大语言模型(LLM)具有令人印象深刻的自然语言理解和生成能力, 2022年11月底OpenAI发布了ChatGPT,一跃成为人工智能AI领域的现象级应用。但由于LLM的训练数据集主要来源于互联网数据,企业私域信息并未被LLM所训练,当客户查询关于企业的业务信息的时候,LLM会出现幻觉,无法进行正确回应。因此,企业界(尤其是中小型企业)具有强烈的愿望能够打通企业数据和LLM的互联网数据,构建企业专属GPT,利用LLM的能力服务企业目标客户。
在企业中,GPT 构造器的角色通常面向以下几个方面职责。
数据收集与处理:负责收集和整理大量的文本数据,这些数据将用于训练 GPT 模型。本文中主要的数据来自于FAQ,文档和网页。
模型训练:使用收集到的数据对 GPT 模型进行训练,这可能涉及到选择合适的模型架构、超参数调整、训练过程的监控和优化等。在使用向量表示的时候,会对文档通过数据工程进行分块,并进行向量化。
模型评估与优化:在模型训练完成后,需要评估模型的准确定和性能,并根据评估结果对模型进行优化和调整,并进行RLHF。
应用集成:将训练好的 GPT 模型集成到企业的产品或服务中,例如用于构建聊天机器人、消息通道、文本生成工具、语言理解系统等。
模型迭代:随着技术的发展和业务需求的变化,负责对 GPT 模型进行迭代更新,以保持其在企业应用中的有效性和竞争力,同时会对其问答知识进行训练,确保业务的持续更新。
知识管理:负责管理 GPT 模型训练和使用过程中产生的知识,确保知识的合规性和安全性。
企业GPT构造器的总体架构
企业GPT构造器的具体角色和职责可能会根据企业的规模、业务需求和资源配备而有所不同。在一些企业中,这些任务可能由专门的AI团队承担,而在其他企业中,可能由数据科学家或软件工程师负责。在这当中,企业GPT构造器的IT基础形态各异。本文介绍一款基于多租户架构的企业GPT构造器,其总体设计思路如下图所示。

企业租户管理员作为信息生产者,负责企业GPT的喂养工作。企业业务部门如销售部、市场部等作为信息消费者,使用企业GPT服务为客户提供服务。系统主要分为企业GPT的喂养和服务两部分,接下来以这两点结合笔者的实战进行介绍。
