目录
一、说明
二、准备好
三、准备文件
四、拆分和创建数据集的嵌入
五、构建 LangChain
六、问一个问题
七、可视化
八、下一步是什么?
九、引用
一、说明
为了应对这些挑战,已经开发了一种称为检索增强生成(RAG)的技术。RAG 向 LLM 的工作流添加了一个检索步骤,使其能够在响应查询时从其他来源(如您的私人文本文档)查询相关数据。这些文档可以预先划分为小片段,嵌入(紧凑向量表示)是使用 OpenAI 的 embedding-ada-002 等 ML 模型生成的。具有相似内容的代码段将具有类似的嵌入。当 RAG 应用程序收到问题时,它会将此查询投影到同一嵌入空间中,并检索与查询相关的相邻文档片段。然后,LLM 使用这些文档片段作为上下文来回答问题。此方法可以提供回答查询所需的信息,还可以通过向用户显示使用的代码片段来实现透明度。
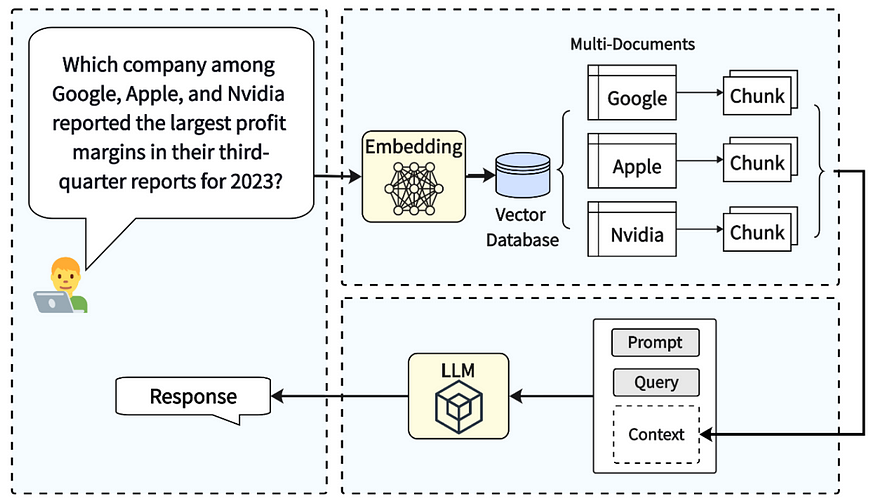
检索增强生成 [2]: 唐一轩, 杨毅: 多跳-RAG: 多跳查询的基准检索增强生成 (2021), arXiv — CC BY-SA 4.0
在开发 RAG 应用程序时,正如许多其他领域所认识到的那样,对数据有一个很好的概述是很重要的。对于 RAG,可视化嵌入空间特别有用,因为 RAG 应用程序使用此空间来查找相关信息。由于查询与文档片段共享空间,因此需要考虑相关文档片段和查询之间的接近程度。我们建议将可视化与 UMAP [3] 等方法结合使用,将高维嵌入简化为更易于管理的 2D 可视化,同时保留重要的属性,例如代码段和查询之间的关系和邻近性。尽管高维嵌入被简化为只有两个组件,但仍然可以识别在嵌入空间中形成集群的问题及其相关文档片段。这有助于深入了解数据的性质。

文档片段嵌入的 UMAP 降维,根据它们与“谁建造了纽博格林”问题的相关性着色——由作者创建
在本文中,您将学习如何
- 准备文档:从收集数据开始。本教程以 HTML 格式的维基百科一级方程式数据为例,为我们的 RAG 应用程序构建数据集。您也可以在这里使用自己的数据!
