朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux自动化构建代码make/makefile的使用,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C 语 言 专 栏:C语言:从入门到精通
数据结构专栏:数据结构
个 人 主 页 :stackY、
C + + 专 栏 :C++
Linux 专 栏 :Linux

目录
1. 背景
2. 实例代码
2.1 依赖关系
2.2 依赖方法
3. 项目清理
4. 原理
4.1 stat指令
4.2 文件的ACM时间
4.3 touch指令拓展
1. 背景
- 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
2. 实例代码
首先先实现一个简单的makefile,通过这个我们再来逐步理解:
①首先实现一个简单的源文件:test.c
②然后创建一个自动化构建代码的文件:Makefile
③再使用vim Makefile自动化构建代码
④在命令行输入make形成可执行程序
⑤ ./test运行可执行程序
下面我们就来逐一看看Makefile中每一行都表示什么意思:
2.1 依赖关系
test文件依赖的是test.c文件
也就是说要形成test文件就必须要有test.c文件
2.2 依赖方法
要形成test文件就必须要有test.c文件
那么依赖方法就是通过这种方法形成test
在现实中,依赖关系 + 依赖方法也就构成了描述清楚一件事情的原因和做法,能达到我们的目标。
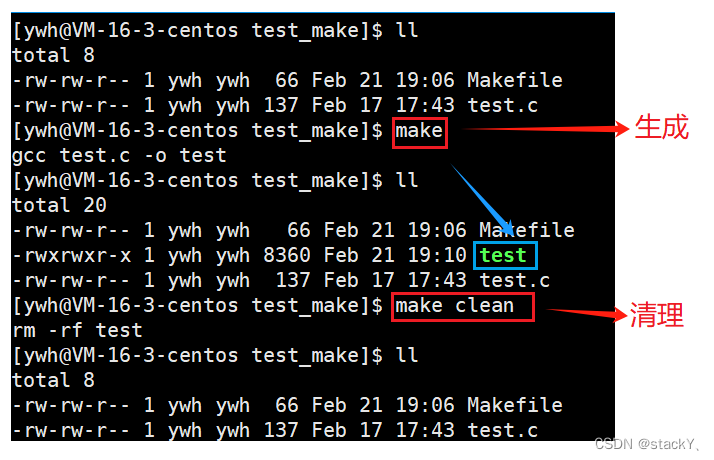
3. 项目清理
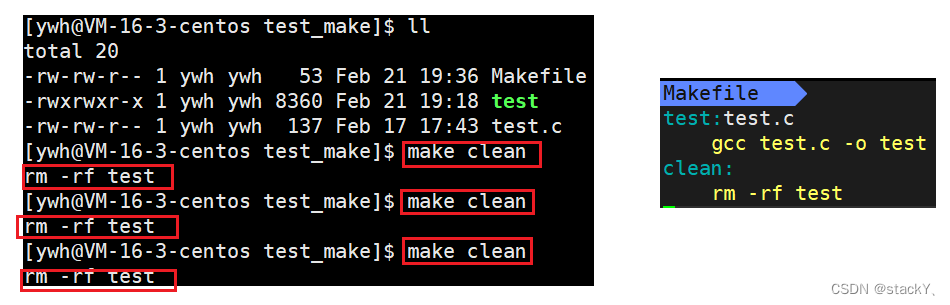
当我们使用make形成可执行程序之后就可以运行了,但是,如果再要使用make时就需要提前删除掉原来形成了可执行程序,需要使用到rm命令,如果我们要多次修改、多次编译、多次删除,rm命令就显得非常臃肿,因为太麻烦,所以在我们的Makefile中还需要存在自动清理项目的功能:
- 像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要make执行。即命令——“make clean”,以此来清除所有的目标文件,以便重编译。
- 但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是,总是被执行的。
- 可以将我们的 test 目标文件声明成伪目标,测试一下。
test:test.cgcc test.c -o test .PHONY:clean clean:rm -rf test
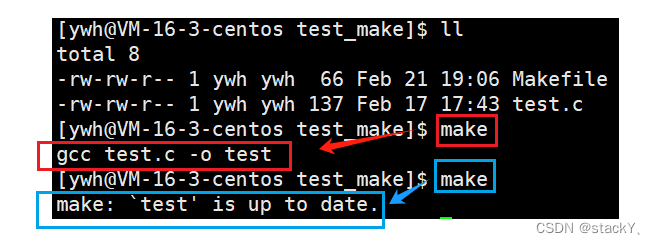
那么为什么我们生成可执行程序时只需要使用make,而在项目清理时需要使用make clean,如果我们make时加上目标文件呢?
