 | 博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维码进入京东手机购书页面。 |
文章目录
- 1. 下载与安装
- 2. 创建 Test Plan
- 3. 创建 Thread Group
- 4. 添加 MySQL JDBC Connection 配置
- 4. 添加 JDBC Request Sampler
- 5. 添加 View Results Tree
- 6. 执行测试计划
- 7. 已知错误
- 8. 附录
数据库的压测工具和方法有很多,最简单的方法无非是编写脚本自动执行 INSERT INTO 语句,也有专门的 GUI 工具可以图形化配置测试计划,例如:Data Generator for MySQL 和 EMS Data Generator for MySQL 等,不过,绝大多数的图形化工具都是付费的。
实际上,对数据库的压测,也包括其他类型的压测,最主要的工作是:如何能简单地生成压测数据(Dummy Data),除了要生成与数据类型相符的字面量之外,更多的是要能控制好数据的取值范围,特别地,在数据库的压测中,受外键约束的影响,对于外键列的取值更不能使用随机值。
考虑到写脚本太麻烦,图形化工具收费还不通用,所以,我们还是选择使用老牌的压力测试工具:Apache JMeter,除了它内置了丰富的随机值生成方法外,还因为它是一个统一的压测平台,操作和配置都和其他类型的压测一致。
备注:本文以 Debezium 官方提供的 MySQL Docker镜像 中的 Inventory 数据库为示例介绍和演示压测步骤。
1. 下载与安装
