目录
- 一. SVM的优越性
- 二. SVM算法推导
- 小节
- 概念
在开始讲述SVM算法之前,我们先来看一段定义:
'''
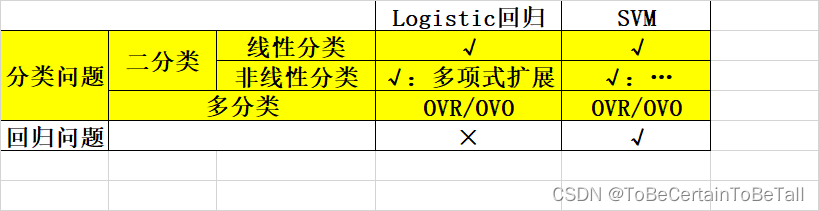
支持向量机(Support VecorMachine, SVM)本身是一个二元分类算法,支持线性分类和非线性分类的分类应用,同时通过OvR或者OvO的方式可以应用在多元分类领域中能够直接将SVM应用于回归应用中
在不考虑集成学习算法或者特定的数据集时,SVM在分类算法中可以说是一种特别优秀的算法
'''
一. SVM的优越性
在Logistic回归算法中:
我们追求是寻找一条决策边界,即找到一条能够正确划分所有训练样本的边界;
当所有样本正确划分时,损失函数已降至最低,模型不再优化
在SVM算法中:
我们追求是寻找一条最优决策边界
那什么是最优呢?SVM提出的基本思想是,寻找一条决策边界,使得该边界到两边最近的点间隔最大这样做得目的在于:相比于其他边界,svm寻找到的边界对于样本的局部扰动容忍性最好,对新进样本更容易判断正确;也就是说,此时决策边界具有最好的鲁棒性

二. SVM算法推导
注意:下面讲述的是线性分类
这里我们换一种思路寻找最佳决策边界:
首先假设决策边界为
y = ω → ⋅ x → + b y= \overrightarrow{\omega }\cdot \overrightarrow{x} +b y=ω⋅x+b
公式解释1:
为什么要这么设方程呢?我们希望通过向量点乘来确定距离
换句话说,希望通过向量点乘来确定正负样本的边界
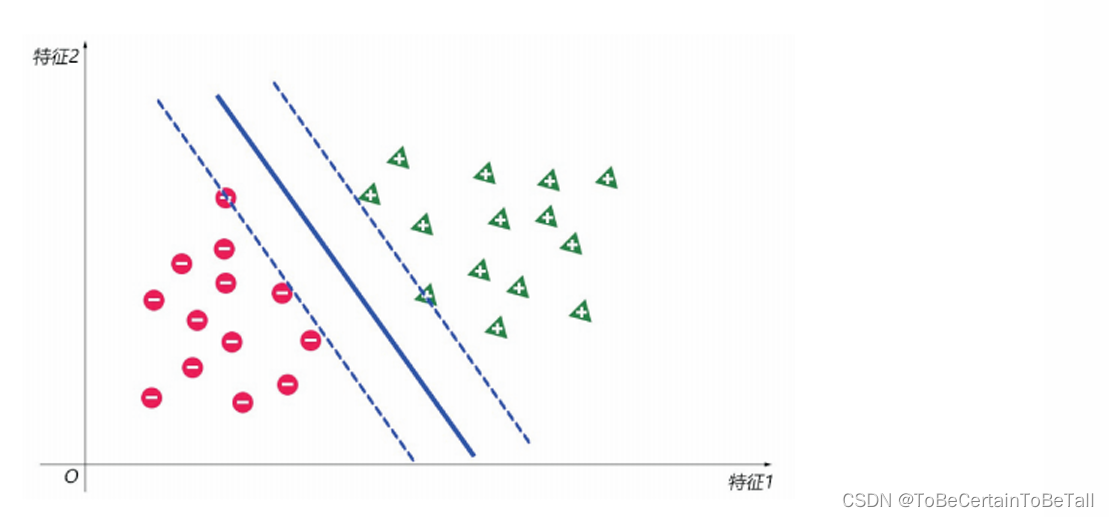
为了寻找最佳决策边界,我们可以:
以上述决策边界为中心线,向两边做平行线,让这两条平行线过两边最近的样本点;此时会形成一条“街道”,最佳决策边界就是使这条街道最宽的那个决策边界。
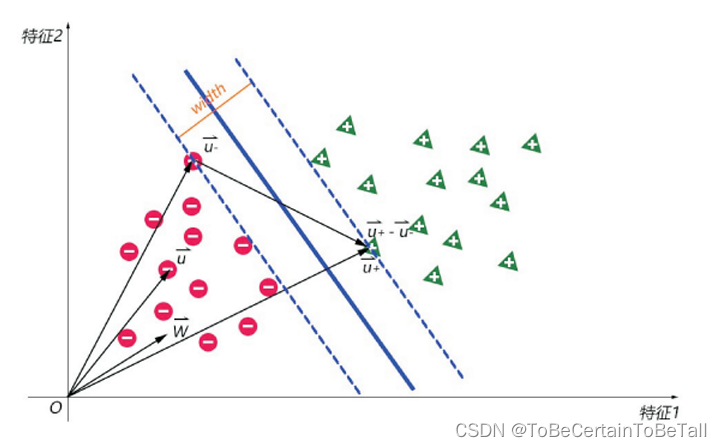
补充一点:
在Logistic回归算法中,我们人为的将数据集设为1,0
在SVM算法中,我们人为的将数据集设为1,-1
参数说明:width:街宽
ω → \overrightarrow{\omega } ω:决策边界的法向量
u − → \overrightarrow{u_{-} } u−:街边上的负样本向量
u + → \overrightarrow{u_{+} } u+:街边上的正样本向量
单位向量: a → ∥ a ∥ \frac{\overrightarrow{a}}{\left \| a \right \| } ∥a∥a向量点乘几何的意义:
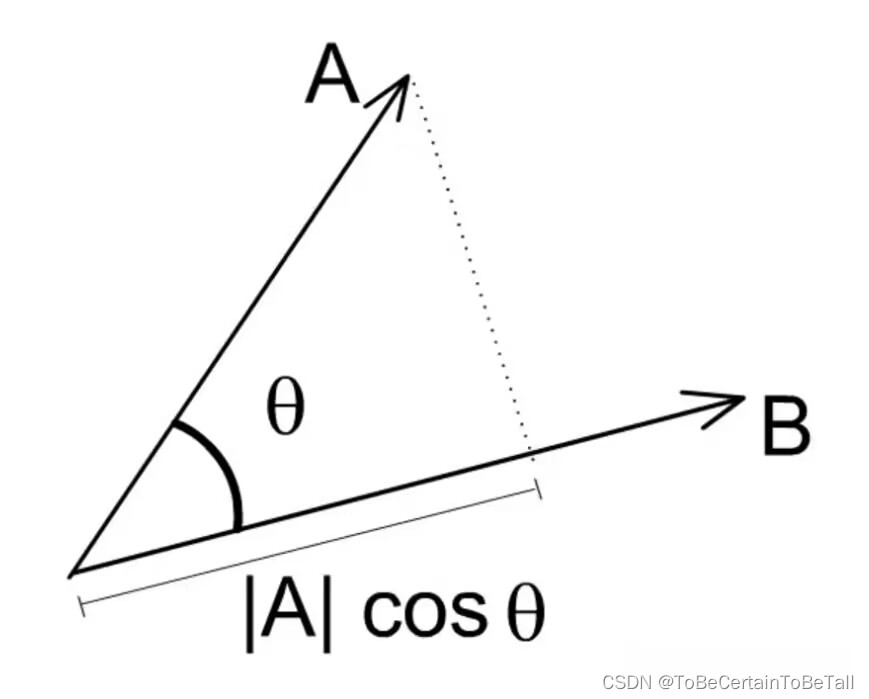
a → ⋅ b → = ∣ a → ∣ ∣ b → ∣ cos θ \overrightarrow{a}\cdot \overrightarrow{b} =\left | \overrightarrow{a} \right| |\overrightarrow{b} | \cos \theta a⋅b= a ∣b∣cosθ
可以理解为 a → \overrightarrow{a} a 在 b → \overrightarrow{b} b上的投影长度乘以 ∣ b → ∣ |\overrightarrow{b}| ∣b∣的模长
对于训练集中的任何一个数据,我们总会取到一个合适长度的 ω → \overrightarrow{\omega } ω,以及一个适合的常数b,得到:
