文献速递:GAN医学影像合成–用生成对抗网络生成 3D TOF-MRA 体积和分割标签
01
文献速递介绍
深度学习算法在自然图像分析中的成功近年来已被应用于医学成像领域。深度学习方法已被用于自动化各种耗时的手动任务,如医学图像的分割和分类(Greenspan 等,2016年;Lundervold 和 Lundervold,2019年)。特别是,监督式深度学习方法通过将输入图像中的特征映射到标签输出来学习相关特征。虽然这些方法的优势在于它们不需要从图像中手动提取特征,但它们确实需要大量的标记数据。这里的一个主要挑战是,获取和标记医学数据既昂贵又困难(Yi 等,2019年)。然而,即使有标记的医学数据可用,通常也不能因为隐私问题而轻易地与其他研究人员共享(临床实践委员会,2000年)。通常应用于医学成像的匿名化方法在神经成像的情况下不会有益,因为大脑图像中存在的独特神经解剖特征可用于识别个体(Wachinger 等,2015年;Valizadeh 等,2018年)。因此,当提出新的神经成像深度学习模型时,常常使用小型、孤立或同质的数据集(Willemink 等,2020年)。解决这个问题的一个潜在方法是生成合成医学成像数据。用于此目的的一个非常有前景的方法是生成对抗网络(GANs)(Goodfellow 等,2014年)。自然图像领域的各种 GAN 架构在医学成像中用于图像合成、监督式图像到图像的转换、重建和超分辨率等方面变得流行(Yi 等,2019年)。对于图像合成,特别是,2D GAN 已在多项工作中使用,例如计算机断层扫描(CT)肝病变的合成(Frid-Adar 等,2018年)、皮肤病变图像的合成(Baur 等,2018年)以及轴向磁共振(MR)切片的合成(Bermudez 等,2018年)。GAN 可以扩展以生成合成图像和标签。例如,2D GAN 已被用于生成肺部 X 射线(Neff 等,2018年)、血管分割(Kossen 等,2021年)、视网膜底片图像(Guibas 等,2018年)和脑肿瘤分割(Foroozandeh 和 Eklund,2020年)的相应分割标签。尽管这些结果充满希望,但挑战仍然是 2D GAN 无法捕获第三维度中的重要解剖关系。由于医学图像通常以 3D 形式记录,因此生成 3D 医学图像的 GAN 显得尤为重要。3D GAN 已用于生成不同分辨率的降采样或调整大小的 MRI 图像(Kwon 等,2019年;Eklund,2020年;Sun 等,2021年)。然而,据我们所知,还没有 3D GAN 医学成像研究生成相应的标签,这对于使用数据进行监督式深度学习研究至关重要。成像体积的合成仍然是一个挑战。在我们的研究中,我们生成了高分辨率的 3D 医学图像块及其标签,并采用端到端的范式进行脑血管分割,以助于识别和研究脑血管疾病。从 3D 飞行时间磁共振血管造影(TOF-MRA)中,我们合成了带有脑血管分割标签的 3D 块。我们实现并比较了四种不同的 3D Wasserstein-GAN(WGAN)变体:三种具有相同架构但不同正则化和混合精度(Micikevicius 等,2018年)方案的变体,以及一种修改了架构的变体 - 每层双倍滤波器 - 由于混合精度的内存效率。除了定性视觉评估外,我们使用定量测量来评估合成的块。我们进一步评估了在生成的块标签对上训练的脑血管分割模型的性能,并将其与在真实数据上训练的基准模型进行比较。此外,我们还在第二个独立的数据集上比较了分割性能。总结来说,我们的主要贡献是:1. 据我们所知,在医学成像领域中,我们首次使用 GAN 生成高分辨率的 3D 块及其分割标签。2. 我们利用混合精度提供的内存效率,以启用具有每层双倍滤波器的更复杂的 WGAN 架构。3. 我们生成的标签使我们能够在合成数据上训练用于脑血管分割的 3D U-Net 模型,采用端到端的框架。
Title
题目
Generating 3D TOF-MRA volumes and segmentation labels using generative adversarial networks
用生成对抗网络生成 3D TOF-MRA 体积和分割标签
Methods
方法
2.1. Architecture We adapted the WGAN - Gradient penalty (Gulrajani et al., 2017) model to 3D in order to produce 3D patches and their corresponding labels of brain vessel segmentation. We implemented four variants of the architecture: a) GP model - WGAN-GP model in 3D b) SN model - GP model with spectral normalization in the critic network c) SN-MP model - SN model with mixed precision d) c-SN-MP model - SN-MP model with double the filters per layer. An overview of the GAN training is provided in Fig. 1.For all models, a noise vector (z) of length 128 sampled from a standard Gaussian distribution (N (0, 1)) was input to the Generator G. It was fed through a linear layer and a 3D batch normalization layer, then 3 blocks of upsampling and 3D convolutional layers with consecutive batch normalization and ReLU activation, and a final upsampling and 3D convolutional layer as shown in Fig. 2A. An upsample factor of 2 with nearest neighbor interpolation was used. The convolutional layers used kernel size of 3 and stride of 1. Hyperbolic tangent (tanh) was used as the final activation function. The output of the generator was a two channel image of size 128 × 128 × 64: one channel was the TOF-MRA patch and the second channel was the corresponding label which is the ground truth segmentation of the generated patch. The function of the labels is to train a supervised segmentation model such as a 3D U-Net model with the generated data.
