第三部分高级shell脚本编程
第17章创建函数
17.1 脚本函数基础
17.1.1 创建函数
在bash shell 脚本中创建函数的语法有两种。第一种语法是使用关键字function,随后跟
上分配给该代码块的函数名:
function name {
commands
}
17.1.2 使用函数
要在脚本中使用函数,只需像其他shell 命令一样写出函数名即可
17.2 函数返回值
17.2.1 默认的退出状态码
在默认情况下,函数的退出状态码是函数中最后一个命令返回的退出状态码。函数执行结束
后,可以使用标准变量$?来确定函数的退出状态码。该函数的退出状态码是1,因为函数中的最后一个命令执行失败了。但你无法知道该函数中的其他命令是否执行成功。
17.2.2 使用return命令
使用return 命令以特定的退出状态码退出函数。return 命令允许指定一个整数值作为函数的退出状态码。当用这种方法从函数中返回值时,一定要小心。为了避免出问题,牢记以下两个技巧: 函数执行一结束就立刻读取返回值;退出状态码必须介于0~255
$ cat test5
#!/bin/bash
# using the return command in a function
function dbl {
read -p "Enter a value: " value
echo "doubling the value"
return $[ $value * 2 ]
}
dbl
echo "The new value is $?" #用$?变量显示出该结果
$ 17.2.3 使用函数输出
将dbl函数的输出保存到shell 变量中:result=$(dbl)
$ cat test5b
#!/bin/bash
# using the echo to return a value
function dbl {
read -p "Enter a value: " value
echo $[ $value * 2 ]
}
result=$(dbl)
echo "The new value is $result"
$17.3 在函数中使用变量
17.3.1 向函数传递参数
函数可以使用标准的位置变量来表示在命令行中传给函数的任何参数。例如,函数名保存在
$0 变量中,函数参数依次保存在$1、$2 等变量中。也可以用特殊变量$#来确定传给函数的参数
数量。
在脚本中调用函数时,必须将参数和函数名放在同一行
17.3.2 在函数中处理变量
1. 全局变量
全局变量是在shell 脚本内任何地方都有效的变量。
在默认情况下,在脚本中定义的任何变量都是全局变量。在函数外定义的变量可在函数内正
常访问
2. 局部变量
无须在函数中使用全局变量,任何在函数内部使用的变量都可以被声明为局部变量。为此,
只需在变量声明之前加上local 关键字即可
$ cat test9
#!/bin/bash
# demonstrating the local keyword
function func1 {
local temp=$[ $value + 5 ]
result=$[ $temp * 2 ]
}17.4 数组变量和函数
将数组变量作为函数参数进行传递,则函数只会提取数组变量的第一个元素,,必须先将数组变量拆解成多个数组元素,然后将这些数组元素作为函数参数传递。最后在函数内部,将所有的参数重新组合成一个新的数组变量。
17.4.1 向函数传递数组
$ cat test10
#!/bin/bash
# array variable to function test
function testit {
local newarray # 创建数组
newarray=(`echo "$@"`) #所有的参数重新组合成一个新的数组变量
echo "The new array value is: ${newarray[*]}"
}
myarray=(1 2 3 4 5)
echo "The original array is ${myarray[*]}"
testit ${myarray[*]}
$
$ ./test10
The original array is 1 2 3 4 5
The new array value is: 1 2 3 4 5
$17.4.2 从函数返回数组
函数先用echo 语句按正确顺序输出数组的各个元素,然后脚本再将数组元素重组成一个新的数组变量
$ cat test12
#!/bin/bash
# returning an array value
function arraydblr {
local origarray
local newarray
local elements
local i
origarray=($(echo "$@"))
newarray=($(echo "$@"))
elements=$[ $# - 1 ]
for (( i = 0; i <= $elements; i++ ))
{
newarray[$i]=$[ ${origarray[$i]} * 2 ]
}
echo ${newarray[*]}
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]}) # echo 语句重组成一个新的数组变量
result=($(arraydblr $arg1)) # 通过$arg1 变量将数组元素作为参数传给arraydblr 函数。
echo "The new array is: ${result[*]}"
$
$ ./test12
The original array is: 1 2 3 4 5
The new array is: 2 4 6 8 1017.5 函数递归