- 拆分和创建嵌入:将收集的文档分解为更小的片段,并使用嵌入模型将它们转换为紧凑的矢量表示形式。这涉及使用拆分器、OpenAI 的 text-embedding-ada-002 和 ChromaDB 作为向量存储。
- 构建 LangChain:通过组合用于创建上下文的提示生成器、用于获取相关片段的检索器和用于回答查询的 LLM (GPT-4) 来设置 LangChain。
- 提问:了解如何向 RAG 应用程序提问。
- 可视化:使用 Renumics-Spotlight 以 2D 形式可视化嵌入,并分析查询和文档片段之间的关系和邻近性。
本简化教程将引导您完成开发 RAG 应用程序的每个阶段,并特别关注可视化结果的作用。
该代码可在 Github 上找到
二、准备好
首先,安装所有必需的软件包:
!pip install langchain langchain-openai chromadb renumics-spotlight 本教程使用 Langchain、Renumics-Spotlight python 包:
- Langchain:一个集成语言模型和 RAG 组件的框架,使设置过程更加顺畅。
- Renumics-Spotlight:一种可视化工具,用于以交互方式探索非结构化 ML 数据集。
免责声明:本文作者也是 Spotlight 的开发者之一。
所需的 ML 模型将从 OpenAI 中使用
- GPT-4:一种最先进的语言模型,以其先进的文本理解和生成功能而闻名。
- embedding-ada-002:设计用于创建文本嵌入表示形式的专用模型。
设置你的OPENAI_API_KEY;例如,您可以在笔记本中使用 Notebook Line Magic 进行设置:
%env OPENAI_API_KEY=<your-api-key>三、准备文件
对于此演示,您可以使用我们准备的维基百科所有一级方程式文章的数据集。该数据集是使用 wikipedia-api 和 BeautifulSoup 创建的。您可以下载数据集。
该数据集基于维基百科上的文章,并根据知识共享署名-相同方式共享许可获得许可。原始文章和作者列表可以在相应的维基百科页面上找到。
将提取的 html 放入 docs/ 子文件夹中。
或者,您可以通过创建 docs/ 子文件夹并将您自己的文件复制到其中来使用您自己的数据集。

作者使用 Midjourney v6.0 创建的图像
四、拆分和创建数据集的嵌入
您可以跳过此部分并下载嵌入一级方程式数据集的数据库。
要自行创建嵌入,您首先需要设置嵌入模型和向量存储。 在这里,我们使用 OpenAIEmbeddings 中的 text-embedding-ada-002 和使用 ChromaDB 的矢量存储:
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores.chroma import Chromaembeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
docs_vectorstore = Chroma(collection_name="docs_store",embedding_function=embeddings_model,persist_directory="docs-db",
)向量存储将保留在 docs-db/ 文件夹中。
为了填充向量存储,我们使用 BSHTMLLoader 加载 html 文档:
from langchain_community.document_loaders import BSHTMLLoader, DirectoryLoader
loader = DirectoryLoader("docs",glob="*.html",loader_cls=BSHTMLLoader,loader_kwargs={"open_encoding": "utf-8"},recursive=True,show_progress=True,
)
docs = loader.load()并将它们分成更小的块
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200, add_start_index=True
)
splits = text_splitter.split_documents(docs)此外,还可以创建可从元数据重构的 ID。如果您只有包含其内容和元数据的文档,则允许在数据库中找到嵌入。您可以将所有内容添加到数据库中并存储它:
import hashlib
import json
from langchain_core.documents import Documentdef stable_hash(doc: Document) -> str:"""Stable hash document based on its metadata."""return hashlib.sha1(json.dumps(doc.metadata, sort_keys=True).encode()).hexdigest()split_ids = list(map(stable_hash, splits))
docs_vectorstore.add_documents(splits, ids=split_ids)
docs_vectorstore.persist()您可以在本教程中找到有关拆分和整个过程的更多信息。
五、构建 LangChain
首先,您需要选择一个 LLM 模型。在这里,我们使用 GPT-4。此外,您需要准备检索器以使用向量存储:
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4", temperature=0.0)
retriever = docs_vectorstore.as_retriever(search_kwargs={"k": 20}) 将参数设置为初始化模型时可确保确定性输出。temperature0.0ChatOpenAI
现在,让我们为 RAG 创建一个提示。LLM 将提供用户的问题和检索到的文档作为回答问题的上下文。它还被指示提供允许其回答的来源:
from langchain_core.prompts import ChatPromptTemplatetemplate = """
You are an assistant for question-answering tasks.
Given the following extracted parts of a long document and a question, create a final answer with references ("SOURCES").
