是基于LangChain框架下的开发,所以最开始请先
pip install Langchain
pip install bilibili-api-python技术要点:
-
使用Langchain框架自带的Document loaders
-
修改BiliBiliLoader的源码,自带的并不支持当前b站的视频加载
源码文件修改:
import json
import re
import warnings
from typing import List, Tupleimport requests
from langchain_core.documents import Document
from bilibili_api import sync, video
from langchain_community.document_loaders.base import BaseLoader
# Pre-compile regular expressions for video ID extraction
BV_PATTERN = re.compile(r"BV\w+")
AV_PATTERN = re.compile(r"av[0-9]+")class BiliBiliLoader(BaseLoader):"""Loader for fetching transcripts from BiliBili videos."""def __init__(self, video_urls: List[str], sessdata: str, bili_jct: str, buvid3: str):"""Initialize with bilibili url.Args:video_urls (List[str]): List of BiliBili video URLs.sessdata (str): SESSDATA cookie value for authentication.bili_jct (str): BILI_JCT cookie value for authentication.buvid3 (str): BUVI3 cookie value for authentication."""self.video_urls = video_urlsself.credential = video.Credential(sessdata=sessdata, bili_jct=bili_jct, buvid3=buvid3)def load(self) -> List[Document]:"""Load and return a list of documents containing video transcripts.Returns:List[Document]: List of Document objects transcripts and metadata."""results = []for url in self.video_urls:transcript, video_info = self._get_bilibili_subs_and_info(url)doc = Document(page_content=transcript, metadata=video_info)results.append(doc)return resultsdef _get_bilibili_subs_and_info(self, url: str) -> Tuple[str, dict]:"""Retrieve video information and transcript for a given BiliBili URL.Args:url (str): BiliBili video URL.Returns:Tuple[str, dict]: A tuple containing the transcript and video information."""bvid = BV_PATTERN.search(url)if bvid:v = video.Video(bvid=bvid.group(), credential=self.credential)else:aid = AV_PATTERN.search(url)if aid:v = video.Video(aid=int(aid.group()[2:]), credential=self.credential)else:raise ValueError(f"Unable to find a valid video ID in URL: {url}")video_info = sync(v.get_info())video_info.update({"url": url})sub = sync(v.get_subtitle(video_info["cid"]))# Retrieve and process subtitle contentsub_list = sub["subtitles"]if sub_list:sub_url = sub_list[0]["subtitle_url"]if not sub_url.startswith("http"):sub_url = "https:" + sub_urlresponse = requests.get(sub_url)if response.status_code == 