JMeter 官方下载: https://jmeter.apache.org/download_jmeter.cgi
提示:在 Windows 下,请运行 ${JMETER_HOME}/bin/jmeterw.cmd (运行 jmeter.bat 会多打开一个 console 窗口)
MySQL JDBC Driver 官方下载:https://dev.mysql.com/downloads/connector/j/
解压 zip 包获得里面的 jar 包,将 jar 包放置到 ${JMETER_HOME}/lib 目录下
2. 创建 Test Plan
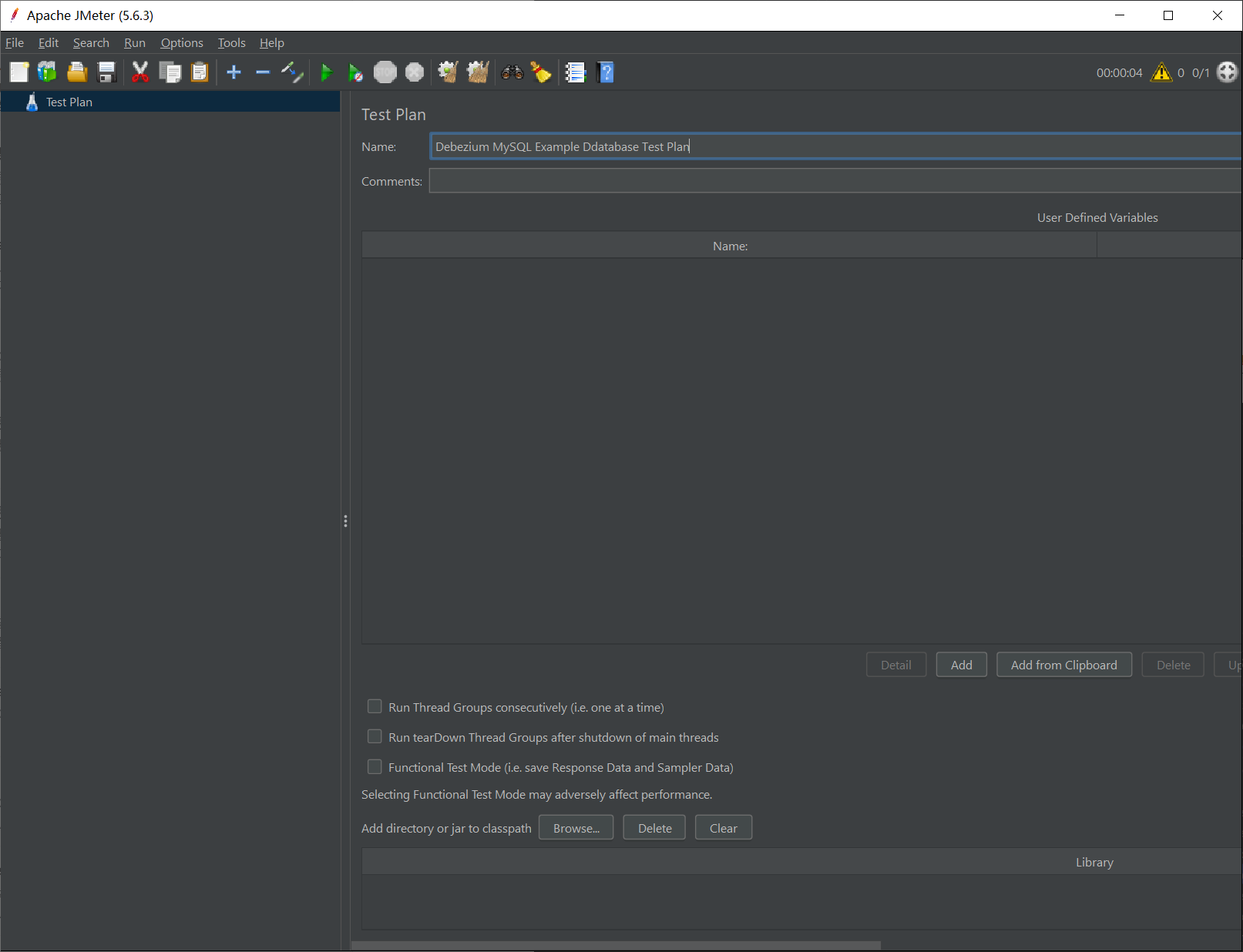
打开 JMeter 时,默认会自动创建一个空的 Test Plan,我们将其重命名为:Debezium MySQL Example Ddatabase Test Plan
