Gemma
日期: March 5, 2024
平台: CSDN, 知乎
状态: Writing
Gemma: Open Models Based on Gemini Research and Technology
谷歌最近放出的Gemma模型【模型名字来源于拉丁文gemma,意为宝石】采用的是与先前Gemini相同的架构。这次谷歌开源了两个规模的模型,分别是2B和7B的版本。【对于个人电脑来说,2B真的要容易运行的多】。在18个基于文本的任务上,有11项胜过其他开源的模型
谷歌在开源社区领域真的做出了巨大的贡献🌼,Transformers, TensorFlow, BERT, T5, JAX, AlphaFold, 以及AlphaCode。每一项对人工智能的发展都起到了推波助澜的作用。
引言
We trained Gemma models on up to 6T tokens of text, using similar architectures, data, and training recipes as the Gemini model family.
分别发布了pre-trained和fine-tuned的checkpoints。
模型架构
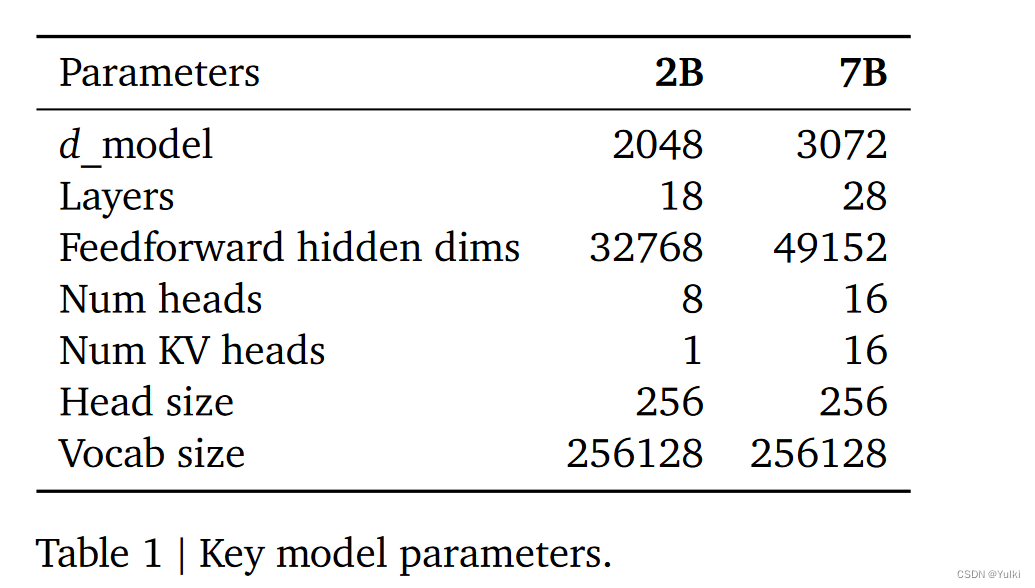
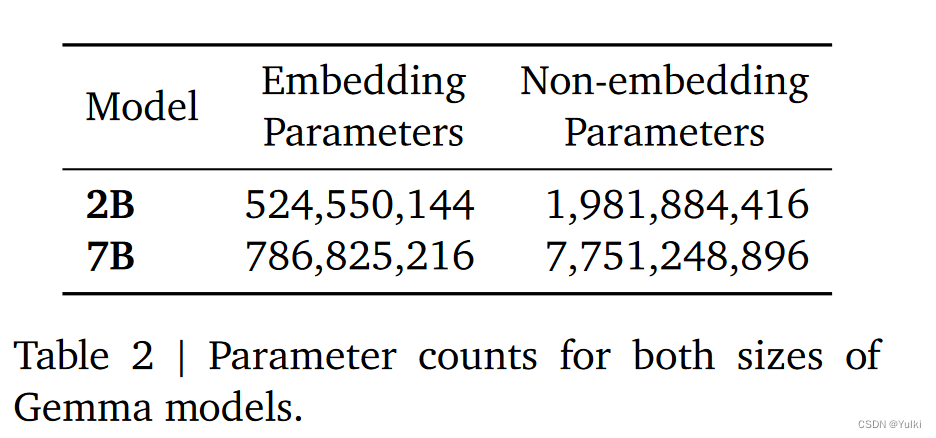
其实通过上面第一张表格就大体就可以计算第二张表格的参数具体是怎么来的
model.layers.0.self_attn.q_proj.weight torch.Size([2048, 2048]) = 4,194,304
