华子目录
- SQL简介
- SQL语句分类
- SQL语句的书写规范
- SQL注释
- 单行注释
- 多行注释
- select语句
- 简单的select语句
- select的算数运算
- select 要查询的信息 from 表名;
- 查询表字段
- 查询常量
- 查询表达式
- 查询函数
- 查询定义==别名==as
- 安全等于<=>
- 去重distinct
- 连接字段concat
- 模糊查询
- 运算符
- 比较运算符
- 逻辑运算符
- 正则表达式regexp
- 聚合函数
- count
- avg
- sum
- min
- max
- group_concat
- group by
- having
- having和where的区别
- order by
- limit
- 完整的select语句
- 联合查询union和union all
- 多表关联查询
- 交叉连接cross
- inner join内连接
- left join外连接
- right join外连接
- 和where与and搭配使用
- 自查询
- 子查询
- 导入sql表
SQL简介
SQL:结构化查询语言(Structured Query Language),在关系型数据库上执行数据操作、数据检索以及数据维护的标准语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务。
- 改变数据库的结构
- 更改系统的安全设置
- 增加用户对数据库或表的许可权限(root和普通用户的权限)
- 在数据库中检索需要的信息
- 对数据库的信息进行更新
SQL语句分类
MySQL致力于支持全套ANSI/ISO SQL标准。在MySQL数据库中,SQL语句主要可以划分为以下几类:
- DDL(Data Definition Language):数据定义语言,定义对数据库对象(库、表、列、索引)的操作。create、drop、alter、rename、 truncate等。
- DML(Data Manipulation Language): 数据操作语言,定义对数据库数据的操作。insert、delete、update等。(内容的增删改查)
- DQL(Data Query Language)数据查询语言:select语句。
- DCL(Data Control Language): 数据控制语言,定义对数据库、表、字段、用户的访问权限和安全级别。grant、revoke等。
- TCL(Transaction Control):事务控制。commit、rollback、savepoint等。
注:可以使用help查看这些语句的帮助信息。
SQL语句的书写规范
- 在数据库系统中,SQL语句不区分大小写(建议用大写) 。
- 但字符串常量区分大小写。
- SQL语句可单行或多行书写,以“;”结尾。
- 关键词不能跨多行或简写。
- 用空格和缩进来提高语句的可读性。
- 子句通常位于独立行,便于编辑,提高可读性。
SQL注释
单行注释
使用"#"或"--" (使用--时,--与sql语句中间需要有一个空格)
mysql> #select user,host from mysql.user;
mysql> select user,host from mysql.user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| redhat | % |
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+------------------+-----------+
mysql> --select user,host from mysql.user;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '--select user,host from mysql.user' at line 1
# 报错的原因:中间没有加空格
mysql> -- select user,host from mysql.user;
mysql> select user,host from mysql.user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| redhat | % |
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+------------------+-----------+
多行注释
使用 /*内容*/
mysql> /*select user,host from mysql.user;*/
mysql> select user,host from mysql.user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| redhat | % |
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+------------------+-----------+
select语句
简单的select语句
语法
mysql> select * from 表名;
或
mysql> select 字段1,字段2... from 表名;
或
mysql> select 字段1,字段2 from 表名 where 条件;
select的算数运算
mysql> select 20+30;
+-------+
| 20+30 |
+-------+
| 50 |
+-------+mysql> select 'abc'+'90';
+------------+
| 'abc'+'90' |
+------------+
| 90 |
+------------+mysql> select '40'+'90';
+-----------+
| '40'+'90' |
+-----------+
| 130 |
+-----------+mysql> select 40+'90';
+---------+
| 40+'90' |
+---------+
| 130 |
+---------+mysql> select 60+30,50+50;
+-------+-------+
| 60+30 | 50+50 |
+-------+-------+
| 90 | 100 |
+-------+-------+mysql> select null+100; #只要其中一个为null,则结果为null
+----------+
| null+100 |
+----------+
| NULL |
+----------+mysql> select 'null'+100;
+------------+
| 'null'+100 |
+------------+
| 100 |
+------------+
null值使用空值是指不可用、未分配的值空值不等于零或空格任意类型都可以支持空值包括空值的任何算术表达式都等于空字符串和null进行连接运算,得到也是null
as或空格都有取别名的功能
mysql> select 40+30 as 总和;
+--------+
| 总和 |
+--------+
| 70 |
+--------+mysql> select 40+30 总和;
+--------+
| 总和 |
+--------+
| 70 |
+--------+

select 要查询的信息 from 表名;
"要查询的信息"可以是什么:(1)表中的一个字段或很多字段(中间用“,”分开)as 字段别名(2)常量值(3)表达式(4)函数
查询表字段
mysql> select first_name,last_name from employees;
查询常量
