业务数据_增量表数据同步
- 1)Flume配置概述
- 2)Flume配置实操
- 3)通道测试
- 4)编写Flume启停脚本
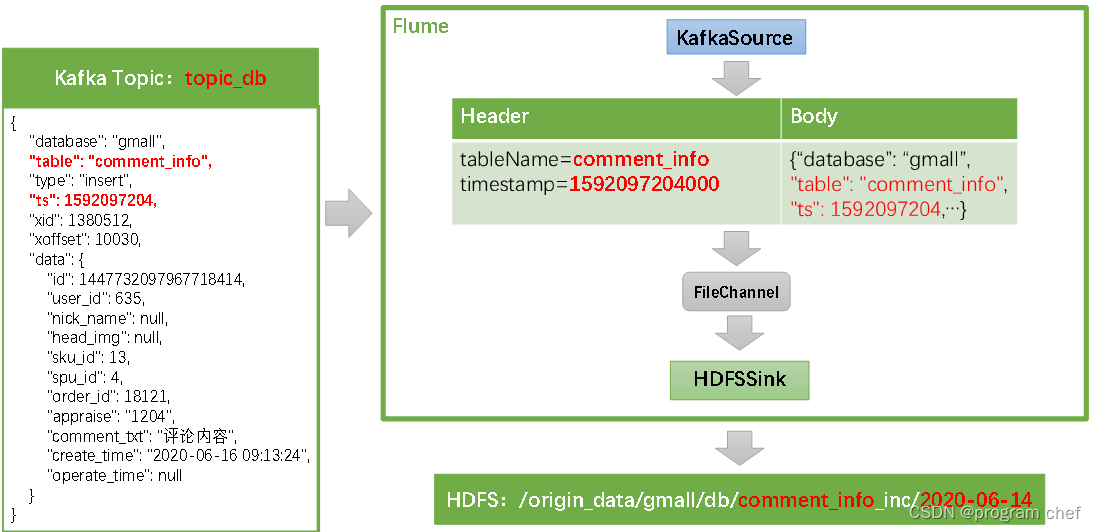
1)Flume配置概述
Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSink,Channel选用FileChannel。
需要注意的是, HDFSSink需要将不同mysql业务表的数据写到不同的路径,并且路径中应当包含一层日期,用于区分每天的数据。关键配置如下:
2)Flume配置实操
(1)创建Flume配置文件
在hadoop104节点的Flume的job目录下创建kafka_to_hdfs_db.conf
[atguigu@hadoop104 flume]$ mkdir job
[atguigu@hadoop104 flume]$ vim job/kafka_to_hdfs_db.conf
(2)配置文件内容如下
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampAndTableNameInterceptor$Buildera1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1(3)编写Flume拦截器
新建一个Maven项目,并在pom.xml文件中加入如下配置
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency>
</dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>在com.atguigu.gmall.flume.interceptor包下创建TimestampAndTableNameInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class TimestampAndTableNameInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);JSONObject jsonObject = JSONObject.parseObject(log);Long ts = jsonObject.getLong("ts");//Maxwell输出的数据中的ts字段时间戳单位为秒,Flume HDFSSink要求单位为毫秒String timeMills = String.valueOf(ts * 1000);String tableName = jsonObject.getString("table");headers.put("timestamp", timeMills);headers.put("tableName", tableName);return event;}@Overridepublic List<Event> intercept(List<Event> events) {for (Event event : events) {intercept(event);}return events;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new TimestampAndTableNameInterceptor ();}@Overridepublic void configure(Context context) {}}
}重新打包
将打好的包放入到hadoop104的/opt/module/flume/lib文件夹下
[atguigu@hadoop102 lib]$ ls | grep interceptor
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar3)通道测试
(1)启动Zookeeper、Kafka集群
(2)启动hadoop104的Flume
[atguigu@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_db.conf -Dflume.root.logger=info,console
(3)生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
(4)观察HDFS上的目标路径是否有数据出现
若HDFS上的目标路径已有增量表的数据出现了,就证明数据通道已经打通。
(5)数据目标路径的日期说明
仔细观察,会发现目标路径中的日期,并非模拟数据的业务日期,而是当前日期。这是由于Maxwell输出的JSON字符串中的ts字段的值,是数据的变动日期。而真实场景下,数据的业务日期与变动日期应当是一致的。4)编写Flume启停脚本
为方便使用,此处编写一个Flume的启停脚本
(1)在hadoop102节点的/home/atguigu/bin目录下创建脚本f3.sh
[atguigu@hadoop102 bin]$ vim f3.sh在脚本中填写如下内容
#!/bin/bashcase $1 in
"start")echo " --------启动 hadoop104 业务数据flume-------"ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")echo " --------停止 hadoop104 业务数据flume-------"ssh hadoop104 "ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f3.sh
(3)f3启动
[atguigu@hadoop102 module]$ f3.sh start
(4)f3停止
[atguigu@hadoop102 module]$ f3.sh stop2.2.6.3 Maxwell配置
1)Maxwell时间戳问题此处为了模拟真实环境,对Maxwell源码进行了改动,增加了一个参数mock_date,该参数的作用就是指定Maxwell输出JSON字符串的ts时间戳的日期,接下来进行测试。
修改Maxwell配置文件config.properties,增加mock_date参数,如下
log_level=infoproducer=kafka
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092#kafka topic配置