200:raw_sub_titles = json.loads(response.content)["body"]raw_transcript = " ".join([c["content"] for c in raw_sub_titles])raw_transcript_with_meta_info = (f"Video Title: {video_info['title']}, "f"description: {video_info['desc']}\n\n"f"Transcript: {raw_transcript}")return raw_transcript_with_meta_info, video_infoelse:warnings.warn(f"Failed to fetch subtitles for {url}. "f"HTTP Status Code: {response.status_code}")return "", video_infoelse:warnings.warn(f"No subtitles found for video: {url}. Returning empty transcript.")return "", video_info其中SESSDATA,BUVID3,BILI_JCT 三个参数需要通过访问登录B站进行获取。固定值也是必须值,不需要刷新,永久有效,但是如果该账户访问次数过多和频繁存在被封禁情况,现在不知道b站那边封禁策略。
获取方法:打开b站网页,F12开发者工具,应用程序->cookies>www.bilibili.com 下的元素获取。
from langchain_community.document_loaders import BiliBiliLoader
SESSDATA = "***************************************"
BUVID3 = "**************************************"
BILI_JCT = "******************************************"loader = BiliBiliLoader(["https://www.bilibili.com/video/BV1PZ421S7VF/?spm_id_from=333.1007.tianma.1-2-2.click"
],
sessdata = SESSDATA,
bili_jct = BILI_JCT,
buvid3 = BUVID3,
)
docs = loader.load()
print(docs)源码解析:
_get_bilibili_subs_and_info:
他是一个检索给定 BiliBili URL 的视频信息和文字记录。
获取到视频信息后,可以找到字幕URL的获取路径,访问该路径可以获取到字幕信息:
sub_list = sub["subtitles"]
if sub_list:sub_url = sub_list[0]["subtitle_url"]if not sub_url.startswith("http"):sub_url = "https:" + sub_urlresponse = requests.get(sub_url)例子:https://aisubtitle.hdslb.com/bfs/ai_subtitle/prod/125040837614317115816310f6f57f99190f192792b6f2d98ac0?auth_key=1708498531-6e1797becb564b90a29714989167da05-0-e9073436bc93efbbb4f87a3b0c3f7b3f
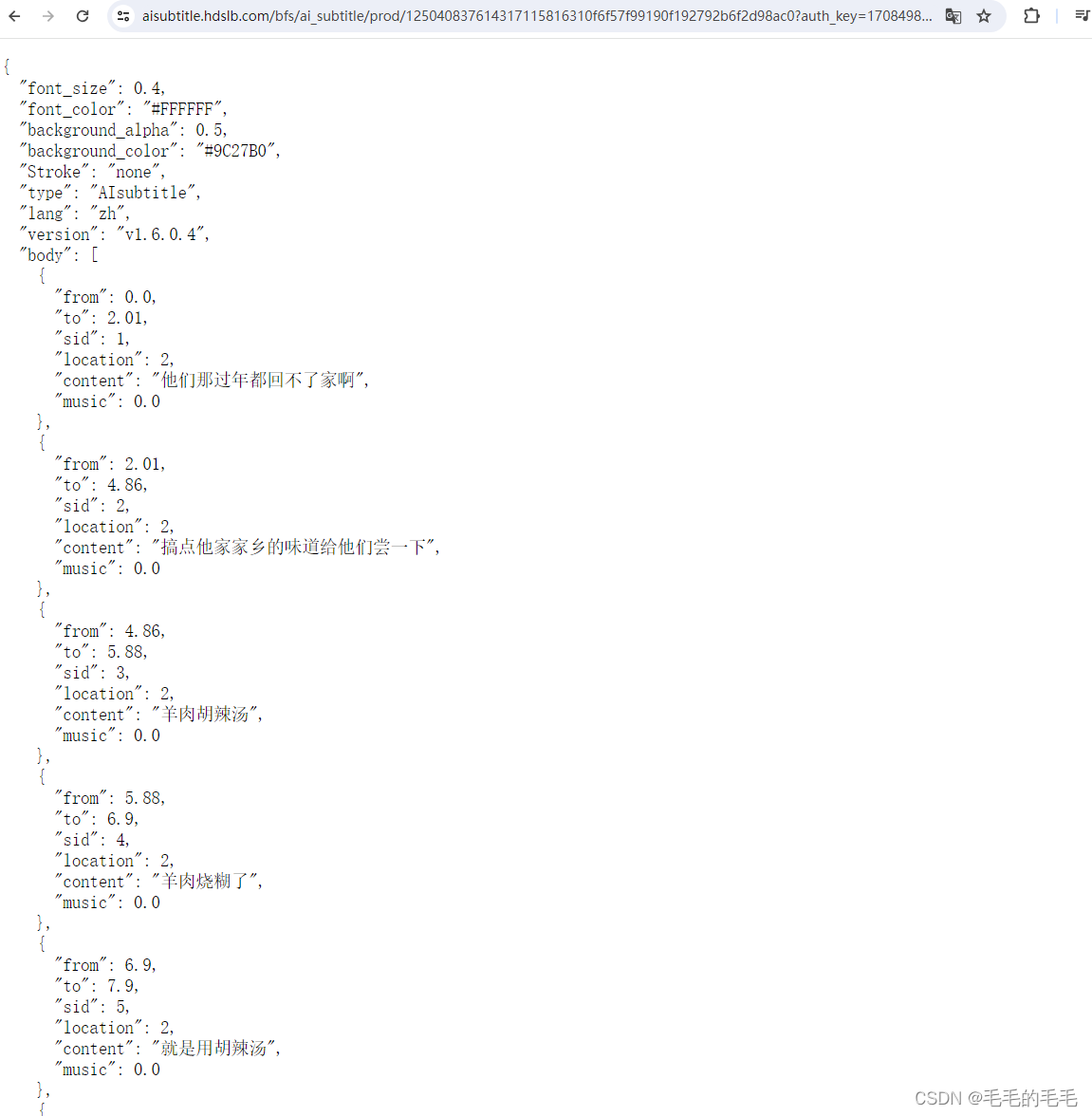
如果请求字幕接口成功,那么对于所有的返回的语音字幕文字进行处理:
response = requests.get(sub_url)
if response.status_code == 200:raw_sub_titles = json.loads(response.content)["body"]raw_transcript = " ".join([c["content"] for c in raw_sub_titles])raw_transcript_with_meta_info = (f"Video Title: {video_info['title']}, "f"description: {video_info['desc']}\n\n"f"Transcript: {raw_transcript}")问题:
-
部分b站视频不支持语音文字字幕获取,获取时给错误提示,现在测试情况95%的是视频都是可以获取到了。
-
目前视频语言字幕抓取语言,测试只抓取中文,抓取的数据目测是b站提供的字幕数据,其他国家的语言不提供一律转为中文。
-
AI 字幕需要使用登录账号的cookie进行请求,请求频繁或者过多会出现封禁,体现为接口返回正常返回内容,但是subtitle列表为空(即使实际上有ai字幕),无法获取subtitle_url。建议准备多个账号备用。











利用脚本进行区块链系统监控)



之SpringCloud Gateway)
 Object Pascal 学习笔记---第5章第3节(自定义托管记录))