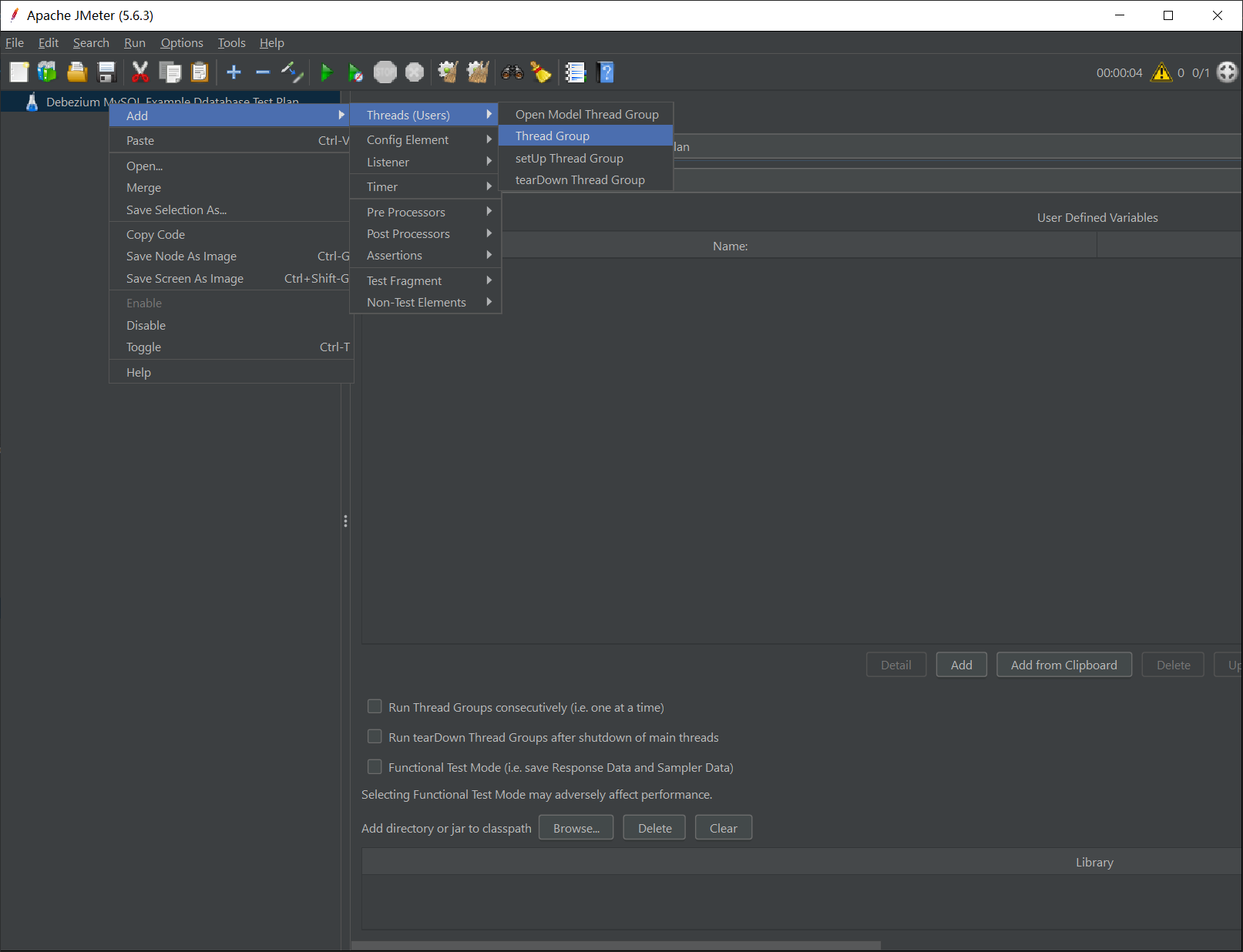
3. 创建 Thread Group
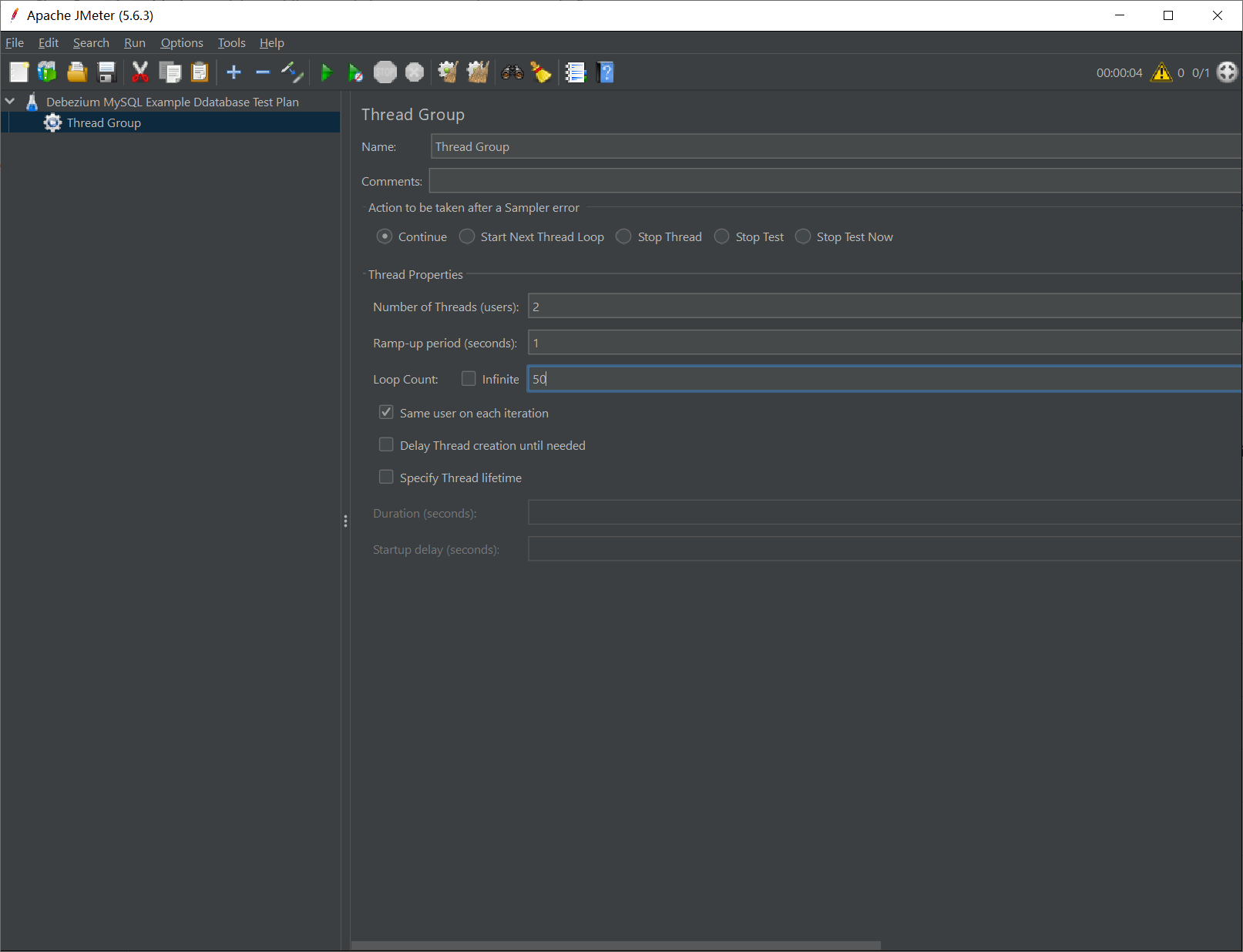
在刚创建的 Test Plan 上单击右键打开菜单,添加一个 Thread Group,其中 Number of Threads (users) 是并行的线程数,Loop Count 是重复执行的次数,假设我们的压测内容是插入一条数据,则执行一次 Thread Group 插入的记录数是两者的乘积。本例中,该测试计划将会插入 2 * 50 = 100 记录。
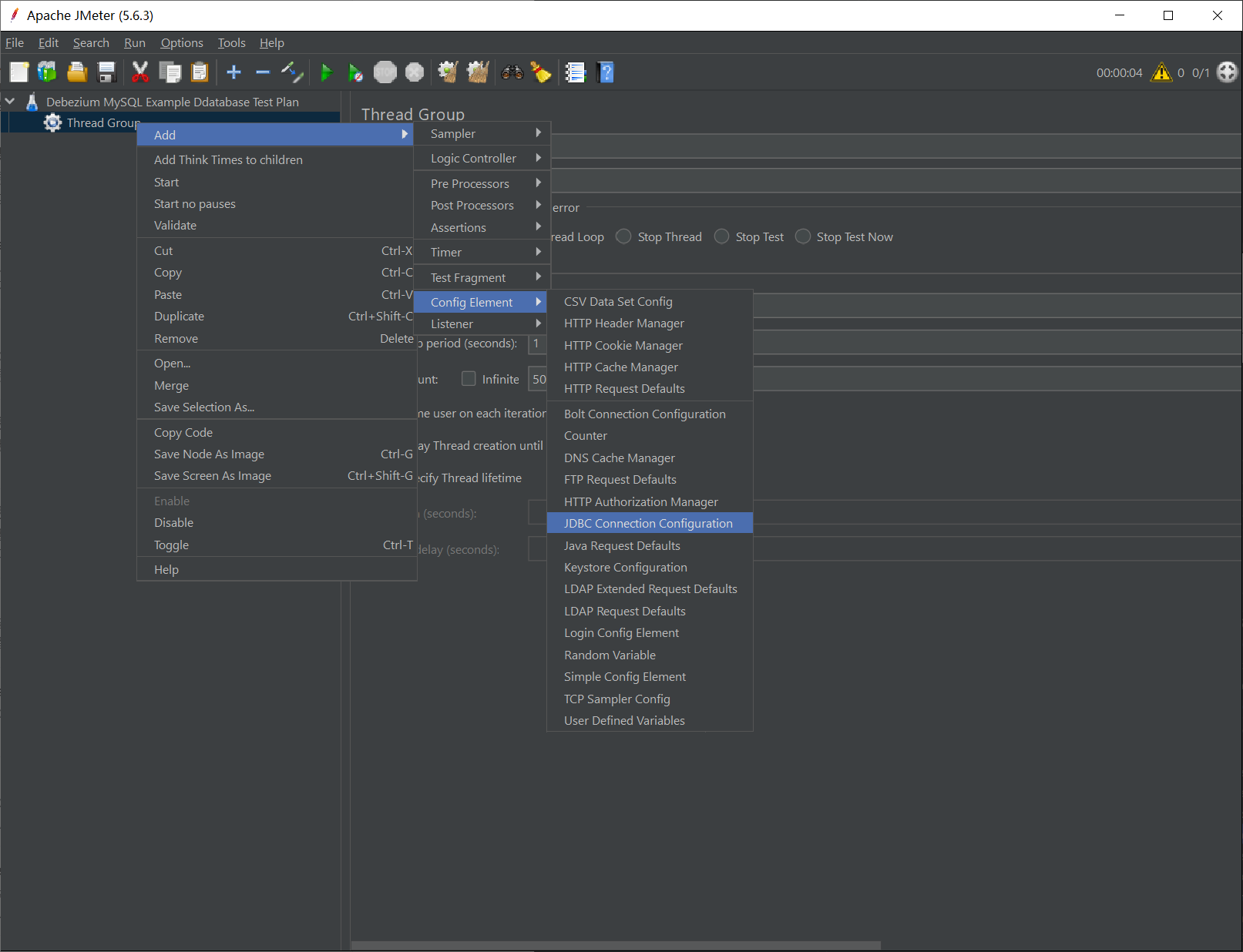