mysql> select 100;+-----+| 100 |+-----+| 100 |+-----+
查询表达式
mysql> select 1+1;+-----+| 1+1 |+-----+| 2 |+-----+
查询函数
mysql> select version();+-----------+| version() |+-----------+| 8.0.21 |+-----------+
查询定义别名as
查询定义别名as 可以省略
- 改变列的标题头
- 用于表示计算结果的含义
- 作为列的别名
- 如果别名中使用特殊字符,或者是强制大小写敏感,或有空格时,都可以通过为别名添加加双引号实现。
mysql> select 100%98 as 余数结果;
+--------------+
| 余数结果 |
+--------------+
| 2 |
+--------------+mysql> select 100%98 余数;
+--------+
| 余数 |
+--------+
| 2 |
+--------+
安全等于<=>
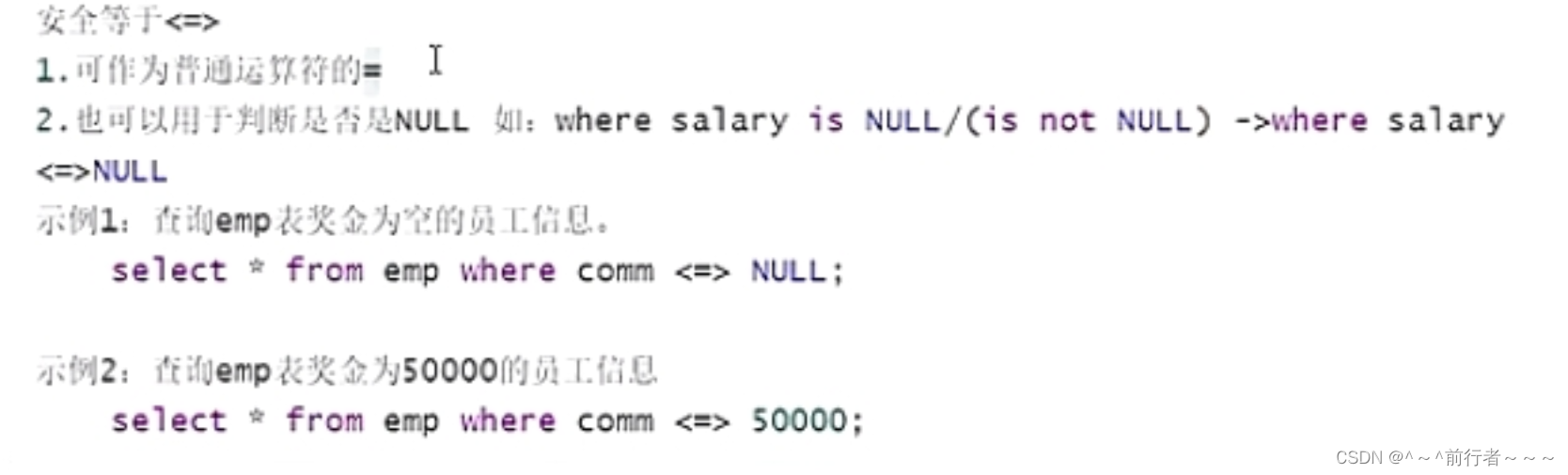
mysql> select stu_name from student where stu_name <=> null;
mysql> select stu_name from student where stu_name is null;
在 MySQL 中,`<=>` 是一个比较运算符,用于比较两个表达式是否相等,包括处理 NULL 值的情况。具体来说,`<=>` 运算符会返回以下值之一:- 如果两个表达式都相等,则返回 `1`。
- 如果其中一个表达式为 `NULL` 而另一个不是,则返回 `0`。
- 如果两个表达式都不相等,则返回 `-1`。该运算符对于处理 NULL 值特别有用,因为普通的等号运算符 `=` 在比较 NULL 值时会返回 `NULL`,而不是布尔值。而 `<=>` 运算符可以直接比较两个表达式,包括对 NULL 值的处理,同时返回一个明确的结果。例如,假设有两个列 `col1` 和 `col2`,如果想要检查它们是否相等,包括对 NULL 值的处理,可以使用 `<=>` 运算符:mysql> SELECT col1 <=> col2 AS are_equal FROM your_table;这样,`are_equal` 列会显示 `1` 表示相等,`0` 表示其中一个是 NULL,`-1` 表示不相等。
去重distinct
正常情况下查询数据显示所有行,包括重复行数据
mysql> select stu_name from stu;使用distinct关键字可以从查询结果中清除重复行
mysql> select distinct stu_name from stu;distinct的作用范围是后面所有字段的组合
mysql> select distinct stu_name,stu_age from stu;
`distinct` 是 MySQL 中的一个关键字,用于在查询结果中去除重复的行。当在 `SELECT` 查询语句中使用 `distinct` 关键字时,MySQL 将返回结果集中唯一的行,即每一行都是不同的。如果有多行内容完全相同,则只返回其中一行,其他重复的行将被过滤掉。例如,假设有一个名为 `students` 的表,其中包含学生的姓名和年龄。如果想要列出不重复的年龄,可以这样查询:mysql> select distinct age FROM students;这将返回 `students` 表中所有不重复的年龄值。`distinct` 关键字可以应用于一个或多个列。例如,如果想要检索不重复的学生姓名和年龄的组合,可以这样查询:mysql> select distinct name, age FROM students;这将返回 `students` 表中所有不重复的姓名和年龄的组合。
连接字段concat
在 MySQL 中,`concat()` 函数用于连接两个或多个字符串。它接受一个或多个字符串参数,并返回这些参数连接在一起的结果。以下是 `concat()` 函数的基本语法:concat(string1, string2, ...)其中 `string1`, `string2`, 等等是要连接的字符串参数。你可以提供任意数量的参数,每个参数都是一个字符串。示例用法:SELECT concat('Hello', ' ', 'World'); -- 输出: Hello World在 `concat()` 函数中,你可以使用常量字符串、表列或其他表达式作为参数。例如:SELECT concat('The ', column1, ' is ', column2) AS result FROM table_name;这将连接列 `column1` 和 `column2` 中的值,并在它们之间添加一些字符串。你还可以使用 `concat_ws()` 函数来连接字符串,并指定一个分隔符,该分隔符将在连接字符串之间插入。例如:SELECT concat_ws(', ', 'John', 'Doe', '123 Main St') AS result;
-- 输出: John, Doe, 123 Main St这里 `,` 是分隔符。
mysql> select * from class;
+----------+
| class_id |
+----------+
| 1001 |
| 1002 |
| 1003 |
+----------+mysql> select * from stu;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select concat(id,name) from stu;
+-----------------+
| concat(id,name) |
+-----------------+
| 101小天 |
| 102小明 |
| 103小红 |
+-----------------+mysql> select concat(id,name) as 学号姓名 from stu;
+--------------+
| 学号姓名 |
+--------------+
| 101小天 |
| 102小明 |
| 103小红 |
+--------------+
3 rows in set (0.00 sec)mysql> select concat('hello',' ','world');
+-----------------------------+
| concat('hello',' ','world') |
+-----------------------------+
| hello world |
+-----------------------------+mysql> select concat(name,'的学号是',id) as result from stu;
+-----------------------+
| result |
+-----------------------+
| 小天的学号是101 |
| 小明的学号是102 |
| 小红的学号是103 |
+-----------------------+mysql> select concat_ws(', ',name,id) as result from stu;
+-------------+
| result |
+-------------+
| 小天, 101 |
| 小明, 102 |
| 小红, 103 |
+-------------+mysql> select concat_ws('-',name,id) as result from stu;
+------------+
| result |
+------------+
| 小天-101 |
