ssd- sas
...
这里的匹配逻辑是 label 的值在某个列表中,现在Kubernetes提供的操作符有下面的几种:
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
如果nodeSelectorTerms下面有多个选项的话,满足任何一个条件就可以了;如果matchExpressions有多个选项的话,则必须同时满足这些条件才能正常调度 Pod
污点(Taints)与容忍(tolerations)
对于nodeAffinity无论是硬策略还是软策略方式,都是调度 Pod 到预期节点上,而Taints恰好与之相反,如果一个节点标记为 Taints ,除非 Pod 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度Pod。
Taints(污点)是Node的一个属性,设置了Taints(污点)后,因为有了污点,所以Kubernetes是不会将Pod调度到这个Node上的。于是Kubernetes就给Pod设置了个属性Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去。
场景一:私有云服务中,某业务使用GPU进行大规模并行计算。为保证性能,希望确保该业务对服务器的专属性,避免将普通业务调度到部署GPU的服务器。
场景二:用户希望把 Master 节点保留给 Kubernetes 系统组件使用,或者把一组具有特殊资源预留给某些 Pod,则污点就很有用了,Pod 不会再被调度到 taint 标记过的节点。taint 标记节点举例如下:
设置污点:
$ kubectl taint node [node_name] key=value:[effect] 其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ]NoSchedule:一定不能被调度。PreferNoSchedule:尽量不要调度。NoExecute:不仅不会调度,还会驱逐Node上已有的Pod。示例:kubectl taint node k8s-slave1 smoke=true:NoSchedule去除污点:
去除指定key及其effect:kubectl taint nodes [node_name] key:[effect]- #这里的key不用指定value去除指定key所有的effect: kubectl taint nodes node_name key-示例:kubectl taint node k8s-master smoke=true:NoSchedulekubectl taint node k8s-master smoke:NoExecute-kubectl taint node k8s-master smoke-污点演示:
## 给k8s-slave1打上污点,smoke=true:NoSchedule
$ kubectl taint node k8s-slave1 smoke=true:NoSchedule
$ kubectl taint node k8s-slave2 drunk=true:NoSchedule## 扩容myblog的Pod,观察新Pod的调度情况
$ kuebctl -n luffy scale deploy myblog --replicas=3
$ kubectl -n luffy get po -w ## pendingPod容忍污点示例:myblog/deployment/deploy-myblog-taint.yaml
...
spec:containers:- name: demoimage: 192.168.136.10:5000/demo/myblog:v1tolerations: #设置容忍性- key: "smoke" operator: "Equal" #如果操作符为Exists,那么value属性可省略,不指定operator,默认为Equalvalue: "true"effect: "NoSchedule"- key: "drunk" operator: "Exists" #如果操作符为Exists,那么value属性可省略,不指定operator,默认为Equal#意思是这个Pod要容忍的有污点的Node的key是smoke Equal true,效果是NoSchedule,#tolerations属性下各值必须使用引号,容忍的值都是设置Node的taints时给的值。
$ kubectl apply -f deploy-myblog-taint.yaml
spec:containers:- name: demoimage: 192.168.136.10:5000/demo/myblogtolerations:- operator: "Exists"
验证NoExecute效果
Kubernetes集群的网络实现
CNI介绍及集群网络选型,
CSI
容器网络接口(Container Network Interface),实现kubernetes集群的Pod网络通信及管理。包括:
- CNI Plugin负责给容器配置网络,它包括两个基本的接口:
配置网络: AddNetwork(net NetworkConfig, rt RuntimeConf) (types.Result, error)
清理网络: DelNetwork(net NetworkConfig, rt RuntimeConf) error - IPAM Plugin负责给容器分配IP地址,主要实现包括host-local和dhcp。
以上两种插件的支持,使得k8s的网络可以支持各式各样的管理模式,当前在业界也出现了大量的支持方案,其中比较流行的比如flannel、calico等。
kubernetes配置了cni网络插件后,其容器网络创建流程为:
- kubelet先创建pause容器生成对应的network namespace
- 调用网络driver,因为配置的是CNI,所以会调用CNI相关代码,识别CNI的配置目录为/etc/cni/net.d
- CNI driver根据配置调用具体的CNI插件,二进制调用,可执行文件目录为/opt/cni/bin,项目
- CNI插件给pause容器配置正确的网络,pod中其他的容器都是用pause的网络
可以在此查看社区中的CNI实现,https://github.com/containernetworking/cni
通用类型:flannel、calico等,部署使用简单
其他:根据具体的网络环境及网络需求选择,比如
- 公有云机器,可以选择厂商与网络插件的定制Backend,如AWS、阿里、腾讯针对flannel均有自己的插件,也有AWS ECS CNI
- 私有云厂商,比如Vmware NSX-T等
- 网络性能等,MacVlan
Flannel网络模型实现剖析
flannel实现overlay,underlay网络通常有多种实现:
- udp
- vxlan
- host-gw
- …
不特殊指定的话,默认会使用vxlan技术作为Backend,可以通过如下查看:
$ kubectl -n kube-system exec kube-flannel-ds-amd64-cb7hs cat /etc/kube-flannel/net-conf.json
{"Network": "10.244.0.0/16","Backend": {"Type": "vxlan"}
}vxlan介绍及点对点通信的实现
VXLAN 全称是虚拟可扩展的局域网( Virtual eXtensible Local Area Network),它是一种 overlay 技术,通过三层的网络来搭建虚拟的二层网络。
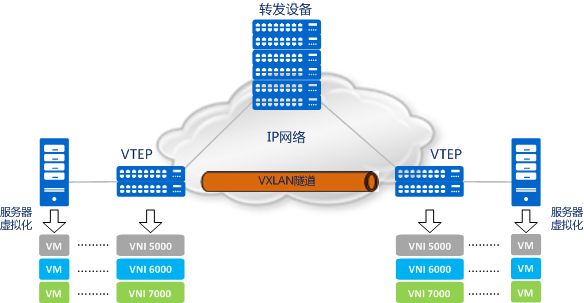
它创建在原来的 IP 网络(三层)上,只要是三层可达(能够通过 IP 互相通信)的网络就能部署 vxlan。在每个端点上都有一个 vtep 负责 vxlan 协议报文的封包和解包,也就是在虚拟报文上封装 vtep 通信的报文头部。物理网络上可以创建多个 vxlan 网络,这些 vxlan 网络可以认为是一个隧道,不同节点的虚拟机能够通过隧道直连。每个 vxlan 网络由唯一的 VNI 标识,不同的 vxlan 可以不相互影响。
- VTEP(VXLAN Tunnel Endpoints):vxlan 网络的边缘设备,用来进行 vxlan 报文的处理(封包和解包)。vtep 可以是网络设备(比如交换机),也可以是一台机器(比如虚拟化集群中的宿主机)
- VNI(VXLAN Network Identifier):VNI 是每个 vxlan 的标识,一共有 2^24 = 16,777,216,一般每个 VNI 对应一个租户,也就是说使用 vxlan 搭建的公有云可以理论上可以支撑千万级别的租户
演示:在k8s-slave1和k8s-slave2两台机器间,利用vxlan的点对点能力,实现虚拟二层网络的通信
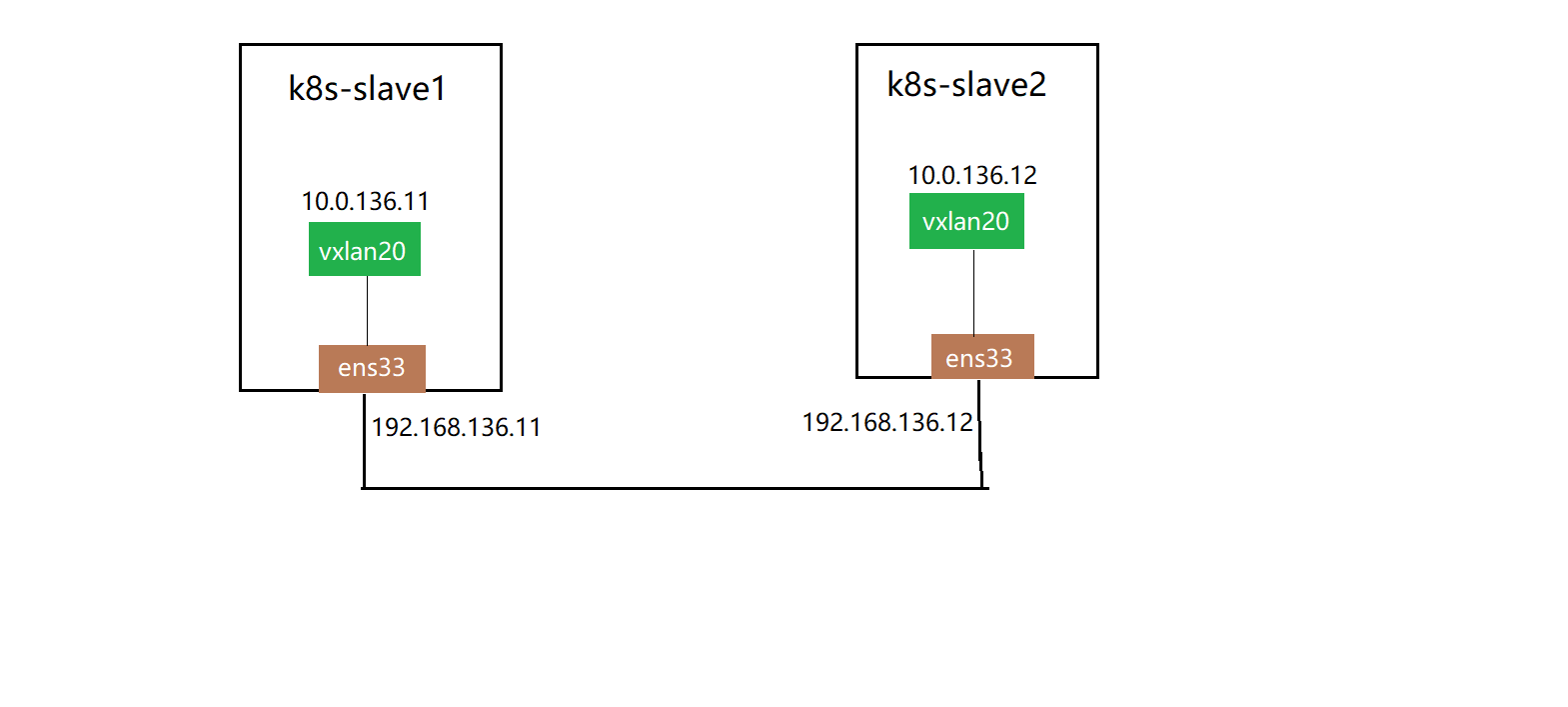
k8s-slave1节点:
# 创建vTEP设备,对端指向k8s-slave2节点,指定VNI及underlay网络使用的网卡
$ ip link add vxlan20 type vxlan id 20 remote 172.21.51.69 dstport 4789 dev eth0$ ip -d link show vxlan20# 启动设备
$ ip link set vxlan20 up # 设置ip地址ip addr add 10.0.136.11/24 dev vxlan20k8s-slave2节点:
# 创建VTEP设备,对端指向k8s-slave1节点,指定VNI及underlay网络使用的网卡
$ ip link add vxlan20 type vxlan id 20 remote 172.21.51.68 dstport 4789 dev eth0# 启动设备
$ ip link set vxlan20 up # 设置ip地址
$ ip addr add 10.0.136.12/24 dev vxlan20在k8s-slave1节点:
$ ping 10.0.136.12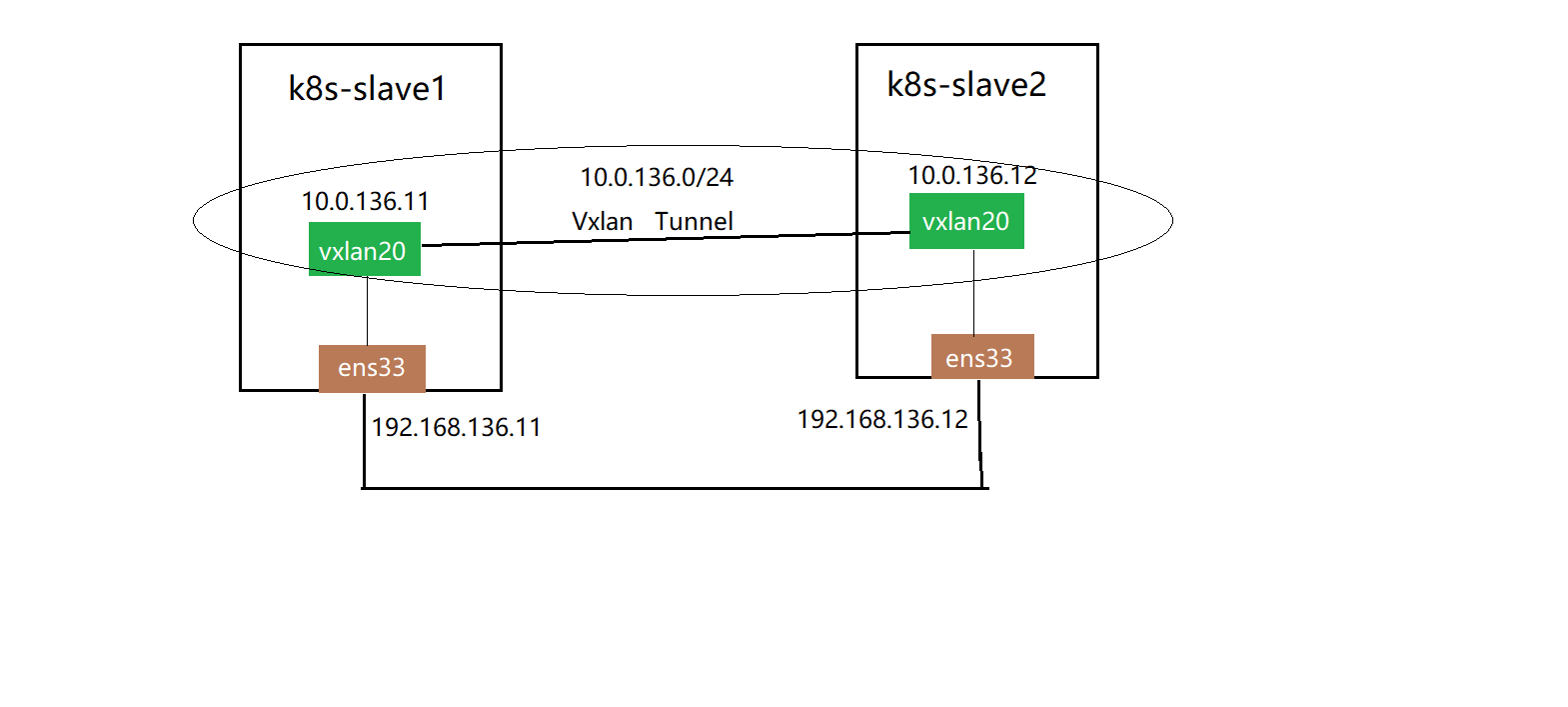
隧道是一个逻辑上的概念,在 vxlan 模型中并没有具体的物理实体想对应。隧道可以看做是一种虚拟通道,vxlan 通信双方(图中的虚拟机)认为自己是在直接通信,并不知道底层网络的存在。从整体来说,每个 vxlan 网络像是为通信的虚拟机搭建了一个单独的通信通道,也就是隧道。
实现的过程:
虚拟机的报文通过 vtep 添加上 vxlan 以及外部的报文层,然后发送出去,对方 vtep 收到之后拆除 vxlan 头部然后根据 VNI 把原始报文发送到目的虚拟机。
# 查看k8s-slave1主机路由
$ route -n
10.0.136.0 0.0.0.0 255.255.255.0 U 0 0 0 vxlan20# 到了vxlan的设备后,
$ ip -d link show vxlan20vxlan id 20 remote 172.21.51.69 dev eth0 srcport 0 0 dstport 4789 ...# 查看fdb地址表,主要由MAC地址、VLAN号、端口号和一些标志域等信息组成,vtep 对端地址为 172.21.51.69,换句话说,如果接收到的报文添加上 vxlan 头部之后都会发到 172.21.51.69
$ bridge fdb show|grep vxlan20
00:00:00:00:00:00 dev vxlan20 dst 172.21.51.69 via eth0 self permanent在k8s-slave2机器抓包,查看vxlan封装后的包:
# 在k8s-slave2机器执行
$ tcpdump -i eth0 host 172.21.51.68 -w vxlan.cap# 在k8s-slave1机器执行
$ ping 10.0.136.12使用wireshark分析ICMP类型的数据包
跨主机容器网络的通信
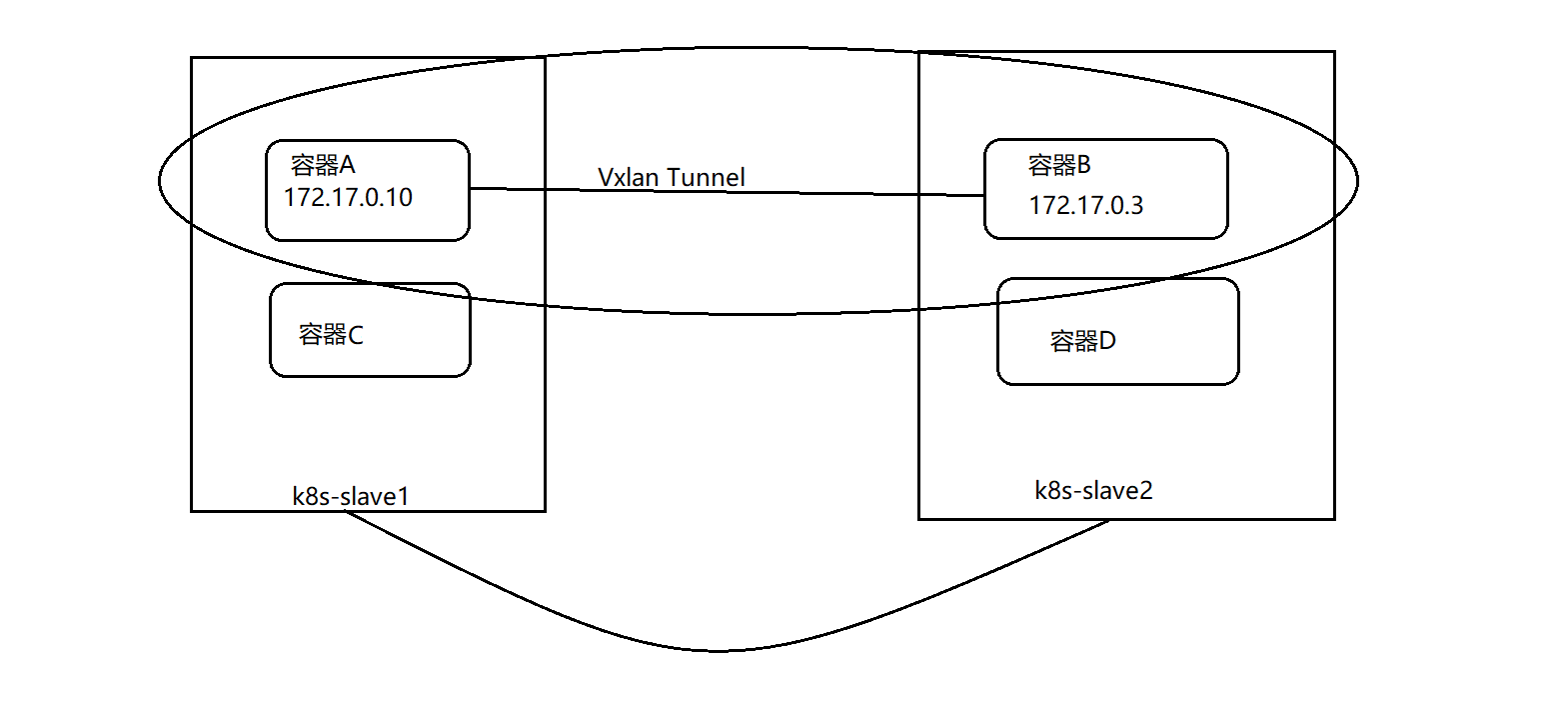
思考:容器网络模式下,vxlan设备该接在哪里?