{ ω → ⋅ u + → + b ≥ 1 ω → ⋅ u − → + b ≤ − 1 \left\{\begin{matrix}\overrightarrow{\omega }\cdot \overrightarrow{u_{+} } +b\ge 1 \\\overrightarrow{\omega }\cdot \overrightarrow{u_{-} } +b\le -1 \end{matrix}\right. {ω⋅u++b≥1ω⋅u−+b≤−1
即可以合并为: y i ( ω → ⋅ u i → + b ) ≥ 1 y_{i} (\overrightarrow{\omega }\cdot \overrightarrow{u_{i} } +b)\ge1 yi(ω⋅ui+b)≥1
而对于街边点而言,满足
y i ( ω → ⋅ u i → + b ) = 1 y_{i} (\overrightarrow{\omega }\cdot \overrightarrow{u_{i} } +b)=1 yi(ω⋅ui+b)=1
注意:这些街边点对于决定决策边界取决定性作用,因此被称为支持向量
这样,我们就可以用数学方式将上述街宽抽象出来:
w i d t h = ( u + → − u − → ) ⋅ w → ∥ w ∥ width = (\overrightarrow{u_{+}}-\overrightarrow{u_{-}} )\cdot \frac{\overrightarrow{w}}{\left \| w \right \| } width=(u+−u−)⋅∥w∥w
推导式子,就可以进一步得到:
w i d t h = ( u + → − u − → ) ⋅ w → ∥ w ∥ width = (\overrightarrow{u_{+}}-\overrightarrow{u_{-}} )\cdot \frac{\overrightarrow{w}}{\left \| w \right \| } width=(u+−u−)⋅∥w∥w
= u + → ⋅ ω → ∥ ω → ∥ − u − → ⋅ ω → ∥ ω → ∥ =\frac{\overrightarrow{u_{+}}\cdot\overrightarrow{\omega _{}} }{\left \| \overrightarrow{\omega\mathrm{} } \right \| }-\frac{\overrightarrow{u_{-}}\cdot\overrightarrow{\omega _{}} }{\left \| \overrightarrow{\omega\mathrm{} } \right \| } =∥ω∥u+⋅ω−∥ω∥u−⋅ω
= 1 − b ∥ w → ∥ − − 1 − b ∥ w → ∥ =\frac{1-b}{\left \| \overrightarrow{w} \right \| } -\frac{-1-b}{\left \| \overrightarrow{w} \right \| } =∥w∥1−b−∥w∥−1−b
= 2 ∥ w → ∥ =\frac{2}{\left \| \overrightarrow{w} \right \| } =∥w∥2
此时,我们要求街宽最大,即是求 m i n ( ∥ w → ∥ ) min({\left \| \overrightarrow{w} \right \| }) min( w ),这里为了后续求导方便,将值写成 m i n ( 1 2 ∥ w → ∥ 2 ) min(\frac{1}{2}\left \| \overrightarrow{w} \right \| ^{2} ) min(21 w 2)