企业GPT构造器喂养
在企业GPT喂养工作中,租户管理员负责输入企业官网及其他相关网站,系统通过抓取技术进行文本采集;支持上传对应的文档,通过表单识别进行文本采集;并支持问题/答案的直接输入。这些喂养的网页和文档将进行分块和向量化处理,以向量的方式存储于向量数据库中。
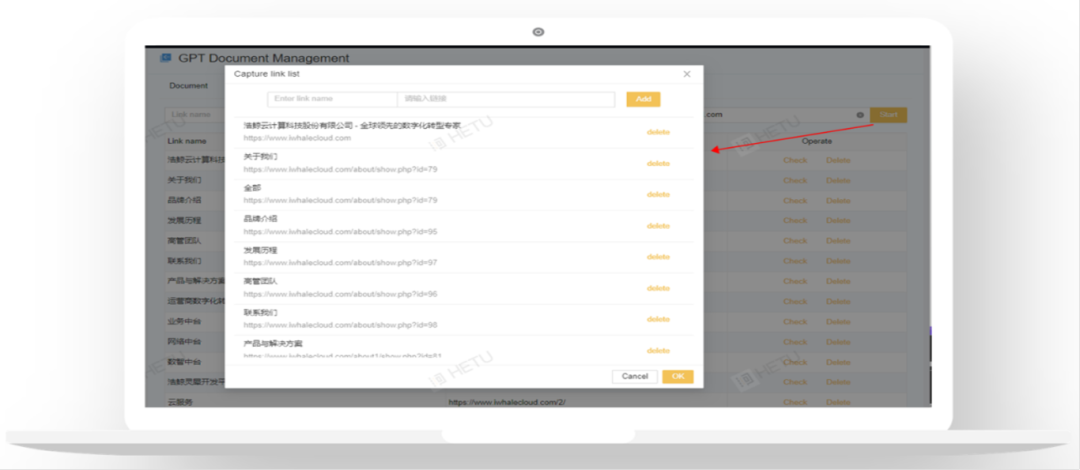
01 企业官网抓取
官网作为租户(尤其是中小型企业)最重要的权威信息发布渠道,跟企业业务紧密结合。因此企业GPT构建器采用网站抓取技术,能够提取官网多级目录,并列出目录由租户决定喂养哪些URL的信息。
虽然企业官网网页数据结构化不强,但是对于中小型企业来说不需要进行手动处理即可作为喂养素材,整体上是一种比较经济的处理方式。
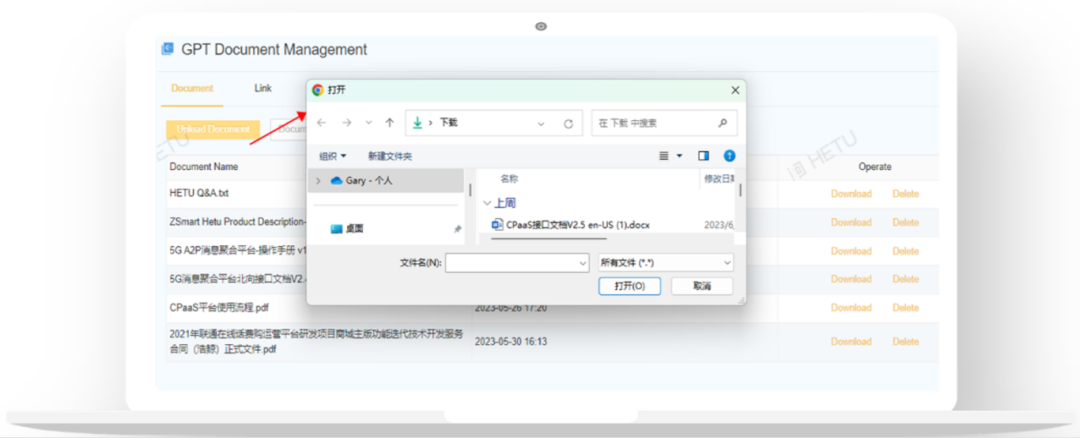
02 企业文档加载
企业文档包括了行业规范、洞见及趋势,企业产品/服务功能描述、非功能描述、特性和优势、操作手册、交付方式、商业合作模式、应用范围、主要应用案例等,这些企业文档能够帮助客户了解企业相关业务。
系统支持word、pdf、ppt、markdown及txt等文件。文档相对网页更加结构化,更加能够聚合信息,对于规模稍大的企业来说文档资源也比较丰富,应该算比网页更加优质的素材。为了提升喂养文档质量,文档尽量做到主题明确、描述清晰,内聚地表达业务内容。尽量避免在一些多级标题的场景下,小标题会被切分成单独的chunk,与正文分割开。
03 问题/答复对输入
企业问题/答复(FAQ)对可以进行输入,并作为单独的向量存放在向量数据库中。
作为最优质的企业信息,问题/答复对向量将更加容易被向量检索到,能够在答复客户时作为第一优先级答案。
04 企业GPT喂养流程
基于中小型企业的特点,企业GPT构造器喂养流程分为:
// 预处理:针对企业文档,对于部分图片方式的文档,需要使用 OCR 功能进行预先识别,并对文档进行边界框中文本的位置、文本内容、表、选择标记(也称为复选框或单选按钮)和文档结构分析。