局部函数变量的一个特性是自成体系(self-containment)。除了获取函数参数,自成体系的
函数不需要使用任何外部资源。这个特性使得函数可以递归地调用,也就是说函数可以调用自己来得到结果。
17.6 创建库
bash shell 允许创建函数库文件,然后在多个脚本中引用此库文件。
在多个脚本中使用同一段代码
第一步是创建一个包含脚本中所需函数的公用库文件,例如:库文件myfuncs
第二步是在需要用到这些函数的脚本文件中包含myfuncs 库文件,用source 命令在脚本中运行库文
$ cat test14
#!/bin/bash
# using functions defined in a library file
. ./myfuncs # . ./ 使用这个来调用
value1=10
value2=5
result1=$(addem $value1 $value2)
result2=$(multem $value1 $value2)
result3=$(divem $value1 $value2)
echo "The result of adding them is: $result1"
echo "The result of multiplying them is: $result2"
echo "The result of dividing them is: $result3"
$
$ ./test14
The result of adding them is: 15
The result of multiplying them is: 50
The result of dividing them is: 2
$
source 命令有个别名,称作点号操作符。
17.7 在命令行中使用函数
17.7.1 在命令行中创建函数
1. 采用单行方式来定义函数
$ function divem { echo $[ $1 / $2 ]; }
$ divem 100 52.采用多行方式来定义函数
使用这种方法,无须在每条命令的末尾放置分号,只需按下回车键即可
$ function multem {
> echo $[ $1 * $2 ]
> }
$ multem 2 5
1017.7.2 在.bashrc文件中定义函数
1. 直接定义函数
可以直接在用户主目录的.bashrc 文件中定义函数,只需将函数放在文件末尾即可
2. 源引函数文件
只要是在shell 脚本中,就可以用source 命令(或者其别名,即点号操作符)将库文件中
的函数添加到.bashrc 脚本中
$ cat .bashrc
# .bashrc
# Source global definitions
if [ -r /etc/bashrc ]; then
. /etc/bashrc
fi
. /home/rich/libraries/myfuncs # 将库文件中的函数添加到.bashrc 脚本
$
第18章 图形化桌面环境中的脚本编程 #
第19章 初识sed和gawk
19.1文本处理
19.1.1 sed编辑器
sed 编辑器被称作流编辑器(stream editor)
sed 命令的格式如下:
sed options script file

1. 在命令行中定义编辑器命令
在默认情况下,sed 编辑器会将指定的命令应用于STDIN 输入流中。因此,可以直接将数据
通过管道传入sed 编辑器进行处理。
$ echo "This is a test" | sed 's/test/big test/'
This is a big test
$#接将数据通过管道传入sed 编辑器进行处理, 替换(s)命令,将big test 替换了test2. 在命令行中使用多个编辑器命令
如果要在sed 命令行中执行多个命令,可以使用-e 选项
$ sed -e 's/brown/red/; s/dog/cat/' data1.txt
The quick red fox jumps over the lazy cat.
The quick red fox jumps over the lazy cat.
The quick red fox jumps over the lazy cat.
The quick red fox jumps over the lazy cat.
$3. 从文件中读取编辑器命令
有大量要执行的sed 命令,那么将其放进单独的文件通常会更方便一些。可以在sed
命令中用-f 选项来指定文件:
$ cat script1.sed
s/brown/green/
s/fox/toad/
s/dog/cat/
$
$ sed -f script1.sed data1.txt
The quick green toad jumps over the lazy cat.
The quick green toad jumps over the lazy cat.
The quick green toad jumps over the lazy cat.
The quick green toad jumps over the lazy cat.
$19.1.2 gawk编辑器
虽然sed 编辑器非常方便,可以即时修改文本文件
19.2 sed编辑器基础命令 #
19.2.1 更多的替换选项 #
19.2.2 使用地址 #
19.2.3 删除行 #
19.2.4 插入和附加文本 #
19.2.5 修改行 #
19.2.6 转换命令 #
19.2.7 再探打印 #
19.2.8 使用sed处理文件 #
第20章 正则表达式
正则表达式是一种可供Linux 工具过滤文本的自定义模板