4. 添加 MySQL JDBC Connection 配置
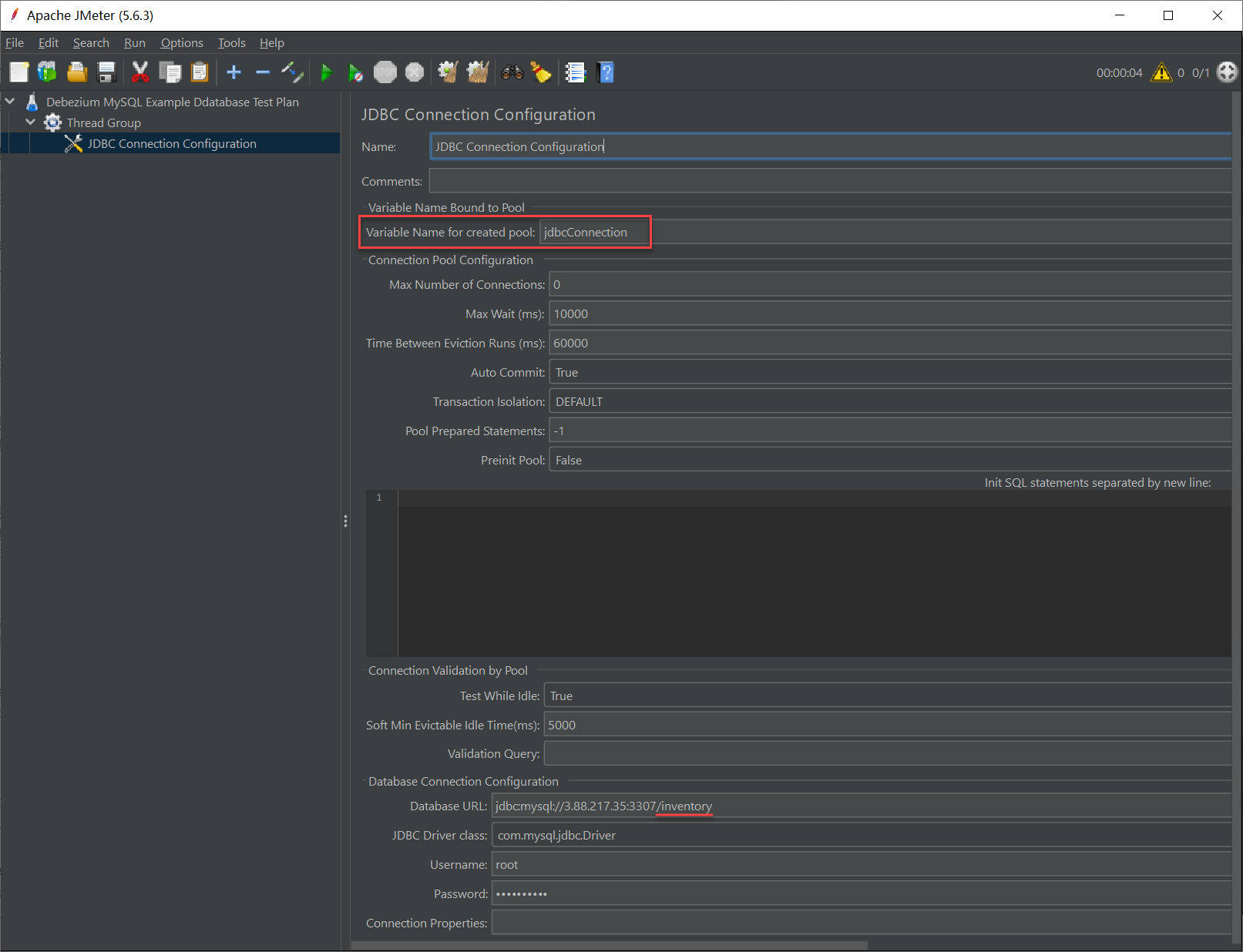
为使 JMeter 能联通 MySQL 数据库,测试计划的第一步就是创建 JDBC 连接的配置。在刚创建的 Test Group 上单击右键打开菜单,添加一个 JDBC Connection Configrutation,这里有两点需要注意:
- JMeter 要求 JDBC 的 URL 必须指定数据库名,否则执行时会报错
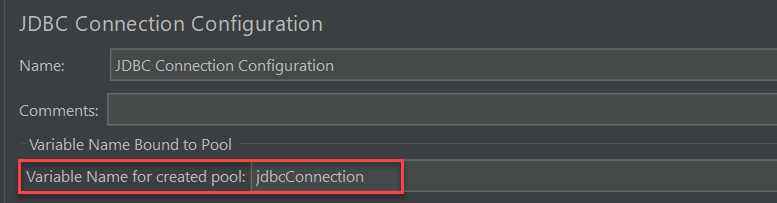
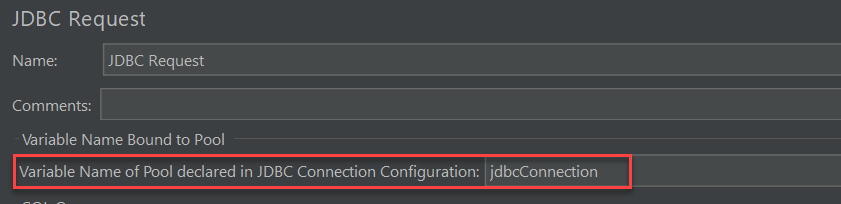
- 必须配置 Variable Name for created pool,否则执行时会报错
4. 添加 JDBC Request Sampler