2.1. 架构 我们将 WGAN - 梯度惩罚(Gulrajani 等,2017年)模型调整为 3D,以生成 3D 块及其对应的脑血管分割标签。我们实现了四种架构变体:a) GP 模型 - 3D 中的 WGAN-GP 模型 b) SN 模型 - 批判网络中具有频谱归一化的 GP 模型 c) SN-MP 模型 - 具有混合精度的 SN 模型 d) c-SN-MP 模型 - 具有每层双倍滤波器的 SN-MP 模型。图 1 提供了 GAN 训练的概述。对于所有模型,一个长度为 128 的噪声向量 (z),从标准高斯分布(N(0, 1))中采样,被输入到生成器 G。它通过一个线性层和一个 3D 批处理归一化层,然后是 3 个上采样和 3D 卷积层块,连续的批处理归一化和 ReLU 激活,以及最后的上采样和 3D 卷积层,如图 2A 所示。使用了最近邻插值的 2 倍上采样因子。卷积层使用了 3 的核大小和 1 的步长。双曲正切 (tanh) 被用作最终激活函数。生成器的输出是一个大小为 128 × 128 × 64 的双通道图像:一个通道是 TOF-MRA 块,第二个通道是相应的标签,即生成块的地面真实分割。标签的功能是用生成的数据训练如 3D U-Net 模型之类的监督分割模型。
**Results
**
结果
In the visual analysis, the synthetic patches, labels and the 3D vessel structure from the complex mixed precision model (c-SNMP) appeared as the most realistic (Fig. 4). The patches from the mixed precision models (SN-MP and c-SN-MP) had the lowest FID scores (Table 1), and the best PRD curves (Fig. 5). Based on the PRD curves, the precision of c-SN-MP outperformed SN-MP where the recall values are higher while the precision of SN-MP is higher for lower recall values. Based on the AUC of the PRD curves shown in Table 1, SN-MP and c-SN-MP patches performed similarly.
在视觉分析中,来自复杂混合精度模型(c-SNMP)的合成块、标签和 3D 血管结构看起来最为逼真(图 4)。来自混合精度模型(SN-MP 和 c-SN-MP)的块具有最低的 FID 分数(表 1),以及最佳的 PRD 曲线(图 5)。基于 PRD 曲线,c-SN-MP 的精度优于 SN-MP,其中召回值更高,而在较低召回值时 SN-MP 的精度更高。根据表 1 中显示的 PRD 曲线的 AUC,SN-MP 和 c-SN-MP 块的表现相似。
Conclusions
结论
In this study, we generated high resolution TOF-MRA patches along with their corresponding labels in 3D employing mixed precision for memory efficiency. Since most medical imaging isrecorded in 3D, generating 3D images that retain the volumetric information together with labels that are time-intensive to generate manually is a first step towards sharing labeled data. While our approach is not privacy-preserving yet, the architecture was designed with privacy as a key aspiration. It would be possible to extend it with differential privacy in future works once the computational advancements allow it. This would pave the way for sharing privacy-preserving, labeled 3D imaging data. Research groups could utilize our open source code to implement a mixed precision approach to generate 3D synthetic volumes and labels efficiently and verify if they hold the necessary predictive properties for the specific downstream task. Making such synthetic data available on request would then allow for larger heterogeneous datasets to be used in the future alleviating the typical data shortages in this domain. This will pave the way for robust and replicable model development and will facilitate clinical applications.