kafka_topic=topic_db#注:该参数仅在maxwell教学版中存在,修改该参数后重启Maxwell才可生效
mock_date=2020-06-14# mysql login info
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
注:该参数仅供学习使用,修改该参数后重启Maxwell才可生效。
重启Maxwell
[atguigu@hadoop102 bin]$ mxw.sh restart
重新生成模拟数据
[atguigu@hadoop102 bin]$ cd /opt/module/db_log/
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-11-14.jar
观察HDFS目标路径日期是否正常2.2.6.4 增量表首日全量同步
通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起见,下面编写一个增量表首日全量同步脚本。
1)在~/bin目录创建mysql_to_kafka_inc_init.sh
[atguigu@hadoop102 bin]$ vim mysql_to_kafka_inc_init.sh
脚本内容如下
#!/bin/bash# 该脚本的作用是初始化所有的增量表,只需执行一次MAXWELL_HOME=/opt/module/maxwellimport_data() {$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}case $1 in
"cart_info")import_data cart_info;;
"comment_info")import_data comment_info;;
"coupon_use")import_data coupon_use;;
"favor_info")import_data favor_info;;
"order_detail")import_data order_detail;;
"order_detail_activity")import_data order_detail_activity;;
"order_detail_coupon")import_data order_detail_coupon;;
"order_info")import_data order_info;;
"order_refund_info")import_data order_refund_info;;
"order_status_log")import_data order_status_log;;
"payment_info")import_data payment_info;;
"refund_payment")import_data refund_payment;;
"user_info")import_data user_info;;
"all")import_data cart_infoimport_data comment_infoimport_data coupon_useimport_data favor_infoimport_data order_detailimport_data order_detail_activityimport_data order_detail_couponimport_data order_infoimport_data order_refund_infoimport_data order_status_logimport_data payment_infoimport_data refund_paymentimport_data user_info;;
esac
2)为mysql_to_kafka_inc_init.sh增加执行权限
[atguigu@hadoop102 bin]$ chmod 777 ~/bin/mysql_to_kafka_inc_init.sh3)测试同步脚本
(1)清理历史数据
为方便查看结果,现将HDFS上之前同步的增量表数据删除
[atguigu@hadoop102 ~]$ hadoop fs -ls /origin_data/gmall/db | grep _inc | awk '{print KaTeX parse error: Expected 'EOF', got '}' at position 2: 8}̲' | xargs hadoo… mysql_to_kafka_inc_init.sh all
4)检查同步结果
观察HDFS上是否重新出现增量表数据。
2.3 采集通道启动/停止脚本
1)在/home/atguigu/bin目录下创建脚本cluster.sh
[atguigu@hadoop102 bin]$ vim cluster.sh在脚本中填写如下内容
#!/bin/bashcase $1 in
"start"){echo ================== 启动 集群 ==================#启动 Zookeeper集群zk.sh start#启动 Hadoop集群hdp.sh start#启动 Kafka采集集群kf.sh start#启动采集 Flumef1.sh start#启动日志消费 Flumef2.sh start#启动业务消费 Flumef3.sh start#启动 maxwellmxw.sh start};;
"stop"){echo ================== 停止 集群 ==================#停止 Maxwellmxw.sh stop#停止 业务消费Flumef3.sh stop#停止 日志消费Flumef2.sh stop#停止 日志采集Flumef1.sh stop#停止 Kafka采集集群kf.sh stop#停止 Hadoop集群hdp.sh stop#停止 Zookeeper集群zk.sh stop};;
esac2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 cluster.sh
3)cluster集群启动脚本
[atguigu@hadoop102 module]$ cluster.sh start
4)cluster集群停止脚本
[atguigu@hadoop102 module]$ cluster.sh stop











)