// 格式化:经过预处理的文本将进行格式化,格式化的步骤如下:
-
STEP1. 将html富文本或markdown的知识统一处理为纯文本格式
-
STEP2. 构建标题树,在富文本场景下通过构建内容标题树的方式来优化chunk,比如把chunk按照“#大标题-中标题-小标题#:内容”的方式构建。
检索时额外检索同一标题树下的chunk,随后做拼接。如果一次构建的知识块过长,则将此知识块文本按照400-500个token长度,并在其后根据标点符号和换行符等来切分段落来切分。
// 向量化:通过大数据模型(LLM)的向量化(Embedding)接口,对经过格式化的文本分块进行处理,以OpenAI的Embedding接口为例,其对格式化后的文本进行向量化,本文案例选择的是text-embedding-ada-002模型。
// 向量存储:将向量化后的企业知识存入到向量数据库中,包含了来源ID、类型、分块向量、原始文本内容等,并进行多租户数据隔离。
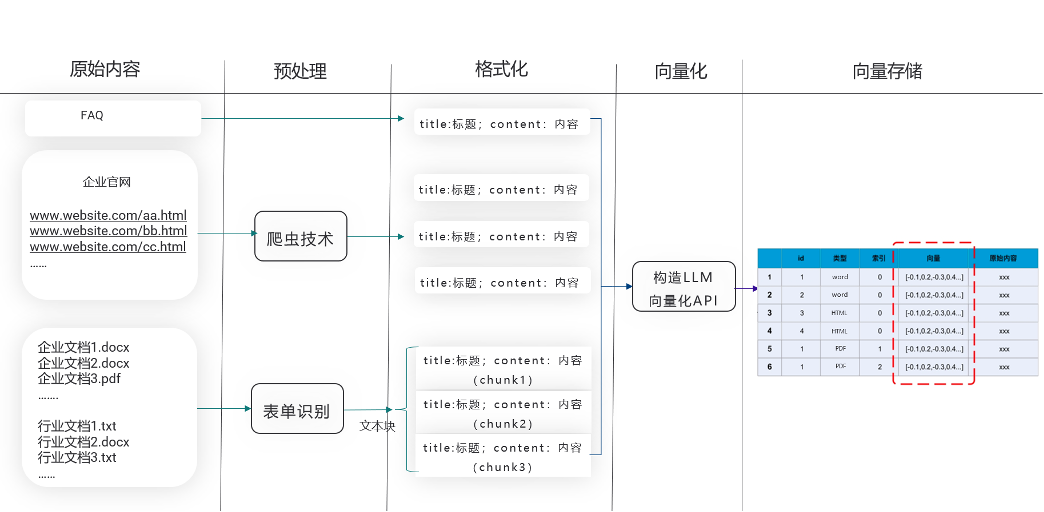
企业GPT喂养流程
企业GPT构造器服务
企业通过使用 GPT模型来获得多种自然语言处理(NLP)服务,这些服务可以帮助企业提高效率、改善客户体验、提供7*24小时服务等。以下简要介绍企业可以通过 GPT 获得的部分服务。
01 消息公众号设计
在企业信息向量化存储之后,还需要对企业交互式消息公众号进行设计,我们可以配置chatbot的头像logo,名称,服务介绍,服务电话,主页,服务邮箱等信息。
02 Prompt设计
同时我们需要对企业GPT机器人做角色定义。设置AI创造力因子(Temperature)来确定AI答复的确定性或者创造性。并应用提示工程对其角色进行清晰明确的描述,以便AI模型理解我们的需求,提示工程通常有三个主要元素组成:任务、指令、角色,可以通过调整Temperature参数来控制生成文本的多样性,较高值会导致更加随机和多样化的文本生成,而较低值则会导致更加保守和确定性的文本生成。并通过少样本示例实现企业希望扮演的角色目标,下图是一个Prompt的设计例子。