| 小明-102 |
| 小红-103 |
+------------+
模糊查询
- %表示匹配任意零个或多个字符
- _表示单个字符
mysql> select * from stu;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from stu where name like '%红';
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+
1 row in set (0.00 sec)mysql> select * from stu where name like '_红';
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+
运算符
比较运算符
= != < > >= <=
逻辑运算符
and:当所有条件都为真时,返回真
or:当至少一个条件为真时,返回真
not:用于否定条件表达式,将为真的条件取反
xor:当仅有一个条件为真时,返回真。如果两个条件都为真或都为假,则返回假。
between and
not between and
in
not in
is
is not
mysql> select * from stu;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from stu where id between 101 and 103;# 从101到103的数据
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from stu where id between 103 and 104;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from stu where age in (13,20);
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from stu where classid in (1003);
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 102 | 小明 | 20 | 1003 |
+-----+--------+-----+---------+mysql> select * from stu where name is not null;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from stu where id in (104) xor age=18;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
+-----+--------+-----+---------+mysql> select * from stu where age>= 18 and age<=21;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
+-----+--------+-----+---------+mysql> select * from stu where age>= 18 or age<=21;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from stu where id != 101;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+
正则表达式regexp
?字符匹配 0 次或 1 次
^ 字符串的开始
$ 字符串的结尾
. 任何单个字符
[. . . ] 在方括号内的字符列表
[^ . . . ] 非列在方括号内的任何字符
p1 | p2 | p3 交替匹配任何模式p1,p2或p3
* 零个或多个前面的元素
+ 前面的元素的一个或多个实例
{n} 前面的元素的n个实例
{m , n} m到n个实例前面的元素
mysql> select * from stu where name regexp '小.';
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from stu where name regexp '^小';
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+
聚合函数
count
- 用于计算行的数量。可以使用 count(*) 来计算所有行的数量,也可以使用 count(字段名) 来计算特定列中非NULL值的数量。
mysql> select count(*) from stu;
+----------+
| count(*) |
+----------+
| 3 |
+----------+mysql> select count(id) from stu;
+-----------+
| count(id) |
+-----------+
| 3 |
+-----------+
avg
- 用于计算数值列的平均值。
mysql> select avg(age) from stu;
+----------+
| avg(age) |
+----------+
| 17.0000 |
+----------+
sum
- 用于计算数值列的总和。
mysql> select sum(age) from stu;
+----------+
| sum(age) |
+----------+
| 51 |
+----------+
min
- 用于找到数值列中的最小值。
mysql> select min(age) from stu;
+----------+
| min(age) |
+----------+
| 13 |
+----------+
max
- 用于找到数值列中的最大值。
mysql> select max(age) from stu;
+----------+
| max(age) |
+----------+
| 20 |
+----------+
注:count(*)表示所有数据行,不会忽略null值,而count(字段)和其他聚合函数会忽略null值(null值不统计)
group_concat
- 默认以逗号分隔
mysql> select group_concat(name) from stu;
+----------------------+
| group_concat(name) |
+----------------------+
| 小天,小明,小红 |
+----------------------+mysql> select group_concat(name separator ';') from stu;
+----------------------------------+
| group_concat(name separator ';') |
+----------------------------------+
| 小天;小明;小红 |
+----------------------------------+mysql> select group_concat(name separator ',') from stu;
+----------------------------------+
| group_concat(name separator ',') |
+----------------------------------+
| 小天,小明,小红 |
+----------------------------------+mysql> select group_concat(name id) from stu;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'id) from stu' at line 1