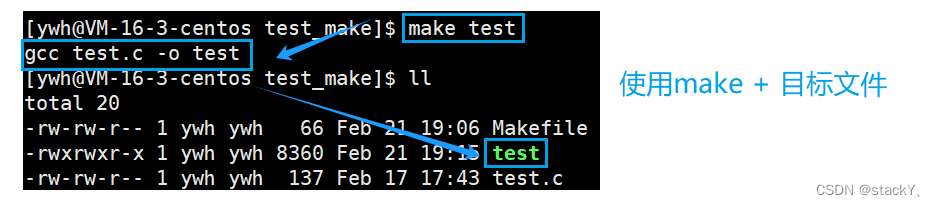
可以看到make + 目标文件也是可以形成可执行程序的,那就说明make后面是可以加上一定的指令的,如果我们将Makefile中的程序生成与项目清理调换一下位置呢?会发生什么呢?
.PHONY:clean clean:rm -rf test test:test.cgcc test.c -o test
可以看到将两个位置调换之后使用make默认会执行项目清理功能,那么简单的说就是在make时会自顶向下进行扫描,谁在前,就先执行谁,我们在写Makefile时一般将项目生成写在前面。
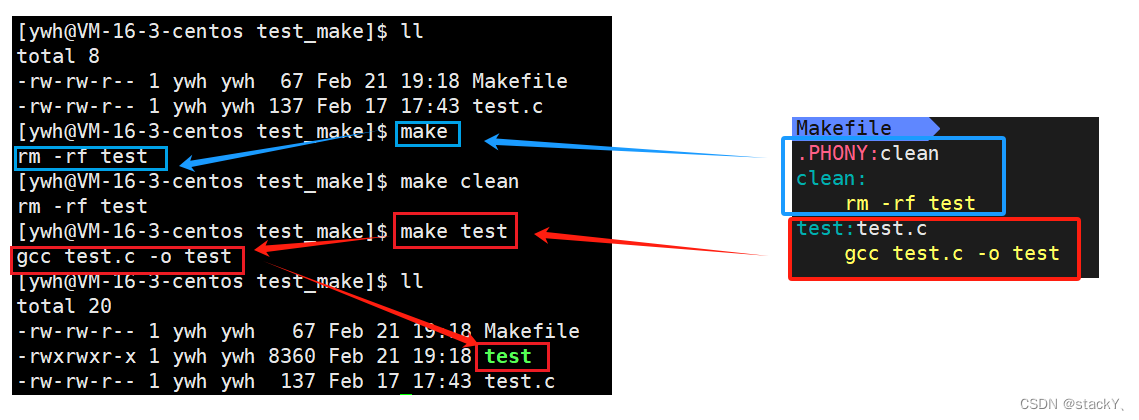
使用.PHONY设置clean为伪目标有什么用呢?
那我们不设置又会发生什么呢?
test:test.cgcc test.c -o test clean:rm -rf test
可以看到我们即使不设置伪目标没有发现什么异常,如果我们将test也设置为伪目标会发生什么呢?
当我们将test设置为为目标之后,可以发现,即使存在目标可执行程序,也会再被强制的执行一次,所以设置伪目标就是该程序总是被执行(依赖方法总是会执行,不会被任何情况拦截)

4. 原理
make是如何工作的,在默认的方式下,也就是我们只输入make命令之后,如何将源文件通过一系列转化形成可执行文件:
- 1. make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 2. 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“test”这个文件,并把这个文件作为最终的目标文件。
- 3. 如果test文件不存在,或是test所依赖的后面的test.c文件的文件修改时间要比test这个文件新(可以用 touch 测试),那么,他就会执行后面所定义的命令来生成hello这个文件。
- 4. 如果test所依赖的test.c文件不存在,那么make会在当前文件中找目标为hello.o文件的依赖性,如果找到则再根据那一个规则生成test.c文件。(这有点像一个堆栈的过程)
- 5. 当然,你的C文件和H文件是存在的啦,于是make会生成 test.c 文件,然后再用 test.c 文件声明make的终极任务,也就是执行文件test了。
- 6. 这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 7. 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
- 8. make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么就不会进行下一步的操作了!