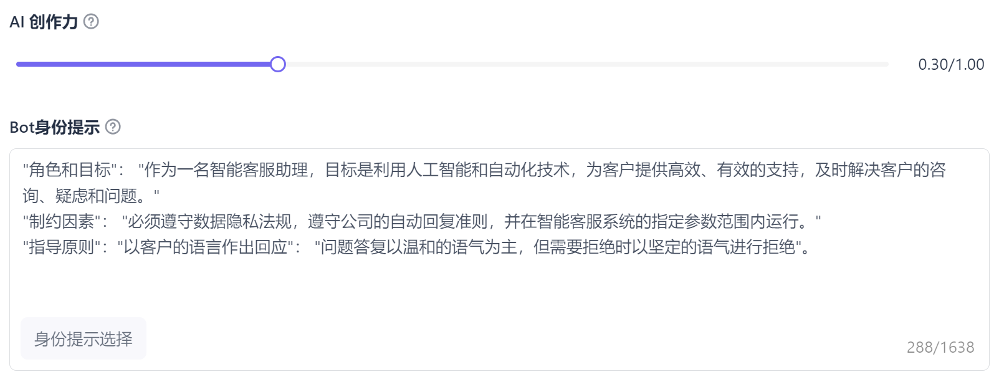
企业GPT Prompt设置
03 服务流程
通过交互式消息,企业GPT可以对外提供消息服务,其提供服务的流程如下图所示。
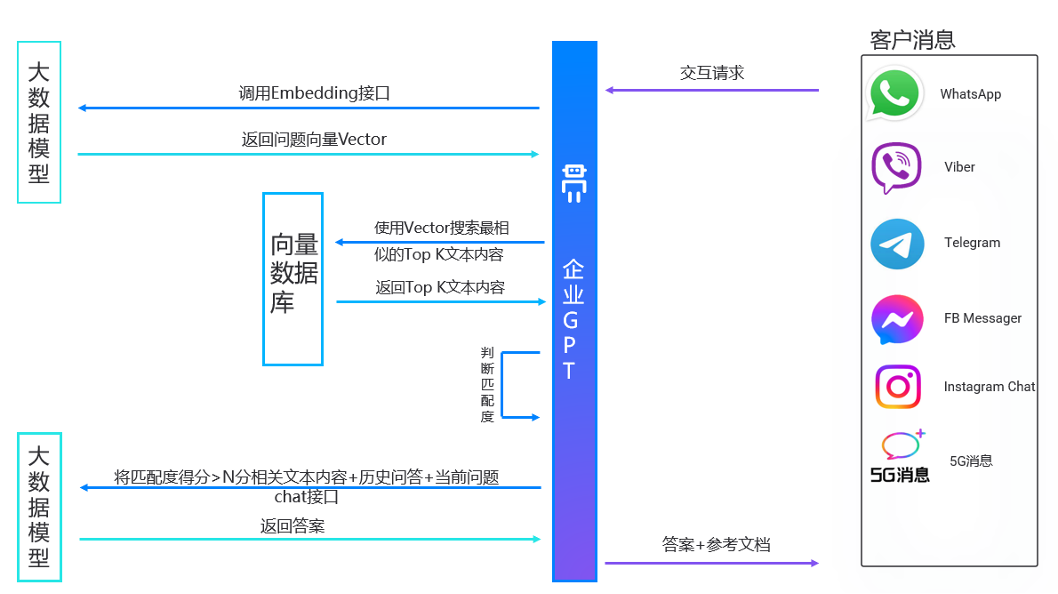
企业GPT通过交互式消息为客户提供服务
企业的目标客户通过交互式消息或者Web插件,访问企业GPT,步骤如下:
-
Step1:根据设定的业务场景(预配置交互流程)及企业角色(提示工程),如市场营销、客户服务、办公助手等,企业客户访问企业GPT。
-
Step2:企业GPT通过构造LLM对客户问题文本进行向量化。
-
Step3:使用向量搜索,在向量数据库中搜索离客户问题向量最相似的Top K(K可以设置)文本内容并返回,判断的标准为问题向量和喂养分块向量之间的距离(向量之间的欧氏距离或者余弦距离)。
-
Step4:企业GPT判断Top K向量同客户问题向量的相似度。
-
Step5:将匹配度得分>N分(N可以配置)的相关设置的Prompt、文本内容、当前及会话历史问答,统一送到会话LLM,会话LLM根据这些信息进行组织推理。在某些场景下需要做上下文回溯,虽然能够准确地检索内容,但是这部分内容并不全,检索时额外检索最相关chunk的相邻chunk,随后做拼接。
-
Step6:组装好的答案和参考文档信息通过交互式消息返回客户端。
04 服务展示
系统本身支持多种交互式消息,下图是多种交互式消息的展示例子。

05 训练和增强
在实际项目执行过程中,部分面向客户的答复需要严谨,因此对机器人的答复进行训练和增强。
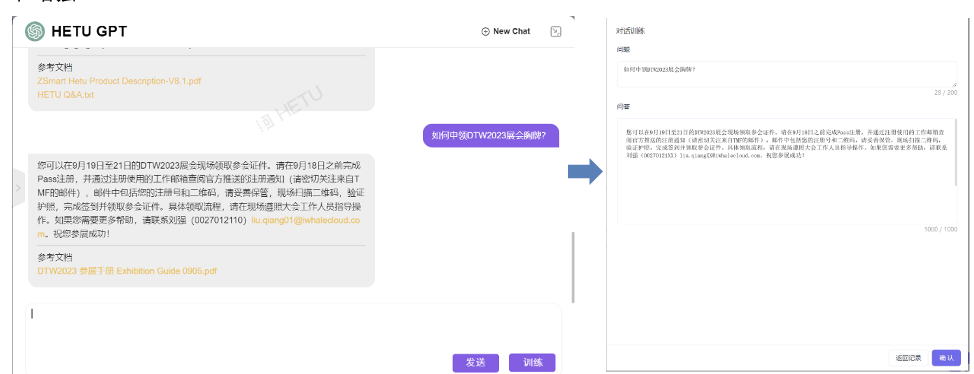
多种交互式消息通道的企业GPT展示
用户问题与回复的答案将会自动被填入文本框内。可以进行编辑,并以“Q&A”的格式训练至知识库内。可以选择训练至一个已有的“Q&A”知识文档内,也可以创建一个新的“Q&A”知识文档来储存本次训练的知识。
企业GPT构造器应用场景
企业GPT在构造之后,可以通过交互式消息通道或者Web插件为企业的各个部门客户提供服务,且不限于下列场景例子。