# 报错的原因:group_concat()中只能包含一个字段
mysql> select group_concat(id) from stu;
+------------------+
| group_concat(id) |
+------------------+
| 101,103,102 |
+------------------+
group by
- group by子句的真正作用在于与各种聚合函数配合使用。用来对查询出来的数据进行分组。
- 分组的含义:把该列具有相同值的多条记录当成一组记录处理,最后每组只输出一条记录。
mysql> select * from department;
+--------------+--------------+
| 部门编号 | 部门名称 |
+--------------+--------------+
| 1001 | 行政部 |
| 1002 | 销售部 |
| 1003 | 技术部 |
| 1004 | 管理部 |
+--------------+--------------+mysql> select * from employee;
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
+------+-----------+-----------------+--------+-------+--------+mysql> select job_id,avg(salary) from employee group by job_id;# 按照job_id进行分组,将相同数据的job_id值分为一组,计算每一组的平均薪资
+--------+-------------+
| job_id | avg(salary) |
+--------+-------------+
| 1001 | 10000.0000 |
| 1002 | 14000.0000 |
| 1003 | 17400.0000 |
| 1004 | 30000.0000 |
+--------+-------------+
注:group by后面跟的字段只能是聚合函数前面出现过的全部字段,否则分组无效。
mysql> select name,count(name) from employee group by name;
+-----------+-------------+
| name | count(name) |
+-----------+-------------+
| 麦当 | 1 |
| 咕咚 | 1 |
| 迪亚 | 1 |
| 米龙 | 1 |
| 极光 | 1 |
| 村长 | 1 |
| 五条人 | 1 |
| 皇帝 | 1 |
+-----------+-------------+
8 rows in set (0.00 sec)mysql> select id,name,count(name) from employee group by id,name;
+------+-----------+-------------+
| id | name | count(name) |
+------+-----------+-------------+
| 101 | 麦当 | 1 |
| 102 | 咕咚 | 1 |
| 103 | 迪亚 | 1 |
| 104 | 米龙 | 1 |
| 105 | 极光 | 1 |
| 106 | 村长 | 1 |
| 107 | 五条人 | 1 |
| 108 | 皇帝 | 1 |
+------+-----------+-------------+
8 rows in set (0.00 sec)mysql> select id,name,count(name) from employee group by id;
ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'huazi.employee.name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
mysql> select id,name,count(name) from employee group by name;
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'huazi.employee.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
having
- having子句用来对分组后的结果再进行条件过滤(所以having中的条件只能是与查询字段相关)
- where和having都是用来做条件限定的,但是having只能用在group by之后
- 分组后加条件,使用having
mysql> select job_id,avg(salary) from employee group by job_id;
+--------+-------------+
| job_id | avg(salary) |
+--------+-------------+
| 1001 | 10000.0000 |
| 1002 | 14000.0000 |
| 1003 | 17400.0000 |
| 1004 | 30000.0000 |
+--------+-------------+mysql> select job_id,avg(salary) from employee group by job_id having job_id=1003;
+--------+-------------+
| job_id | avg(salary) |
+--------+-------------+
| 1003 | 17400.0000 |
+--------+-------------+mysql> select job_id,avg(salary) from employee group by job_id having avg(salary)>20000;
+--------+-------------+
| job_id | avg(salary) |
+--------+-------------+
| 1004 | 30000.0000 |
+--------+-------------+
mysql> select job_id,avg(salary) from employee where bonus>5000 group by job_id;
+--------+-------------+
| job_id | avg(salary) |
+--------+-------------+
| 1002 | 14000.0000 |
| 1004 | 30000.0000 |
+--------+-------------+mysql> select job_id,avg(salary) from employee where bonus>5000 group by job_id having avg(salary)>20000;
+--------+-------------+
| job_id | avg(salary) |
+--------+-------------+
| 1004 | 30000.0000 |
+--------+-------------+
having和where的区别
- where是在分组前进行条件过滤的,having子句是在分组后进行条件过滤的,(where子句中不能使用聚合函数,having子句中 可以使用聚合函数)
order by