当我们使用make时,如果存在目标可执行程序,那么make会失败,为什么呢?因为使用make/Makefile就是为了提高编译效率,一直重复的多次编译是一种非常多余的操作,因为编译的过程并不简单,如果我们存在上千个源代码,编译一次就已经够费劲了,一直重复的编译是非常没有必要的,当我们对源文件的内容进行修改之后,使用make是可以通过的,那么就说明make会自动识别我们编译的文件的新旧,那它是怎么做到的呢?
我们在编写源文件代码时,不仅仅文件内容在改变,文件的属性同样的也在改变,那么最具有代表的就是文件的修改时间,那么时间毕竟只是时间,怎么通过时间来判断文件的新旧呢?
时间其实不是本质,通过时间对比出来文件的新旧才是本质,那么我我们所写的源文件跟谁的时间去比较才能体现源文件的新旧呢?
源文件存在的目的就是为了形成可执行程序,那么可执行程序同样的也是一个文件,重新编译的本质就是重新写入一个二进制文件,同时附带的修改时间也会改变!
第一次的时候:一定是现有源文件,再有目标可执行程序文件,所以源文件的修改时间一定是小于目标可执行程序文件;
第二/n次的时候:我们对我们的源文件进行修改时,源文件的修改时间就大于了目标可执行程序文件。
此时,就形成新的源文件和旧的目标可执行文件,当我们对新的源文件重新编译之后,形成的目标可执行程序文件的修改时间又大于源文件的修改时间,就又回到了第一次的情形,所以,当源文件的修改时间大于目标可执行程序文件修改时间时我们就可以重新编译。
4.1 stat指令
上面关于新旧问题以及文件的修改时间说了这么多,那么怎么在Linux上看见呢?
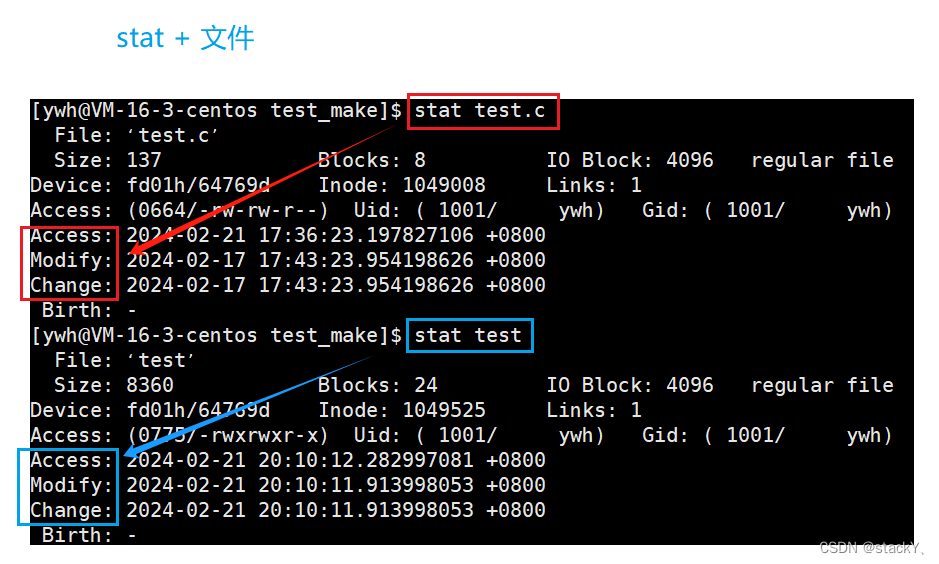
stat 文件: 查看该文件属性(包含关于文件的各种时间)
4.2 文件的ACM时间
在上面我们使用stat指令查看到的文件的各种属性,里面有三个时间:
Access、 Modify、Change
那么这三个时间该怎么理解呢?