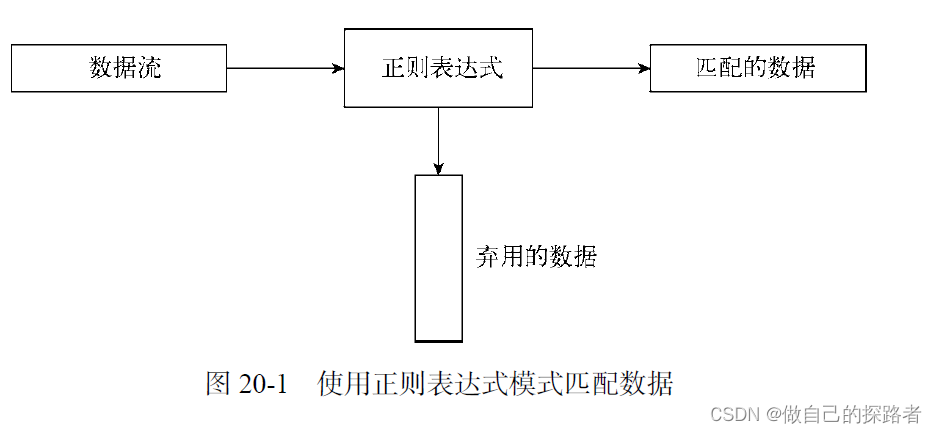
第21章 sed进阶 #
第22章 gawk进阶 #
第23章 使用其他shell
- dash shell
- zsh shell
第四部分 创建和管理实用的脚本
第24章 编写简单的脚本实用工具
第25章 井井有条
第24章 编写简单的脚本实用工具
24.1 备份
定时进行备份(也称作归档)
24.1.1 日常备份 #
24.1.2 创建按小时归档的脚本 #
24.2 删除账户
管理本地用户账户绝不仅仅是添加、修改和删除,还需考虑安全问题、保留工作的需求,以
及精确删除账户。
删除本地账户属于更复杂的账户管理任务,至少需要4 个步骤。
(1) 获取正确的待删除用户账户名。
(2)“杀死”系统中正在运行的属于该账户的进程。
(3) 确认系统中属于该账户的所有文件。
(4) 删除该用户账户。
24.3 系统监控
24.3.1 获得默认的shell审计功能
使用cut 命令获取/etc/passwd 文件中所有账户的默认shell。
$ cut -d: -f7 /etc/passwd
24.3.2 权限审计功能
SUID(set user ID)和SGID(set group ID)是两种很方便的权限设置
找出具有这两种权限的文件和目录,需要使用find 命令
$ sudo find / -perm /6000 2>/dev/null
第25章 井井有条
25.1 理解版本控制
25.1.1 工作目录
工作目录是所有脚本的创建、修改和审查之地。它通常是脚本编写者的主目录中的某个子目录,类似于/home/christine/scripts。最好为每个项目都创建一个新的子目录,因为Git 会在其中放
置文件,以便进行跟踪。
25.1.2 暂存区
暂存区也称为索引。该区域和工作目录位于同一系统。bash 脚本通过Git 命令(git add)
在暂存区内注册。通过git init 命令,暂存区在工作目录中设置了一个名为.git 的隐藏子目录。
25.1.3 本地仓库
本地仓库包括每个脚本文件的历史记录。它也会用到工作目录的.git 子目录。脚本文件的各
个版本(称为项目树)和提交信息之间的关系通过Git 命令(git commit),以对象的方式存储
在.git/objects/目录中。
项目树和提交数据合起来称为快照。每次提交数据都会创建一个新快照。不过,旧快照并不
会被删除,依然可以查看。如果需要,还可以返回到之前的快照,这是Git 另一个不错的特性。
25.1.4 远程仓库
在Git 配置中,远程仓库通常位于云端,提供代码托管服务。著名的远程仓库有GitHub、GitLab、BitBucket 和Launchpad。不过到目前为止,GitHub 最受欢迎
25.1.5 分支
Git 还提供了一个名为分支的特性,该特性可以在各种脚本项目中发挥作用。分支是本地仓
库中属于特定项目的一个区域。
25.1.6 克隆
Git 的另一个特性是复制项目。这个过程称为克隆。
注意 在Git 中,克隆(cloning)和 分叉(forking)是两种紧密相关的操作。使用git clone
命令将文件从远程仓库下载到本地系统,这一过程是克隆。将文件从一个远程仓库复制
到另一个远程仓库,这一过程是分叉。
25.1.7 使用Git作为VCS
好处
性能:Git只操作本地文件, 这提高了其部署速度。同远程仓库之间收发文件属于例外
情况。
历史文件:从文件被注册那一刻起, Git就开始使用索引来记录文件的内容。当对本地存
储库的提交完成时, Git会及时创建并存储对该快照的引用。
准确性:Git使用校验和来保护文件完整性。
去中心化:脚本编写者可以在同一个项目中工作,但不必位于同一网络或系统。
25.2 设置Git环境
安装好git 软件包之后,为新的脚本项目设置Git 环境涉及以下4 个基本步骤。
(1) 创建工作目录:
$ mkdir MWGuard$ cd MWGuard/
(2) 初始化.git/子目录
$ git init$ git remote add origin https://github.com/C-Bresnahan/MWGuard.git
$
$ git remote -v
origin https://github.com/C-Bresnahan/MWGuard.git (fetch)
origin https://github.com/C-Bresnahan/MWGuard.git (push)
$
(3) 设置本地仓库选项
#,则需将姓名和email 地址添加到Git 的全局仓库配置文件中
$ git config --global user.name "Christine Bresnahan"
$ git config --global user.email "cbresn1723@gmail.com"
(4) 确定远程仓库位置
建立好项目的远程仓库之后,需要把仓库地址记下来。随后向远程仓库发送项目文件时,要
用到这个地址。
可以使用git remote add origin URL 命令来添加地址,其中URL 就是远程仓库地址:
$ git remote add origin https://github.com/C-Bresnahan/MWGuard.git
$
$ git remote -v
origin https://github.com/C-Bresnahan/MWGuard.git (fetch)
origin https://github.com/C-Bresnahan/MWGuard.git (push)
$)






12.5-Dem)


 prepare 阶段)





)
)