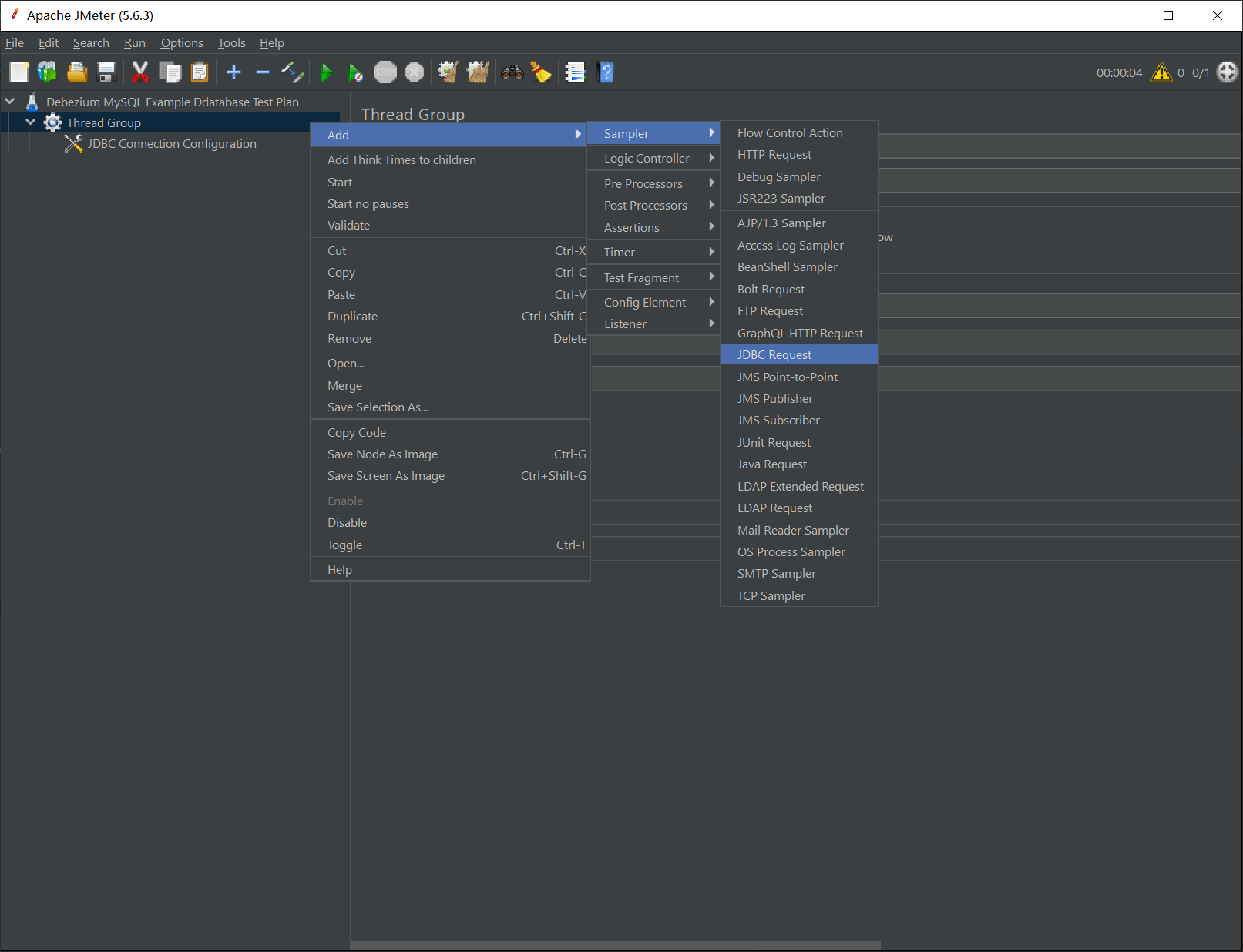
JMeter 负责向数据库发送 SQL 的组件是:JDBC Request Sampler,所以我们要创建一个 JDBC Request Sampler 并填入相应的 SQL 语句,在刚创建的 Test Group 上单击右键打开菜单,添加一个 JDBC Request:
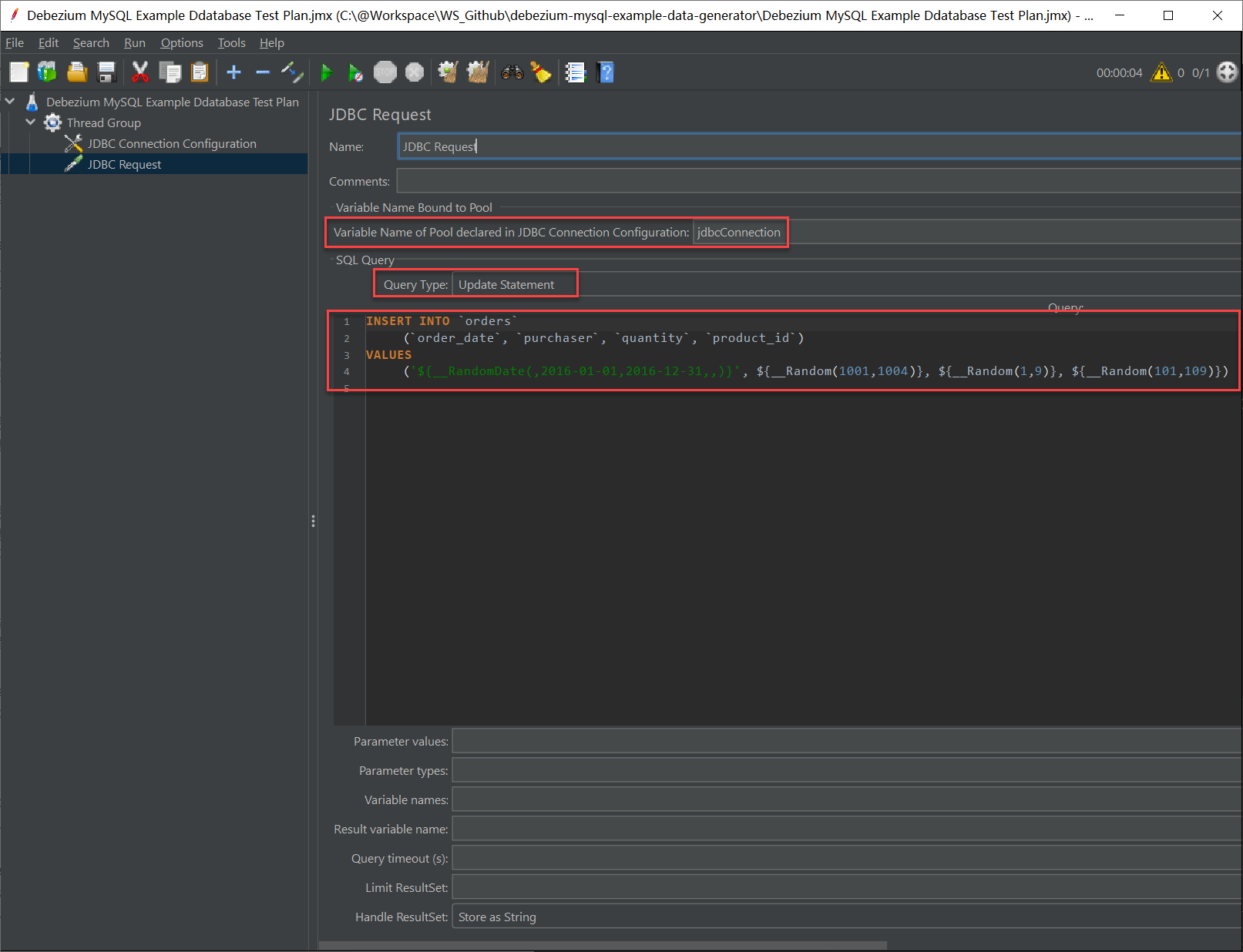
在这里,Query Typle 选择 Upate Statement (这是 JDBC 中的 API),填入的 SQL 是整个测试计划中最核心的部分,所有的动态变量、取值范围等细节,都通过这条 SQL 实现了,因为我们使用了 JMeter 的函数和变量来生成期望的数值!