基本的保证:目的容器的流量要通过vtep设备进行转发!
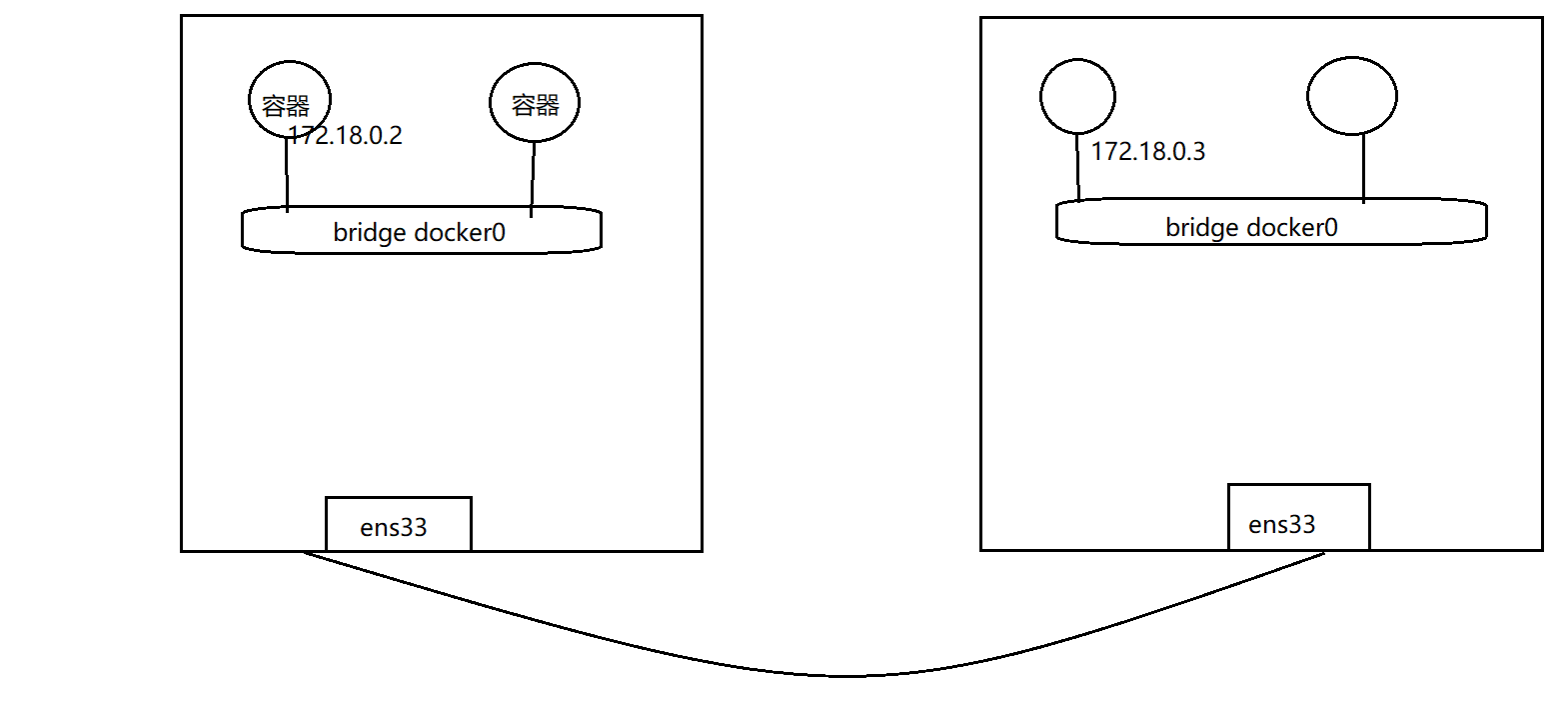
演示:利用vxlan实现跨主机容器网络通信
为了不影响已有的网络,因此创建一个新的网桥,创建容器接入到新的网桥来演示效果
在k8s-slave1节点:
$ docker network ls# 创建新网桥,指定cidr段
$ docker network create --subnet 172.18.0.0/16 network-luffy
$ docker network ls# 新建容器,接入到新网桥
$ docker run -d --name vxlan-test --net network-luffy --ip 172.18.0.2 nginx:alpine$ docker exec vxlan-test ifconfig$ brctl show network-luffy在k8s-slave2节点:
# 创建新网桥,指定cidr段
$ docker network create --subnet 172.18.0.0/16 network-luffy# 新建容器,接入到新网桥
$ docker run -d --name vxlan-test --net network-luffy --ip 172.18.0.3 nginx:alpine此时执行ping测试:
$ docker exec vxlan-test ping 172.18.0.3分析:数据到了网桥后,出不去。结合前面的示例,因此应该将流量由vtep设备转发,联想到网桥的特性,接入到桥中的端口,会由网桥负责转发数据,因此,相当于所有容器发出的数据都会经过到vxlan的端口,vxlan将流量转到对端的vtep端点,再次由网桥负责转到容器中。
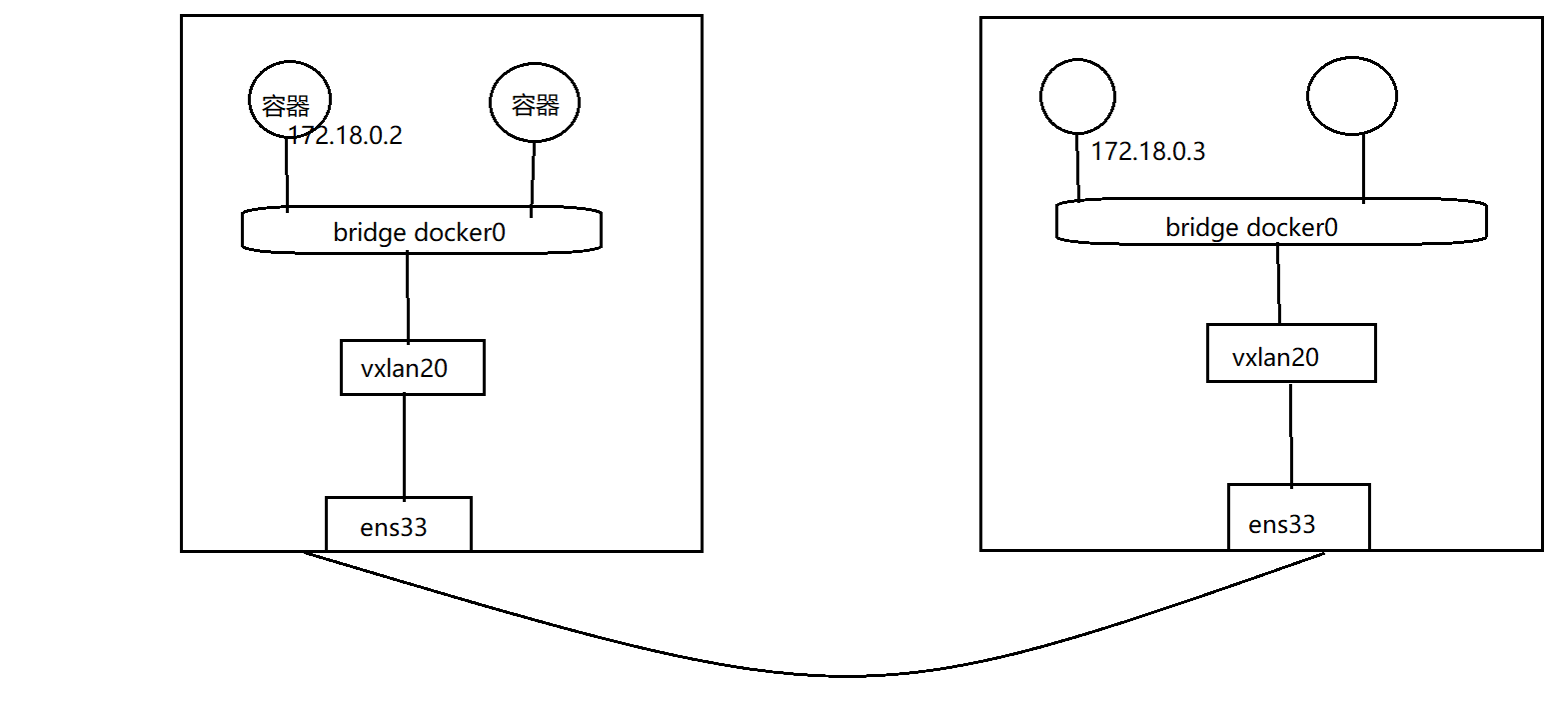
k8s-slave1节点:
# 删除旧的vtep
$ ip link del vxlan20# 新建vtep
$ ip link add vxlan_docker type vxlan id 100 remote 172.21.51.69 dstport 4789 dev eth0
$ ip link set vxlan_docker up
# 不用设置ip,因为目标是可以转发容器的数据即可# 接入到网桥中
$ brctl addif br-904603a72dcd vxlan_dockerk8s-slave2节点:
# 删除旧的vtep
$ ip link del vxlan20# 新建vtep
$ ip link add vxlan_docker type vxlan id 100 remote 172.21.51.68 dstport 4789 dev eth0
$ ip link set vxlan_docker up
# 不用设置ip,因为目标是可以转发容器的数据即可# 接入到网桥中
$ brctl addif br-c6660fe2dc53 vxlan_docker再次执行ping测试:
$ docker exec vxlan-test ping 172.18.0.3
Flannel的vxlan实现精讲
思考:k8s集群的网络环境和手动实现的跨主机的容器通信有哪些差别?
- CNI要求,集群中的每个Pod都必须分配唯一的Pod IP
- k8s集群内的通信不是vxlan点对点通信,因为集群内的所有节点之间都需要互联
- 没法创建点对点的vxlan模型

flannel如何为每个节点分配Pod地址段:
$ kubectl -n kube-system exec kube-flannel-ds-amd64-cb7hs cat /etc/kube-flannel/net-conf.json
{"Network": "10.244.0.0/16","Backend": {"Type": "vxlan"}
}#查看节点的pod ip
[root@k8s-master bin]# kd get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myblog-5d9ff54d4b-4rftt 1/1 Running 1 33h 10.244.2.19 k8s-slave2
myblog-5d9ff54d4b-n447p 1/1 Running 1 33h 10.244.1.32 k8s-slave1#查看k8s-slave1主机分配的地址段
$ cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.1.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true# kubelet启动容器的时候就可以按照本机的网段配置来为pod设置IP地址vtep的设备在哪:
$ ip -d link show flannel.1
# 没有remote ip,非点对点Pod的流量如何转到vtep设备中
$ brctl show cni0# 每个Pod都会使用Veth pair来实现流量转到cni0网桥$ route -n
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1vtep封包的时候,如何拿到目的vetp端的IP及MAC信息
# flanneld启动的时候会需要配置--iface=eth0,通过该配置可以将网卡的ip及Mac信息存储到ETCD中,
# 这样,flannel就知道所有的节点分配的IP段及vtep设备的IP和MAC信息,而且所有节点的flanneld都可以感知到节点的添加和删除操作,就可以动态的更新本机的转发配置演示跨主机Pod通信的流量详细过程:
$ kubectl -n luffy get po -o wide
myblog-5d9ff54d4b-4rftt 1/1 Running 1 25h 10.244.2.19 k8s-slave2
myblog-5d9ff54d4b-n447p 1/1 Running 1 25h 10.244.1.32 k8s-slave1$ kubectl -n luffy exec myblog-5d9ff54d4b-n447p -- ping 10.244.2.19 -c 2
PING 10.244.2.19 (10.244.2.19) 56(84) bytes of data.