文件 = 内容 + 属性
①Access: 2024-02-21 17:36:23.197827106 +0800
文件的最近访问时间
②Modify: 2024-02-17 17:43:23.954198626 +0800文件的最近修改时间,具体指的是对文件内容做修改
③Change: 2024-02-17 17:43:23.954198626 +0800文件的最近改变时间,具体指的是对文件属性做修改
通过修改文件的内容,在源文件中写入、删除代码都可以改变Modify时间;
使用chmod可以对文件的权限做修改,也就可以改变Change时间;
我们重点来看一些Access时间:
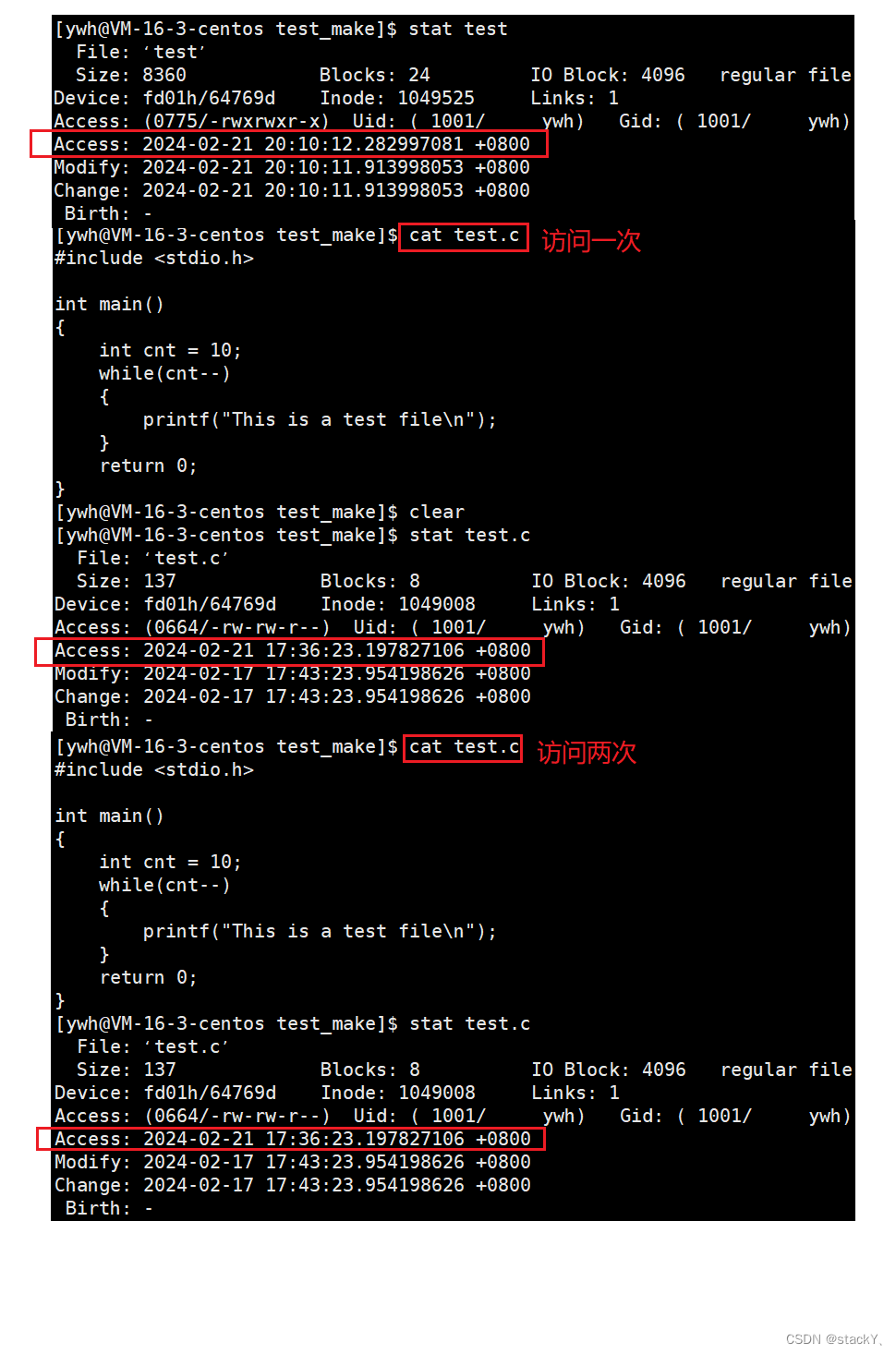
Access时间表示的是最近一次的访问时间,那么我们可以实现一下,使用cat命令打印一下文件内容,看一下它是否发生变化:
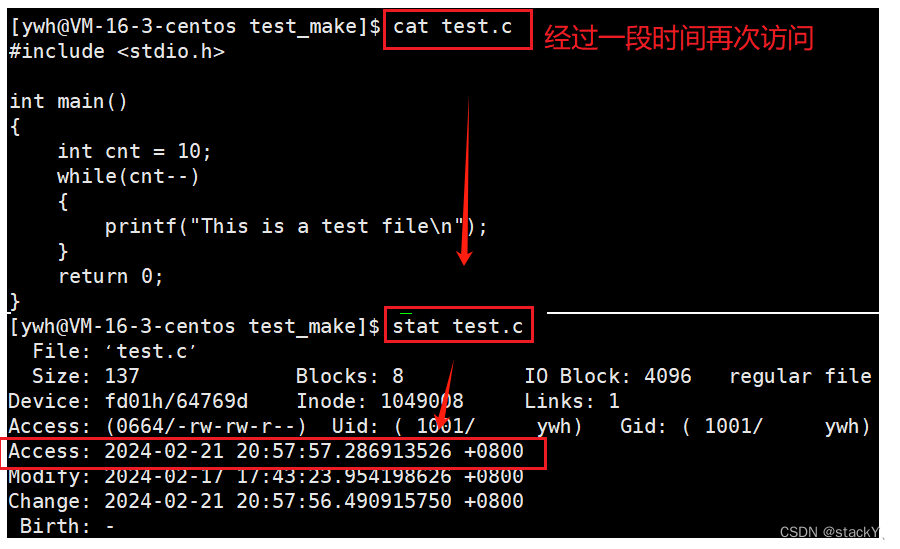
可以发现我们在短时间内多次访问文件,文件的Access时间并不会多次改变只会改变一次,当我们过一段时间之后再次访问文件,它的Access时间才会更改:
那这是为什么呢?