需要明确,"街边"最大值的条件是基于支持向量的,而支持向量是属于数据集的,因此我们的问题就变成了:
{ m i n ( 1 2 ∥ w → ∥ 2 ) s . t . y i ( ω → ⋅ x → + b ) − 1 ≥ 0 \left\{\begin{matrix}min(\frac{1}{2}\left \| \overrightarrow{w} \right \| ^{2} ) \\s.t. y_{i} (\overrightarrow{\omega }\cdot \overrightarrow{x } +b)-1\ge0 \end{matrix}\right. {min(21 w 2)s.t.yi(ω⋅x+b)−1≥0
这是一个典型的条件极值问题,我们用拉格朗日乘数法,得到拉格朗日函数为:
L = 1 2 ∥ w → ∥ 2 − ∑ i = 1 m β i [ y i ( ω → ⋅ x → + b ) − 1 ] , ( β i ≥ 0 ) L = \frac{1}{2}\left \| \overrightarrow{w} \right \| ^{2} -\sum_{i=1}^{m} \beta _{i}[ y_{i} (\overrightarrow{\omega }\cdot \overrightarrow{x } +b)-1] ,(\beta _{i}\ge 0) L=21 w 2−i=1∑mβi[yi(ω⋅x+b)−1],(βi≥0)
这里的约束是不等式约束,所以要使用KKT条件(KKT是拉格朗日乘数法的一种泛化形式,此时 β i ≥ 0 \beta _{i}\ge0 βi≥0),而KKT条件的计算方式为: max β ≥ 0 min w , b L ( w , b , β ) \max_{\beta \ge 0} \min_{w,b}L(w,b,\beta ) β≥0maxw,bminL(w,b,β)
∂ L ∂ w = w − ∑ i = 1 m β i x ( i ) y ( i ) = 0 ⇒ w = ∑ i = 1 m β i x ( i ) y ( i ) \frac{\partial L}{\partial w} =w-\sum_{i=1}^{m} \beta _{i} x^{(i)}y^{(i)}=0\Rightarrow w=\sum_{i=1}^{m} \beta _{i} x^{(i)}y^{(i)} ∂w∂L=w−i=1∑mβix(i)y(i)=0⇒w=i=1∑mβix(i)y(i)
∂ L ∂ b = − ∑ i = 1 m β i y ( i ) = 0 ⇒ 0 = ∑ i = 1 m β i y ( i ) \frac{\partial L}{\partial b} =-\sum_{i=1}^{m} \beta _{i}y^{(i)}=0\Rightarrow 0=\sum_{i=1}^{m} \beta _{i} y^{(i)} ∂b∂L=−i=1∑mβiy(i)=0⇒0=i=1∑mβiy(i)
公式解释:
β \beta β是每个样本对应的拉格朗日乘子对于非支持向量而言, β = 0 \beta=0 β=0,即对非支持向量无约束
则: y ( i ) ∗ 0 = 0 y^{(i)}*0=0 y(i)∗0=0
对于支持向量而言, β > 0 \beta>0 β>0,即对支持向量有约束
则: 正样本支持向量 ∗ 1 + 负样本支持向量 ∗ ( − 1 ) = 0 正样本支持向量\ast 1+负样本支持向量\ast (-1)=0 正样本支持向量∗1+负样本支持向量∗(−1)=0
