
文章目录
- 一 背景
- 二 Stack 和 Heap
- 2.1 Stack
- 2.2 Heap
- 2.3 性能区别
- 2.4 所有权和堆栈
- 三 所有权原则
- 3.1 变量作用域
- 3.2 String 类型示例
- 四 变量绑定背后的数据交互
- 4.1 所有权转移
- 4.1.1 基本类型: 拷贝, 不转移所有权
- 4.1.2 分配在 Heap 的类型: 转移所有权
- 4.2 Clone(深拷贝)
- 4.3 Copy(浅拷贝)
- 五 函数传值和返回
一 背景
变成语言都有潜在的内存泄露风险, 目前有三种方案流派:
- 垃圾回收机制(GC),在程序运行时不断寻找不再使用的内存,典型代表:Java、Go
- 手动管理内存的分配和释放, 在程序中,通过函数调用的方式来申请和释放内存,典型代表:C++
- 通过所有权来管理内存,编译器在编译时会根据一系列规则进行检查, 典型代表: Rust
一段不安全的代码如下:
int* foo() {int a; // 变量a的作用域开始a = 100;char *c = "xyz"; // 变量c的作用域开始return &a;
} // 变量a和c的作用域结束
这段代码虽然可以编译通过,但是其实非常糟糕,变量 a 和 c 都是局部变量,函数结束后将局部变量 a 的地址返回,但局部变量 a 存在栈中,在离开作用域后,a 所申请的栈上内存都会被系统回收,从而造成了 悬空指针(Dangling Pointer) 的问题。这是一个非常典型的内存安全问题,虽然编译可以通过,但是运行的时候会出现错误, 很多编程语言都存在。
再来看变量 c,c 的值是常量字符串,存储于常量区,可能这个函数我们只调用了一次,也可能我们不再会使用这个字符串,但 "xyz" 只有当整个程序结束后系统才能回收这片内存。
所以内存安全问题,一直都是程序员非常头疼的问题,好在, 在 Rust 中这些问题即将成为历史,因为 Rust 在编译的时候就可以帮助我们发现内存不安全的问题,那 Rust 如何做到这一点呢?
二 Stack 和 Heap
Stack 和 Heap 都是 os 里的数据结构
2.1 Stack
Stack: 其中 Stack 是后进先出, 因为这种实现方式, 所以 Stack 里的所有数据, 都必须占用已知且固定的内存空间. 如果数据的大小都是未知的, 那么取出数据时, 将无法取到你想要的数据.
2.2 Heap
Heap: 而 Heap 则可以存储大小未知, 或可能变化的数据. 当我们向 Heap 放入数据时需要申请一定的内存空间, os 在 Heap 的某处找到一块足够大的空位, 把它标记为已使用, 并返回一个该位置地址的指针, 这个过程称为 allocating (在 Heap 上分配内存).
接着, 该指针会被放入 Stack 中, 因为指针的大小是已知且固定的, 所以后续, 可以通过 Stack 里的指针获取数据在 Heap 上的实际内存位置, 进而访问该数据.
因此, 堆是一种缺乏组织的数据结构。想象一下去餐馆就座吃饭: 进入餐馆,告知服务员有几个人,然后服务员找到一个够大的空桌子(堆上分配的内存空间)并领你们过去。如果有人来迟了,他们也可以通过桌号(栈上的指针)来找到你们坐在哪。
2.3 性能区别
在 Stack 上分配内存, 比在 Heap 上分配内存更快.
因为 push Stack 时, os 无需更慢的系统调用, 只需要把新数据放在 栈顶即可. 而相比之下, 在 Heap 上分配内存则需要更多工作, 这是因为 os 必须先找到一块足够存放数据的内存空间, 并做一些记录来为下一次分配做准备, 而且如果当前进程分配的内存页不足时, 还需要做系统调用来申请更多内存.