- 在 MySQL 中,order by子句用于对查询结果进行排序。你可以根据一个或多个列的值对结果进行排序,并指定升序或降序排序。
mysql> select * from employee;
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
+------+-----------+-----------------+--------+-------+--------+mysql> select * from employee order by salary;# 默认升序
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
+------+-----------+-----------------+--------+-------+--------+mysql> select * from employee order by salary desc;# desc降序
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
+------+-----------+-----------------+--------+-------+--------+mysql> select * from employee order by salary asc; # asc升序
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
+------+-----------+-----------------+--------+-------+--------+
limit
- 在MySQL中,limit子句用于限制select查询返回的行数。这对于处理大量数据并且只需要部分结果时非常有用。
select.......limit [offset_start,] row_count;
注:
offset_start:偏移量,默认为0
row_count:查询的最大行数
mysql> select * from employee;
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
+------+-----------+-----------------+--------+-------+--------+mysql> select * from employee limit 5; # 从第1行开始,一共显示5行数据
+------+--------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+--------+-----------------+--------+-------+--------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
+------+--------+-----------------+--------+-------+--------+mysql> select * from employee limit 1,3; # 从第2行开始,一共显示3行数据
+------+--------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+--------+-----------------+--------+-------+--------+
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
+------+--------+-----------------+--------+-------+--------+
完整的select语句
mysql> select 去重选项 字段列表 [as 字段别名] from 数据源 [where子句] [group by 子句] [having子句] [order by 子句] [limit子句];
联合查询union和union all
当我们在查询过程中遇到select * from employee where dept_id in (1001,1002);这类情况时,
可以使用select * from employee where dept_id=1001 union/union all select *from employee where dept_id=1002;说明:一般情况下,我们会将in或者or语句改写为union all来提高性能。
union:去重
union all 不去重
mysql> select * from employee;
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
+------+-----------+-----------------+--------+-------+--------+mysql> select * from employee where job_id in (1003,1001);
+------+--------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+--------+-----------------+--------+-------+--------+
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
+------+--------+-----------------+--------+-------+--------+mysql> select * from employee where job_id=1001 union select * from employee where job_id=1003;
+------+--------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+--------+-----------------+--------+-------+--------+
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
+------+--------+-----------------+--------+-------+--------+mysql> select * from employee where job_id=1001 union all select * from employee where job
_id=1003;
+------+--------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+--------+-----------------+--------+-------+--------+
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
+------+--------+-----------------+--------+-------+--------+
mysql> select * from employee where dept_id=1001-> union-> select * from employee where dept_id=1002;
多表关联查询
mysql> select 字段... from 表1 inner/left/right/full join 表2 on 条件;
在 MySQL 中,多表关联查询是通过使用 `JOIN` 子句来实现的,它允许你在一个查询中检索多个表中的数据,并且可以根据这些表之间的关联条件来连接它们。基本语法如下:SELECT column1, column2, ...