此时 L ( β ) L(\beta) L(β)为:
L ( β ) = 1 2 ∥ w → ∥ 2 − ∑ i = 1 m β i [ y ( i ) ( ω T ⋅ x ( i ) + b ) − 1 ] L(\beta)=\frac{1}{2}\left \| \overrightarrow{w} \right \| ^{2} -\sum_{i=1}^{m} \beta _{i}[y^{(i)} (\omega ^{T} \cdot x^{(i)} +b)-1] L(β)=21 w 2−∑i=1mβi[y(i)(ωT⋅x(i)+b)−1]
= 1 2 ω T ω − ∑ i = 1 m β i y ( i ) ω T ⋅ x ( i ) − b ∑ i = 1 m β i y ( i ) + ∑ i = 1 m β i =\frac{1}{2}\omega ^{T}\omega -\sum_{i=1}^{m} \beta _{i}y^{(i)}\omega ^{T} \cdot x^{(i)}-b\sum_{i=1}^{m} \beta _{i}y^{(i)}+\sum_{i=1}^{m} \beta _{i} =21ωTω−∑i=1mβiy(i)ωT⋅x(i)−b∑i=1mβiy(i)+∑i=1mβi
= 1 2 ω T ∑ i = 1 m β i x ( i ) y ( i ) − ∑ i = 1 m β i y ( i ) ω T x ( i ) + ∑ i = 1 m β i =\frac{1}{2}\omega ^{T}\sum_{i=1}^{m} \beta _{i} x^{(i)}y^{(i)} -\sum_{i=1}^{m} \beta _{i}y^{(i)}\omega ^{T}x^{(i)}+\sum_{i=1}^{m} \beta _{i} =21ωT∑i=1mβix(i)y(i)−∑i=1mβiy(i)ωTx(i)+∑i=1mβi
= − 1 2 ω T ∑ i = 1 m β i x ( i ) y ( i ) + ∑ i = 1 m β i =-\frac{1}{2}\omega ^{T}\sum_{i=1}^{m} \beta _{i} x^{(i)}y^{(i)} +\sum_{i=1}^{m} \beta _{i} =−21ωT∑i=1mβix(i)y(i)+∑i=1mβi
= − 1 2 ( ∑ j = 1 m β j x ( j ) y ( j ) ) T ( ∑ i = 1 m β i x ( i ) y ( i ) ) + ∑ i = 1 m β i =-\frac{1}{2}(\sum_{j=1}^{m} \beta _{j} x^{(j)}y^{(j)})^{T}(\sum_{i=1}^{m} \beta _{i} x^{(i)}y^{(i)} )+\sum_{i=1}^{m} \beta _{i} =−21(∑j=1mβjx(j)y(j))T(∑i=1mβix(i)y(i))+∑i=1mβi
= − 1 2 ∑ j = 1 m β j x ( j ) T y ( j ) ∑ i = 1 m β i x ( i ) y ( i ) + ∑ i = 1 m β i =-\frac{1}{2}\sum_{j=1}^{m} \beta _{j} x^{(j)^{T}}y^{(j)}\sum_{i=1}^{m} \beta _{i} x^{(i)}y^{(i)} +\sum_{i=1}^{m} \beta _{i} =−21∑j=1mβjx(j)Ty(j)∑i=1mβix(i)y(i)+∑i=1mβi