在这项研究中,我们利用混合精度生成了高分辨率的 TOF-MRA 块及其相应的 3D 标签,以提高内存效率。由于大多数医学成像是以 3D 形式记录的,因此生成保留体积信息的 3D 图像以及手动生成需要大量时间的标签,是朝着共享标记数据迈出的第一步。虽然我们的方法目前还没有实现隐私保护,但架构的设计考虑了隐私作为一个关键目标。未来的工作中,一旦计算进步允许,可以将其扩展为具有差分隐私。这将为共享具有隐私保护的标记 3D 成像数据铺平道路。研究小组可以利用我们的开源代码实现混合精度方法,有效地生成 3D 合成体积和标签,并验证它们是否具有特定下游任务所需的预测属性。之后,根据需求提供此类合成数据,将允许未来使用更大、更多样化的数据集,缓解这一领域中的典型数据短缺问题。这将为健壮且可复制的模型开发铺平道路,并促进临床应用。
Figure
图
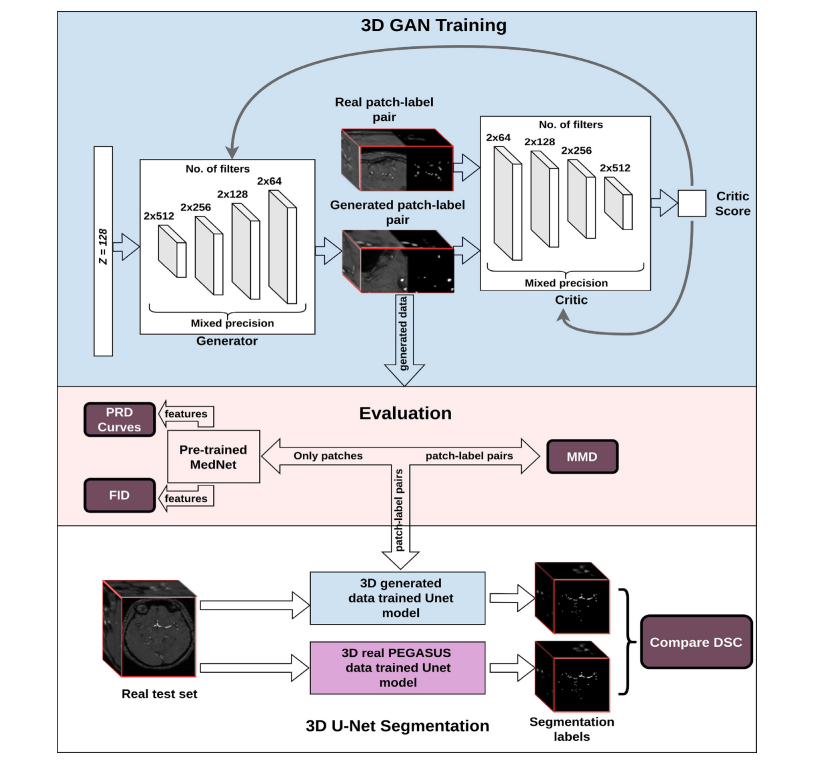
Fig. 1. Structure of the workflow from training the 3D GAN to qualitative and quantitative assessments. Top: Overview of GAN training - Here, we illustrate our most complex model using spectral normalization and mixed precision (c-SN-MP), middle: Evaluation schemes, bottom: Segmentation performance evaluation
图 1. 从训练 3D GAN 到定性和定量评估的工作流程结构。顶部:GAN 训练概览 - 在此,我们展示了我们使用频谱归一化和混合精度的最复杂模型(c-SN-MP),中间:评估方案,底部:分割性能评估。
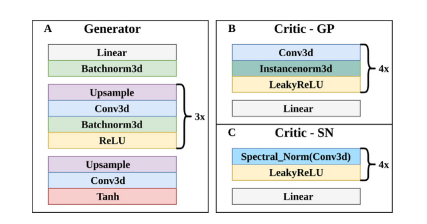
Fig. 2. Architectures of A. Generator of all models, B. Critic of GP model, and C. Critic of all SN models.