2.4 所有权和堆栈
当你的代码调用一个函数时,传递给函数的参数(包括可能指向堆上数据的指针和函数的局部变量)依次被压入栈中,当函数调用结束时,这些值将被从栈中按照相反的顺序依次移除。
因为堆上的数据缺乏组织,因此跟踪这些数据何时分配和释放是非常重要的,否则堆上的数据将产生内存泄漏 —— 这些数据将永远无法被回收。这就是 Rust 所有权系统为我们提供的强大保障。
对于其他很多编程语言,你确实无需理解堆栈的原理,但是在 Rust 中,明白堆栈的原理,对于我们理解所有权的工作原理会有很大的帮助。
三 所有权原则
理解了堆栈,接下来看一下关于所有权的规则,首先请谨记以下规则:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
3.1 变量作用域
作用域是一个变量在程序中有效的范围, 假如有这样一个变量:
let s = "hello";
变量 s 绑定到了一个字符串字面值,该字符串字面值是硬编码到程序代码中的。s 变量从声明的点开始直到当前作用域的结束都是有效的:
{ // s 在这里无效,它尚未声明let s = "hello"; // 从此处起,s 是有效的// 使用 s
} // 此作用域已结束,s不再有效
简而言之,s 从创建开始就有效,然后有效期持续到它离开作用域为止,可以看出,就作用域来说,Rust 语言跟其他编程语言没有区别。
3.2 String 类型示例
之前提到过,本章会用 String 作为例子,因此这里会进行一下简单的介绍,具体的 String 学习请参见 String 类型。
我们已经见过字符串字面值 let s ="hello",s 是被硬编码进程序里的字符串值(类型为 &str )。字符串字面值是很方便的,但是它并不适用于所有场景。原因有二:
- 字符串字面值是不可变的,因为被硬编码到程序代码中
- 并非所有字符串的值都能在编写代码时得知
例如,字符串是需要程序运行时,通过用户动态输入然后存储在内存中的,这种情况,字符串字面值就完全无用武之地。 为此,Rust 为我们提供动态字符串类型: String, 该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小未知的文本。
四 变量绑定背后的数据交互
4.1 所有权转移
4.1.1 基本类型: 拷贝, 不转移所有权
先来看一段代码:
let x = 5;
let y = x;
这段代码并没有发生所有权的转移,原因很简单: 代码首先将 5 绑定到变量 x,接着拷贝 x 的值赋给 y,最终 x 和 y 都等于 5,因为整数是 Rust 基本数据类型,是固定大小的简单值,因此这两个值都是通过自动拷贝的方式来赋值的,都被存在栈中,完全无需在堆上分配内存。
整个过程中的赋值都是通过值拷贝的方式完成(发生在栈中),因此并不需要所有权转移。
可能有同学会有疑问:这种拷贝不消耗性能吗?实际上,这种栈上的数据足够简单,而且拷贝非常非常快,只需要复制一个整数大小(
i32,4 个字节)的内存即可,因此在这种情况下,拷贝的速度远比在堆上创建内存来得快的多。实际上,上一章我们讲到的 Rust 基本类型都是通过自动拷贝的方式来赋值的,就像上面代码一样。
4.1.2 分配在 Heap 的类型: 转移所有权
然后再来看一段代码:
let s1 = String::from("hello");
let s2 = s1;
此时,可能某个大聪明( 善意昵称 )已经想到了:嗯,上面一样,把 s1 的内容拷贝一份赋值给 s2,实际上,并不是这样。之前也提到了,对于基本类型(存储在栈上),Rust 会自动拷贝,但是 String 不是基本类型,而且是存储在堆上的,因此不能自动拷贝。
实际上, String 类型是一个复杂类型,由存储在栈中的堆指针、字符串长度、字符串容量共同组成,其中堆指针是最重要的,它指向了真实存储字符串内容的堆内存,至于长度和容量,如果你有 Go 语言的经验,这里就很好理解:容量是堆内存分配空间的大小,长度是目前已经使用的大小。
总之 String 类型指向了一个堆上的空间,这里存储着它的真实数据,下面对上面代码中的 let s2 = s1 分成两种情况讨论:
- 拷贝
String和存储在堆上的字节数组 如果该语句是拷贝所有数据(深拷贝),那么无论是String本身还是底层的堆上数据,都会被全部拷贝,这对于性能而言会造成非常大的影响 - 只拷贝
String本身 这样的拷贝非常快,因为在 64 位机器上就拷贝了8字节的指针、8字节的长度、8字节的容量,总计 24 字节,但是带来了新的问题,还记得我们之前提到的所有权规则吧?其中有一条就是:一个值只允许有一个所有者,而现在这个值(堆上的真实字符串数据)有了两个所有者:s1和s2。
好吧,就假定一个值可以拥有两个所有者,会发生什么呢?
