一、为什么要分库分表
1.目的
1. 分担了访问压力 2. 解决存储压力
2.分库分表的时机
1. 前提,项目业务数据逐渐增多,或业务发展迅速,单表的数据量达1000W或20G以后。
2. 优化已解决不了性能问题(主从读写分离、查询索引…)。
3. IO瓶颈(磁盘IO、网络IO)、CPU瓶颈(聚合查询、连接数太多)。
二、拆分策略
1.垂直拆分
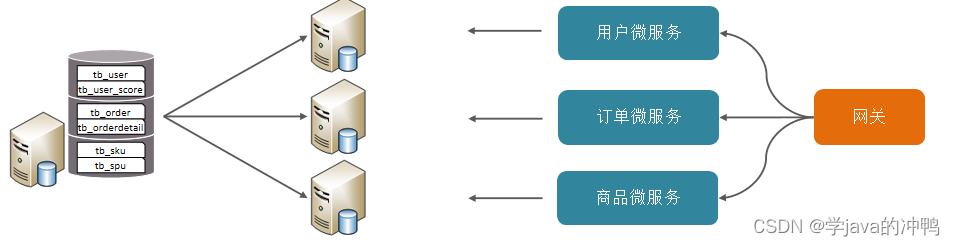
(1)垂直分库
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
特点: 1. 按业务对数据分级管理、维护、监控、扩展。
2. 在高并发下,提高磁盘IO和数据量连接数。
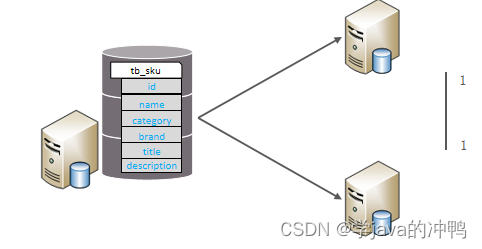
(2)垂直分表
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。
特点: 1. 冷热数据分离。
2. 减少IO过渡争抢,两表互不影响。
拆分规则: 把不常用的字段单独放在一张表。
把text,blob等大字段拆分出来放在附表中。
2.水平拆分
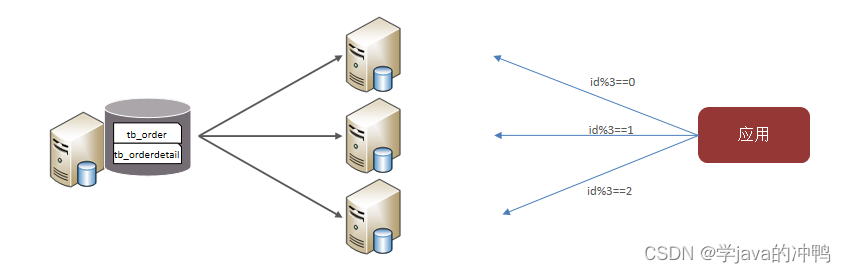
(1)水平分库
水平分库:将一个库的数据拆分到多个库中。
特点: 1. 解决了单库大数量,高并发的性能瓶颈问题。
2. 提高了系统的稳定性和可用性。
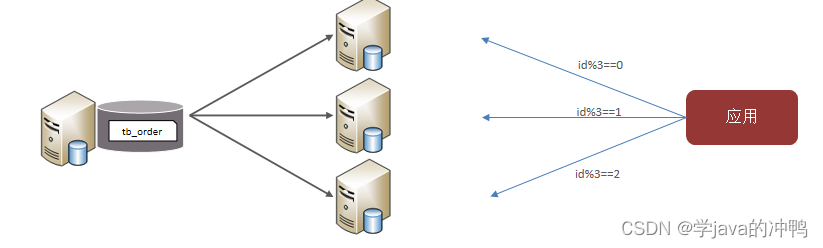
(2)水平分表
水平分表:将一个表的数据拆分到多个表中(可以在同一个库内)。
特点: 1. 优化单一表数据量过大而产生的性能问题。
2. 避免IO争抢并减少锁表的几率。
三、产生的问题以及如何解决
分库之后的问题:
1. 分布式事务一致性问题。
2. 跨节点关联查询。
3. 跨节点分页、排序函数。
4. 主键避重。
解决方案:
分库分表中间件:
1. sharding-sphere。
2. mycat。
四、面试的回答
面试官:你们项目用过MySQL的分库分表吗?
候选人:因为我们都是微服务开发,每个微服务对应了一个数据库,是根据业务进行拆分的,这个其实就是垂直拆分。
面试官:那你之前使用过水平分库吗?
候选人:这个是使用过的,我们当时的业务是(xxx),一开始,我们也是单库,后来这个业务逐渐发展,业务量上来的很迅速,其中(xx)表已经存放了超过1000万的数据,我们做了很多优化也不好使,性能依然很慢,所以当时就使用了水平分库。
我们一开始先做了3台服务器对应了3个数据库,由于库多了,需要分片,我们当时采用的mycat来作为数据库的中间件。数据都是按照id(自增)取模的方式来存取的。
当然开始的时候,那些旧数据,我们做了一些清洗的工作,我们也是按照id取模规则分别存储到了各个数据库中,好处就是可以让各个数据库分摊存储和读取的压力,解决了我们当时性能的问题。

)




)
数据结构练习题(2))



— 完善后端报错与客户端显示)


外部认证)




