采用分类任务的指标评估生成任务的问题
举个例子,在一个seq2seq模型中,黄金标签是“police killed the gunman”,模型输出是"the gunman police killed",两句话的意思是有差别的,但是从unigram的角度,它们都包含了"The", "police", "killed", "gunman",是完全相同的。
以常用的分类指标precision, recall, f1为例。precision = TP/(TP+FP), recall = TP/(TP+FN)。
在上面情境中,模型预测出"the" "gunman" "killed" "police"四个unigram,还都预测对了,因为它们在黄金标签“police killed the gunman”中也出现了,因此TP=4, 因为没有预测错误的unigram,FP=0,precision =1。
同理,对recall而言,TP=4,因为黄金标签中的4个unigram,全都被模型预测出来了,没有漏网之鱼,因此FN=0,即没有那些本来为阳性,却预测为阴性的unigram。因此recall为1.
因此F1 = TP/(TP+FN)=1,从分类的角度看,模型的预测是非常成功的。

但是我们一眼就看出,模型生成的结果改变了黄金标签的意思。这时候怎么去衡量模型生成结果的质量呢。
rouge-1

首先介绍rouge-1,这个1指的就是连续的一个单词。上图中绿色的是机器生成的,黄色的是人类给的标注,从单个连续单词的角度,一共有六个匹配的单词,按照图中给出的公式计算,即可算出rouge-1。
rouge-2
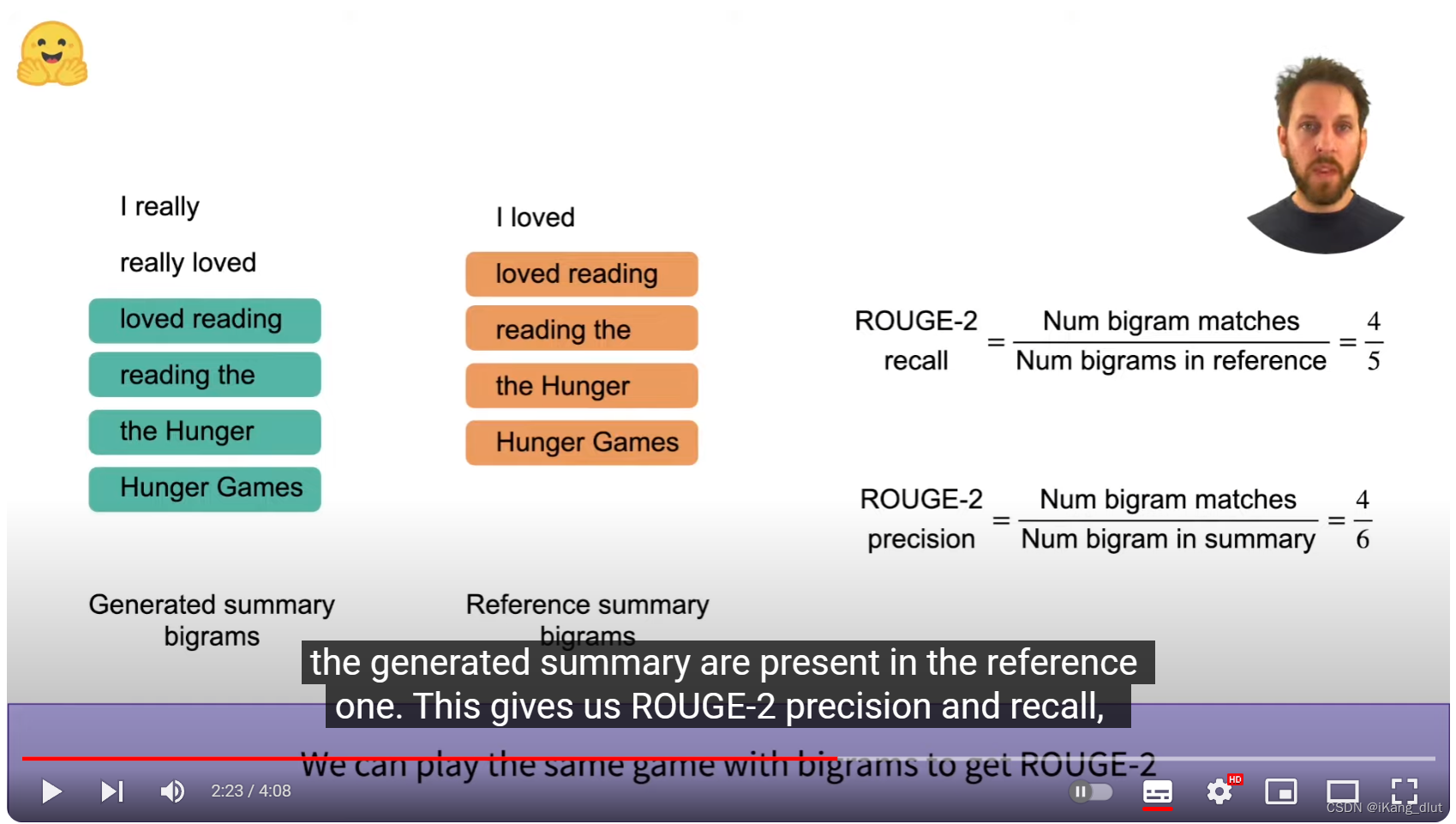
通过把模型生成的句子和人类给出的标注分拆成bi-gram的形式,与计算rouge-1类似,寻找匹配的bi-gram个数,带入公式,即可计算出rouge-2。
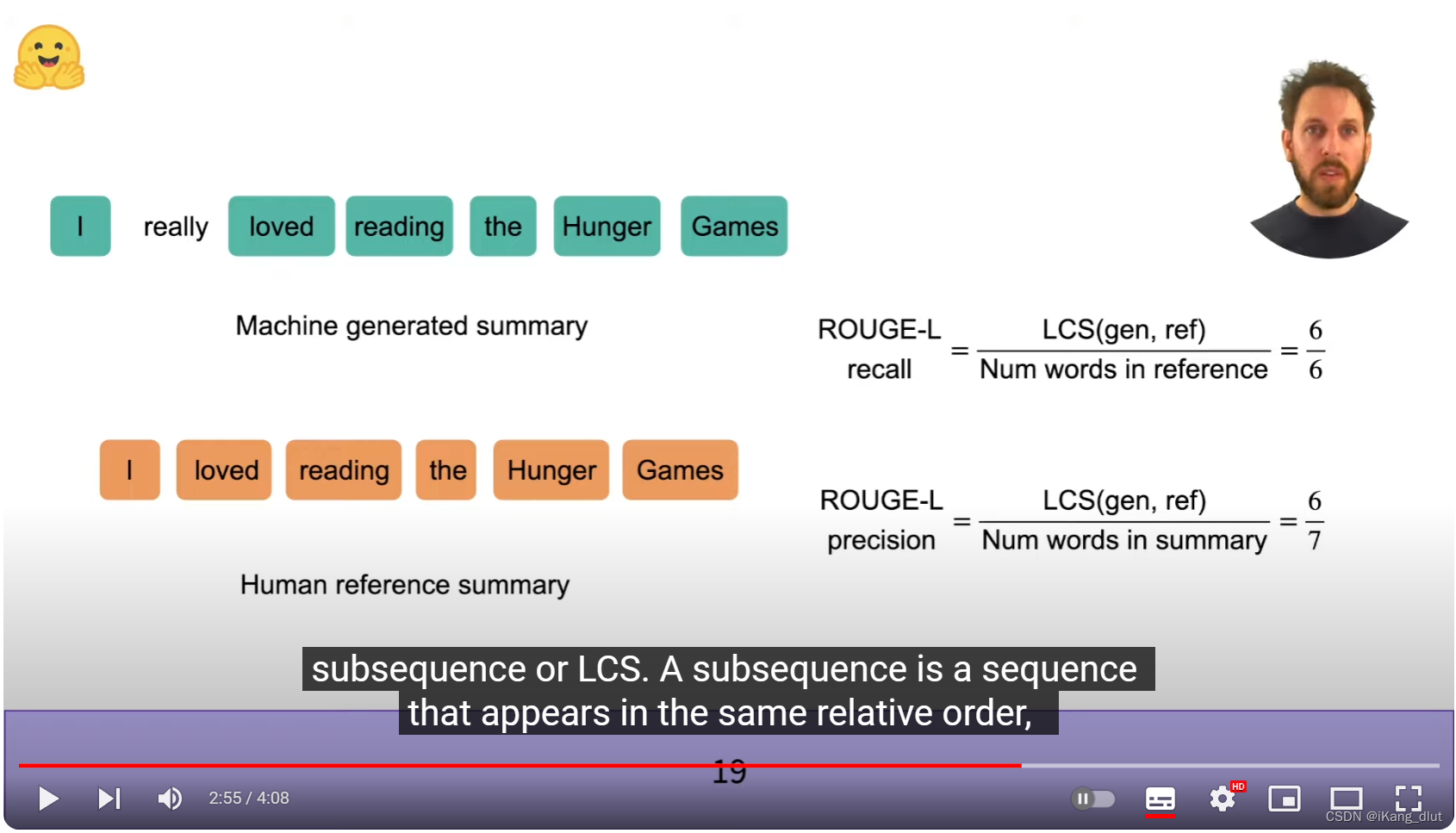