64 bytes from 10.244.2.19: icmp_seq=1 ttl=62 time=0.480 ms
64 bytes from 10.244.2.19: icmp_seq=2 ttl=62 time=1.44 ms--- 10.244.2.19 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.480/0.961/1.443/0.482 ms# 查看路由
$ kubectl -n luffy exec myblog-5d9ff54d4b-n447p -- route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.1.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.1.1 255.255.0.0 UG 0 0 0 eth0
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0# 查看k8s-slave1 的veth pair 和网桥
$ brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.6a9a0b341d88 no veth048cc253veth76f8e4cevetha4c972e1
# 流量到了cni0后,查看slave1节点的route
$ route -n
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.136.2 0.0.0.0 UG 100 0 0 eth0
10.0.136.0 0.0.0.0 255.255.255.0 U 0 0 0 vxlan20
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.136.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0# 流量转发到了flannel.1网卡,查看该网卡,其实是vtep设备
$ ip -d link show flannel.1
4: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group defaultlink/ether 8a:2a:89:4d:b0:31 brd ff:ff:ff:ff:ff:ff promiscuity 0vxlan id 1 local 172.21.51.68 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535# 该转发到哪里,通过etcd查询数据,然后本地缓存,流量不用走多播发送
$ bridge fdb show dev flannel.1
a6:64:a0:a5:83:55 dst 192.168.136.10 self permanent
86:c2:ad:4e:47:20 dst 172.21.51.69 self permanent# 对端的vtep设备接收到请求后做解包,取出源payload内容,查看k8s-slave2的路由
$ route -n
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.136.2 0.0.0.0 UG 100 0 0 eth0
10.0.136.0 0.0.0.0 255.255.255.0 U 0 0 0 vxlan20
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
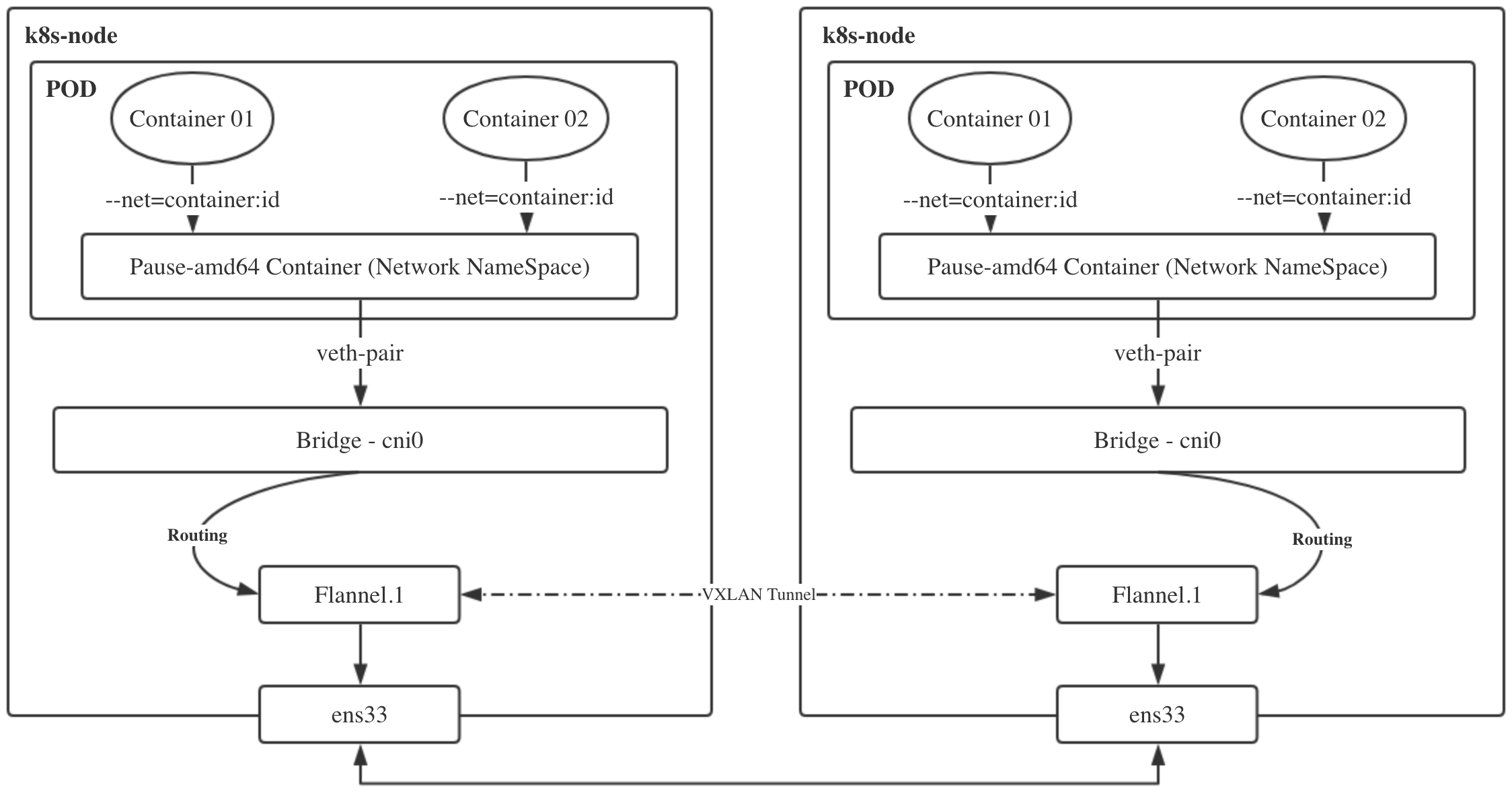
192.168.136.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0#根据路由规则转发到cni0网桥,然后由网桥转到具体的Pod中实际的请求图:
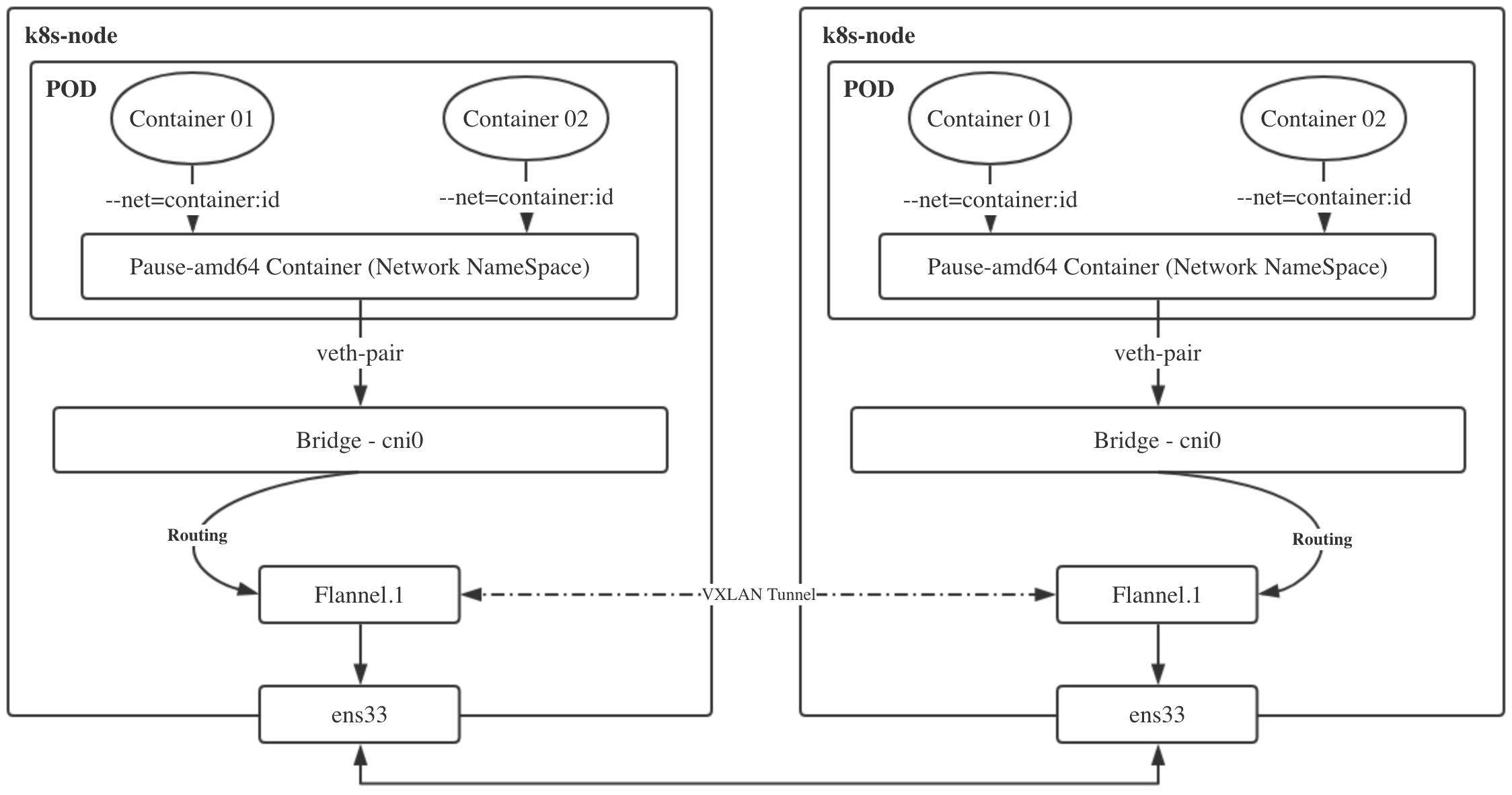
- k8s-slave1 节点中的 pod-a(10.244.2.19)当中的 IP 包通过 pod-a 内的路由表被发送到eth0,进一步通过veth pair转到宿主机中的网桥
cni0 - 到达
cni0当中的 IP 包通过匹配节点 k8s-slave1 的路由表发现通往 10.244.2.19 的 IP 包应该交给flannel.1接口 flannel.1作为一个 VTEP 设备,收到报文后将按照VTEP的配置进行封包,第一次会查询ETCD,知道10.244.2.19的vtep设备是k8s-slave2机器,IP地址是172.21.51.69,拿到MAC 地址进行 VXLAN 封包。- 通过节点 k8s-slave2 跟 k8s-slave1之间的网络连接,VXLAN 包到达 k8s-slave2 的 eth0 接口
- 通过端口 8472,VXLAN 包被转发给 VTEP 设备
flannel.1进行解包 - 解封装后的 IP 包匹配节点 k8s-slave2 当中的路由表(10.244.2.0),内核将 IP 包转发给
cni0 cni0将 IP 包转发给连接在cni0上的 pod-b
利用host-gw模式提升集群网络性能
vxlan模式适用于三层可达的网络环境,对集群的网络要求很宽松,但是同时由于会通过VTEP设备进行额外封包和解包,因此给性能带来了额外的开销。
网络插件的目的其实就是将本机的cni0网桥的流量送到目的主机的cni0网桥。实际上有很多集群是部署在同一二层网络环境下的,可以直接利用二层的主机当作流量转发的网关。这样的话,可以不用进行封包解包,直接通过路由表去转发流量。
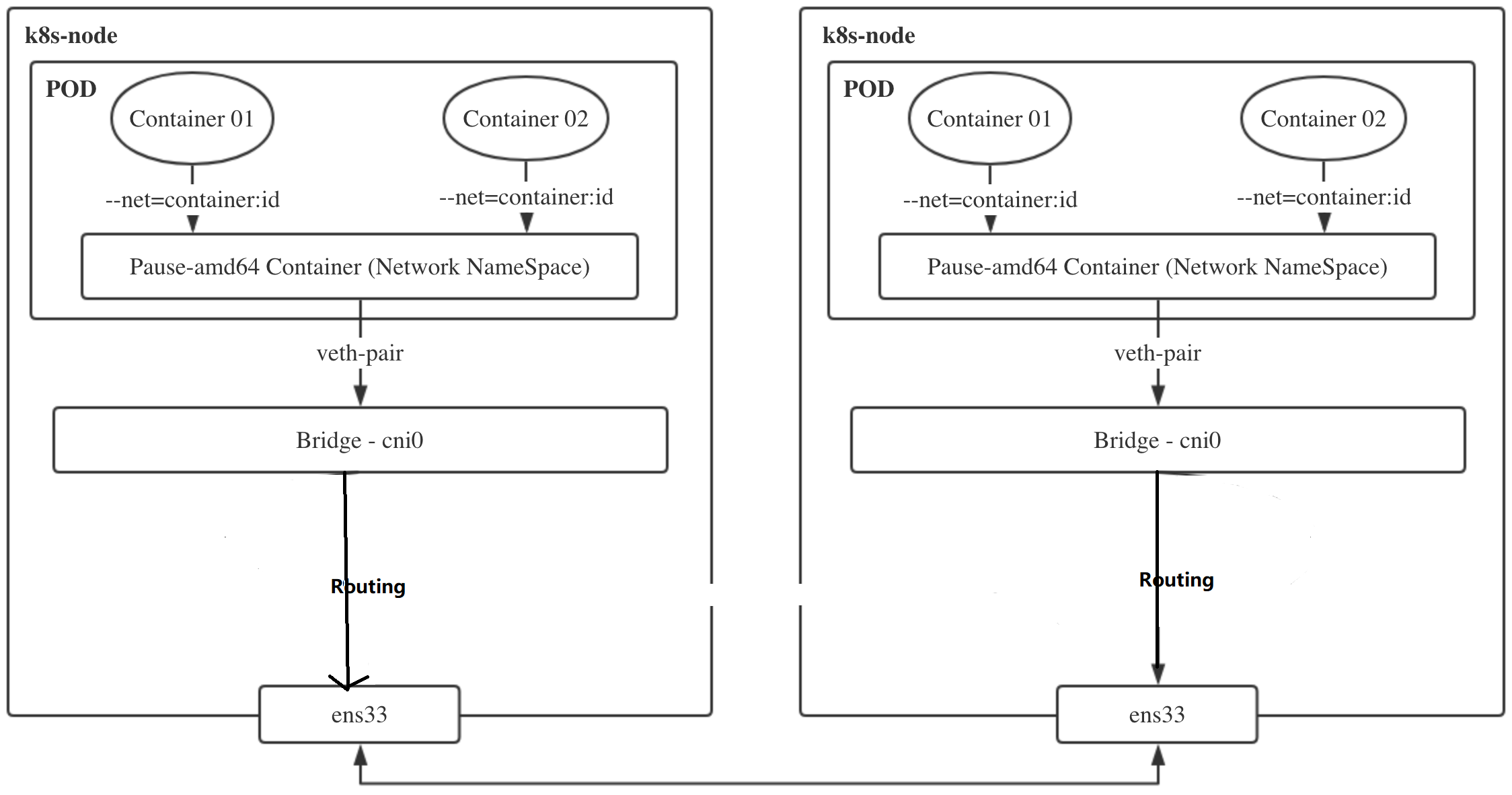
为什么三层可达的网络不直接利用网关转发流量?
内核当中的路由规则,网关必须在跟主机当中至少一个 IP 处于同一网段。
由于k8s集群内部各节点均需要实现Pod互通,因此,也就意味着host-gw模式需要整个集群节点都在同一二层网络内。修改flannel的网络后端:
$ kubectl edit cm kube-flannel-cfg -n kube-system
...
net-conf.json: |{"Network": "10.244.0.0/16","Backend": {"Type": "host-gw"}}
kind: ConfigMap
...重建Flannel的Pod
$ kubectl -n kube-system get po |grep flannel
kube-flannel-ds-amd64-5dgb8 1/1 Running 0 15m
kube-flannel-ds-amd64-c2gdc 1/1 Running 0 14m
kube-flannel-ds-amd64-t2jdd 1/1 Running 0 15m$ kubectl -n kube-system delete po kube-flannel-ds-amd64-5dgb8 kube-flannel-ds-amd64-c2gdc kube-flannel-ds-amd64-t2jdd# 等待Pod新启动后,查看日志,出现Backend type: host-gw字样
$ kubectl -n kube-system logs -f kube-flannel-ds-amd64-4hjdw
I0704 01:18:11.916374 1 kube.go:126] Waiting 10m0s for node controller to sync
I0704 01:18:11.916579 1 kube.go:309] Starting kube subnet manager
I0704 01:18:12.917339 1 kube.go:133] Node controller sync successful
I0704 01:18:12.917848 1 main.go:247] Installing signal handlers
I0704 01:18:12.918569 1 main.go:386] Found network config - Backend type: host-gw
I0704 01:18:13.017841 1 main.go:317] Wrote subnet file to /run/flannel/subnet.env查看节点路由表:
$ route -n
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.136.2 0.0.0.0 UG 100 0 0 eth0
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 172.21.51.68 255.255.255.0 UG 0 0 0 eth0
10.244.2.0 172.21.51.69 255.255.255.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.136.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0- k8s-slave1 节点中的 pod-a(10.244.2.19)当中的 IP 包通过 pod-a 内的路由表被发送到eth0,进一步通过veth pair转到宿主机中的网桥
cni0 - 到达
cni0当中的 IP 包通过匹配节点 k8s-slave1 的路由表发现通往 10.244.2.19 的 IP 包应该使用172.21.51.69这个网关进行转发 - 包到达k8s-slave2节点(172.21.51.69)节点的eth0网卡,根据该节点的路由规则,转发给cni0网卡
cni0将 IP 包转发给连接在cni0上的 pod-b
Kubernetes认证与授权
APIServer安全控制
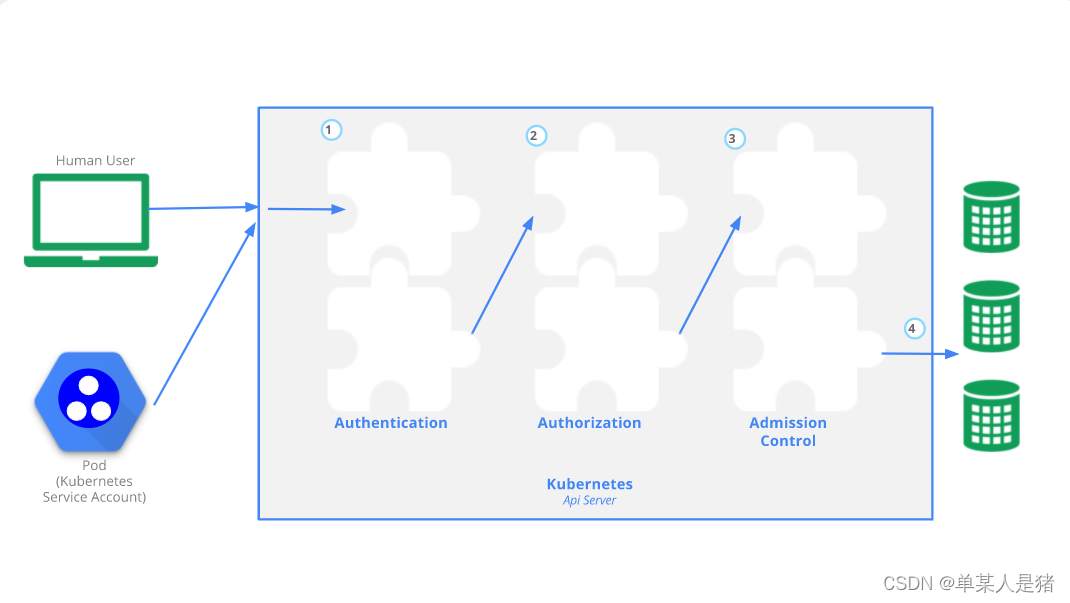
-
Authentication:身份认证
-
这个环节它面对的输入是整个
http request,负责对来自client的请求进行身份校验,支持的方法包括:-
basic auth -
client证书验证(https双向验证)
-
jwt token(用于serviceaccount)
-
-
APIServer启动时,可以指定一种Authentication方法,也可以指定多种方法。如果指定了多种方法,那么APIServer将会逐个使用这些方法对客户端请求进行验证, 只要请求数据通过其中一种方法的验证,APIServer就会认为Authentication成功;
-
使用kubeadm引导启动的k8s集群,apiserver的初始配置中,默认支持
client证书验证和serviceaccount两种身份验证方式。 证书认证通过设置--client-ca-file根证书以及--tls-cert-file和--tls-private-key-file来开启。 -
在这个环节,apiserver会通过client证书或
http header中的字段(比如serviceaccount的jwt token)来识别出请求的用户身份,包括”user”、”group”等,这些信息将在后面的authorization环节用到。
-
-
Authorization:鉴权,你可以访问哪些资源
-
这个环节面对的输入是
http request context中的各种属性,包括:user、group、request path(比如:/api/v1、/healthz、/version等)、request verb(比如:get、list、create等)。 -
APIServer会将这些属性值与事先配置好的访问策略(
access policy)相比较。APIServer支持多种authorization mode,包括Node、RBAC、Webhook等。 -
APIServer启动时,可以指定一种
authorization mode,也可以指定多种authorization mode,如果是后者,只要Request通过了其中一种mode的授权, 那么该环节的最终结果就是授权成功。在较新版本kubeadm引导启动的k8s集群的apiserver初始配置中,authorization-mode的默认配置是”Node,RBAC”。
-
-
Admission Control:准入控制,一个控制链(层层关卡),用于拦截请求的一种方式。偏集群安全控制、管理方面。
-
为什么需要?
认证与授权获取 http 请求 header 以及证书,无法通过body内容做校验。
Admission 运行在 API Server 的增删改查 handler 中,可以自然地操作 API resource
-
举个栗子
-
以NamespaceLifecycle为例, 该插件确保处于Termination状态的Namespace不再接收新的对象创建请求,并拒绝请求不存在的Namespace。该插件还可以防止删除系统保留的Namespace:default,kube-system,kube-public。
-
LimitRanger,若集群的命名空间设置了LimitRange对象,若Pod声明时未设置资源值,则按照LimitRange的定义来未Pod添加默认值
apiVersion: v1 kind: LimitRange metadata:name: mem-limit-rangenamespace: luffy spec:limits:- default:memory: 512MidefaultRequest:memory: 256Mitype: Container --- apiVersion: v1 kind: Pod metadata:name: default-mem-demo-2 spec:containers:- name: default-mem-demo-2-ctrimage: nginx:alpine -
NodeRestriction, 此插件限制kubelet修改Node和Pod对象,这样的kubelets只允许修改绑定到Node的Pod API对象,以后版本可能会增加额外的限制 。开启Node授权策略后,默认会打开该项
-
-
怎么用?