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
ALWAYS return a "SOURCES" part in your answer.QUESTION: {question}
=========
{source_documents}
=========
FINAL ANSWER: """
prompt = ChatPromptTemplate.from_template(template)接下来,设置一个处理管道,该管道首先设置检索到的文档的格式,以包含页面内容和源文件路径。然后,将此格式化输入输入到语言模型 (LLM) 步骤中,该步骤根据组合的用户问题和文档上下文生成答案。
from typing import Listfrom langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParserdef format_docs(docs: List[Document]) -> str:return "\n\n".join(f"Content: {doc.page_content}\nSource: {doc.metadata['source']}" for doc in docs)rag_chain_from_docs = (RunnablePassthrough.assign(source_documents=(lambda x: format_docs(x["source_documents"])))| prompt| llm| StrOutputParser()
)
rag_chain = RunnableParallel({"source_documents": retriever,"question": RunnablePassthrough(),}
).assign(answer=rag_chain_from_docs)六、问一个问题
RAG 应用程序现在已准备好回答问题:
question = "Who built the nuerburgring"
response = rag_chain.invoke(question)
response["answer"]这将打印一个正确答案:
'The Nürburgring was built in the 1920s, with the construction of the track beginning in September 1925. The track was designed by the Eichler Architekturbüro from Ravensburg, led by architect Gustav Eichler. The original Nürburgring was intended to be a showcase for German automotive engineering and racing talent (SOURCES: data/docs/Nürburgring.html).'我们将坚持一个问题。这个问题也将在下一节中用于进一步调查。
七、可视化
为了在 Spotlight 中探索数据,我们使用 Pandas DataFrame 来组织我们的数据。让我们从向量存储中提取文本片段及其嵌入开始。另外,让我们标记正确答案:
import pandas as pdresponse = docs_vectorstore.get(include=["metadatas", "documents", "embeddings"])
df = pd.DataFrame({"id": response["ids"],"source": [metadata.get("source") for metadata in response["metadatas"]],"page": [metadata.get("page", -1) for metadata in response["metadatas"]],"document": response["documents"],"embedding": response["embeddings"],}
)
df["contains_answer"] = df["document"].apply(lambda x: "Eichler" in x)
df["contains_answer"].to_numpy().nonzero()问题和相关答案也会投影到嵌入空间中。它们的处理方式与文本片段相同:
question_row = pd.DataFrame({"id": "question","question": question,"embedding": embeddings_model.embed_query(question),}
)
answer_row = pd.DataFrame({"id": "answer","answer": answer,"embedding": embeddings_model.embed_query(answer),}
)
df = pd.concat([question_row, answer_row, df])此外,可以确定问题和文档片段之间的距离:
import numpy as np
question_embedding = embeddings_model.embed_query(question)
df["dist"] = df.apply(lambda row: np.linalg.norm(np.array(row["embedding"]) - question_embedding),axis=1,
) 这还可以用于可视化,并将存储在列中:distance
+----+------------------------------------------+----------------------------+------------------------------------------------------------------------+----------------------------------------------------+----------------------------------------+--------+------------------------------+-------------------+------------+