图 2. A. 所有模型的生成器架构,B. GP 模型的批判者架构,以及 C. 所有 SN 模型的批判者架构。
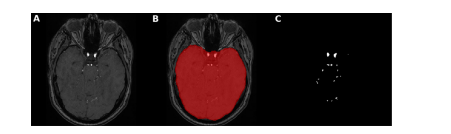
Fig. 3. Brain mask application for intracranial vessels analysis. Here, an axial slice is shown of A. TOF-MRA image with skull B. brain mask extracted using FSL-BET tool from TOF-MRA image C. ground truth segmentation label after brain mask application leading to skull-stripping i.e. removal of all vessels of face and neck with only intracranial vessels remaining
图 3. 用于颅内血管分析的脑部遮罩应用。这里展示了 A. 带有头骨的 TOF-MRA 图像的轴向切片 B. 使用 FSL-BET 工具从 TOF-MRA 图像中提取的脑部遮罩 C. 应用脑部遮罩后的地面真实分割标签,导致去除头骨,即移除面部和颈部的所有血管,只剩下颅内血管。
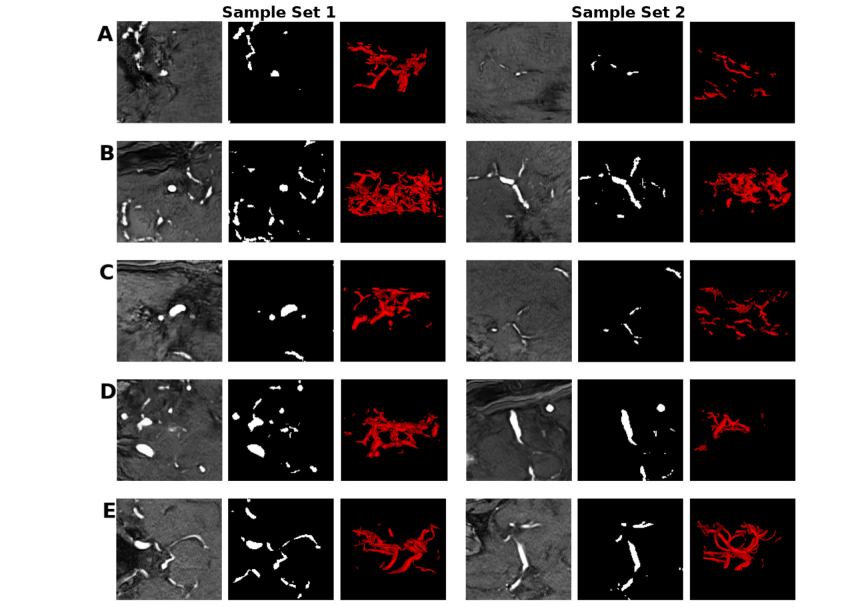
Fig. 4. Sets of samples of the mid-axial slice of the patch and label, and the corresponding 3D vessel structure from A) GP B) SN C) SN-MP D) c-SN-MP and E) real. The visualizations were obtained using ITK-SNAP for illustrative purposes only
图 4. 来自 A) GP B) SN C) SN-MP D) c-SN-MP 和 E) 真实数据的中轴切片块和标签的样本集合,以及相应的 3D 血管结构。这些可视化是使用 ITK-SNAP 仅出于说明目的而获得的。
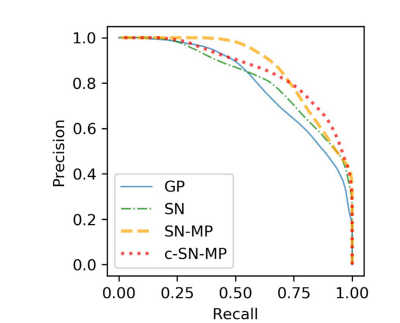
Fig. 5. PRD Curves of synthetic data from the four different models with real data as reference. Precision and Recall in GANs quantify the quality and modes captured by the models respectively
图 5. 四种不同模型合成数据的 PRD 曲线,以真实数据作为参考。GANs 中的精确度和召回率分别量化了模型捕获的质量和模式。
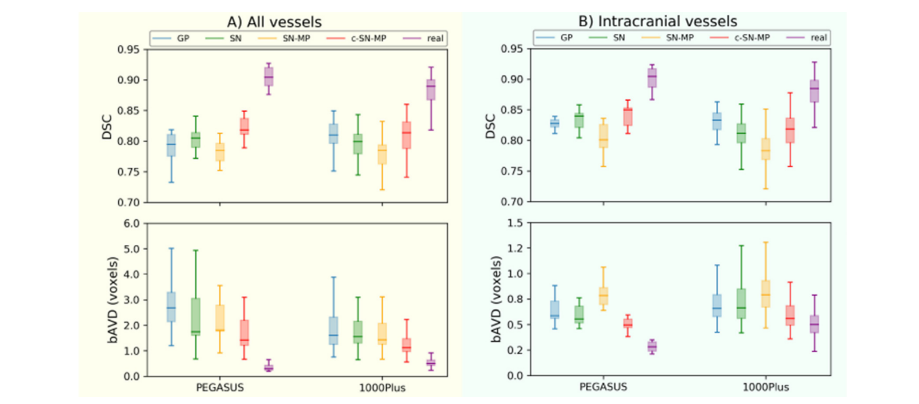
Fig. 6. Segmentation performance (DSC and bAVD) of 3D U-Net models trained with 4 different generated data and PEGASUS training data on the 2 datasets PEGASUS and 1000Plus of A) all vessels B) intracranial vessels. The horizontal line of the box-whisker plots indicates the median, the box indicates the interquartile range and the whiskers the minimum and maximum.