INSERT INTO `orders` (`order_date`, `purchaser`, `quantity`, `product_id`)
VALUES('${__RandomDate(,2016-01-01,2016-12-31,,)}', ${__Random(1001,1004)}, ${__Random(1,9)}, ${__Random(101,109)})
关于${__RandomDate(,2016-01-01,2016-12-31,,)} 和 ${__Random(1001,1004)} 这些 JMeter 的函数,请移步 JMeter 官方文档:https://jmeter.apache.org/usermanual/functions.html ,这里有细致地解释。
5. 添加 View Results Tree
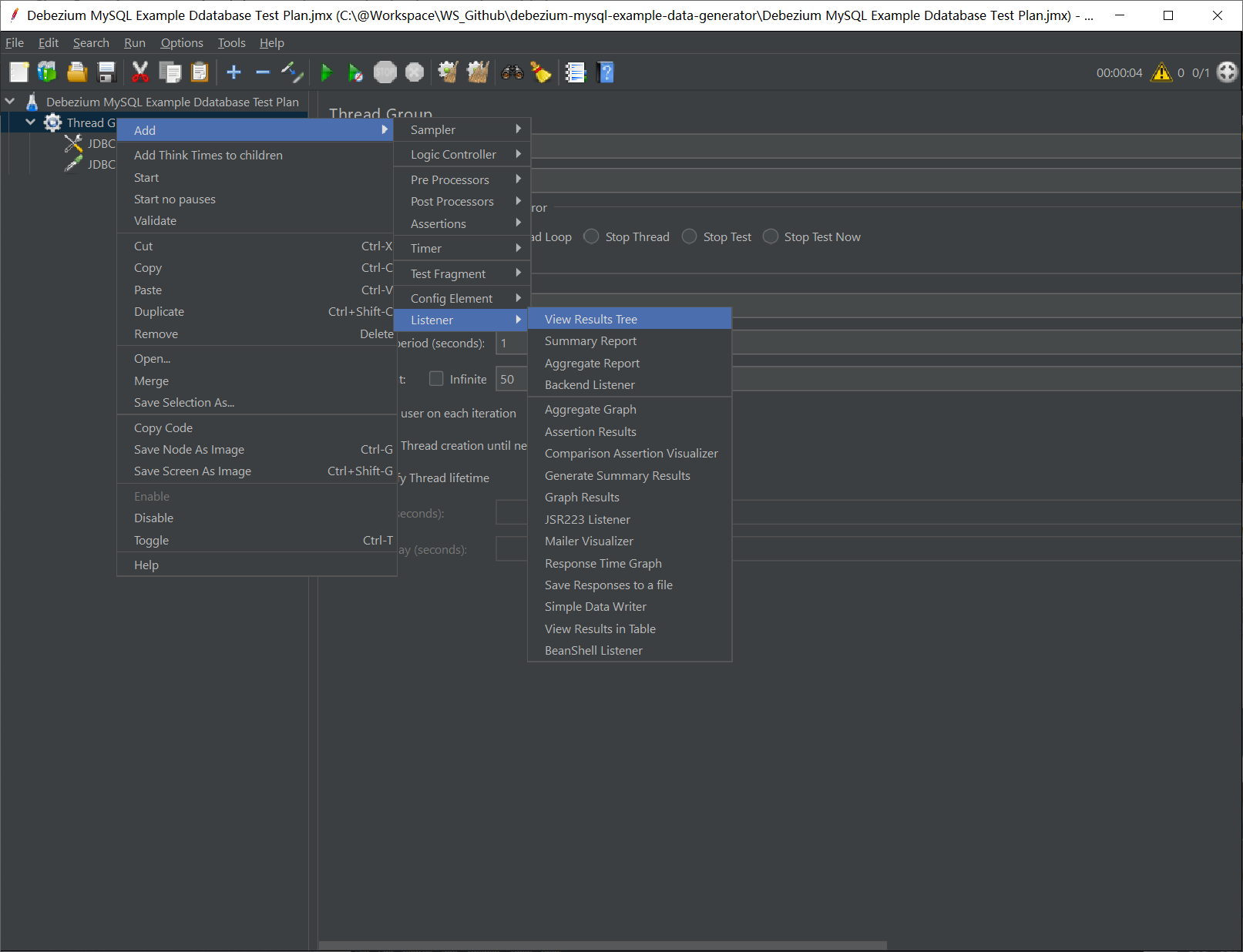
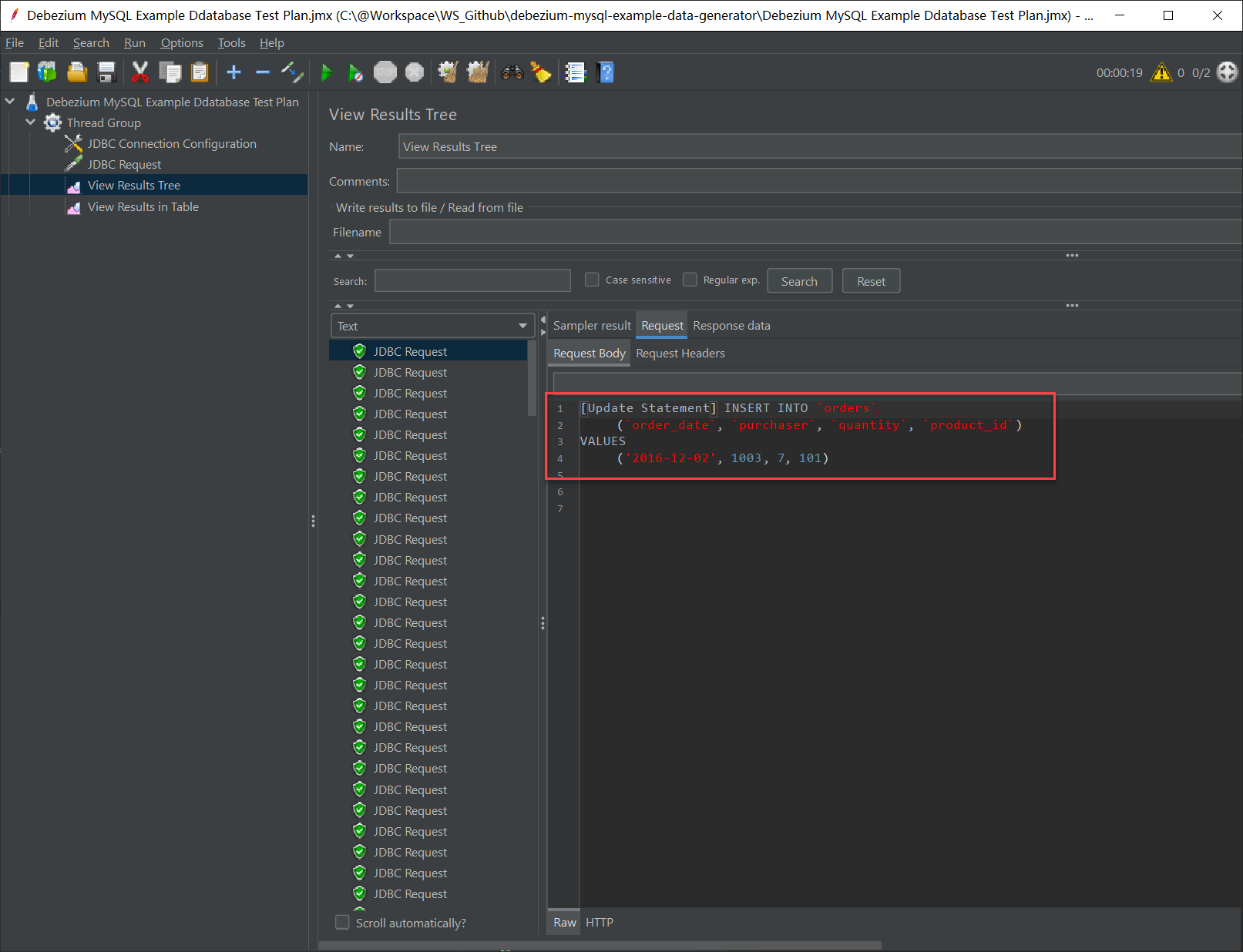
View Results Tree 是用来查看执行结果的,在配置或执行过程中出错的话,可以在这里看到发送的请求和详细错误,是很有必要配置的一个组件。在刚创建的 Test Group 上单击右键打开菜单,添加一个 View Results Tree 即可,无需特别配置。
6. 执行测试计划
完成上述配置后,就可以执行测试计划了,点击工具栏中的 “绿色开始按钮”,等待测试计划执行完毕,然后打开 View Results Tree 可以看到每次测试的详细情况,包括是否执行成功、发送的请求内容和得到的响应。如果初始尝试没有成功,可以在这里找到详细的错误信息,从而帮助定位问题并解决。
7. 已知错误
1. Name for DataSoure must not be empty in JDBC Connection Configuration
执行测试计划时,JMeter 报错:
java.lang.IllegalArgumentException: Name for DataSoure must not be empty in JDBC Connection Configurationat org.apache.jmeter.protocol.jdbc.config.DataSourceElement.testStarted(DataSourceElement.java:119) ~[ApacheJMeter_jdbc.jar:5.6.3]at org.apache.jmeter.engine.StandardJMeterEngine.notifyTestListenersOfStart(StandardJMeterEngine.java:247) [ApacheJMeter_core.jar:5.6.3]at