| | id | question | embedding | answer | source | page | document | contains_answer | dist |
|----+------------------------------------------+----------------------------+------------------------------------------------------------------------+----------------------------------------------------+----------------------------------------+--------+------------------------------+-------------------+------------|
| 0 | question | Who built the nuerburgring | [0.005164676835553928, -0.011625865528385777, ... | nan | nan | nan | nan | nan | nan |
| 1 | answer | nan | [-0.007912757349432444, -0.021647867427574807, ... | The Nürburgring was built in the 1920s in the town | nan | nan | nan | nan | 0.496486 |
| 2 | 000062fd07a090c7c84ed42468a0a4b7f5f26bf8 | nan | [-0.028886599466204643, 0.006249633152037859, ... | nan | data/docs/Hamilton–Vettel rivalry.html | -1 | Media reception... | 0 | 0.792964 |
| 3 | 0003de08507d7522c43bac201392929fb2e26b86 | nan | [-0.031988393515348434, -0.002095212461426854, ... | nan | data/docs/Cosworth GBA.html | -1 | Team Haas[edit]... | 0 | 0.726574 |
| 4 | 000543bb633380334e742ec9e0c15a188dcb0bf2 | nan | [-0.007886063307523727, 0.007812486961483955, ... | nan | data/docs/Interlagos Circuit.html | -1 | Grand Prix motorcycle racing.| 0 | 0.728354 |
| | | | | | | | Brazilian motorcycle... | | |
+----+------------------------------------------+----------------------------+------------------------------------------------------------------------+----------------------------------------------------+----------------------------------------+--------+------------------------------+-------------------+------------Renumics Spotlight 可以从以下方式开始:
from renumics import spotlight
spotlight.show(df)它将打开一个新的浏览器窗口。左上角的表格部分显示数据集的所有字段。您可以使用“可见列”按钮选择“问题”、“答案”、“源”、“文档”和“dist”列。按“dist”对表格进行排序,在顶部显示问题、答案和最相关的文档片段。选择前 14 行以在右上角的相似性图中突出显示它们。
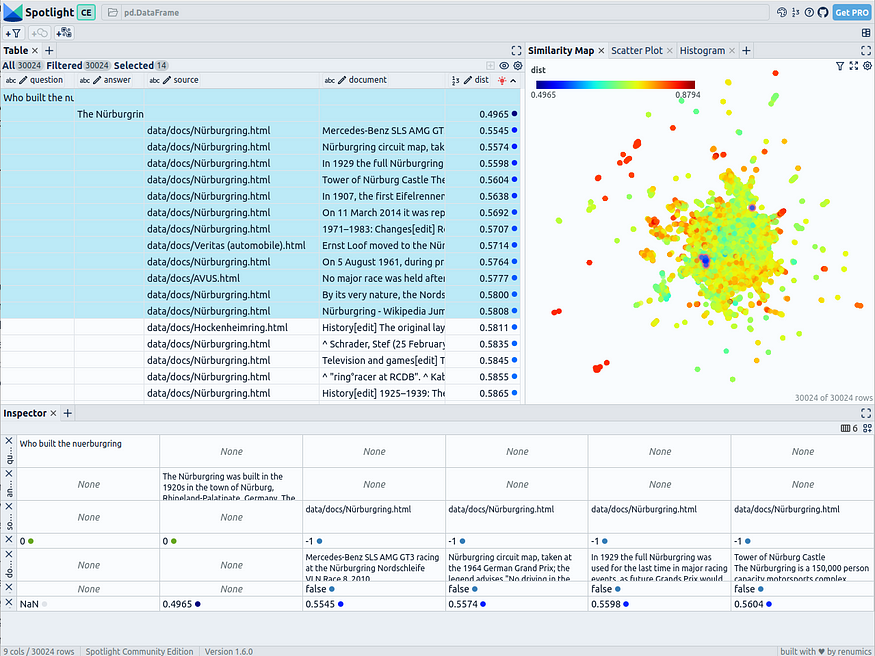
文档片段嵌入的 UMAP 降维,根据它们与“谁建造了纽博格林?”问题的相关性着色——由作者与 Renumics Spotlight 一起创建
您可以观察到,最相关的文档与问题和答案非常接近。这包括包含正确答案的单个文档片段。
八、下一步是什么?
单个问题、答案和相关文档的良好可视化显示了 RAG 的巨大潜力。使用降维技术可以使用户和开发人员可以访问嵌入空间。本文中具体介绍的实用性仍然非常有限。探索这些方法在提出许多问题的可能性,从而说明RAG系统在运行中的使用或通过评估问题检查嵌入空间的覆盖范围,仍然令人兴奋。请继续关注后续的更多文章。
通过使用增强数据科学工作流程的 Spotlight 等工具,可以更轻松地实现 RAG 的可视化。尝试使用您自己的数据编写代码,并在评论中告诉我们您的结果!
我是一名专业人士,擅长为非结构化数据的交互式探索创建高级软件解决方案。我撰写有关非结构化数据的文章,并使用强大的可视化工具进行分析并做出明智的决策。
九、引用
[1] 高云帆, 熊云, 高新宇, 贾康祥, 潘金柳, 毕玉溪, 戴毅, 孙佳伟, 郭倩宇, 王萌, 王浩芬: 大型语言模型的检索增强生成:调查 (2024), arxiv
[2] Yixuan Tang, Yi Yang: MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries (2021), arXiv
[3] Leland McInnes、John Healy、James Melville:UMAP:用于降维的均匀流形近似和投影 (2018),arXiv

方法的基本使用,第一种用法 <模板字符串>.format(<参数列表>)。)






拓扑排序)





![[SUCTF 2019]EasySQL1 题目分析与详解](http://pic.xiahunao.cn/[SUCTF 2019]EasySQL1 题目分析与详解)