当变量离开作用域后,Rust 会自动调用 drop 函数并清理变量的堆内存。不过由于两个 String 变量指向了同一位置。这就有了一个问题:当 s1 和 s2 离开作用域,它们都会尝试释放相同的内存。这是一个叫做 二次释放(double free) 的错误,也是之前提到过的内存安全性 BUG 之一。两次释放(相同)内存会导致内存污染,它可能会导致潜在的安全漏洞。
因此,Rust 这样解决问题:当 s1 被赋予 s2 后,Rust 认为 s1 不再有效,因此也无需在 s1 离开作用域后 drop 任何东西,这就是把所有权从 s1 转移给了 s2,s1 在被赋予 s2 后就马上失效了。
再来看看,在所有权转移后再来使用旧的所有者,会发生什么:
let s1 = String::from("hello");
let s2 = s1;println!("{}, world!", s1);
由于 Rust 禁止你使用无效的引用,你会看到以下的错误:
error[E0382]: borrow of moved value: `s1`--> src/main.rs:5:28|
2 | let s1 = String::from("hello");| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;| -- value moved here
4 |
5 | println!("{}, world!", s1);| ^^ value borrowed here after move|= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable|
3 | let s2 = s1.clone();| ++++++++For more information about this error, try `rustc --explain E0382`.
现在再回头看看之前的规则,相信大家已经有了更深刻的理解:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
如果你在其他语言中听说过术语 浅拷贝(shallow copy) 和 深拷贝(deep copy),那么拷贝指针、长度和容量而不拷贝数据听起来就像浅拷贝,但是又因为 Rust 同时使第一个变量 s1 无效了,因此这个操作被称为 移动(move),而不是浅拷贝。上面的例子可以解读为 s1 被移动到了 s2 中。那么具体发生了什么,用一张图简单说明:

这样就解决了我们之前的问题,s1 不再指向任何数据,只有 s2 是有效的,当 s2 离开作用域,它就会释放内存。 相信此刻,你应该明白了,为什么 Rust 称呼 let a = b 为变量绑定了吧?
再来看一段代码:
fn main() {let x: &str = "hello, world";let y = x;println!("{},{}",x,y);
}
这段代码,大家觉得会否报错?如果参考之前的 String 所有权转移的例子,那这段代码也应该报错才是,但是实际上呢?
这段代码和之前的 String 有一个本质上的区别:在 String 的例子中 s1 持有了通过String::from("hello") 创建的值的所有权,而这个例子中,x 只是引用了存储在二进制中的字符串 "hello, world",并没有持有所有权。
因此 let y = x 中,仅仅是对该引用进行了拷贝,此时 y 和 x 都引用了同一个字符串。如果还不理解也没关系,当学习了下一章节 “引用与借用” 后,大家自然而言就会理解。
4.2 Clone(深拷贝)
首先,Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何自动的复制都不是深拷贝,可以被认为对运行时性能影响较小。
如果我们确实需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的方法。
let s1 = String::from("hello");
let s2 = s1.clone();println!("s1 = {}, s2 = {}", s1, s2);
这段代码能够正常运行,说明 s2 确实完整的复制了 s1 的数据。
如果代码性能无关紧要,例如初始化程序时或者在某段时间只会执行寥寥数次时,你可以使用 clone 来简化编程。但是对于执行较为频繁的代码(热点路径),使用 clone 会极大的降低程序性能,需要小心使用!
4.3 Copy(浅拷贝)
浅拷贝只发生在栈上,因此性能很高,在日常编程中,浅拷贝无处不在。
再回到之前看过的例子:
let x = 5;