model.layers.0.self_attn.k_proj.weight torch.Size([256, 2048]) = 524,288
model.layers.0.self_attn.v_proj.weight torch.Size([256, 2048]) = 524,288
model.layers.0.self_attn.o_proj.weight torch.Size([2048, 2048]) = = 4,194,304
model.layers.0.mlp.gate_proj.weight torch.Size([16384, 2048]) = 33,554,432
model.layers.0.mlp.up_proj.weight torch.Size([16384, 2048]) = 33,554,432
model.layers.0.mlp.down_proj.weight torch.Size([2048, 16384]) = 33,554,432
model.layers.0.input_layernorm.weight torch.Size([2048]) = 2048
model.layers.0.post_attention_layernorm.weight torch.Size([2048]) = 2048
…
model.norm.weight torch.Size([2048])
(4,194,3042+524,2882+33,554,4323+20482)*18+2048=1,981,884,416
下面四种技术,有机会会出单独的文章进行讲解
Multi-Query Attention
对于7B 模型使用的是multi-head attention【transformer中原始的】
对于2B模型则是使用的multi-query attention (with 𝑛𝑢𝑚_𝑘𝑣_ℎ𝑒𝑎𝑑𝑠 = 1)
RoPE Embeddings
位置编码使用的RoPE位置编码,在每一层中使用旋转位置嵌入
GeGLU Activation
标准 ReLU 非线性被 GeGLU 激活函数取代。
Normalizer Location
对输入输出都是用RMSNorm 标准化
模型训练基础设施
用的全是谷歌自己的TPU,说结论吧,训练7B的Gemma用了4096个TPUv5e,训练
B模型用了512个TPUv5e
预训练
训练数据