APIServer启动时通过
--enable-admission-plugins --disable-admission-plugins指定需要打开或者关闭的 Admission Controller -
场景
- 自动注入sidecar容器或者initContainer容器
- webhook admission,实现业务自定义的控制需求
-
kubectl的认证授权
kubectl的日志调试级别:
| 信息 | 描述 |
|---|---|
| v=0 | 通常,这对操作者来说总是可见的。 |
| v=1 | 当您不想要很详细的输出时,这个是一个合理的默认日志级别。 |
| v=2 | 有关服务和重要日志消息的有用稳定状态信息,这些信息可能与系统中的重大更改相关。这是大多数系统推荐的默认日志级别。 |
| v=3 | 关于更改的扩展信息。 |
| v=4 | 调试级别信息。 |
| v=6 | 显示请求资源。 |
| v=7 | 显示 HTTP 请求头。 |
| v=8 | 显示 HTTP 请求内容。 |
| v=9 | 显示 HTTP 请求内容,并且不截断内容。 |
$ kubectl get nodes -v=7
I0329 20:20:08.633065 3979 loader.go:359] Config loaded from file /root/.kube/config
I0329 20:20:08.633797 3979 round_trippers.go:416] GET https://192.168.136.10:6443/api/v1/nodes?limit=500kubeadm init启动完master节点后,会默认输出类似下面的提示内容:
... ...
Your Kubernetes master has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config
... ...这些信息是在告知我们如何配置kubeconfig文件。按照上述命令配置后,master节点上的kubectl就可以直接使用$HOME/.kube/config的信息访问k8s cluster了。 并且,通过这种配置方式,kubectl也拥有了整个集群的管理员(root)权限。
很多K8s初学者在这里都会有疑问:
- 当
kubectl使用这种kubeconfig方式访问集群时,Kubernetes的kube-apiserver是如何对来自kubectl的访问进行身份验证(authentication)和授权(authorization)的呢? - 为什么来自
kubectl的请求拥有最高的管理员权限呢?
查看/root/.kube/config文件:
前面提到过apiserver的authentication支持通过tls client certificate、basic auth、token等方式对客户端发起的请求进行身份校验, 从kubeconfig信息来看,kubectl显然在请求中使用了tls client certificate的方式,即客户端的证书。
证书base64解码:
$ echo xxxxxxxxxxxxxx |base64 -d > kubectl.crt说明在认证阶段,apiserver会首先使用--client-ca-file配置的CA证书去验证kubectl提供的证书的有效性,基本的方式 :
$ openssl verify -CAfile /etc/kubernetes/pki/ca.crt kubectl.crt
kubectl.crt: OK除了认证身份,还会取出必要的信息供授权阶段使用,文本形式查看证书内容:
$ openssl x509 -in kubectl.crt -text
Certificate:Data:Version: 3 (0x2)Serial Number: 4736260165981664452 (0x41ba9386f52b74c4)Signature Algorithm: sha256WithRSAEncryptionIssuer: CN=kubernetesValidityNot Before: Feb 10 07:33:39 2020 GMTNot After : Feb 9 07:33:40 2021 GMTSubject: O=system:masters, CN=kubernetes-admin...认证通过后,提取出签发证书时指定的CN(Common Name),kubernetes-admin,作为请求的用户名 (User Name), 从证书中提取O(Organization)字段作为请求用户所属的组 (Group),group = system:masters,然后传递给后面的授权模块。
kubeadm在init初始引导集群启动过程中,创建了许多默认的RBAC规则, 在k8s有关RBAC的官方文档中,我们看到下面一些default clusterrole列表:

其中第一个cluster-admin这个cluster role binding绑定了system:masters group,这和authentication环节传递过来的身份信息不谋而合。 沿着system:masters group对应的cluster-admin clusterrolebinding“追查”下去,真相就会浮出水面。
我们查看一下这一binding:
$ kubectl describe clusterrolebinding cluster-admin
Name: cluster-admin
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
Role:Kind: ClusterRoleName: cluster-admin
Subjects:Kind Name Namespace---- ---- ---------Group system:masters我们看到在kube-system名字空间中,一个名为cluster-admin的clusterrolebinding将cluster-admin cluster role与system:masters Group绑定到了一起, 赋予了所有归属于system:masters Group中用户cluster-admin角色所拥有的权限。
我们再来查看一下cluster-admin这个role的具体权限信息:
$ kubectl describe clusterrole cluster-admin
Name: cluster-admin
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
PolicyRule:Resources Non-Resource URLs Resource Names Verbs--------- ----------------- -------------- -----*.* [] [] [*][*] [] [*]非资源类,如查看集群健康状态。
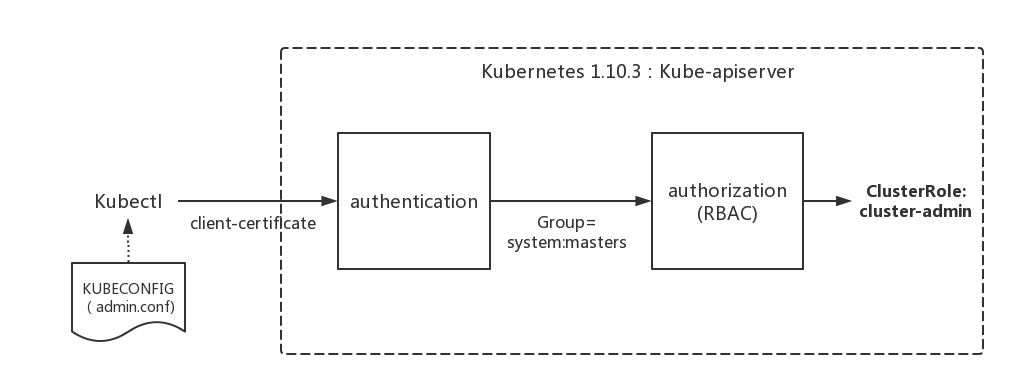
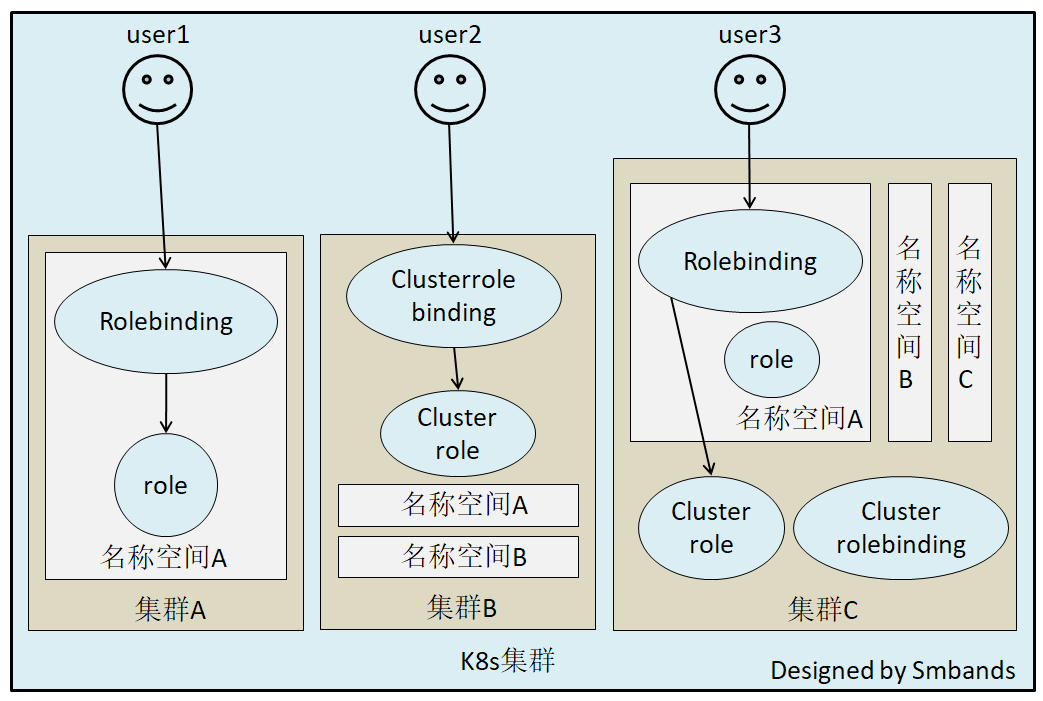
RBAC
Role-Based Access Control,基于角色的访问控制, apiserver启动参数添加–authorization-mode=RBAC 来启用RBAC认证模式,kubeadm安装的集群默认已开启。官方介绍
查看开启:
# master节点查看apiserver进程
$ ps aux |grep apiserverRBAC模式引入了4个资源类型:
-
Role,角色
一个Role只能授权访问单个namespace
## 示例定义一个名为pod-reader的角色,该角色具有读取default这个命名空间下的pods的权限 kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata:namespace: defaultname: pod-reader rules: - apiGroups: [""] # "" indicates the core API groupresources: ["pods"]verbs: ["get", "watch", "list"]## apiGroups: "","apps", "autoscaling", "batch", kubectl api-versions ## resources: "services", "pods","deployments"... kubectl api-resources ## verbs: "get", "list", "watch", "create", "update", "patch", "delete", "exec"## https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.18/ -
ClusterRole
一个ClusterRole能够授予和Role一样的权限,但是它是集群范围内的。
## 定义一个集群角色,名为secret-reader,该角色可以读取所有的namespace中的secret资源 kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata:# "namespace" omitted since ClusterRoles are not namespacedname: secret-reader rules: - apiGroups: [""]resources: ["secrets"]verbs: ["get", "watch", "list"]# User,Group,ServiceAccount -
Rolebinding
将role中定义的权限分配给用户和用户组。RoleBinding包含主题(users,groups,或service accounts)和授予角色的引用。对于namespace内的授权使用RoleBinding,集群范围内使用ClusterRoleBinding。
## 定义一个角色绑定,将pod-reader这个role的权限授予给jane这个User,使得jane可以在读取default这个命名空间下的所有的pod数据 kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata:name: read-podsnamespace: default subjects: - kind: User #这里可以是User,Group,ServiceAccountname: jane apiGroup: rbac.authorization.k8s.io roleRef:kind: Role #这里可以是Role或者ClusterRole,若是ClusterRole,则权限也仅限于rolebinding的内部name: pod-reader # match the name of the Role or ClusterRole you wish to bind toapiGroup: rbac.authorization.k8s.io注意:rolebinding既可以绑定role,也可以绑定clusterrole,当绑定clusterrole的时候,subject的权限也会被限定于rolebinding定义的namespace内部,若想跨namespace,需要使用clusterrolebinding
## 定义一个角色绑定,将dave这个用户和secret-reader这个集群角色绑定,虽然secret-reader是集群角色,但是因为是使用rolebinding绑定的,因此dave的权限也会被限制在development这个命名空间内 apiVersion: rbac.authorization.k8s.io/v1 # This role binding allows "dave" to read secrets in the "development" namespace. # You need to already have a ClusterRole named "secret-reader". kind: RoleBinding metadata:name: read-secrets## The namespace of the RoleBinding determines where the permissions are granted.# This only grants permissions within the "development" namespace.namespace: development subjects: - kind: Username: dave # Name is case sensitiveapiGroup: rbac.authorization.k8s.io - kind: ServiceAccountname: dave # Name is case sensitivenamespace: luffy roleRef:kind: ClusterRolename: secret-readerapiGroup: rbac.authorization.k8s.io考虑一个场景: 如果集群中有多个namespace分配给不同的管理员,每个namespace的权限是一样的,就可以只定义一个clusterrole,然后通过rolebinding将不同的namespace绑定到管理员身上,否则就需要每个namespace定义一个Role,然后做一次rolebinding。
-
ClusterRolebingding
允许跨namespace进行授权
apiVersion: rbac.authorization.k8s.io/v1 # This cluster role binding allows anyone in the "manager" group to read secrets in any namespace. kind: ClusterRoleBinding metadata:name: read-secrets-global subjects: - kind: Groupname: manager # Name is case sensitiveapiGroup: rbac.authorization.k8s.io roleRef:kind: ClusterRolename: secret-readerapiGroup: rbac.authorization.k8s.io

kubelet的认证授权
查看kubelet进程
$ systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node AgentLoaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)Drop-In: /usr/lib/systemd/system/kubelet.service.d└─10-kubeadm.confActive: active (running) since Sun 2020-07-05 19:33:36 EDT; 1 day 12h agoDocs: https://kubernetes.io/docs/Main PID: 10622 (kubelet)Tasks: 24Memory: 60.5MCGroup: /system.slice/kubelet.service└─851 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf查看/etc/kubernetes/kubelet.conf,解析证书:
$ echo xxxxx |base64 -d >kubelet.crt
$ openssl x509 -in kubelet.crt -text
Certificate:Data:Version: 3 (0x2)Serial Number: 9059794385454520113 (0x7dbadafe23185731)Signature Algorithm: sha256WithRSAEncryptionIssuer: CN=kubernetesValidityNot Before: Feb 10 07:33:39 2020 GMTNot After : Feb 9 07:33:40 2021 GMTSubject: O=system:nodes, CN=system:node:master-1得到我们期望的内容:
Subject: O=system:nodes, CN=system:node:k8s-master我们知道,k8s会把O作为Group来进行请求,因此如果有权限绑定给这个组,肯定在clusterrolebinding的定义中可以找得到。因此尝试去找一下绑定了system:nodes组的clusterrolebinding
$ kubectl get clusterrolebinding|awk 'NR>1{print $1}'|xargs kubectl get clusterrolebinding -oyaml|grep -n10 system:nodes
98- roleRef:
99- apiGroup: rbac.authorization.k8s.io
100- kind: ClusterRole
101- name: system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
102- subjects:
103- - apiGroup: rbac.authorization.k8s.io
104- kind: Group
105: name: system:nodes
106-- apiVersion: rbac.authorization.k8s.io/v1
107- kind: ClusterRoleBinding
108- metadata:
109- creationTimestamp: "2020-02-10T07:34:02Z"
110- name: kubeadm:node-proxier
111- resourceVersion: "213"
112- selfLink: /apis/rbac.authorization.k8s.io/v1/clusterrolebindings/kubeadm%3Anode-proxier$ kubectl describe clusterrole system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
Name: system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
PolicyRule:Resources Non-Resource URLs Resource Names Verbs--------- ----------------- -------------- -----certificatesigningrequests.certificates.k8s.io/selfnodeclient [] [] [create]结局有点意外,除了system:certificates.k8s.io:certificatesigningrequests:selfnodeclient外,没有找到system相关的rolebindings,显然和我们的理解不一样。 尝试去找资料,发现了这么一段 :
| Default ClusterRole | Default ClusterRoleBinding | Description |
|---|---|---|
| system:kube-scheduler | system:kube-scheduler user | Allows access to the resources required by the schedulercomponent. |
| system:volume-scheduler | system:kube-scheduler user | Allows access to the volume resources required by the kube-scheduler component. |
| system:kube-controller-manager | system:kube-controller-manager user | Allows access to the resources required by the controller manager component. The permissions required by individual controllers are detailed in the controller roles. |
| system:node | None | Allows access to resources required by the kubelet, including read access to all secrets, and write access to all pod status objects. You should use the Node authorizer and NodeRestriction admission plugin instead of the system:node role, and allow granting API access to kubelets based on the Pods scheduled to run on them. The system:node role only exists for compatibility with Kubernetes clusters upgraded from versions prior to v1.8. |
| system:node-proxier | system:kube-proxy user | Allows access to the resources required by the kube-proxycomponent. |
大致意思是说:之前会定义system:node这个角色,目的是为了kubelet可以访问到必要的资源,包括所有secret的读权限及更新pod状态的写权限。如果1.8版本后,是建议使用 Node authorizer and NodeRestriction admission plugin 来代替这个角色的。
我们目前使用1.16,查看一下授权策略:
$ ps axu|grep apiserver
kube-apiserver --authorization-mode=Node,RBAC --enable-admission-plugins=NodeRestriction查看一下官网对Node authorizer的介绍:
Node authorization is a special-purpose authorization mode that specifically authorizes API requests made by kubelets.
In future releases, the node authorizer may add or remove permissions to ensure kubelets have the minimal set of permissions required to operate correctly.
In order to be authorized by the Node authorizer, kubelets must use a credential that identifies them as being in the system:nodes group, with a username of system:node:<nodeName>
Service Account及K8S Api调用
前面说,认证可以通过证书,也可以通过使用ServiceAccount(服务账户)的方式来做认证。大多数时候,我们在基于k8s做二次开发时都是选择通过ServiceAccount + RBAC 的方式。我们之前访问dashboard的时候,是如何做的?