图6使用 4 种不同生成数据和 PEGASUS 训练数据在 PEGASUS 和 1000Plus 两个数据集上训练的 3D U-Net 模型的分割性能(DSC 和 bAVD),涵盖 A) 全部血管 B) 颅内血管。箱形图的水平线表示中位数,箱体表示四分位数范围,而须表示最小值和最大值。
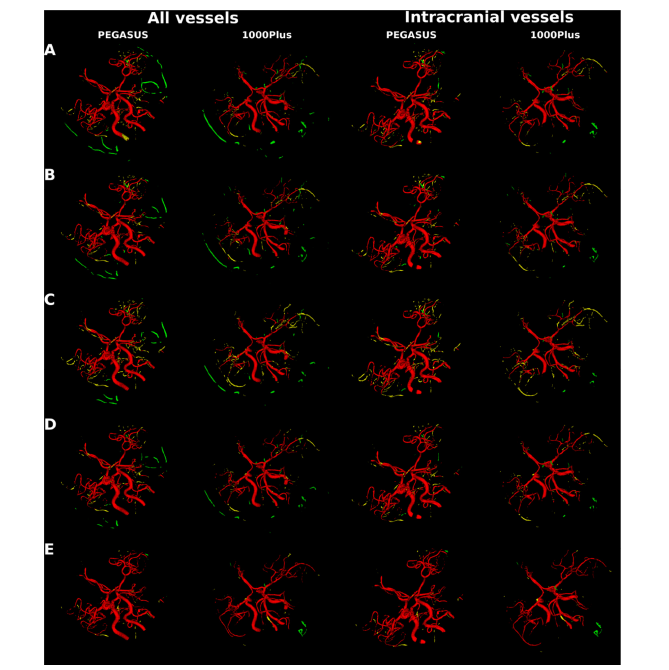
Fig. 7. Segmentation error map of an example patient each from PEGASUS test set and 1000Plus test set for all vessels and for intracranial vessels. Top to bottom maps from 3D U-Net model trained on: A. GP synthetic data B. SN synthetic data C. SN-MP synthetic data D. c-SN-MP synthetic data E. real data. True positives are shown in red, false positives are in green and false negatives in yellow.