一般而言,一个文件被访问的频率是极高的,然后我们所看到的文件都是储存在磁盘中的,文件 = 内容 + 属性,我们更改文件时间的本质就是访问磁盘,由于访问磁盘的效率是比较低下的,如果我们短时间内每一次访问文件都需要更改文件的Access时间,这样就会导致Linux系统内充满大量的访问磁盘的IO操作,变相的减慢系统的效率,所以在不同的内核中,对于更改Access时间添加了次数限制。
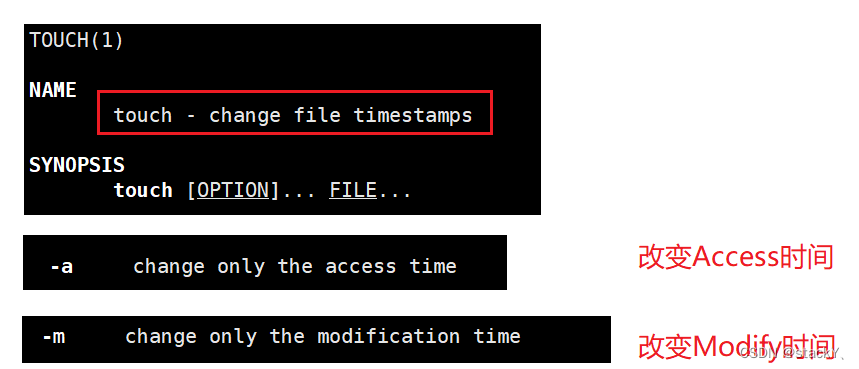
4.3 touch指令拓展
touch命令在前面的章节中简单介绍过,是创建空文件的指令,那么在今天,它可以改变文件的时间属性:
朋友们、伙计们,美好的时光总是短暂的,我们本期的的分享就到此结束,欲知后事如何,请听下回分解~,最后看完别忘了留下你们弥足珍贵的三连喔,感谢大家的支持!







![洛谷 P2866 [USACO06NOV] Bad Hair Day S (Java)](http://pic.xiahunao.cn/洛谷 P2866 [USACO06NOV] Bad Hair Day S (Java))
![[C++]声明和定义全局变量](http://pic.xiahunao.cn/[C++]声明和定义全局变量)







——while循环)