Gemma 2B 和 7B 分别针对来自网络文档、数学和代码的主要英语数据的 2T 和 6T 标记进行训练。并没有对语言进行优化!!!!
Instruction Tuning
Formatting
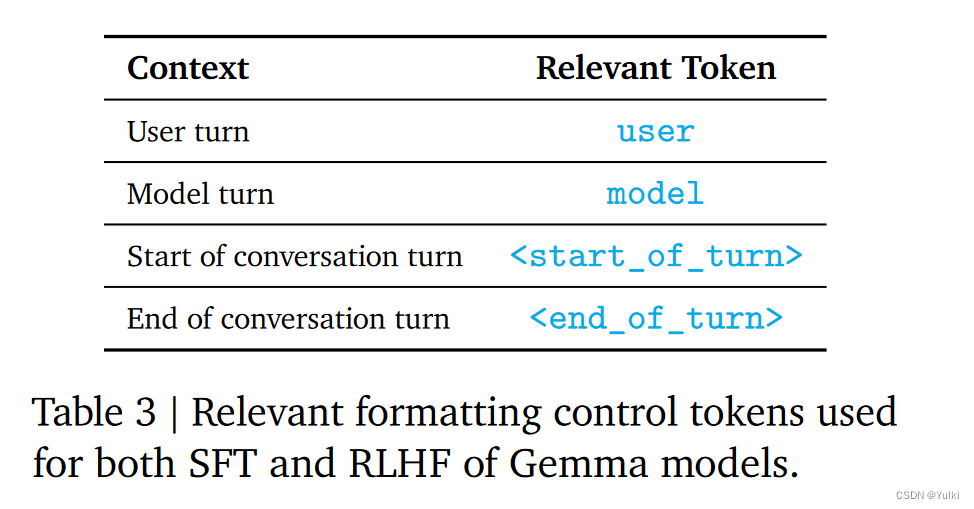
结果
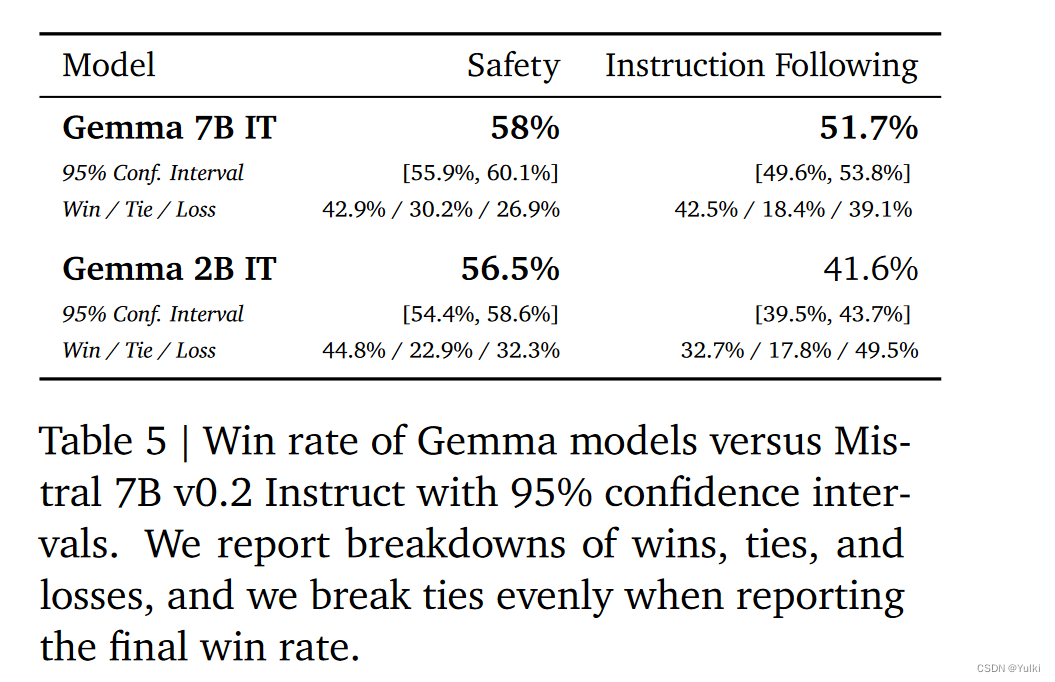
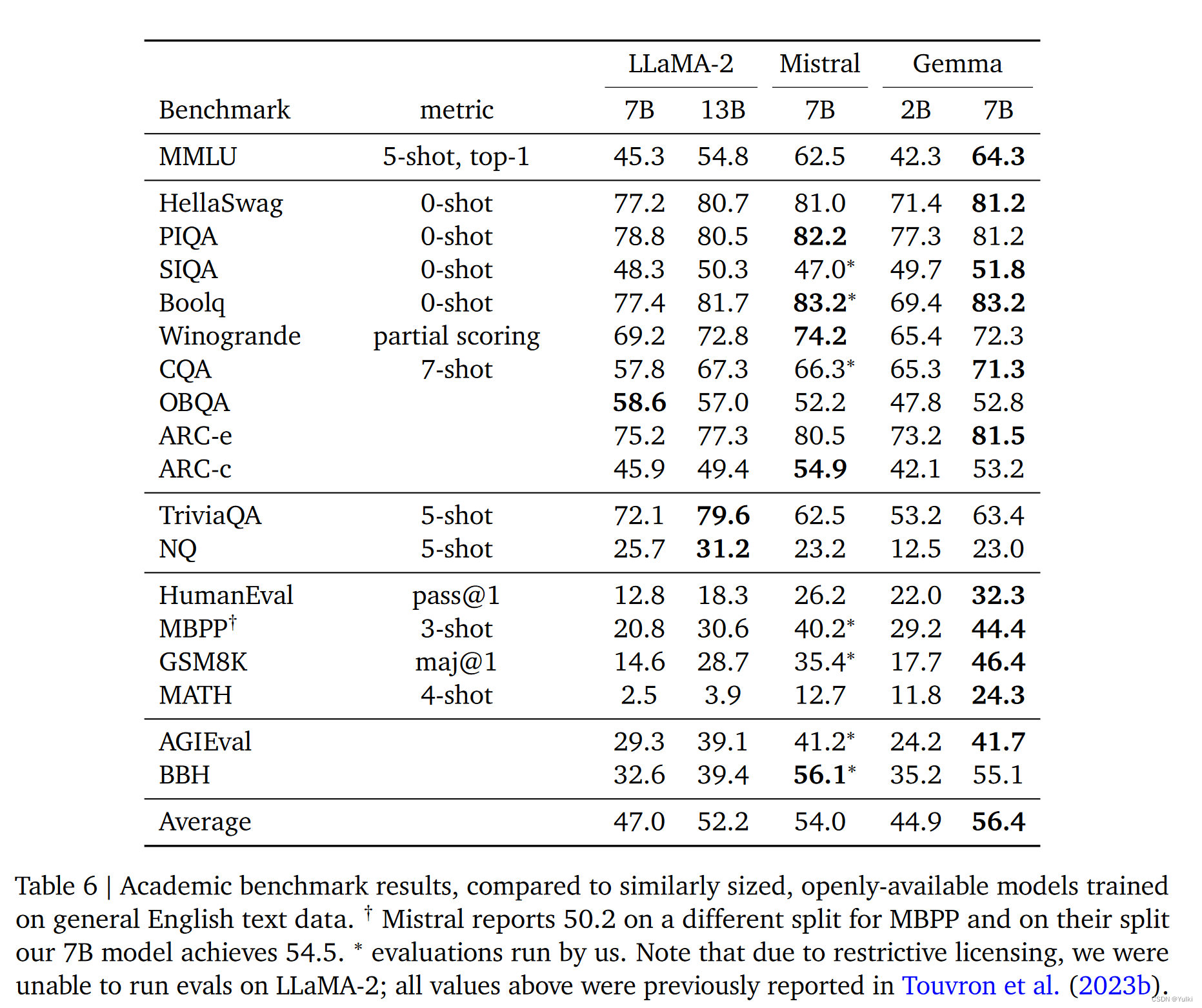
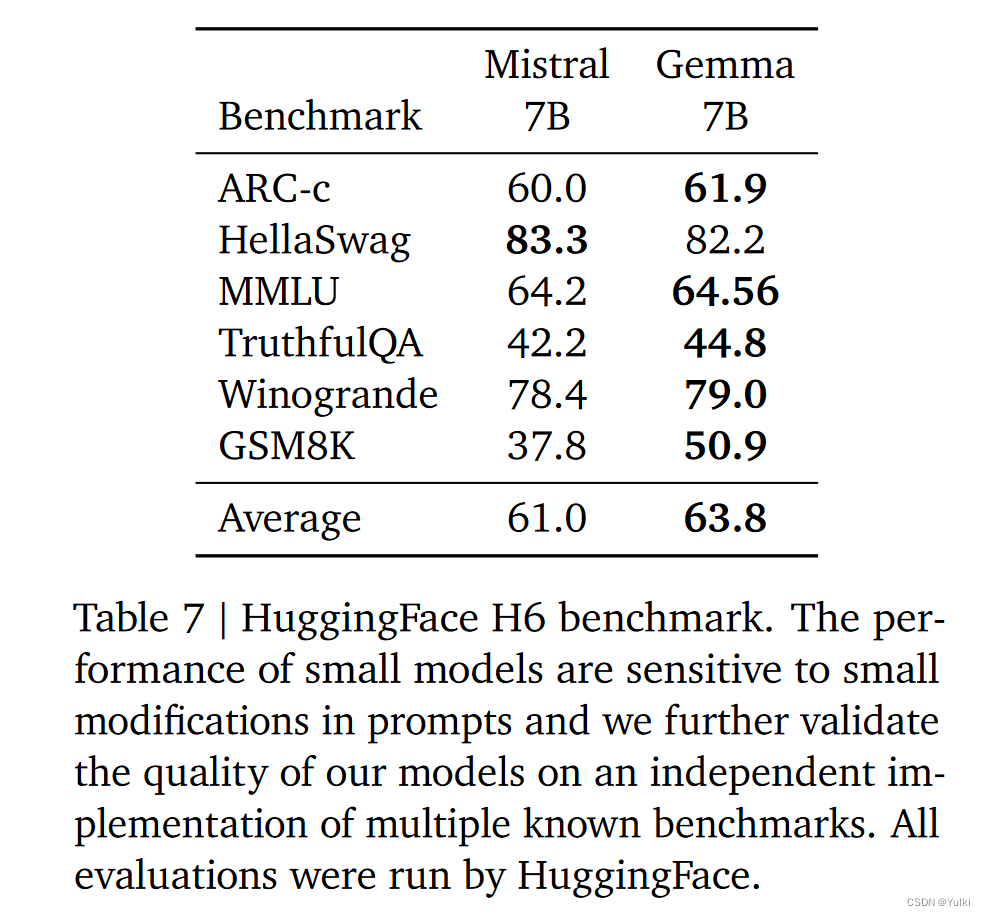
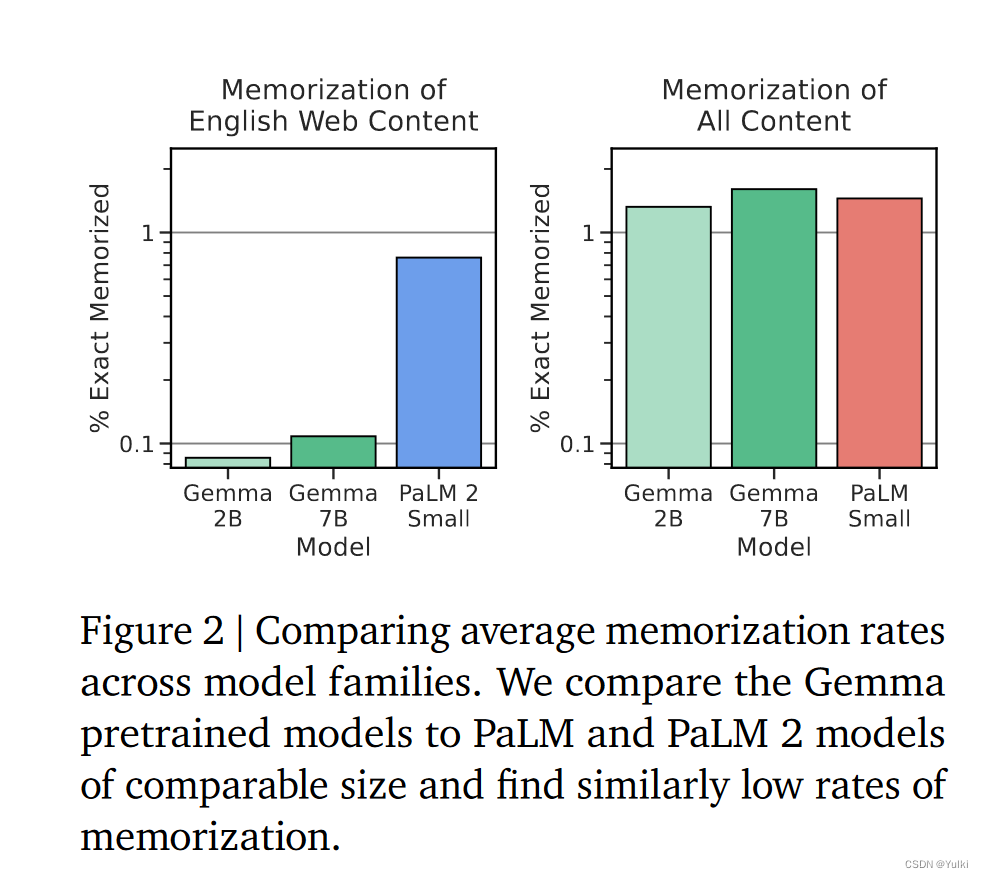
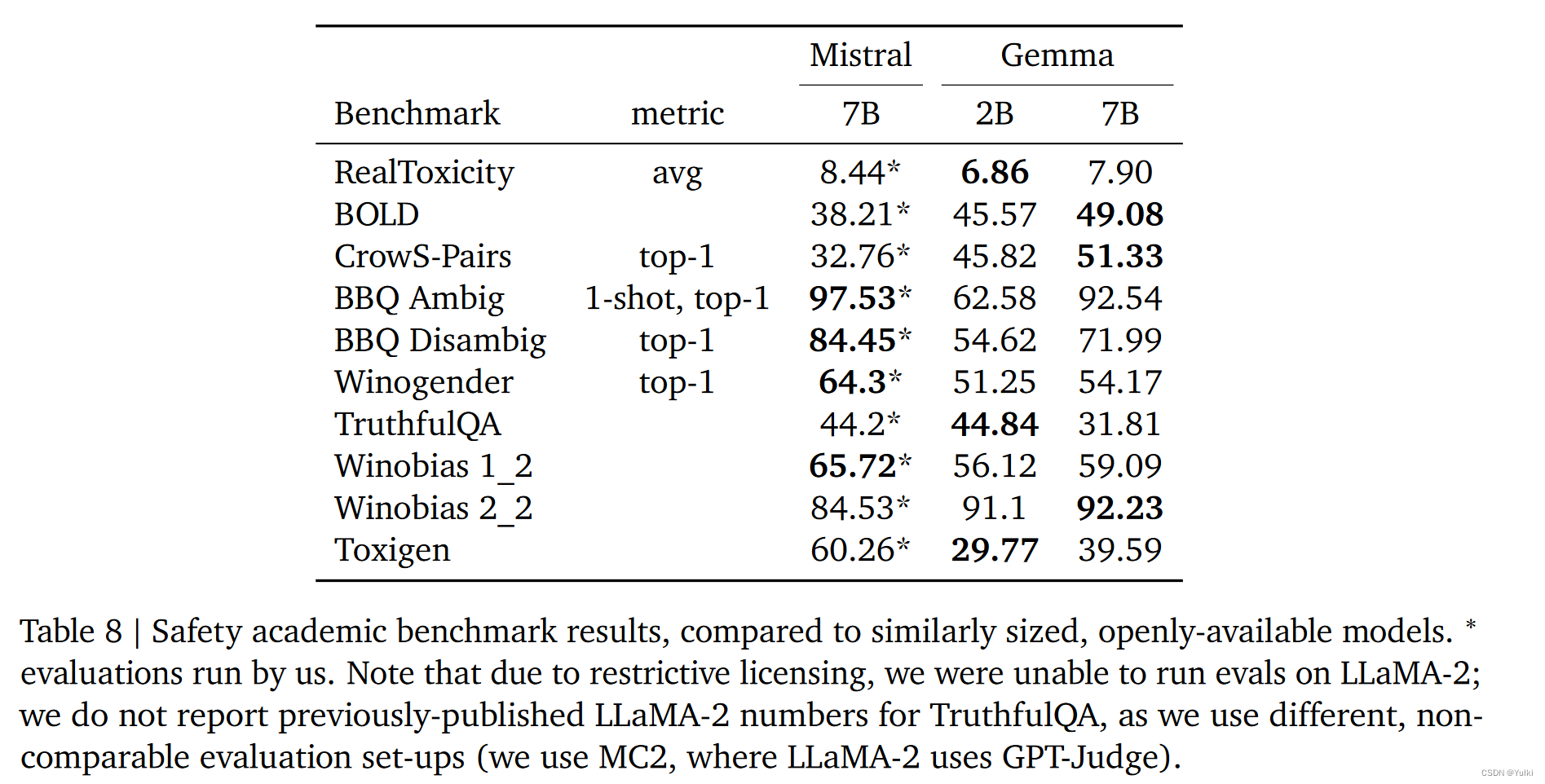




)


)




)