图 7. PEGASUS 测试集和 1000Plus 测试集中每个患者的一个例子的所有血管和颅内血管的分割错误图。从上到下的地图来自于在以下数据上训练的 3D U-Net 模型:A. GP 合成数据 B. SN 合成数据 C. SN-MP 合成数据 D. c-SN-MP 合成数据 E. 真实数据。正确的阳性显示为红色,错误的阳性为绿色,错误的阴性为黄色。
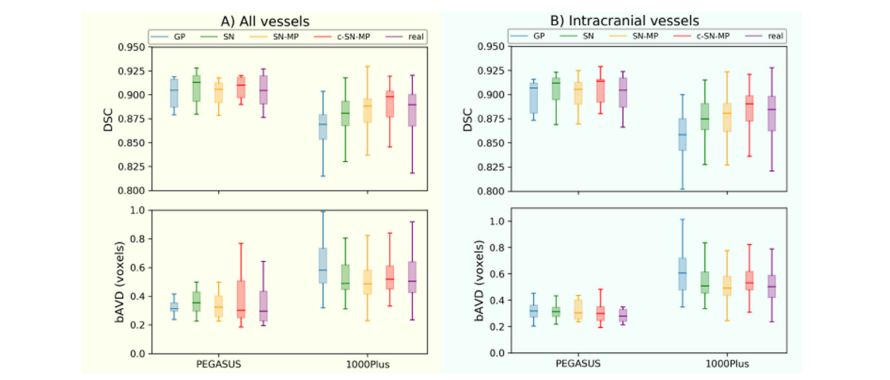
Fig. A.1. Segmentation performance (DSC and bAVD) of 3D U-Net models trained with PEGASUS training data together with 4 different generated data as data augmentation on the 2 datasets PEGASUS and 1000Plus of A) all vessels B) intracranial vessels. The horizontal line of the box-whisker plots indicates the median, the box indicates the interquartile range and the whiskers the minimum and maximum.
图 A.1. 使用 PEGASUS 训练数据与 4 种不同生成数据作为数据增强,在 PEGASUS 和 1000Plus 两个数据集上训练的 3D U-Net 模型的分割性能(DSC 和 bAVD),涵盖 A) 全部血管 B) 颅内血管。箱形图的水平线表示中位数,箱体表示四分位数范围,而须表示最小值和最大值。
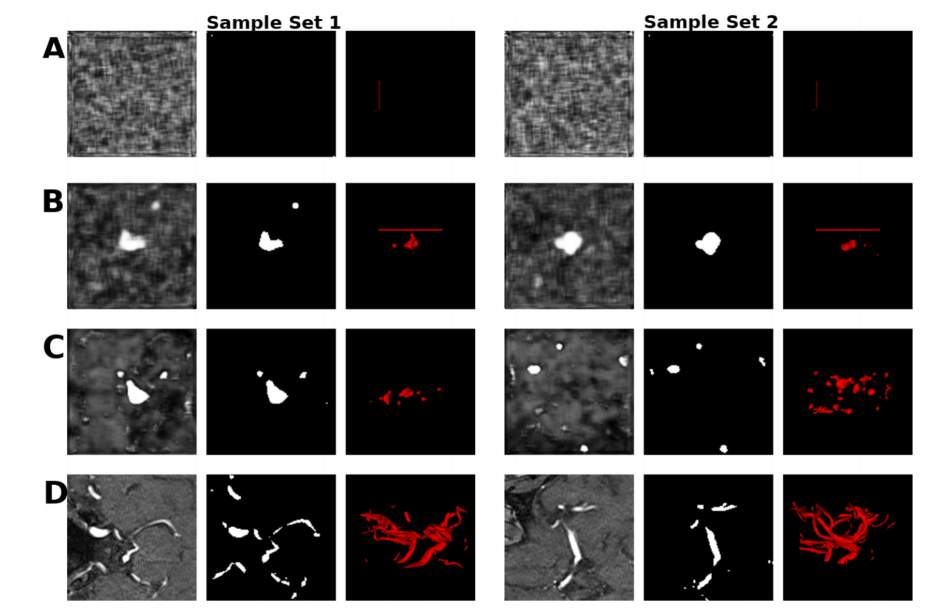
Fig. B.1. Sets of samples of the mid-axial slice of the patch and label, and the corresponding 3D vessel structure from A) DPGAN ≈ 102 B) DPGAN ≈ 103 C) DPGAN ≈ 106 D) real. Note that lower the higher the privacy. The visualizations were obtained using ITK-SNAP for illustrative purposes only.
