1.概述
Zookeeper是一个开源的,分布式的,为分布式框架(如下图中的Hadoop和Hive)提供协调服务的Apache项目。

工作机制:基于观察者设计模式的分布式服务管理框架,负责存储和管理数据,接受观察者注册,一旦这些数据状态发生变化,Zookeeper就会发送通知给这些已注册的观察者。简而言之,Zookeeper = 文件系统+通知机制。
特点:
1)由1个Leader和多个Follower组成的集群
2)有一半以上节点存活,Zookeeper集群就能正常服务,所以Zookeeper适合安装奇数台服务器(比如5台和6台服务器,都是挂3台之后Zookeeper集群不能服务,6台服务器相比于5台服务器的可靠性并没有提高)
3)全局数据一致,每个服务器都有一份相同的数据副本
4)来自同一个客户端的请求顺序执行
5)数据更新具有原子性,要么成功,要么失败

2.数据结构
Zookeeper的数据结构和Linux类似,都是树形结构(类似的还有HDFS),每一个节点称为一个ZNode,默认存储1MB的数据,所以不能存储海量数据,只能存储配置信息这种小数据。
3.配置
将conf目录下的zoo_sample.cfg修改为zoo.cfg,其中内容如下

其中dataDir的值需要修改,不要设为放在Linux临时目录下。tickTime表示心跳时间,客户端与服务端或者服务端与服务端的通信心跳时间。initLimit表示Leader和Follower初始化第一次建立连接的最大通信心跳数。syncLimit表示建立第一次连接连接之后的最大通信心跳数。clientPort是客户端端口号。
启动服务端命令:bin/zkServer.sh start,可以通过jps -l看到zookeeper的进程:
![]()
启动客户端命令:bin/zkCli.sh

查看zk服务端状态命令:bin/zkServer.sh status,下图显示的是standalone模式

停止服务端命令:bin/zkServer.sh stop
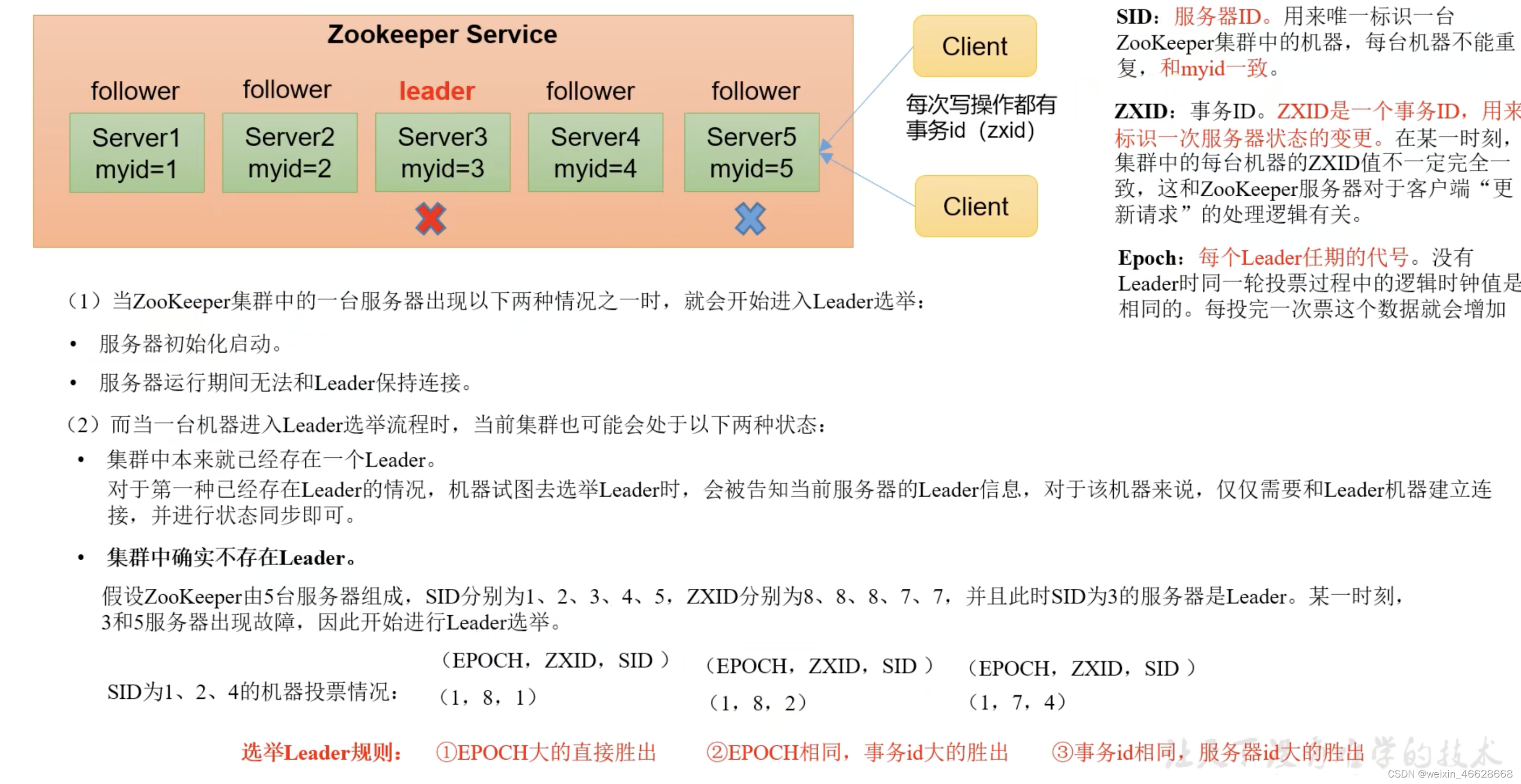
4.第一次选举机制

其中的myid是在配置文件里,相当于这台服务器的身份标识。第一次选举机制可以简单理解为依次投给myid最大的服务器,直到集群里半数以上服务器启动完。
5.非第一次启动选举机制
![[算法沉淀记录] 排序算法 —— 归并排序](http://pic.xiahunao.cn/[算法沉淀记录] 排序算法 —— 归并排序)
最佳实践 -- 稀疏主索引)

![js使用import到本js文件中的函数时报错 Error [ERR_MODULE_NOT_FOUND]: Cannot find module](http://pic.xiahunao.cn/js使用import到本js文件中的函数时报错 Error [ERR_MODULE_NOT_FOUND]: Cannot find module)
)



一步一步编译SDK文件)

)
)
)