## 新建一个名为admin的serviceaccount,并且把名为cluster-admin的这个集群角色的权限授予新建的
#serviceaccount
apiVersion: v1
kind: ServiceAccount
metadata:name: adminnamespace: kubernetes-dashboard
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:name: adminannotations:rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:kind: ClusterRolename: cluster-adminapiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccountname: adminnamespace: kubernetes-dashboard我们查看一下:
$ kubectl -n kubernetes-dashboard get sa admin -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:creationTimestamp: "2020-04-01T11:59:21Z"name: adminnamespace: kubernetes-dashboardresourceVersion: "1988878"selfLink: /api/v1/namespaces/kubernetes-dashboard/serviceaccounts/adminuid: 639ecc3e-74d9-11ea-a59b-000c29dfd73f
secrets:
- name: admin-token-lfsrf注意到serviceaccount上默认绑定了一个名为admin-token-lfsrf的secret,我们查看一下secret
$ kubectl -n kubernetes-dashboard describe secret admin-token-lfsrf
Name: admin-token-lfsrf
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: adminkubernetes.io/service-account.uid: 639ecc3e-74d9-11ea-a59b-000c29dfd73fType: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 4 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZW1vIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImFkbWluLXRva2VuLWxmc3JmIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiNjM5ZWNjM2UtNzRkOS0xMWVhLWE1OWItMDAwYzI5ZGZkNzNmIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50OmRlbW86YWRtaW4ifQ.ffGCU4L5LxTsMx3NcNixpjT6nLBi-pmstb4I-W61nLOzNaMmYSEIwAaugKMzNR-2VwM14WbuG04dOeO67niJeP6n8-ALkl-vineoYCsUjrzJ09qpM3TNUPatHFqyjcqJ87h4VKZEqk2qCCmLxB6AGbEHpVFkoge40vHs56cIymFGZLe53JZkhu3pwYuS4jpXytV30Ad-HwmQDUu_Xqcifni6tDYPCfKz2CZlcOfwqHeGIHJjDGVBKqhEeo8PhStoofBU6Y4OjObP7HGuTY-Foo4QindNnpp0QU6vSb7kiOiQ4twpayybH8PTf73dtdFt46UF6mGjskWgevgolvmO8A演示role的权限:
$ cat test-sa.yaml
serviceaccount
apiVersion: v1
kind: ServiceAccount
metadata:name: testnamespace: kubernetes-dashboard---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:name: testannotations:rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:kind: ClusterRolename: cluster-adminapiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccountname: testnamespace: kubernetes-dashboard
curl演示
$ curl -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6InhXcmtaSG5ZODF1TVJ6dUcycnRLT2c4U3ZncVdoVjlLaVRxNG1wZ0pqVmcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi10b2tlbi1xNXBueiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImViZDg2ODZjLWZkYzAtNDRlZC04NmZlLTY5ZmE0ZTE1YjBmMCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbiJ9.iEIVMWg2mHPD88GQ2i4uc_60K4o17e39tN0VI_Q_s3TrRS8hmpi0pkEaN88igEKZm95Qf1qcN9J5W5eqOmcK2SN83Dd9dyGAGxuNAdEwi0i73weFHHsjDqokl9_4RGbHT5lRY46BbIGADIphcTeVbCggI6T_V9zBbtl8dcmsd-lD_6c6uC2INtPyIfz1FplynkjEVLapp_45aXZ9IMy76ljNSA8Uc061Uys6PD3IXsUD5JJfdm7lAt0F7rn9SdX1q10F2lIHYCMcCcfEpLr4Vkymxb4IU4RCR8BsMOPIO_yfRVeYZkG4gU2C47KwxpLsJRrTUcUXJktSEPdeYYXf9w" https://192.168.136.10:6443/api/v1/namespaces/luffy/pods?limit=500
通过HPA实现业务应用的动态扩缩容
HPA控制器介绍
当系统资源过高的时候,我们可以使用如下命令来实现 Pod 的扩缩容功能
$ kubectl -n luffy scale deployment myblog --replicas=2
但是这个过程是手动操作的。在实际项目中,我们需要做到是的是一个自动化感知并自动扩容的操作。Kubernetes 也为提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称HPA
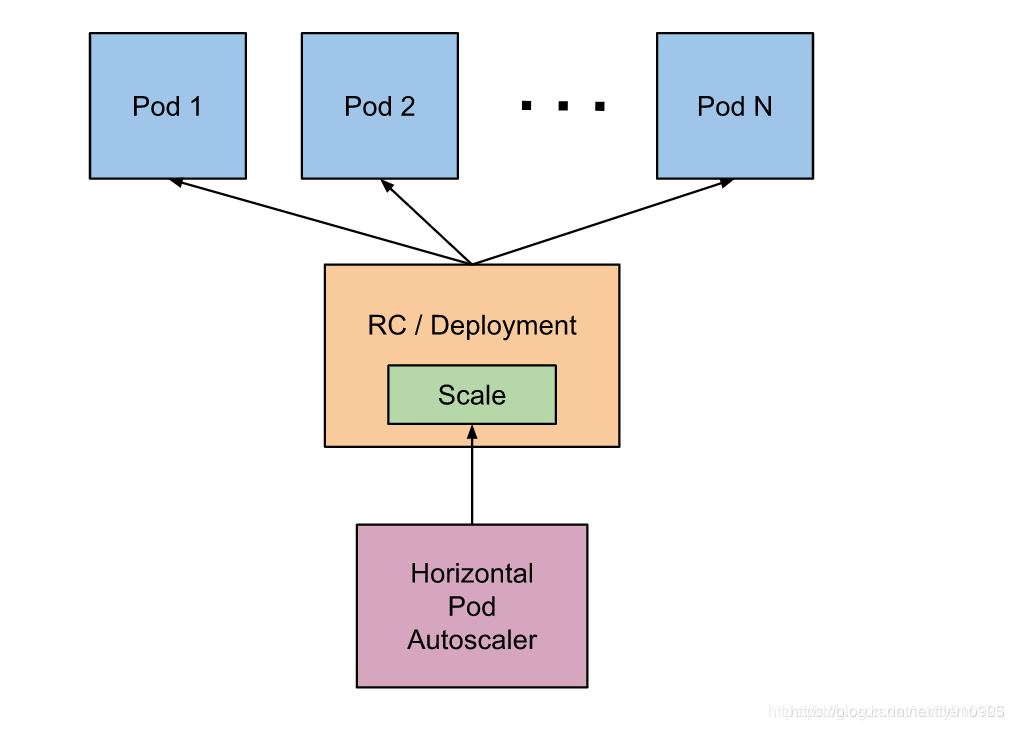
基本原理:HPA 通过监控分析控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量
HPA的实现有两个版本:
- autoscaling/v1,只包含了根据CPU指标的检测,稳定版本
- autoscaling/v2beta1,支持根据memory或者用户自定义指标进行伸缩
如何获取Pod的监控数据?
- k8s 1.8以下:使用heapster,1.11版本完全废弃
- k8s 1.8以上:使用metric-server
思考:为什么之前用 heapster ,现在废弃了项目,改用 metric-server ?
heapster时代,apiserver 会直接将metric请求通过apiserver proxy 的方式转发给集群内的 hepaster 服务,采用这种 proxy 方式是有问题的:
-
http://kubernetes_master_address/api/v1/namespaces/namespace_name/services/service_name[:port_name]/proxy -
proxy只是代理请求,一般用于问题排查,不够稳定,且版本不可控
-
heapster的接口不能像apiserver一样有完整的鉴权以及client集成
-
pod 的监控数据是核心指标(HPA调度),应该和 pod 本身拥有同等地位,即 metric应该作为一种资源存在,如metrics.k8s.io 的形式,称之为 Metric Api
于是官方从 1.8 版本开始逐步废弃 heapster,并提出了上边 Metric api 的概念,而 metrics-server 就是这种概念下官方的一种实现,用于从 kubelet获取指标,替换掉之前的 heapster。
Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,比如获取某一Pod的监控数据:
https://192.168.136.10:6443/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name># https://192.168.136.10:6443/api/v1/namespaces/luffy/pods?limit=500
目前的采集流程:
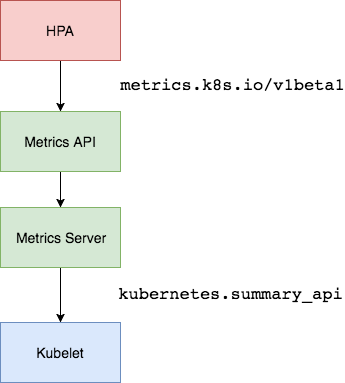
Metric Server
官方介绍
...
Metric server collects metrics from the Summary API, exposed by Kubelet on each node.Metrics Server registered in the main API server through Kubernetes aggregator, which was introduced in Kubernetes 1.7
...
安装
官方代码仓库地址:https://github.com/kubernetes-sigs/metrics-server
Depending on your cluster setup, you may also need to change flags passed to the Metrics Server container. Most useful flags:
--kubelet-preferred-address-types- The priority of node address types used when determining an address for connecting to a particular node (default [Hostname,InternalDNS,InternalIP,ExternalDNS,ExternalIP])--kubelet-insecure-tls- Do not verify the CA of serving certificates presented by Kubelets. For testing purposes only.--requestheader-client-ca-file- Specify a root certificate bundle for verifying client certificates on incoming requests.
$ wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.6/components.yaml
修改args参数:
...84 containers:85 - name: metrics-server86 image: registry.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.687 imagePullPolicy: IfNotPresent88 args:89 - --cert-dir=/tmp90 - --secure-port=444391 - --kubelet-insecure-tls92 - --kubelet-preferred-address-types=InternalIP
...
执行安装:
$ kubectl create -f components.yaml$ kubectl -n kube-system get pods$ kubectl top nodes
kubelet的指标采集
无论是 heapster还是 metric-server,都只是数据的中转和聚合,两者都是调用的 kubelet 的 api 接口获取的数据,而 kubelet 代码中实际采集指标的是 cadvisor 模块,你可以在 node 节点访问 10250 端口获取监控数据:
- Kubelet Summary metrics: https://127.0.0.1:10250/metrics,暴露 node、pod 汇总数据
- Cadvisor metrics: https://127.0.0.1:10250/metrics/cadvisor,暴露 container 维度数据
调用示例:
$ curl -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6InhXcmtaSG5ZODF1TVJ6dUcycnRLT2c4U3ZncVdoVjlLaVRxNG1wZ0pqVmcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi10b2tlbi1xNXBueiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImViZDg2ODZjLWZkYzAtNDRlZC04NmZlLTY5ZmE0ZTE1YjBmMCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbiJ9.iEIVMWg2mHPD88GQ2i4uc_60K4o17e39tN0VI_Q_s3TrRS8hmpi0pkEaN88igEKZm95Qf1qcN9J5W5eqOmcK2SN83Dd9dyGAGxuNAdEwi0i73weFHHsjDqokl9_4RGbHT5lRY46BbIGADIphcTeVbCggI6T_V9zBbtl8dcmsd-lD_6c6uC2INtPyIfz1FplynkjEVLapp_45aXZ9IMy76ljNSA8Uc061Uys6PD3IXsUD5JJfdm7lAt0F7rn9SdX1q10F2lIHYCMcCcfEpLr4Vkymxb4IU4RCR8BsMOPIO_yfRVeYZkG4gU2C47KwxpLsJRrTUcUXJktSEPdeYYXf9w" https://localhost:10250/metrics
kubelet虽然提供了 metric 接口,但实际监控逻辑由内置的cAdvisor模块负责,早期的时候,cadvisor是单独的组件,从k8s 1.12开始,cadvisor 监听的端口在k8s中被删除,所有监控数据统一由Kubelet的API提供。
cadvisor获取指标时实际调用的是 runc/libcontainer库,而libcontainer是对 cgroup文件 的封装,即 cadvsior也只是个转发者,它的数据来自于cgroup文件。
cgroup文件中的值是监控数据的最终来源,如
-
mem usage的值,
-
对于docker容器来讲,来源于
/sys/fs/cgroup/memory/docker/[containerId]/memory.usage_in_bytes -
对于pod来讲,
/sys/fs/cgroup/memory/kubepods/besteffort/pod[podId]/memory.usage_in_bytes或者/sys/fs/cgroup/memory/kubepods/burstable/pod[podId]/memory.usage_in_bytes
-
-
如果没限制内存,Limit = machine_mem,否则来自于
/sys/fs/cgroup/memory/docker/[id]/memory.limit_in_bytes -
内存使用率 = memory.usage_in_bytes/memory.limit_in_bytes
Metrics数据流:

思考:
Metrics Server是独立的一个服务,只能服务内部实现自己的api,是如何做到通过标准的kubernetes 的API格式暴露出去的?
kube-aggregator
kube-aggregator聚合器及Metric-Server的实现
kube-aggregator是对 apiserver 的api的一种拓展机制,它允许开发人员编写一个自己的服务,并把这个服务注册到k8s的api里面,即扩展 API 。

定义一个APIService对象:
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:name: v1beta1.luffy.k8s.io
spec:group: luffy.k8s.iogroupPriorityMinimum: 100insecureSkipTLSVerify: trueservice:name: service-A # 必须https访问namespace: luffyport: 443 version: v1beta1versionPriority: 100
k8s会自动帮我们代理如下url的请求:
proxyPath := "/apis/" + apiService.Spec.Group + "/" + apiService.Spec.Version
即:https://192.168.136.10:6443/apis/luffy.k8s.io/v1beta1/xxxx转到我们的service-A服务中,service-A中只需要实现 https://service-A/luffy.k8s.io/v1beta1/xxxx 即可。
看下metric-server的实现:
$ kubectl get apiservice
NAME SERVICE AVAILABLE
v1beta1.metrics.k8s.io kube-system/metrics-server True$ kubectl get apiservice v1beta1.metrics.k8s.io -oyaml
...
spec:group: metrics.k8s.iogroupPriorityMinimum: 100insecureSkipTLSVerify: trueservice:name: metrics-servernamespace: kube-systemport: 443version: v1beta1versionPriority: 100
...$ kubectl -n kube-system get svc metrics-server
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metrics-server ClusterIP 10.110.111.146 <none> 443/TCP 11h$ curl -k -H "Authorization: Bearer xxxx" https://10.110.111.146
{"paths": ["/apis","/apis/metrics.k8s.io","/apis/metrics.k8s.io/v1beta1","/healthz","/healthz/healthz","/healthz/log","/healthz/ping","/healthz/poststarthook/generic-apiserver-start-informers","/metrics","/openapi/v2","/version"]# https://192.168.136.10:6443/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
#
$ curl -k -H "Authorization: Bearer xxxx" https://10.110.111.146/apis/metrics.k8s.io/v1beta1/namespaces/luffy/pods/myblog-5d9ff54d4b-4rftt$ curl -k -H "Authorization: Bearer xxxx" https://192.168.136.10:6443/apis/metrics.k8s.io/v1beta1/namespaces/luffy/pods/myblog-5d9ff54d4b-4rftt
HPA实践
基于CPU的动态伸缩
创建hpa对象:
# 方式一
$ cat hpa-myblog.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:name: hpa-myblog-cpunamespace: luffy
spec:maxReplicas: 3minReplicas: 1scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: myblogtargetCPUUtilizationPercentage: 10# 方式二
$ kubectl -n luffy autoscale deployment myblog --cpu-percent=10 --min=1 --max=3
Deployment对象必须配置requests的参数,不然无法获取监控数据,也无法通过HPA进行动态伸缩
验证:
$ yum -y install httpd-tools
$ kubectl -n luffy get svc myblog
myblog ClusterIP 10.104.245.225 <none> 80/TCP 6d18h# 为了更快看到效果,先调整副本数为1
$ kubectl -n luffy scale deploy myblog --replicas=1# 模拟1000个用户并发访问页面10万次
$ ab -n 100000 -c 1000 http://10.104.245.225/blog/index/$ kubectl get hpa
$ kubectl -n luffy get pods压力降下来后,会有默认5分钟的scaledown的时间,可以通过controller-manager的如下参数设置:
--horizontal-pod-autoscaler-downscale-stabilizationThe value for this option is a duration that specifies how long the autoscaler has to wait before another downscale operation can be performed after the current one has completed. The default value is 5 minutes (5m0s).
是一个逐步的过程,当前的缩放完成后,下次缩放的时间间隔,比如从3个副本降低到1个副本,中间大概会等待2*5min = 10分钟
基于内存的动态伸缩
创建hpa对象
$ cat hpa-demo-mem.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:name: hpa-demo-memnamespace: luffy
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: hpa-demo-memminReplicas: 1maxReplicas: 3metrics:- type: Resourceresource:name: memorytargetAverageUtilization: 30
加压演示脚本:
$ cat increase-mem-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: increase-mem-confignamespace: luffy
data:increase-mem.sh: |#!/bin/bash mkdir /tmp/memory mount -t tmpfs -o size=40M tmpfs /tmp/memory dd if=/dev/zero of=/tmp/memory/block sleep 60 rm /tmp/memory/block umount /tmp/memory rmdir /tmp/memory
测试deployment:
$ cat hpa-demo-mem-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: hpa-demo-memnamespace: luffy
spec:selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:volumes:- name: increase-mem-scriptconfigMap:name: increase-mem-configcontainers:- name: nginximage: nginx:alpineports:- containerPort: 80volumeMounts:- name: increase-mem-scriptmountPath: /etc/scriptresources:requests:memory: 50Micpu: 50msecurityContext:privileged: true
测试:
$ kubectl create -f increase-mem-config.yaml
$ kubectl create -f hpa-demo-mem.yaml
$ kubectl create -f hpa-demo-mem-deploy.yaml$ kubectl -n luffy exec -ti hpa-demo-mem-7fc75bf5c8-xx424 sh
#/ sh /etc/script/increase-mem.sh# 观察hpa及pod
$ kubectl -n luffy get hpa
$ kubectl -n luffy get po
基于自定义指标的动态伸缩
除了基于 CPU 和内存来进行自动扩缩容之外,我们还可以根据自定义的监控指标来进行。这个我们就需要使用 Prometheus Adapter,Prometheus 用于监控应用的负载和集群本身的各种指标,Prometheus Adapter 可以帮我们使用 Prometheus 收集的指标并使用它们来制定扩展策略,这些指标都是通过 APIServer 暴露的,而且 HPA 资源对象也可以很轻易的直接使用。

架构图:

kubernetes对接分部式存储
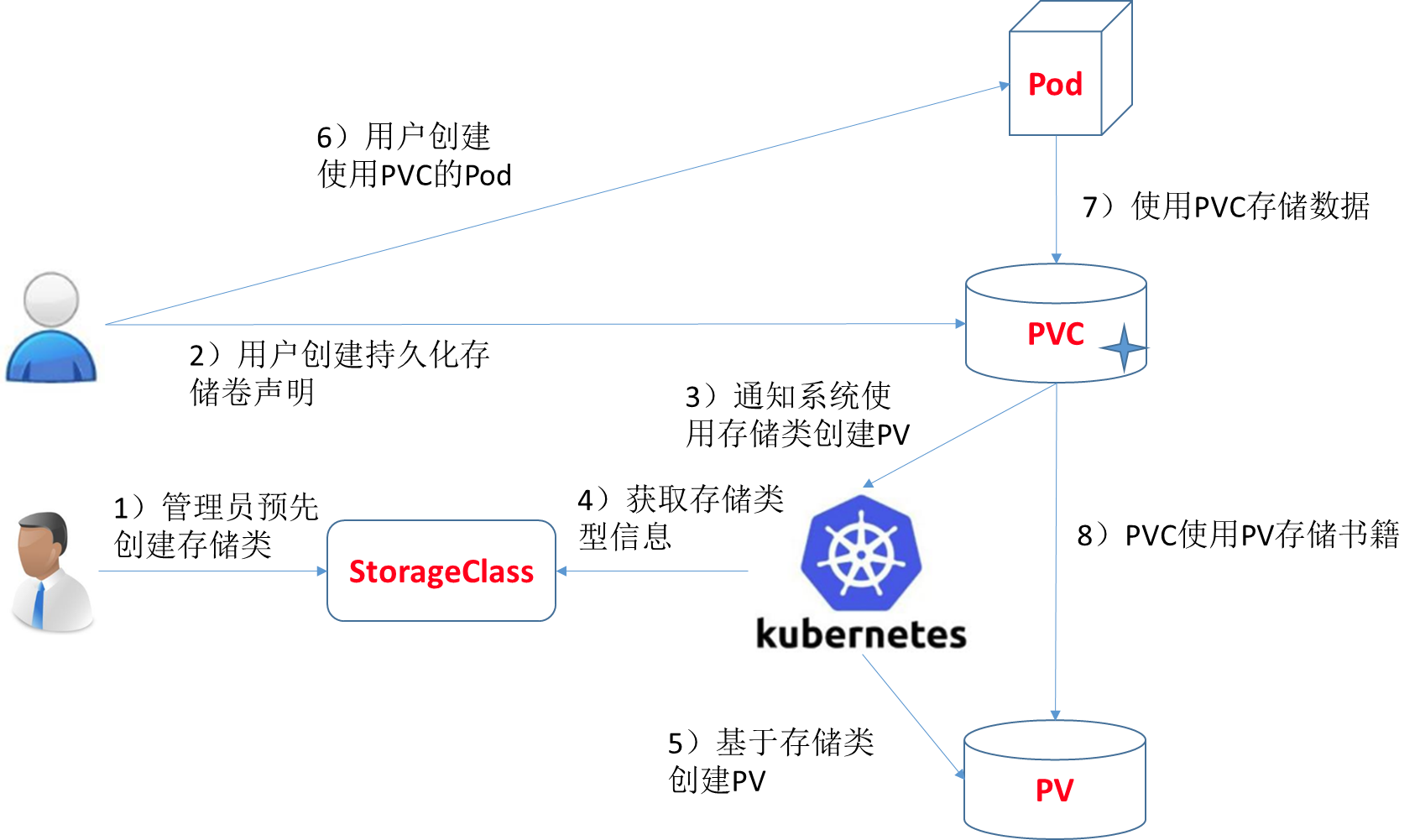
PV与PVC快速入门
k8s存储的目的就是保证Pod重建后,数据不丢失。简单的数据持久化的下述方式:
-
emptyDir
apiVersion: v1 kind: Pod metadata:name: test-pd spec:containers:- image: k8s.gcr.io/test-webservername: webservervolumeMounts:- mountPath: /cachename: cache-volume- image: k8s.gcr.io/test-redisname: redisvolumeMounts:- mountPath: /dataname: cache-volume volumes:- name: cache-volumeemptyDir: {}- Pod内的容器共享卷的数据
- 存在于Pod的生命周期,Pod销毁,数据丢失
- Pod内的容器自动重建后,数据不会丢失
-
hostPath
apiVersion: v1 kind: Pod metadata:name: test-pd spec:containers:- image: k8s.gcr.io/test-webservername: test-containervolumeMounts:- mountPath: /test-pdname: test-volumevolumes:- name: test-volumehostPath:# directory location on hostpath: /data# this field is optionaltype: Directory通常配合nodeSelector使用
-
nfs存储
...volumes:- name: redisdata #卷名称nfs: #使用NFS网络存储卷server: 192.168.31.241 #NFS服务器地址path: /data/redis #NFS服务器共享的目录readOnly: false #是否为只读 ...