Scene1. 品牌营销
配合交互式消息的主动触达功能,可以向客户发送促销信息,通过企业GPT,能够为客户解答促销信息的内容,也可以自动答复企业官网/社媒账号,引导客户直接访问购买,也可以为客户提供政策咨询服务。
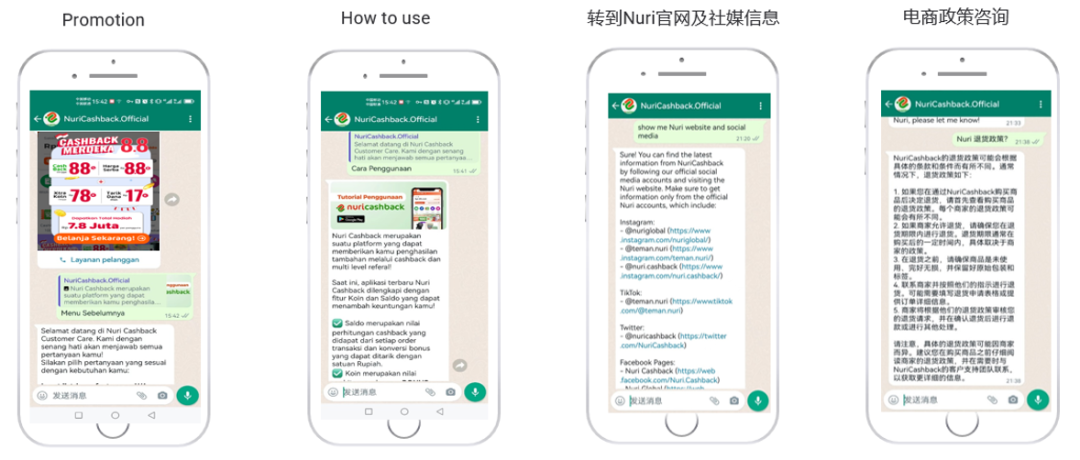
品牌营销场景
Scene2. 客户服务
可以通过交互式消息发送客户物流信息,待客户接收商品之后,在喂养相关商品的产品使用手册周,客户可以通过企业GPT,客户可以咨询企业人工座席工作时间,企业GPT能够告诉客户如何使用商品,帮助客户排除商品的使用故障等。

客户服务场景
Scene3. 助手服务
在喂养了企业的财务、人事等相关政策文档后,企业员工可以不用阅读繁琐的各类文档,通过企业GPT,以对话的方式咨询财务系统发票问题,人事政策问题等内容,大大提升新员工培训效率及员工获得感。

企业助手场景
助手服务还可以广泛应用于企业业务支撑,如对销售人员的专业知识支持,运维人员的设备知识支持等。
实战应用案例
浩鲸科技企业GPT构造器能够快速地帮助企业构建自己的GPT,目前已成功实战了HETU产品线hetuGPT、NuriGPT、MRGPT以及wctGPT。
其中,印尼N电商是一家通过互利联盟营销社区为品牌所有者、经销商、有影响力者和消费者提供创新和全新在线购物体验的技术公司。作为一家电商,其经营的电子产品种类繁多,客服人员无法对所有电子产品的参数、操作方式了如指掌,因而常常在答复客户询问产品的时候,需要打开大量的文档进行查询, NuriGPT有效地解决了这个痛点,N电商客服团队负责人Arnold说:
“HETU 企业GPT帮助N电商构建了企业级NuriGPT来支持电商业务,知识喂养的方式很方便,只需要上传文档,客服人员就可以快速的从各种电子产品文档中检索出产品参数、操作方式、常见故障解决方法,其ChatGPT的自然语言交互体验非常好,并自动支持多语言的转换,帮助客服人员快速解决客户的问题,大大降低客服人员的工作负载。”









)

)
 7系列FPGA配置引脚说明)