org.apache.jmeter.engine.StandardJMeterEngine.run(StandardJMeterEngine.java:432) [ApacheJMeter_core.jar:5.6.3]at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:539) [?:?]at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) [?:?]at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) [?:?]at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) [?:?]at java.base/java.lang.Thread.run(Thread.java:833) [?:?]
原因:JDBC Connection Configuration 和 JDBC Request 中没有配置 pool 的变量名,或者配置了,但取名不一样,改为相同的变量名即可:
8. 附录
以下是本文使用的 Debezium 官方提供的 MySQL Docker镜像 中的 Inventory 数据库的 orders 数据表的表结构:
-- Dumping structure for table inventory.orders
DROP TABLE IF EXISTS `orders`;
CREATE TABLE IF NOT EXISTS `orders` (`order_number` int(11) NOT NULL AUTO_INCREMENT,`order_date` date NOT NULL,`purchaser` int(11) NOT NULL,`quantity` int(11) NOT NULL,`product_id` int(11) NOT NULL,PRIMARY KEY (`order_number`),KEY `order_customer` (`purchaser`),KEY `ordered_product` (`product_id`),CONSTRAINT `orders_ibfk_1` FOREIGN KEY (`purchaser`) REFERENCES `customers` (`id`),CONSTRAINT `orders_ibfk_2` FOREIGN KEY (`product_id`) REFERENCES `products` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10008 DEFAULT CHARSET=latin1;-- Dumping data for table inventory.orders: ~5 rows (approximately)
INSERT INTO `orders` (`order_number`, `order_date`, `purchaser`, `quantity`, `product_id`) VALUES(10001, '2016-01-16', 1002, 5, 104),(10002, '2016-01-17', 1002, 2, 105),(10003, '2016-02-25', 1002, 2, 106),(10006, '2016-02-29', 1002, 2, 106),(10007, '2016-02-28', 1001, 2, 106);
 集合)
















)