= ∑ i = 1 m β i − 1 2 ∑ i = 1 m ∑ j = 1 m β i β j y ( i ) y ( j ) x ( j ) T x ( i ) =\sum_{i=1}^{m} \beta _{i}-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m} \beta _{i}\beta _{j} y^{(i)}y^{(j)}x^{(j)^{T}} x^{(i)} =∑i=1mβi−21∑i=1m∑j=1mβiβjy(i)y(j)x(j)Tx(i)
即: { L ( β ) = ∑ i = 1 m β i − 1 2 ∑ i = 1 m ∑ j = 1 m β i β j y ( i ) y ( j ) x ( j ) T x ( i ) s . t : ∑ i = 1 m β i y ( i ) = 0 \left\{\begin{matrix}L(\beta)=\sum_{i=1}^{m} \beta _{i}-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m} \beta _{i}\beta _{j} y^{(i)}y^{(j)}x^{(j)^{T}} x^{(i)} \\s.t:\sum_{i=1}^{m} \beta _{i} y^{(i)}=0 \end{matrix}\right. {L(β)=∑i=1mβi−21∑i=1m∑j=1mβiβjy(i)y(j)x(j)Tx(i)s.t:∑i=1mβiy(i)=0
解到这一步,我们发现L函数只与 β \beta β有关,所以此时可以直接极大化我们的优化函数,且
max β ≥ 0 l ( β ) ⟶ min β ≥ 0 − l ( β ) \max_{\beta \ge 0}l(\beta ) \longrightarrow \min_{\beta \ge 0}-l(\beta ) β≥0maxl(β)⟶β≥0min−l(β)
因此,求解 β \beta β就变成了
{ min β ≥ 0 1 2 ∑ i = 1 m ∑ j = 1 m β i β j y ( i ) y ( j ) x ( j ) T x ( i ) − ∑ i = 1 m β i s . t : ∑ i = 1 m β i y ( i ) = 0 \left\{\begin{matrix}\min_{\beta \ge 0}\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m} \beta _{i}\beta _{j} y^{(i)}y^{(j)}x^{(j)^{T}} x^{(i)}-\sum_{i=1}^{m} \beta _{i} \\s.t:\sum_{i=1}^{m} \beta _{i} y^{(i)}=0 \end{matrix}\right. {minβ≥021∑i=1m∑j=1mβiβjy(i)y(j)x(j)Tx(i)−∑i=1mβis.t:∑i=1mβiy(i)=0
但是对于 β \beta β,可以使用SMO算法求得;对于SMO算法,我们先放一放
这里,假设我们用SMO求得了 β \beta β的最优解,那么我们可以分别计算得到对应的:
w = ∑ i = 1 m β i x ( i ) y ( i ) w=\sum_{i=1}^{m} \beta _{i} x^{(i)}y^{(i)} w=∑i=1mβix(i)y(i)
b:一般使用所有支持向量的计算均值作为实际值
怎么得到支持向量呢?