rouge-L
对于rouge-L,它不比较两句话中有多少个L-gram是相互匹配的,而是用两句话的最长公共子序列来计算。图中两句话的最长公共子序列长度为6,代入图中的ROUGE-L公式,即可计算出precision和recall。
如何调包计算rouge
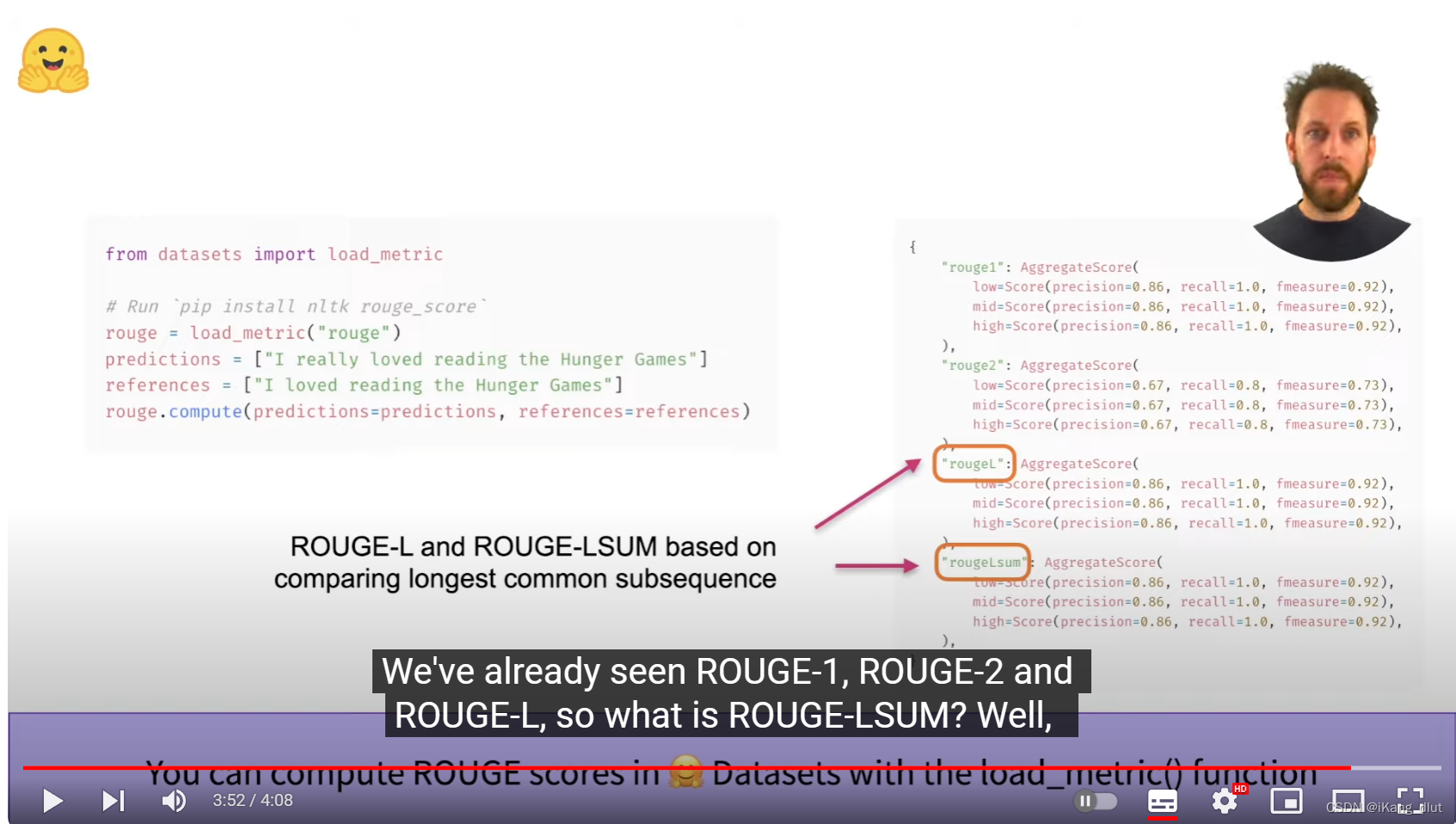
可以调用load_metric包来计算rouge








![Javascript[ECMAScript] ES6、ES7、ES8、ES9、ES10、ES11、ES12、ES13、ES14[2023]新特性](http://pic.xiahunao.cn/Javascript[ECMAScript] ES6、ES7、ES8、ES9、ES10、ES11、ES12、ES13、ES14[2023]新特性)





)
)



。Javaee项目。ssm项目。)