图 B.1. 中轴切片的块和标签样本集合,以及来自 A) DPGAN ≈ 102 B) DPGAN ≈ 103 C) DPGAN ≈ 106 D) 真实数据的相应 3D 血管结构。请注意,数值越低,隐私保护程度越高。这些可视化仅使用 ITK-SNAP 出于说明目的而获得。
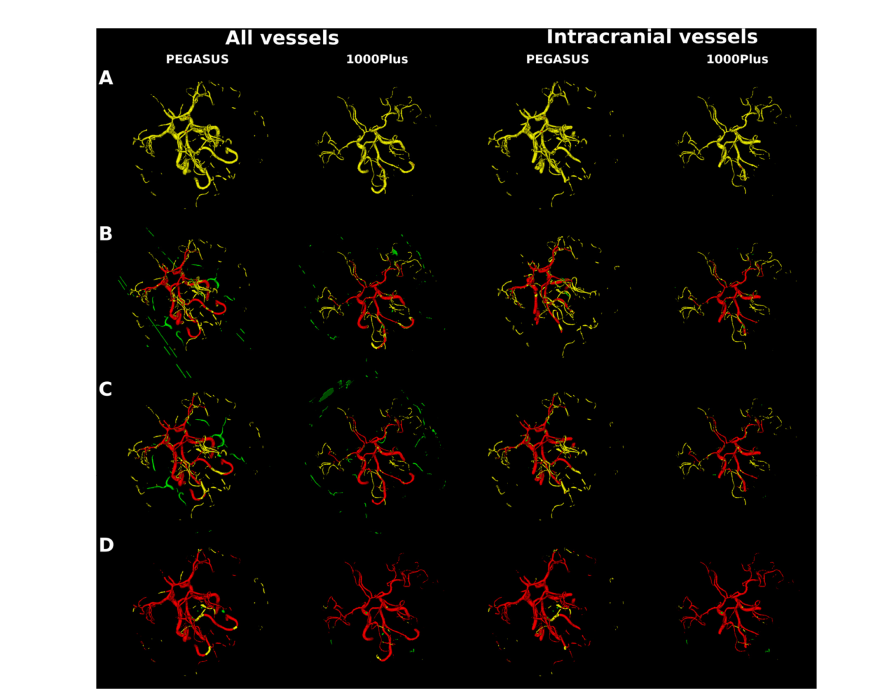
Fig. B.2. Segmentation error map of an example patient each from PEGASUS test set and 1000Plus test set for all vessels and for intracranial vessels. Top to bottom maps from 3D U-Net model trained on: A. DPGAN ≈ 102 B. DPGAN ≈ 103 C. DPGAN ≈ 106 D. real data. True positives are shown in red, false positives are in green and false negatives in yellow、
图 B.2. PEGASUS 测试集和 1000Plus 测试集中每个患者的一个例子的所有血管和颅内血管的分割错误图。从上到下的地图来自于在以下数据上训练的 3D U-Net 模型:A. DPGAN ≈ 102 B. DPGAN ≈ 103 C. DPGAN ≈ 106 D. 真实数据。正确的阳性显示为红色,错误的阳性为绿色,错误的阴性为黄色。
Table
表
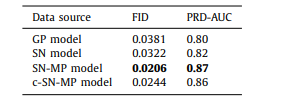
Table 1 FID scores and AUC of the PRD curves for synthetic data from different models.
表 1 不同模型合成数据的 FID 分数和 PRD 曲线的 AUC。

Table 2 Total number of trainable parameters, memory consumption and training times of various 3D GAN models. Note that c-SN-MP, which is our complex mixed precision model, uses twice the number of filters per layer leading to doubling of the trainable parameters compared to non-complex models. The memory consumption increased by 1.5 times compared to the SN model allowing it to be accommodated in the limited memory of our computational infrastructure. The training time also increased by 2.5 times but it was not a constraint in our study
表 2 各种 3D GAN 模型的可训练参数总数、内存消耗和训练时间。请注意,我们的复杂混合精度模型 c-SN-MP 每层使用了两倍数量的滤波器,与非复杂模型相比,可训练参数数量增加了一倍。与 SN 模型相比,内存消耗增加了 1.5 倍,使其能够适应我们计算基础设施的有限内存。训练时间也增加了 2.5 倍,但在我们的研究中这不是一个限制。
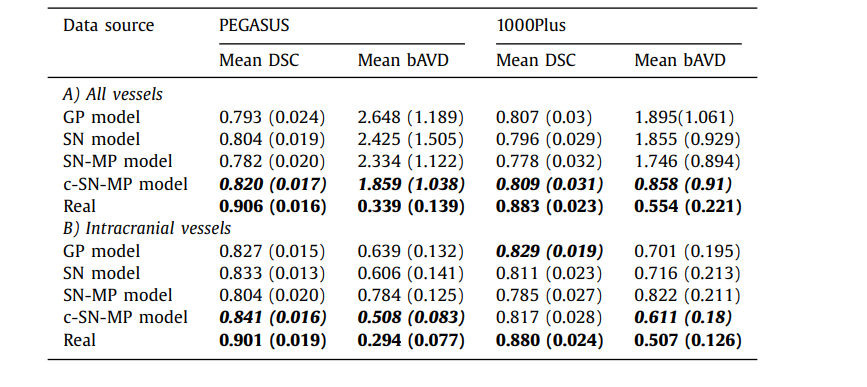
Table 3 The mean DSC and mean bAVD (in voxels) across all the patients in the test set for 2 different datasets PEGASUS and 1000Plus. The value in brackets is the standard deviation across patients. A) All vessels is done on the entire prediction with the entire ground truth as reference, and B) Intracranial vessels is done on skull-stripped prediction with skullstripped ground truth as reference.