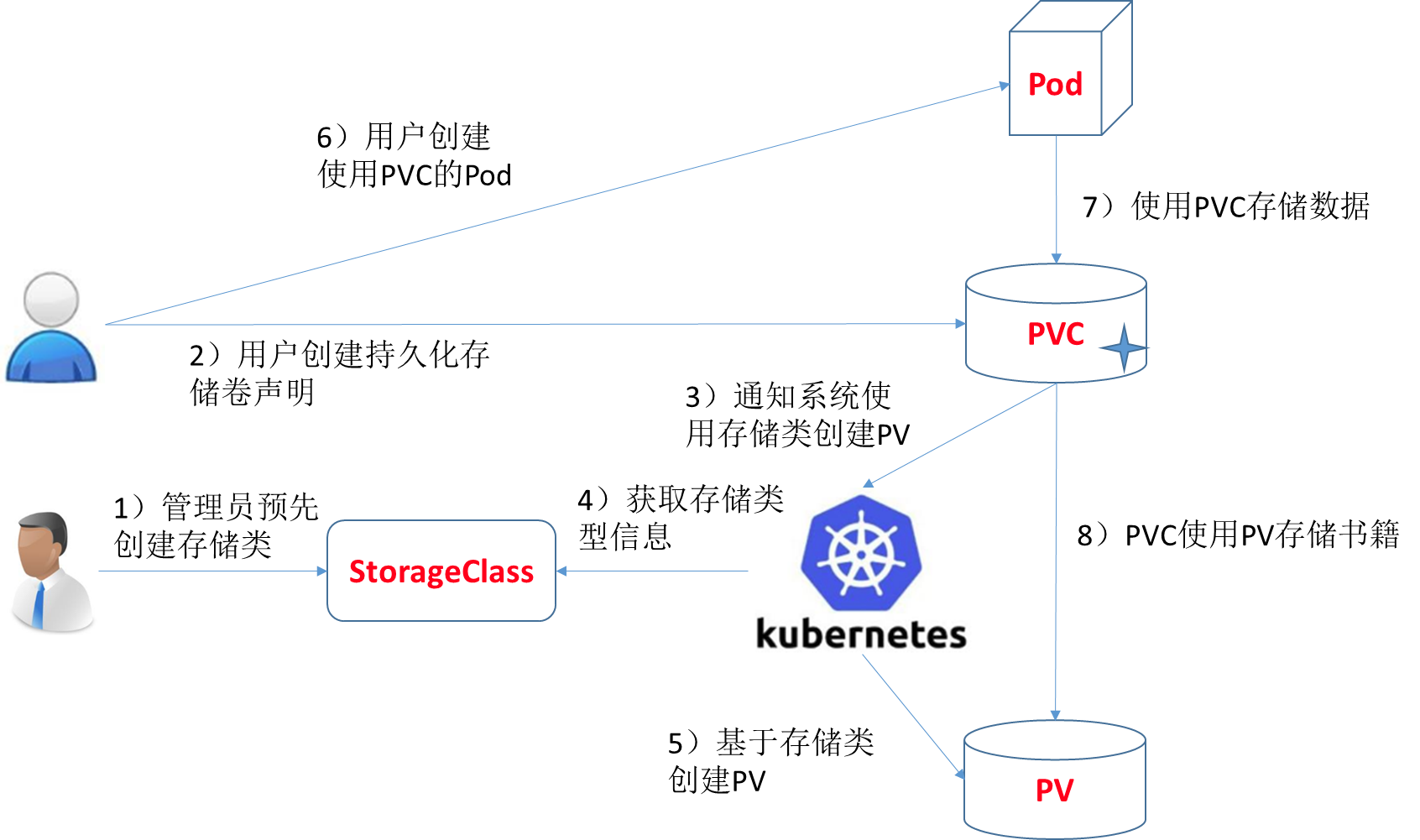
volume支持的种类众多(参考 https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes ),每种对应不同的存储后端实现,因此为了屏蔽后端存储的细节,同时使得Pod在使用存储的时候更加简洁和规范,k8s引入了两个新的资源类型,PV和PVC。
PersistentVolume(持久化卷),是对底层的存储的一种抽象,它和具体的底层的共享存储技术的实现方式有关,比如 Ceph、GlusterFS、NFS 等,都是通过插件机制完成与共享存储的对接。如使用PV对接NFS存储:
apiVersion: v1
kind: PersistentVolume
metadata:name: nfs-pv
spec:capacity: storage: 1GiaccessModes:- ReadWriteOncepersistentVolumeReclaimPolicy: Retainnfs:path: /data/k8sserver: 121.204.157.52- capacity,存储能力, 目前只支持存储空间的设置, 就是我们这里的 storage=1Gi,不过未来可能会加入 IOPS、吞吐量等指标的配置。
- accessModes,访问模式, 是用来对 PV 进行访问模式的设置,用于描述用户应用对存储资源的访问权限,访问权限包括下面几种方式:
- ReadWriteOnce(RWO):读写权限,但是只能被单个节点挂载
- ReadOnlyMany(ROX):只读权限,可以被多个节点挂载
- ReadWriteMany(RWX):读写权限,可以被多个节点挂载

- persistentVolumeReclaimPolicy,pv的回收策略, 目前只有 NFS 和 HostPath 两种类型支持回收策略
- Retain(保留)- 保留数据,需要管理员手工清理数据
- Recycle(回收)- 清除 PV 中的数据,效果相当于执行 rm -rf /thevolume/*
- Delete(删除)- 与 PV 相连的后端存储完成 volume 的删除操作,当然这常见于云服务商的存储服务,比如 ASW EBS。
因为PV是直接对接底层存储的,就像集群中的Node可以为Pod提供计算资源(CPU和内存)一样,PV可以为Pod提供存储资源。因此PV不是namespaced的资源,属于集群层面可用的资源。Pod如果想使用该PV,需要通过创建PVC挂载到Pod中。
PVC全写是PersistentVolumeClaim(持久化卷声明),PVC 是用户存储的一种声明,创建完成后,可以和PV实现一对一绑定。对于真正使用存储的用户不需要关心底层的存储实现细节,只需要直接使用 PVC 即可。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc-nfsnamespace: default
spec:accessModes:- ReadWriteOnceresources:requests:storage: 1Gi然后Pod中通过如下方式去使用:
...spec:containers:- name: nginximage: nginx:alpineimagePullPolicy: IfNotPresentports:- containerPort: 80name: webvolumeMounts: #挂载容器中的目录到pvc nfs中的目录- name: wwwmountPath: /usr/share/nginx/htmlvolumes:- name: wwwpersistentVolumeClaim: #指定pvcclaimName: pvc-nfs
...
PV与PVC管理NFS存储卷实践
环境准备
服务端:121.204.157.52
$ yum -y install nfs-utils rpcbind# 共享目录
$ mkdir -p /data/k8s && chmod 755 /data/k8s$ echo '/data/k8s *(insecure,rw,sync,no_root_squash)'>>/etc/exports$ systemctl enable rpcbind && systemctl start rpcbind
$ systemctl enable nfs && systemctl start nfs
客户端:k8s集群slave节点
$ yum -y install nfs-utils rpcbind
$ mkdir /nfsdata
$ mount -t nfs 121.204.157.52:/data/k8s /nfsdataPV与PVC演示
$ cat pv-nfs.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: nfs-pv
spec:capacity: storage: 1GiaccessModes:- ReadWriteOncepersistentVolumeReclaimPolicy: Retainnfs:path: /data/k8sserver: 121.204.157.52$ kubectl create -f pv-nfs.yaml$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS
nfs-pv 1Gi RWO Retain Available一个 PV 的生命周期中,可能会处于4中不同的阶段:
- Available(可用):表示可用状态,还未被任何 PVC 绑定
- Bound(已绑定):表示 PV 已经被 PVC 绑定
- Released(已释放):PVC 被删除,但是资源还未被集群重新声明
- Failed(失败): 表示该 PV 的自动回收失败
$ cat pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc-nfsnamespace: default
spec:accessModes:- ReadWriteOnceresources:requests:storage: 1Gi$ kubectl create -f pvc.yaml
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-nfs Bound nfs-pv 1Gi RWO 3s
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM
nfs-pv 1Gi RWO Retain Bound default/pvc-nfs #访问模式,storage大小(pvc大小需要小于pv大小),以及 PV 和 PVC 的 storageClassName 字段必须一样,这样才能够进行绑定。#PersistentVolumeController会不断地循环去查看每一个 PVC,是不是已经处于 Bound(已绑定)状态。如果不是,那它就会遍历所有的、可用的 PV,并尝试将其与未绑定的 PVC 进行绑定,这样,Kubernetes 就可以保证用户提交的每一个 PVC,只要有合适的 PV 出现,它就能够很快进入绑定状态。而所谓将一个 PV 与 PVC 进行“绑定”,其实就是将这个 PV 对象的名字,填在了 PVC 对象的 spec.volumeName 字段上。# 查看nfs数据目录
$ ls /nfsdata创建Pod挂载pvc
$ cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: nfs-pvc
spec:replicas: 1selector: #指定Pod的选择器matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:alpineimagePullPolicy: IfNotPresentports:- containerPort: 80name: webvolumeMounts: #挂载容器中的目录到pvc nfs中的目录- name: wwwmountPath: /usr/share/nginx/htmlvolumes:- name: wwwpersistentVolumeClaim: #指定pvcclaimName: pvc-nfs$ kubectl create -f deployment.yaml# 查看容器/usr/share/nginx/html目录
storageClass实现动态挂载
创建pv及pvc过程是手动,且pv与pvc一一对应,手动创建很繁琐。因此,通过storageClass + provisioner的方式来实现通过PVC自动创建并绑定PV。
部署: https://github.com/kubernetes-retired/external-storage
provisioner.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: nfs-client-provisionerlabels:app: nfs-client-provisioner# replace with namespace where provisioner is deployednamespace: default
spec:replicas: 1selector:matchLabels:app: nfs-client-provisionerstrategy:type: Recreateselector:matchLabels:app: nfs-client-provisionertemplate:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisionercontainers:- name: nfs-client-provisionerimage: quay.io/external_storage/nfs-client-provisioner:latestvolumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: luffy.com/nfs- name: NFS_SERVERvalue: 172.21.51.55- name: NFS_PATH value: /data/k8svolumes:- name: nfs-client-rootnfs:server: 172.21.51.55path: /data/k8s
rbac.yaml
kind: ServiceAccount
apiVersion: v1
metadata:name: nfs-client-provisionernamespace: nfs-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: nfs-client-provisioner-runnernamespace: nfs-provisioner
rules:- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: run-nfs-client-provisionernamespace: nfs-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: nfs-provisioner
roleRef:kind: ClusterRolename: nfs-client-provisioner-runnerapiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: nfs-provisioner
rules:- apiGroups: [""]resources: ["endpoints"]verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: nfs-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisioner# replace with namespace where provisioner is deployednamespace: nfs-provisioner
roleRef:kind: Rolename: leader-locking-nfs-client-provisionerapiGroup: rbac.authorization.k8s.io
storage-class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: nfs
provisioner: luffy.com/nfs
pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: test-claim2
spec:accessModes:- ReadWriteManyresources:requests:storage: 1MistorageClassName: nfs
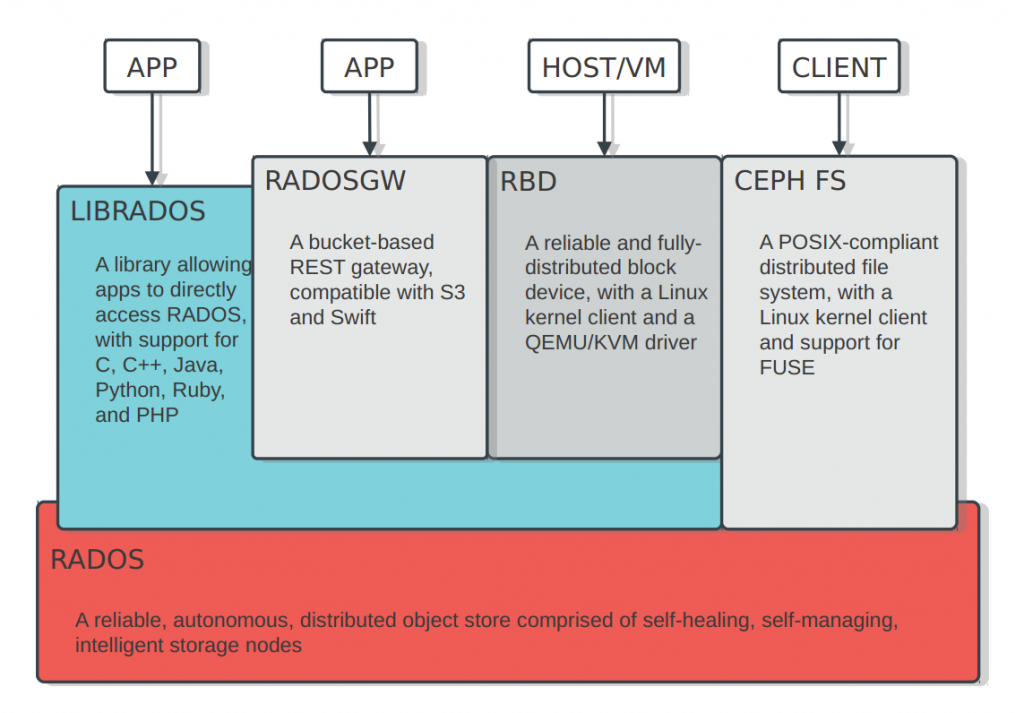
对接Ceph存储实践
ceph的安装及使用参考 http://docs.ceph.org.cn/start/intro/
# CephFS需要使用两个Pool来分别存储数据和元数据
ceph osd pool create cephfs_data 128
ceph osd pool create cephfs_meta 128
ceph osd lspools# 创建一个CephFS
ceph fs new cephfs cephfs_meta cephfs_data# 查看
ceph fs ls#
rados -p cephfs_meta ls
storageClass实现动态挂载
创建pv及pvc过程是手动,且pv与pvc一一对应,手动创建很繁琐。因此,通过storageClass + provisioner的方式来实现通过PVC自动创建并绑定PV。
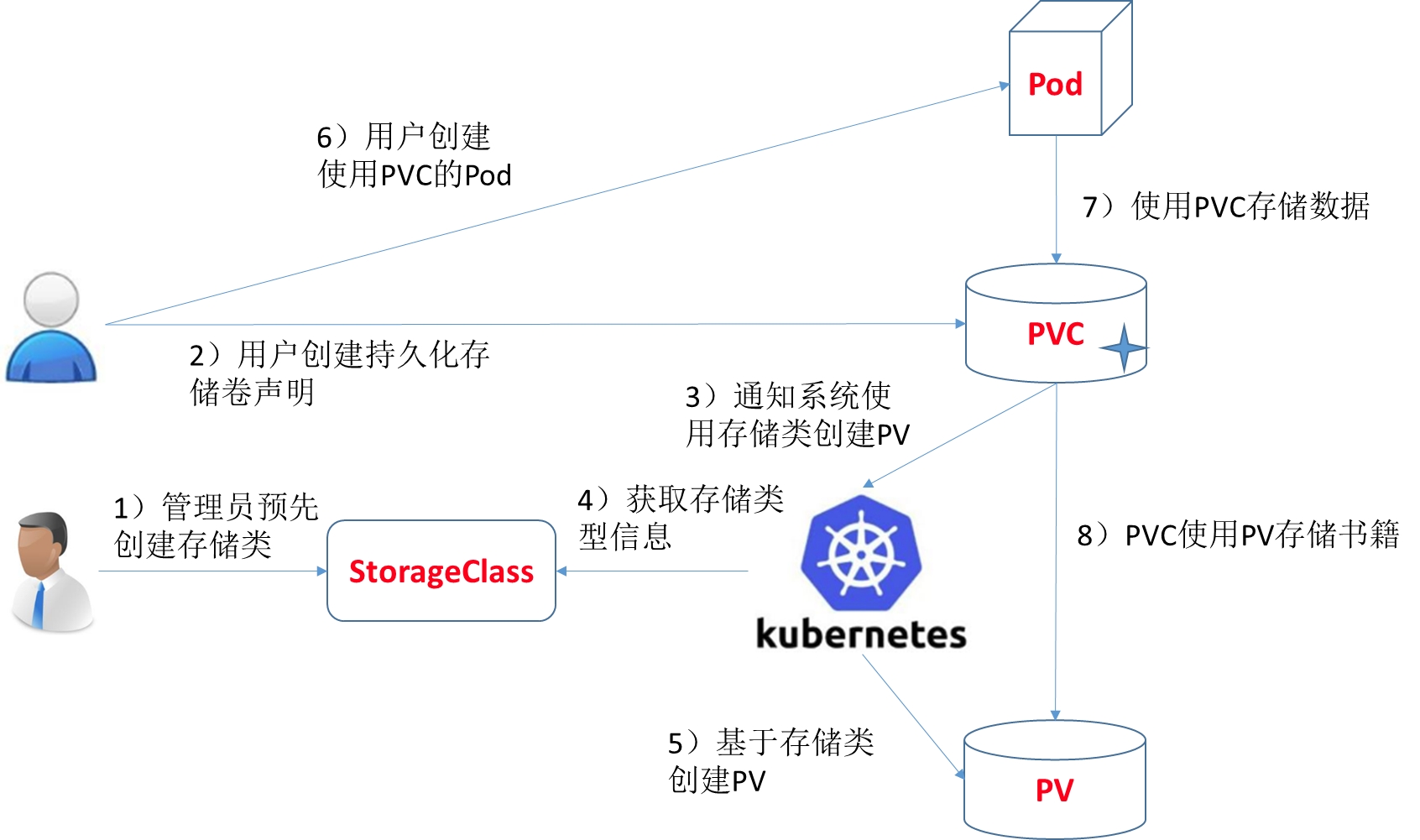
比如,针对cephfs,可以创建如下类型的storageclass:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:name: dynamic-cephfs
provisioner: ceph.com/cephfs
parameters:monitors: 121.204.157.52:6789adminId: adminadminSecretName: ceph-admin-secretadminSecretNamespace: "kube-system"claimRoot: /volumes/kubernetes
NFS,ceph-rbd,cephfs均提供了对应的provisioner
部署cephfs-provisioner
$ cat external-storage-cephfs-provisioner.yaml
apiVersion: v1
kind: ServiceAccount
