
2月22日,Stability AI 发布了 Stable Diffusion 3 early preview,这是一种开放权重的下一代图像合成模型。据报道,它继承了其前身,生成了详细的多主题图像,并提高了文本生成的质量和准确性。这一简短的公告并未附带公开演示,但 Stability今天为那些想尝试的人开放了Waitlist,想等着尝鲜的同学可以注册加入Waitlist。
Waitlist地址:SD 3 Waitlist — Stability AI
Stability 表示,其 Stable Diffusion 3 系列模型(采用称为“prompt”的文本描述并将其转换为匹配图像)的参数大小从 8 亿到 80 亿不等。尺寸范围允许模型的不同版本在各种设备(从智能手机到服务器)上本地运行。参数大小大致对应于模型可以生成多少细节的能力。较大的模型还需要 GPU 加速器上有更多 VRAM 才能运行。
自 2022年以来,我们看到 Stability 推出了一系列 AI 图像生成模型:Stable Diffusion 1.4、1.5、2.0、2.1 、 XL 、 XL Turbo ,现在是 3。Stability 因提供更开放的替代方案而闻名,例如,类似OpenAI 的 DALL-E 3 这样的专有图像合成模型。尽管由于使用受版权保护的训练数据、偏见和滥用的可能性而引起争议,并导致了一些未解决的诉讼。Stable Diffusion模型是开放权重且源可用的,这意味着模型可以在本地运行并进行微调以改变其输出。
Stable Diffusion 3的技术改进
就技术改进而言,Stability 首席执行官 Emad Mostaque在 X 上写道:“这使用了新型Diffusion Transformer(类似于Sora),并结合了流量匹配(flow matching)和其他改进。这利用了Transformer的改进,不仅可以进一步扩展,还能够接受多模式输入。”
正如 Mostaque 所说,Stable Diffusion 3 系列使用Diffusion Transformer架构,这是一种利用 AI 创建图像的新方法,它将常用的图像构建块(例如U-Net 架构)替换为适用于小块图像的系统。该方法的灵感来自于擅长处理模式和序列的Transformer。这种方法不仅可以有效地扩大规模,而且据报道还可以产生更高质量的图像。
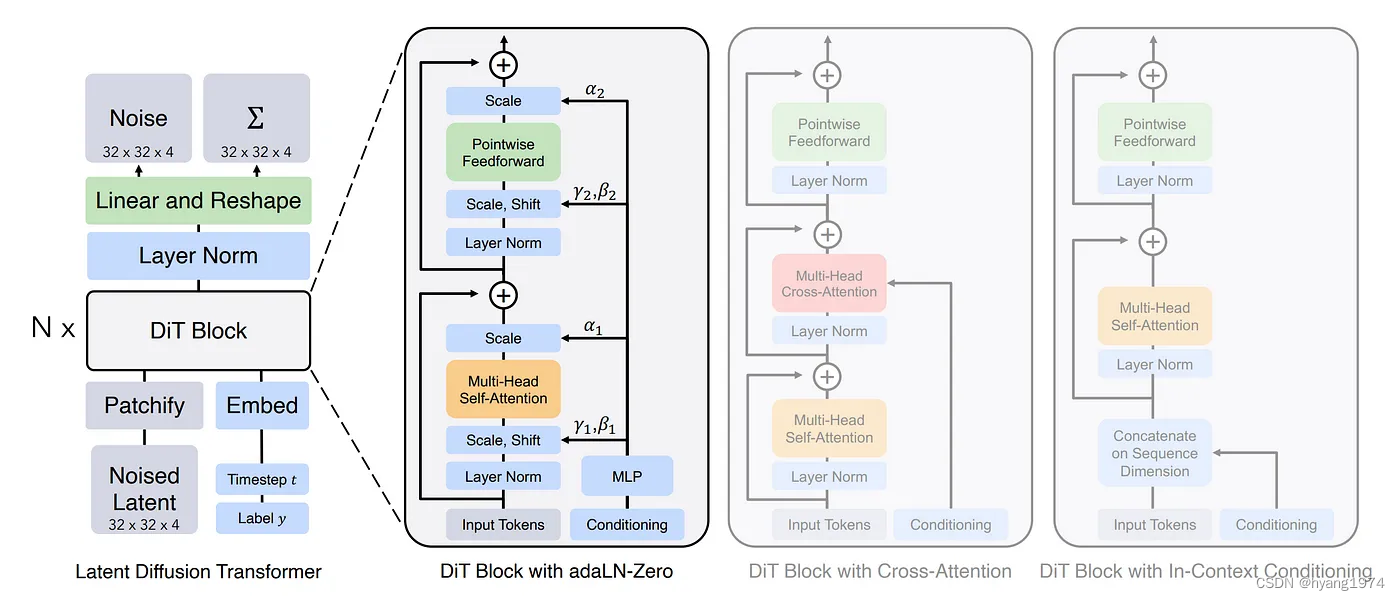
Stable Diffusion 3 还利用了流匹配(flow matching),这是一种创建 AI 模型的技术,该模型可以通过学习如何从随机噪声平滑过渡到结构化图像来生成图像。它不需要模拟过程的每个步骤,而是专注于图像创建应遵循的总体方向或流程。