表 3 在测试集中所有患者的平均 DSC 和平均 bAVD(以体素计)针对两个不同的数据集 PEGASUS 和 1000Plus。括号中的值是患者间的标准偏差。A) 全部血管是基于整个预测与整个地面真实作为参考进行的,而 B) 颅内血管是基于去除头骨的预测与去除头骨的地面真实作为参考进行的。
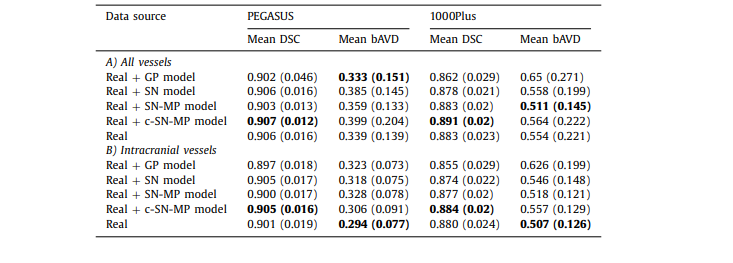
Table A.1 The mean DSC and mean bAVD (in voxels) across all the patients in the test set for 2 different datasets PEGASUS and 1000Plus using model trained with real data along with generated data used as data augmentation. The value in brackets is the standard deviation across patients. A) All vessels is done on the entire prediction with the entire ground truth as reference, and B) Intracranial vessels is done on skull-stripped prediction with skull-stripped ground truth as reference
表 A.1 在测试集中所有患者的平均 DSC 和平均 bAVD(以体素计)针对两个不同的数据集 PEGASUS 和 1000Plus,使用与真实数据一起训练的模型,同时生成的数据用作数据增强。括号中的值是患者间的标准偏差。A) 全部血管是基于整个预测与整个地面真实作为参考进行的,而 B) 颅内血管是基于去除头骨的预测与去除头骨的地面真实作为参考进行的。
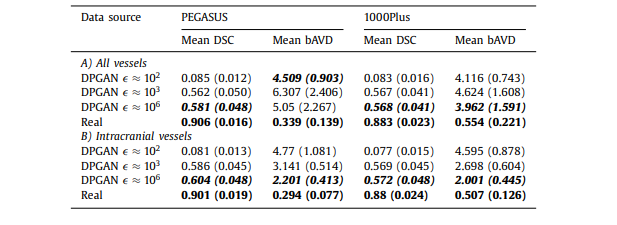
Table B.1 The mean DSC and mean bAVD (in voxels) across all the patients in the test set for 2 different datasets PEGASUS and 1000Plus using model trained with generated data from 3D DPGAN with different values - starting from low value indicating high privacy to the high value indicating low privacy. The value in brackets is the standard deviation across patients. A) All vessels is done on the entire prediction with the entire ground truth as reference, and B) Intracranial vessels is done on skull-stripped prediction with skull-stripped ground truth as reference
All vessels is done on the entire prediction with the entire ground truth as reference, and B) Intracranial vessels is done on skull-stripped prediction with skull-stripped ground truth as reference*
表 B.1 在测试集中所有患者的平均 DSC 和平均 bAVD(以体素计)针对两个不同的数据集 PEGASUS 和 1000Plus,使用从具有不同 值的 3D DPGAN 生成的数据训练的模型,从表示高隐私的低 值到表示低隐私的高 值。括号中的值是患者间的标准偏差。A) 全部血管是基于整个预测与整个地面真实作为参考进行的,而 B) 颅内血管是基于去除头骨的预测与去除头骨的地面真实作为参考进行的。





)



)