β = 0 \beta=0 β=0,该样本不是支持向量
β > 1 \beta>1 β>1,该样本是支持向量
小节
对于线性可分的m个样本(x1,y1),(x2,y2)… :
x为n维的特征向量y为二元输出,即+1,-1
SVM的输出为w,b,分类决策函数
通过构造约束问题:
{ min β ≥ 0 1 2 ∑ i = 1 m ∑ j = 1 m β i β j y ( i ) y ( j ) x ( j ) T x ( i ) − ∑ i = 1 m β i s . t : ∑ i = 1 m β i y ( i ) = 0 \left\{\begin{matrix}\min_{\beta \ge 0}\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m} \beta _{i}\beta _{j} y^{(i)}y^{(j)}x^{(j)^{T}} x^{(i)}-\sum_{i=1}^{m} \beta _{i} \\s.t:\sum_{i=1}^{m} \beta _{i} y^{(i)}=0 \end{matrix}\right. {minβ≥021∑i=1m∑j=1mβiβjy(i)y(j)x(j)Tx(i)−∑i=1mβis.t:∑i=1mβiy(i)=0
使用SMO算法求出上述最优解 β \beta β
找到所有支持向量集合:
S = ( x ( i ) , y ( i ) ) ( β > 0 , i = 1 , 2 , . . . , m ) S = (x^{(i)}, y^{(i)}) (\beta > 0,i=1,2,...,m) S=(x(i),y(i))(β>0,i=1,2,...,m)
从而更新w,b
w = ∑ i = 1 m β i x ( i ) y ( i ) w=\sum_{i=1}^{m} \beta _{i} x^{(i)}y^{(i)} w=∑i=1mβix(i)y(i)
b = 1 S ∑ i = 1 S ( y s − ∑ i = 1 m β i x ( i ) T y ( i ) x s ) b=\frac{1}{S} \sum_{i=1}^{S}(y^{s}- \sum_{i=1}^{m} \beta _{i} x^{(i)^{T}}y^{(i)}x^{s} ) b=S1∑i=1S(ys−∑i=1mβix(i)Ty(i)xs)
构造最终的分类器,为:
f ( x ) = s i g n ( w ∗ x + b ) f(x)=sign(w\ast x+b) f(x)=sign(w∗x+b)
x<0时,y=-1x=0时,y=0x>0时,y=1注意:假设,不会出现0若出现,正负样本随意输出一个,即+0.00000001或-0.00000001都可以
概念
最后,我们定义具体概念:
分割超平面(Separating Hyperplane):将数据集分割开来的直线、平面叫分割超平面
支持向量(Support Vector):离分割超平面最近的那些点叫做支持向量
间隔(Margin):支持向量数据点到分割超平面的距离称为间隔;任何一个支持向量到分割超平面的距离都是相等的
感谢阅读🌼
如果喜欢这篇文章,记得点赞👍和转发🔄哦!
有任何想法或问题,欢迎留言交流💬,我们下次见!
本文相关代码存放位置
祝愉快🌟!



2024.03.02:UCOSIII第四节:创建任务)
)



)








】双向循环带头链表的增删查改详解(天才设计的链表结构,应用简单逆天!!!!!))