我们目前还无法访问 Stable Diffusion 3 (SD3),但从我们在 Stability 网站和相关社交媒体帐户上发布的样本来看,这几代模型似乎与目前其他最先进的图像合成模型大致相当,包括前面提到的DALL-E 3、Adobe Firefly、Imagine with Meta AI、Midjourney和Google Imagen。
在Stability AI提供的示例中,SD3 可以很好地处理文本生成。文本生成是早期图像合成模型的一个特别弱点,因此在免费模型中改进该功能是一件大事。此外,提示保真度(它遵循提示中的描述的程度)似乎与 DALL-E 3 类似,但我们还没有自己测试过。
虽然 Stable Diffusion 3 尚未广泛使用,但 Stability 表示,一旦测试完成,其权重将可以免费下载并在本地运行。Stability 写道:“与之前的模型一样,这个预览阶段对于收集见解以在公开发布之前提高其性能和安全性至关重要。”
Stability 最近一直在尝试各种图像合成架构。除了 SDXL 和 SDXL Turbo 之外,就在上周,该公司还发布了Stable Cascade,它使用三阶段过程进行文本到图像的合成。

Flow Matching介绍
Flow Matching是Stable Diffusion 3中一个重要的技术改进。目前很多文生图模型使用的是CNF(连续正规化流动)训练方法,主要使用常微分方程对流动进行建模,实现从一种已知分布到目标分布的平滑映射。Stable Diffusion 3的Flow Matching基于“Flow Matching for Generative Modeling”,abs: https://arxiv.org/abs/2210.02747。

CNF的训练过程需要进行大量的微分方程模拟,会导致算力成本高、模型设计复杂、可解释性差等缺点。FM则是放弃微分方程的直接模拟,而是通过回归固定条件概率轨迹来实现无模拟训练。研究人员设计了条件概率分布与向量场的概念,利用边缘分布的结合可以建立总体目标概率轨迹与向量场,从而消除了模拟过程对梯度计算的影响。
1)条件概率路径构建:FM需要给出一个目标概率路径,该路径从简单分布演变到逼近数据分布。然后利用条件概率路径构建了目标路径,这样每个样本有一个对应的条件路径。
2)变换层:构成FM的基本单元,每个变换层都是可逆的。这意味着从输入到输出的每一步映射都可以精确地反转,从而允许从目标分布反推到原始分布。
3)耦合层:将输入分成两部分,对其中一部分应用变换,而变换函数可以是任意的神经网络,其参数由另一部分决定,保证了变换的可逆性。
目前,FM技术已在图像生成与超分辨率、图像理解、图像修复与填充、条件图像生成、图像风格迁移与合成、视频处理等领域得到广泛应用。
Stable Diffusion 3文生图展示
声明:以下的prompt和图片均来自StabilityAI官方和互联网,本人还在Waitlist无法亲自测试。
Prompt: Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy
Prompt: cinematic photo of a red apple on a table in a classroom, on the blackboard are the words "go big or go home"
Prompt: a painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner are the words "stable diffusion"
Prompt: studio photograph closeup of a chameleon over a black background
Prompt: night photo of a sports car with the text "SD3" on the side, the car is on a race track at high speed, a hug road sign with the text "faster"
Prompt: Photo of an 90's desktop computer on a work desk, on the computer screen it says "welcome". On the wall in the background we see
beautiful graffiti with the text "SD3" very large on the wall
Prompt: Three transparent glass bottles on a wooden table. The one on the left has red liquid and the number 1. The one in the middle has blue liquid and the number 2. The one on the right has green liquid and the number 3.
作者Blog原文:Stable Diffusion 3 Early Preview发布 - HY's Blog



![命令执行 [网鼎杯 2020 朱雀组]Nmap1](http://pic.xiahunao.cn/命令执行 [网鼎杯 2020 朱雀组]Nmap1)













)

】考试报名及起重机司机(限桥式起重机)证考试)