硬件配置
vCPU:32核
内存:188 GiB
宽带:5 Mbps
GPU:NVIDIA A10 24G
cuda 安装
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda-repo-rhel7-12-1-local-12.1.0_530.30.02-1.x86_64.rpm
sudo rpm -i cuda-repo-rhel7-12-1-local-12.1.0_530.30.02-1.x86_64.rpm
sudo yum clean all
sudo yum -y install nvidia-driver-latest-dkmssudo yum -y install cuda#cudnn
wget https://developer.download.nvidia.com/compute/cudnn/9.0.0/local_installers/cudnn-local-repo-rhel7-9.0.0-1.0-1.x86_64.rpm
sudo rpm -i cudnn-local-repo-rhel7-9.0.0-1.0-1.x86_64.rpm
sudo yum clean all
sudo yum -y install cudnnAnconda
chmod +xwr Anaconda3-2022.10-Linux-x86_64.sh
./Anaconda3-2022.10-Linux-x86_64.sh
Base: Python=3.9
torch
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidiaenv_test.py
import torch # 如果pytorch安装成功即可导入
print(torch.cuda.is_available()) # 查看CUDA是否可用
print(torch.cuda.device_count()) # 查看可用的CUDA数量
print(torch.version.cuda) # 查看CUDA的版本号包
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
pip install csrc/layer_norm
pip install csrc/rotary
pip install modelscope
问题:
1、subprocess.calledprocesserror: command '['which', 'g++']' returned non-zero exit status 1.
解决:
yum install make automake gcc gcc-c++ kernel-devel
yum group install "Development Tools" "Development Libraries"
2、RuntimeError: Error compiling objects for extension
解决:Pytroch和cuda不匹配,重新安装对应的cuda或者pytorch
3、nvidia-smi :Failed to initialize NVML: Driver/library version mismatch
解决:
yum remove nvidia-*
#重装cuda12.1
4、WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu.
内存不够: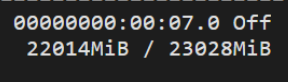
test:
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig# Note: The default behavior now has injection attack prevention off.
#trust_remote_code=True 表示你信任远程的预训练模型,愿意运行其中的代码
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-14B", trust_remote_code=True)# use bf16
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-14B", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-14B", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-14B", device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-14B", device_map="auto", trust_remote_code=True).eval()# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-14B", trust_remote_code=True)inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...

)

)








![[线代]自用大纲](http://pic.xiahunao.cn/[线代]自用大纲)

)