metadata:name: cephfs-provisionernamespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: cephfs-provisioner
rules:- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["create", "update", "patch"]- apiGroups: [""]resources: ["endpoints"]verbs: ["get", "list", "watch", "create", "update", "patch"]- apiGroups: [""]resources: ["secrets"]verbs: ["create", "get", "delete"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: cephfs-provisioner
subjects:- kind: ServiceAccountname: cephfs-provisionernamespace: kube-system
roleRef:kind: ClusterRolename: cephfs-provisionerapiGroup: rbac.authorization.k8s.io---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:name: cephfs-provisionernamespace: kube-system
rules:- apiGroups: [""]resources: ["secrets"]verbs: ["create", "get", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:name: cephfs-provisionernamespace: kube-system
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: cephfs-provisioner
subjects:
- kind: ServiceAccountname: cephfs-provisionernamespace: kube-system---
apiVersion: apps/v1
kind: Deployment
metadata:name: cephfs-provisionernamespace: kube-system
spec:replicas: 1selector:matchLabels:app: cephfs-provisionerstrategy:type: Recreatetemplate:metadata:labels:app: cephfs-provisionerspec:containers:- name: cephfs-provisionerimage: "quay.io/external_storage/cephfs-provisioner:latest"env:- name: PROVISIONER_NAMEvalue: ceph.com/cephfsimagePullPolicy: IfNotPresentcommand:- "/usr/local/bin/cephfs-provisioner"args:- "-id=cephfs-provisioner-1"- "-disable-ceph-namespace-isolation=true"serviceAccount: cephfs-provisioner
在ceph monitor机器中查看admin账户的key
$ ceph auth ls
$ ceph auth get-key client.admin
AQAejeJbowvgMhAAsuloUOvepcj/TXEIoSrd7A==创建secret
$ echo -n AQAejeJbowvgMhAAsuloUOvepcj/TXEIoSrd7A==|base64
QVFBZWplSmJvd3ZnTWhBQXN1bG9VT3ZlcGNqL1RYRUlvU3JkN0E9PQ==
$ cat ceph-admin-secret.yaml
apiVersion: v1
data:key: QVFBZWplSmJvd3ZnTWhBQXN1bG9VT3ZlcGNqL1RYRUlvU3JkN0E9PQ==
kind: Secret
metadata:name: ceph-admin-secretnamespace: kube-system
type: Opaque创建storageclass
$ cat cephfs-storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:name: dynamic-cephfs
provisioner: ceph.com/cephfs
parameters:monitors: 36.111.140.31:6789adminId: adminadminSecretName: ceph-admin-secretadminSecretNamespace: "kube-system"claimRoot: /volumes/kubernetes动态pvc验证及实现分析
使用流程: 创建pvc,指定storageclass和存储大小,即可实现动态存储。
创建pvc测试自动生成pv
$ cat cephfs-pvc-test.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: cephfs-claim
spec:accessModes: - ReadWriteOncestorageClassName: dynamic-cephfsresources:requests:storage: 2Gi$ kubectl create -f cephfs-pvc-test.yaml$ kubectl get pv
pvc-2abe427e-7568-442d-939f-2c273695c3db 2Gi RWO Delete Bound default/cephfs-claim dynamic-cephfs 1s创建Pod使用pvc挂载cephfs数据盘
$ cat test-pvc-cephfs.yaml
apiVersion: v1
kind: Pod
metadata:name: nginx-podlabels:name: nginx-pod
spec:containers:- name: nginx-podimage: nginx:alpineports:- name: webcontainerPort: 80volumeMounts:- name: cephfsmountPath: /usr/share/nginx/htmlvolumes:- name: cephfspersistentVolumeClaim:claimName: cephfs-claim$ kubectl create -f test-pvc-cephfs.yaml我们所说的容器的持久化,实际上应该理解为宿主机中volume的持久化,因为Pod是支持销毁重建的,所以只能通过宿主机volume持久化,然后挂载到Pod内部来实现Pod的数据持久化。
宿主机上的volume持久化,因为要支持数据漂移,所以通常是数据存储在分布式存储中,宿主机本地挂载远程存储(NFS,Ceph,OSS),这样即使Pod漂移也不影响数据。
k8s的pod的挂载盘通常的格式为:
/var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>查看nginx-pod的挂载盘,
$ df -TH
/var/lib/kubelet/pods/61ba43c5-d2e9-4274-ac8c-008854e4fa8e/volumes/kubernetes.io~cephfs/pvc-2abe427e-7568-442d-939f-2c273695c3db/$ findmnt /var/lib/kubelet/pods/61ba43c5-d2e9-4274-ac8c-008854e4fa8e/volumes/kubernetes.io~cephfs/pvc-2abe427e-7568-442d-939f-2c273695c3db/36.111.140.31:6789:/volumes/kubernetes/kubernetes/kubernetes-dynamic-pvc-ffe3d84d-c433-11ea-b347-6acc3cf3c15f使用Helm3管理复杂应用的部署
认识Helm
-
为什么有helm?
-
Helm是什么?
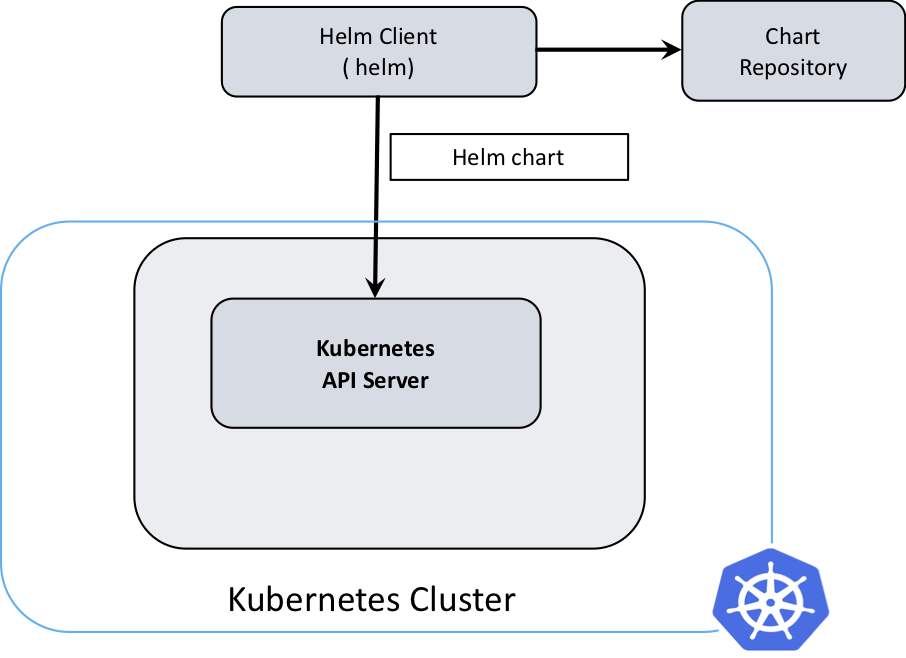
kubernetes的包管理器,“可以将Helm看作Linux系统下的apt-get/yum”。
-
对于应用发布者而言,可以通过Helm打包应用,管理应用依赖关系,管理应用版本并发布应用到软件仓库。
-
对于使用者而言,使用Helm后不用需要了解Kubernetes的Yaml语法并编写应用部署文件,可以通过Helm下载并在kubernetes上安装需要的应用。
除此以外,Helm还提供了kubernetes上的软件部署,删除,升级,回滚应用的强大功能。
-
-
Helm的版本
-
helm2
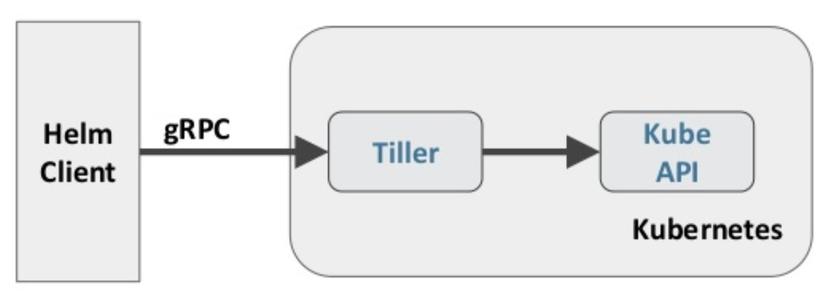
C/S架构,helm通过Tiller与k8s交互
-
helm3
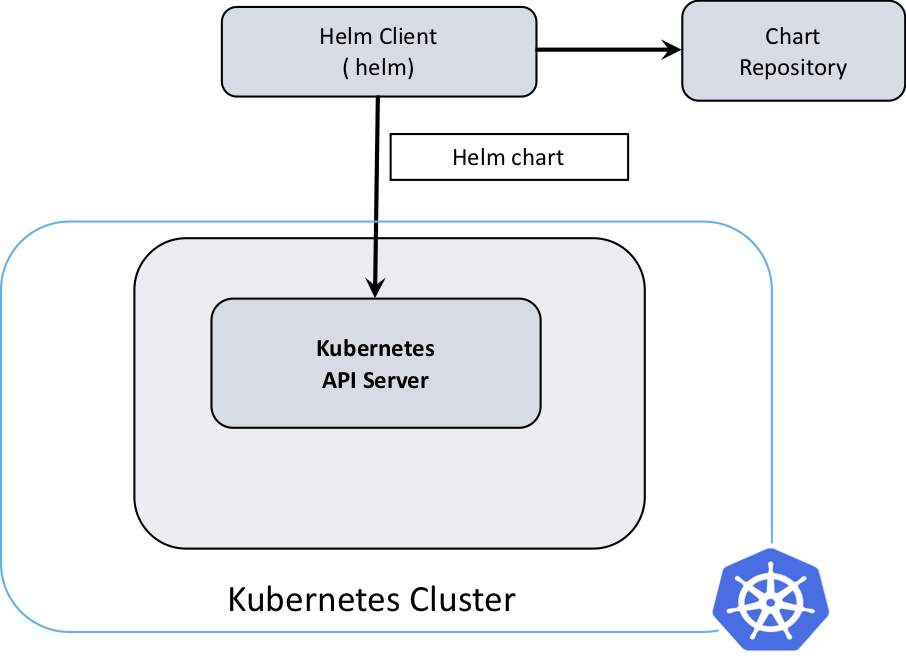
-
从安全性和易用性方面考虑,移除了Tiller服务端,helm3直接使用kubeconfig文件鉴权访问APIServer服务器
-
由二路合并升级成为三路合并补丁策略( 旧的配置,线上状态,新的配置 )
helm install very_important_app ./very_important_app这个应用的副本数量设置为 3 。现在,如果有人不小心执行了
kubectl edit或:kubectl scale -replicas=0 deployment/very_important_app然后,团队中的某个人发现 very_important_app 莫名其妙宕机了,尝试执行命令:
helm rollback very_important_app在 Helm 2 中,这个操作将比较旧的配置与新的配置,然后生成一个更新补丁。由于,误操作的人仅修改了应用的线上状态(旧的配置并未更新)。Helm 在回滚时,什么事情也不会做。因为旧的配置与新的配置没有差别(都是 3 个副本)。然后,Helm 不执行回滚,副本数继续保持为 0
-
移除了helm serve本地repo仓库
-
创建应用时必须指定名字(或者–generate-name随机生成)
-
-
-
Helm的重要概念
- chart,应用的信息集合,包括各种对象的配置模板、参数定义、依赖关系、文档说明等
- Repoistory,chart仓库,存储chart的地方,并且提供了一个该 Repository 的 Chart 包的清单文件以供查询。Helm 可以同时管理多个不同的 Repository。
- release, 当 chart 被安装到 kubernetes 集群,就生成了一个 release , 是 chart 的运行实例,代表了一个正在运行的应用
helm 是包管理工具,包就是指 chart,helm 能够:
- 从零创建chart
- 与仓库交互,拉取、保存、更新 chart
- 在kubernetes集群中安装、卸载 release
- 更新、回滚、测试 release
安装与快速入门实践
下载最新的稳定版本:https://get.helm.sh/helm-v3.2.4-linux-amd64.tar.gz
更多版本可以参考: https://github.com/helm/helm/releases
# k8s-master节点
$ wget https://get.helm.sh/helm-v3.2.4-linux-amd64.tar.gz
$ tar -zxf helm-v3.2.4-linux-amd64.tar.gz$ cp linux-amd64/helm /usr/local/bin/# 验证安装
$ helm version
version.BuildInfo{Version:"v3.2.4", GitCommit:"0ad800ef43d3b826f31a5ad8dfbb4fe05d143688", GitTreeState:"clean", GoVersion:"go1.13.12"}
$ helm env# 添加仓库
$ helm repo add stable http://mirror.azure.cn/kubernetes/charts/
# 同步最新charts信息到本地
$ helm repo update快速入门实践:
示例一:使用helm安装mysql应用
# helm 搜索chart包
$ helm search repo mysql# 从仓库安装
$ helm install mysql stable/mysql$ helm ls
$ kubectl get all # 从chart仓库中把chart包下载到本地
$ helm pull stable/mysql
$ tree mysql
示例二:新建nginx的chart并安装
$ helm create nginx# 从本地安装
$ helm install nginx ./nginx# 安装到别的命名空间luffy
$ helm -n luffy install ./nginx# 查看
$ helm ls
$ helm -n luffy ls#
$ kubectl get all
$ kubectl -n luffy get all
Chart的模板语法及开发
nginx的chart实现分析
格式:
$ tree nginx/
nginx/
├── charts # 存放子chart
├── Chart.yaml # 该chart的全局定义信息
├── templates # chart运行所需的资源清单模板,用于和values做渲染
│ ├── deployment.yaml
│ ├── _helpers.tpl # 定义全局的命名模板,方便在其他模板中引入使用
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── NOTES.txt # helm安装完成后终端的提示信息
│ ├── serviceaccount.yaml
│ ├── service.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml # 模板使用的默认值信息
很明显,资源清单都在templates中,数据来源于values.yaml,安装的过程就是将模板与数据融合成k8s可识别的资源清单,然后部署到k8s环境中。
分析模板文件的实现:
-
引用命名模板并传递作用域
{{ include "nginx.fullname" . }}include从_helpers.tpl中引用命名模板,并传递顶级作用域.