let y = x;println!("x = {}, y = {}", x, y);
但这段代码似乎与我们刚刚学到的内容相矛盾:没有调用 clone,不过依然实现了类似深拷贝的效果 —— 没有报所有权的错误。
原因是像整型这样的基本类型在编译时是已知大小的,会被存储在栈上,所以拷贝其实际的值是快速的。这意味着没有理由在创建变量 y 后使 x 无效(x、y 都仍然有效)。换句话说,这里没有深浅拷贝的区别,因此这里调用 clone 并不会与通常的浅拷贝有什么不同,我们可以不用管它(可以理解成在栈上做了深拷贝)。
Rust 有一个叫做 Copy 的特征,可以用在类似整型这样在栈中存储的类型。如果一个类型拥有 Copy 特征,一个旧的变量在被赋值给其他变量后仍然可用,也就是赋值的过程即是拷贝的过程。
那么什么类型是可 Copy 的呢?可以查看给定类型的文档来确认,这里可以给出一个通用的规则: 任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的。如下是一些 Copy 的类型:
- 所有整数类型,比如
u32 - 布尔类型,
bool,它的值是true和false - 所有浮点数类型,比如
f64 - 字符类型,
char - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是 - 不可变引用
&T,例如转移所有权中的最后一个例子,但是注意: 可变引用&mut T是不可以 Copy的
五 函数传值和返回
将值传递给函数,一样会发生 移动 或者 复制,就跟 let 语句一样,下面的代码展示了所有权、作用域的规则:
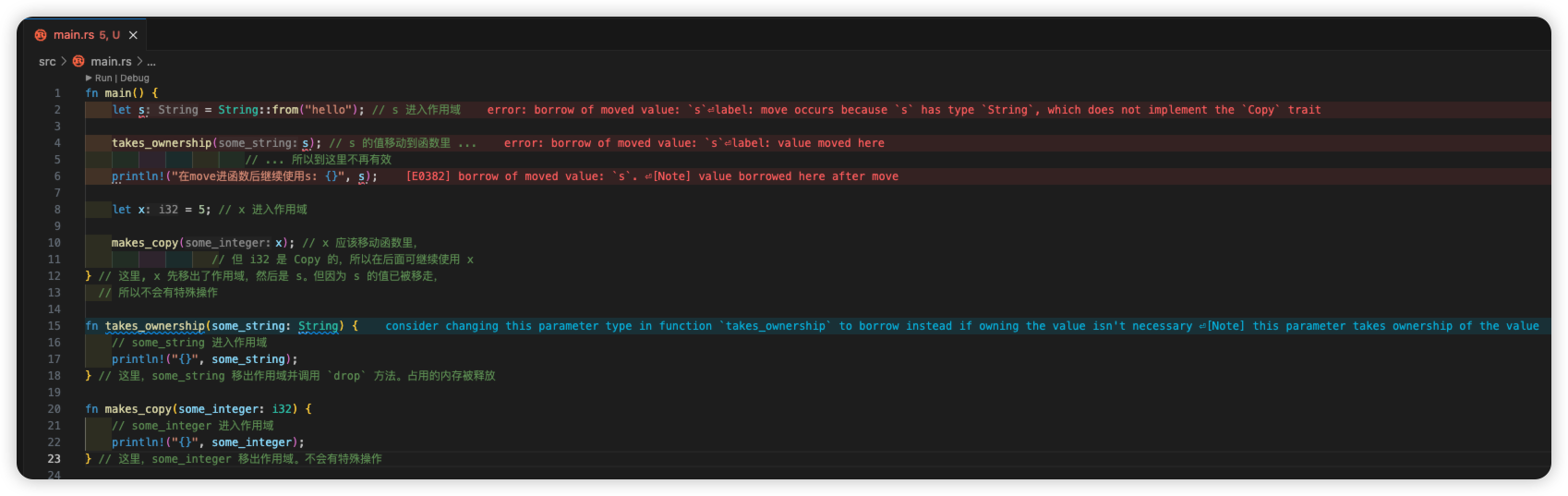
fn main() {let s = String::from("hello"); // s 进入作用域takes_ownership(s); // s 的值移动到函数里 ...// ... 所以到这里不再有效let x = 5; // x 进入作用域makes_copy(x); // x 应该移动函数里,// 但 i32 是 Copy 的,所以在后面可继续使用 x} // 这里, x 先移出了作用域,然后是 s。但因为 s 的值已被移走,// 所以不会有特殊操作fn takes_ownership(some_string: String) { // some_string 进入作用域println!("{}", some_string);
} // 这里,some_string 移出作用域并调用 `drop` 方法。占用的内存被释放fn makes_copy(some_integer: i32) { // some_integer 进入作用域println!("{}", some_integer);
} // 这里,some_integer 移出作用域。不会有特殊操作
你可以尝试在 takes_ownership 之后,再使用 s,看看如何报错?例如添加一行 println!(“在move进函数后继续使用s: {}”,s);。
同样的,函数返回值也有所有权,例如:
fn main() {let s1 = gives_ownership(); // gives_ownership 将返回值// 移给 s1let s2 = String::from("hello"); // s2 进入作用域let s3 = takes_and_gives_back(s2); // s2 被移动到// takes_and_gives_back 中,// 它也将返回值移给 s3
} // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,// 所以什么也不会发生。s1 移出作用域并被丢弃fn gives_ownership() -> String { // gives_ownership 将返回值移动给// 调用它的函数let some_string = String::from("hello"); // some_string 进入作用域.some_string // 返回 some_string 并移出给调用的函数
}// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域a_string // 返回 a_string 并移出给调用的函数
}
所有权很强大,避免了内存的不安全性,但是也带来了一个新麻烦: 总是把一个值传来传去来使用它。 传入一个函数,很可能还要从该函数传出去,结果就是语言表达变得非常啰嗦,幸运的是,Rust 提供了新功能解决这个问题。
)
之 @RequestMapping 注解)

,动态规划1)



)

)





——锁)


)