-
内置对象
.Values .Release.NameRelease:该对象描述了 release 本身的相关信息,它内部有几个对象:Release.Name:release 名称Release.Namespace:release 安装到的命名空间Release.IsUpgrade:如果当前操作是升级或回滚,则该值为 trueRelease.IsInstall:如果当前操作是安装,则将其设置为 trueRelease.Revision:release 的 revision 版本号,在安装的时候,值为1,每次升级或回滚都会增加Reelase.Service:渲染当前模板的服务,在 Helm 上,实际上该值始终为 Helm
Values:从values.yaml文件和用户提供的 values 文件传递到模板的 Values 值Chart:获取Chart.yaml文件的内容,该文件中的任何数据都可以访问,例如{{ .Chart.Name }}-{{ .Chart.Version}}可以渲染成mychart-0.1.0
-
模板定义
{{- define "nginx.fullname" -}} {{- if .Values.fullnameOverride }} {{- .Values.fullnameOverride | trunc 63 | trimSuffix "-" }} {{- else }} {{- $name := default .Chart.Name .Values.nameOverride }} {{- if contains $name .Release.Name }} {{- .Release.Name | trunc 63 | trimSuffix "-" }} {{- else }} {{- printf "%s-%s" .Release.Name $name | trunc 63 | trimSuffix "-" }} {{- end }} {{- end }} {{- end }}-
{{- 去掉左边的空格及换行,-}} 去掉右侧的空格及换行
-
示例
apiVersion: v1 kind: ConfigMap metadata:name: {{ .Release.Name }}-configmap data:myvalue: "Hello World"drink: {{ .Values.favorite.drink | default "tea" | quote }}food: {{ .Values.favorite.food | upper | quote }}{{ if eq .Values.favorite.drink "coffee" }}mug: true{{ end }}渲染完后是:
apiVersion: v1 kind: ConfigMap metadata:name: mychart-1575971172-configmap data:myvalue: "Hello World"drink: "coffee"food: "PIZZA"mug: true
-
-
管道及方法
-
trunc表示字符串截取,63作为参数传递给trunc方法,trimSuffix表示去掉
-后缀{{- .Values.fullnameOverride | trunc 63 | trimSuffix "-" }} -
nindent表示前面的空格数
selector:matchLabels:{{- include "nginx.selectorLabels" . | nindent 6 }} -
lower表示将内容小写,quote表示用双引号引起来
value: {{ include "mytpl" . | lower | quote }}
-
-
条件判断语句每个if对应一个end
{{- if .Values.fullnameOverride }} ... {{- else }} ... {{- end }}通常用来根据values.yaml中定义的开关来控制模板中的显示:
{{- if not .Values.autoscaling.enabled }}replicas: {{ .Values.replicaCount }} {{- end }} -
定义变量,模板中可以通过变量名字去引用
{{- $name := default .Chart.Name .Values.nameOverride }} -
遍历values的数据
{{- with .Values.nodeSelector }}nodeSelector:{{- toYaml . | nindent 8 }}{{- end }}toYaml处理值中的转义及特殊字符, “kubernetes.io/role”=master , name=“value1,value2” 类似的情况
-
default设置默认值
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
Helm template
hpa.yaml
{{- if .Values.autoscaling.enabled }}
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:name: {{ include "nginx.fullname" . }}labels:{{- include "nginx.labels" . | nindent 4 }}
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: {{ include "nginx.fullname" . }}minReplicas: {{ .Values.autoscaling.minReplicas }}maxReplicas: {{ .Values.autoscaling.maxReplicas }}metrics:{{- if .Values.autoscaling.targetCPUUtilizationPercentage }}- type: Resourceresource:name: cputargetAverageUtilization: {{ .Values.autoscaling.targetCPUUtilizationPercentage }}{{- end }}{{- if .Values.autoscaling.targetMemoryUtilizationPercentage }}- type: Resourceresource:name: memorytargetAverageUtilization: {{ .Values.autoscaling.targetMemoryUtilizationPercentage }}{{- end }}
{{- end }}
创建应用的时候赋值
- set的方式
# 改变副本数和resource值
$ helm install nginx-2 ./nginx --set replicaCount=2 --set resources.limits.cpu=200m --set resources.limits.memory=256Mi-
value文件的方式
$ cat nginx-values.yaml resources:limits:cpu: 100mmemory: 128Mirequests:cpu: 100mmemory: 128Mi autoscaling:enabled: trueminReplicas: 1maxReplicas: 3targetCPUUtilizationPercentage: 80 ingress:enabled: truehosts:- host: chart-example.luffy.compaths:- /$ helm install -f nginx-values.yaml nginx-3 ./nginx
更多语法参考:
https://helm.sh/docs/topics/charts/
部署mysql失败的问题
实战:使用Helm部署Harbor镜像及chart仓库
harbor踩坑部署
架构 https://github.com/goharbor/harbor/wiki/Architecture-Overview-of-Harbor
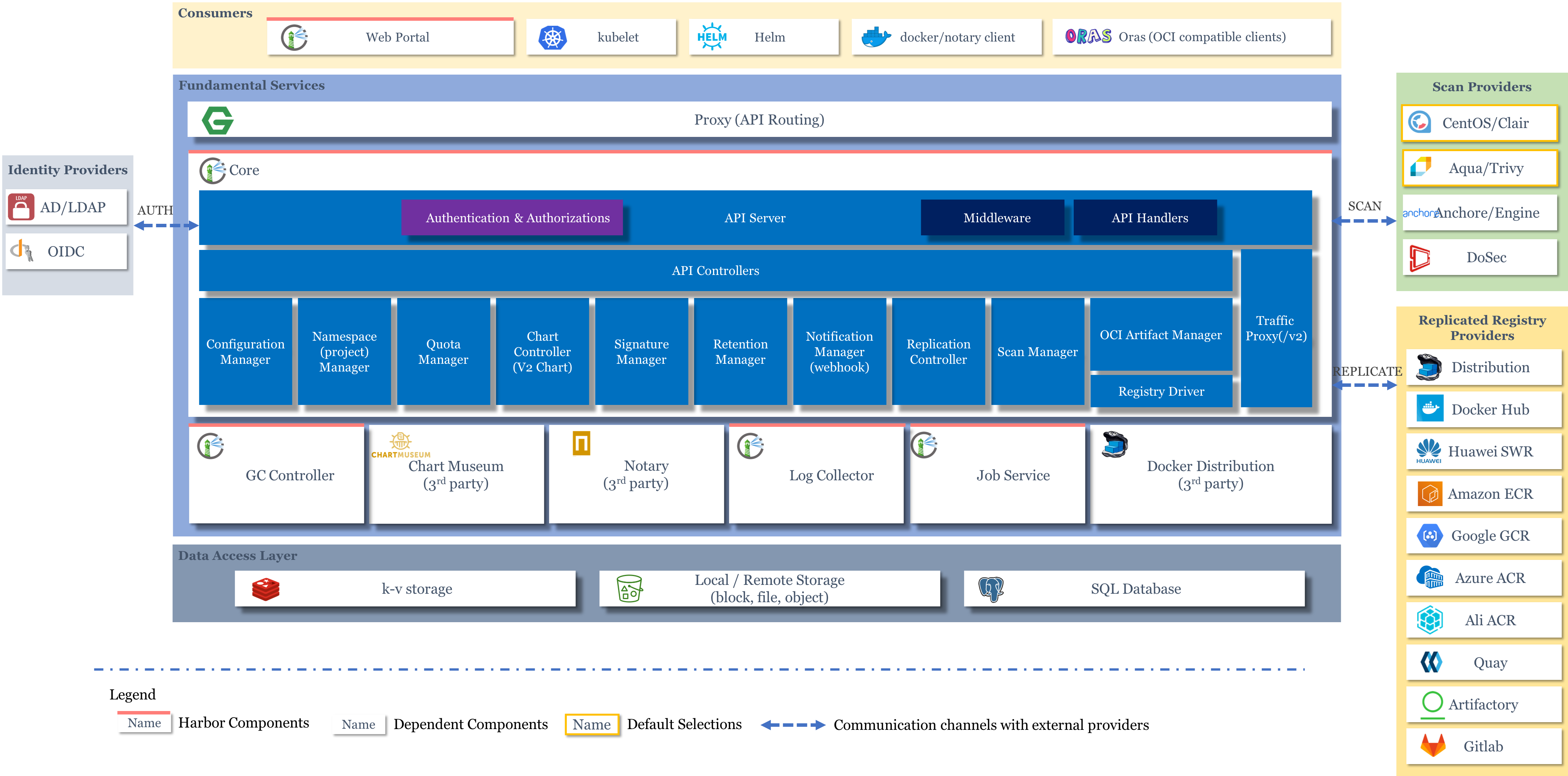
- Core,核心组件
- API Server,接收处理用户请求
- Config Manager :所有系统的配置,比如认证、邮件、证书配置等
- Project Manager:项目管理
- Quota Manager :配额管理
- Chart Controller:chart管理
- Replication Controller :镜像副本控制器,可以与不同类型的仓库实现镜像同步
- Distribution (docker registry)
- Docker Hub
- …
- Scan Manager :扫描管理,引入第三方组件,进行镜像安全扫描
- Registry Driver :镜像仓库驱动,目前使用docker registry
- Job Service,执行异步任务,如同步镜像信息
- Log Collector,统一日志收集器,收集各模块日志
- GC Controller
- Chart Museum,chart仓库服务,第三方
- Docker Registry,镜像仓库服务
- kv-storage,redis缓存服务,job service使用,存储job metadata
- local/remote storage,存储服务,比较镜像存储
- SQL Database,postgresl,存储用户、项目等元数据
通常用作企业级镜像仓库服务,实际功能强大很多。
组件众多,因此使用helm部署
# 添加harbor chart仓库
$ helm repo add harbor https://helm.goharbor.io# 搜索harbor的chart
$ helm search repo harbor# 不知道如何部署,因此拉到本地
$ helm pull harbor/harbor --version 1.4.1
创建pvc
$ kubectl create namespace harbor
$ cat harbor-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: harbor-pvcnamespace: harbor
spec:accessModes: - ReadWriteOncestorageClassName: dynamic-cephfsresources:requests:storage: 20Gi
修改harbor配置:
- 开启ingress访问
- externalURL,web访问入口,和ingress的域名相同
- 持久化,使用PVC对接的cephfs
- harborAdminPassword: “Harbor12345”,管理员默认账户 admin/Harbor12345
- 开启chartmuseum
- clair和trivy漏洞扫描组件,暂不启用
helm创建:
# 使用本地chart安装
$ helm install harbor ./harbor -n harbor 踩坑一:redis持久化数据目录权限导致无法登录
redis数据目录,/var/lib/redis,需要设置redis的用户及用户组权限
initContainers:- name: "change-permission-of-directory"image: {{ .Values.redis.internal.image.repository }}:{{ .Values.redis.internal.image.tag }}imagePullPolicy: {{ .Values.imagePullPolicy }}command: ["/bin/sh"]args: ["-c", "chown -R 999:999 /var/lib/redis"]securityContext:runAsUser: 0volumeMounts:- name: datamountPath: /var/lib/redissubPath: {{ $redis.subPath }}
踩坑二:registry组件的镜像存储目录权限导致镜像推送失败
registry的镜像存储目录,需要设置registry用户的用户及用户组,不然镜像推送失败
initContainers:- name: "change-permission-of-directory"securityContext:runAsUser: 0image: {{ .Values.registry.registry.image.repository }}:{{ .Values.registry.registry.image.tag }}imagePullPolicy: {{ .Values.imagePullPolicy }}command: ["/bin/sh"]args: ["-c", "chown -R 10000:10000 {{ .Values.persistence.imageChartStorage.filesystem.rootdirectory }}"]volumeMounts:- name: registry-datamountPath: {{ .Values.persistence.imageChartStorage.filesystem.rootdirectory }}subPath: {{ .Values.persistence.persistentVolumeClaim.registry.subPath }}
踩坑三:chartmuseum存储目录权限,导致chart推送失败
initContainers:- name: "change-permission-of-directory"image: {{ .Values.chartmuseum.image.repository }}:{{ .Values.chartmuseum.image.tag }}imagePullPolicy: {{ .Values.imagePullPolicy }}command: ["/bin/sh"]args: ["-c", "chown -R 10000:10000 /chart_storage"]securityContext:runAsUser: 0volumeMounts:- name: chartmuseum-datamountPath: /chart_storagesubPath: {{ .Values.persistence.persistentVolumeClaim.chartmuseum.subPath }}
更新内容后,执行更新release
$ helm upgrade harbor -n harbor ./
推送镜像到Harbor仓库
配置hosts及docker非安全仓库:
$ cat /etc/hosts
...
192.168.136.10 k8s-master core.harbor.domain
...$ cat /etc/docker/daemon.json
{ "insecure-registries": [ "192.168.136.10:5000", "core.harbor.domain" ], "registry-mirrors" : [ "https://8xpk5wnt.mirror.aliyuncs.com" ]
} #
$ systemctl restart docker# 使用账户密码登录admin/Harbor12345
$ docker login core.harbor.domain$ docker tag nginx:alpine core.harbor.domain/library/nginx:alpine
$ docker push core.harbor.domain/library/nginx:alpine
推送chart到Harbor仓库
helm3默认没有安装helm push插件,需要手动安装。插件地址 https://github.com/chartmuseum/helm-push
安装插件:
$ helm plugin install https://github.com/chartmuseum/helm-push离线安装:
$ helm plugin install ./helm-push添加repo
$ helm repo add myharbor https://core.harbor.domain/chartrepo/library
# x509错误# 添加证书信任,根证书为配置给ingress使用的证书
$ kubectl get secret harbor-harbor-ingress -n harbor -o jsonpath="{.data.ca\.crt}" | base64 -d >harbor.ca.crt$ cp harbor.ca.crt /etc/pki/ca-trust/source/anchors
$ update-ca-trust enable; update-ca-trust extract# 再次添加
$ helm repo add myharbor https://core.harbor.domain/chartrepo/library --ca-file=harbor.ca.crt$ helm repo ls推送chart到仓库:
$ helm push harbor myharbor --ca-file=harbor.ca.crt -u admin -p Harbor12345查看harbor仓库的chart
课程小结
使用k8s的进阶内容。
-
学习k8s在etcd中数据的存储,掌握etcd的基本操作命令
-
理解k8s调度的过程,预选及优先。影响调度策略的设置
-
Flannel网络的原理学习,了解网络的流向,帮助定位问题
-
认证与授权,掌握kubectl、kubelet、rbac及二次开发如何调度API
-
利用HPA进行业务动态扩缩容,通过metrics-server了解整个k8s的监控体系

-
PV + PVC
-
Helm
e.filesystem.rootdirectory }}"]
volumeMounts:
- name: registry-data
mountPath: {{ .Values.persistence.imageChartStorage.filesystem.rootdirectory }}
subPath: {{ .Values.persistence.persistentVolumeClaim.registry.subPath }}
踩坑三:chartmuseum存储目录权限,导致chart推送失败```goinitContainers:- name: "change-permission-of-directory"image: {{ .Values.chartmuseum.image.repository }}:{{ .Values.chartmuseum.image.tag }}imagePullPolicy: {{ .Values.imagePullPolicy }}command: ["/bin/sh"]args: ["-c", "chown -R 10000:10000 /chart_storage"]securityContext:runAsUser: 0volumeMounts:- name: chartmuseum-datamountPath: /chart_storagesubPath: {{ .Values.persistence.persistentVolumeClaim.chartmuseum.subPath }}
更新内容后,执行更新release
$ helm upgrade harbor -n harbor ./
推送镜像到Harbor仓库
配置hosts及docker非安全仓库:
$ cat /etc/hosts
...
192.168.136.10 k8s-master core.harbor.domain
...$ cat /etc/docker/daemon.json
{ "insecure-registries": [ "192.168.136.10:5000", "core.harbor.domain" ], "registry-mirrors" : [ "https://8xpk5wnt.mirror.aliyuncs.com" ]
} #
$ systemctl restart docker# 使用账户密码登录admin/Harbor12345
$ docker login core.harbor.domain$ docker tag nginx:alpine core.harbor.domain/library/nginx:alpine
$ docker push core.harbor.domain/library/nginx:alpine
推送chart到Harbor仓库
helm3默认没有安装helm push插件,需要手动安装。插件地址 https://github.com/chartmuseum/helm-push
安装插件:
$ helm plugin install https://github.com/chartmuseum/helm-push离线安装:
$ helm plugin install ./helm-push添加repo
$ helm repo add myharbor https://core.harbor.domain/chartrepo/library
# x509错误# 添加证书信任,根证书为配置给ingress使用的证书
$ kubectl get secret harbor-harbor-ingress -n harbor -o jsonpath="{.data.ca\.crt}" | base64 -d >harbor.ca.crt$ cp harbor.ca.crt /etc/pki/ca-trust/source/anchors
$ update-ca-trust enable; update-ca-trust extract# 再次添加
$ helm repo add myharbor https://core.harbor.domain/chartrepo/library --ca-file=harbor.ca.crt$ helm repo ls推送chart到仓库:
$ helm push harbor myharbor --ca-file=harbor.ca.crt -u admin -p Harbor12345查看harbor仓库的chart
课程小结
使用k8s的进阶内容。
-
学习k8s在etcd中数据的存储,掌握etcd的基本操作命令
-
理解k8s调度的过程,预选及优先。影响调度策略的设置
[外链图片转存中…(img-HjTvzMta-1709693311876)]
-
Flannel网络的原理学习,了解网络的流向,帮助定位问题
[外链图片转存中…(img-xPClWJAo-1709693311876)]
-
认证与授权,掌握kubectl、kubelet、rbac及二次开发如何调度API
[外链图片转存中…(img-maC5Cvvb-1709693311877)]
-
利用HPA进行业务动态扩缩容,通过metrics-server了解整个k8s的监控体系
[外链图片转存中…(img-7OQ6Kabl-1709693311877)]
-
PV + PVC
[外链图片转存中…(img-8izcWT5n-1709693311877)]
-
Helm
[外链图片转存中…(img-DSVSySAe-1709693311878)]





![[数据集][图像分类]苹果叶子病害分类数据集9714张4类别](http://pic.xiahunao.cn/[数据集][图像分类]苹果叶子病害分类数据集9714张4类别)

ALGO-985 幸运的店家)






)


)
)