FROM table1
JOIN table2 ON table1.column_name = table2.column_name;在这里,`table1` 和 `table2` 是要连接的表,`column_name` 是它们之间的关联列。这个列可以是两个表中的任何一个列,只要它们的值匹配。有几种不同类型的 `JOIN`:1. INNER JOIN(内连接):返回匹配两个表之间连接条件的行。SELECT *
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;2. LEFT JOIN(左连接):返回左表中的所有行,以及右表中与左表中的行匹配的行。如果没有匹配的行,将为右表中的列返回 NULL 值。SELECT *
FROM table1
LEFT JOIN table2 ON table1.column_name = table2.column_name;3. RIGHT JOIN(右连接):返回右表中的所有行,以及左表中与右表中的行匹配的行。如果没有匹配的行,将为左表中的列返回 NULL 值。SELECT *
FROM table1
RIGHT JOIN table2 ON table1.column_name = table2.column_name;4. FULL JOIN(全连接):返回左表和右表中的所有行。如果没有匹配的行,将为另一个表中的列返回 NULL 值。SELECT *
FROM table1
FULL JOIN table2 ON table1.column_name = table2.column_name;`JOIN` 子句也可以与 `WHERE` 子句一起使用,以添加额外的筛选条件。SELECT *
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name
WHERE condition;在多表关联查询中,你可以使用多个 `JOIN` 子句来连接更多的表,以获取所需的数据。
交叉连接cross
- 将两张表或多张表联合起来查询,这就是连接查询。交叉连接返回的结果是被连接的两个表中所有数据行的笛卡儿积。
- 笛卡尔积是必须要知道的一个概念。在没有任何限制条件的情况下,两表连接必然会形成笛卡尔积。(如表1m行a列,表2n行b列,则无条件连接时则会有m*n,a+b列。)交叉连接查询在实际运用中没有任何意义
- 注意:连接条件必须是唯一字段,如果非唯一字段则会产生笛卡尔积。
mysql> select * from stu;
+-----+--------+-----+---------+
| id | name | age | classid |
+-----+--------+-----+---------+
| 101 | 小天 | 18 | 1001 |
| 102 | 小明 | 20 | 1003 |
| 103 | 小红 | 13 | 1002 |
+-----+--------+-----+---------+mysql> select * from class;
+----------+
| class_id |
+----------+
| 1001 |
| 1002 |
| 1003 |
+----------+mysql> select * from stu,class;#笛卡尔积
+-----+--------+-----+---------+----------+
| id | name | age | classid | class_id |
+-----+--------+-----+---------+----------+
| 103 | 小红 | 13 | 1002 | 1001 |
| 102 | 小明 | 20 | 1003 | 1001 |
| 101 | 小天 | 18 | 1001 | 1001 |
| 103 | 小红 | 13 | 1002 | 1002 |
| 102 | 小明 | 20 | 1003 | 1002 |
| 101 | 小天 | 18 | 1001 | 1002 |
| 103 | 小红 | 13 | 1002 | 1003 |
| 102 | 小明 | 20 | 1003 | 1003 |
| 101 | 小天 | 18 | 1001 | 1003 |
+-----+--------+-----+---------+----------+
inner join内连接
mysql> select * from employee;
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
+------+-----------+-----------------+--------+-------+--------+mysql> select * from department;
+--------------+--------------+
| 部门编号 | 部门名称 |
+--------------+--------------+
| 1001 | 行政部 |
| 1002 | 销售部 |
| 1003 | 技术部 |
| 1004 | 管理部 |
| 1005 | 领导部 |
+--------------+--------------+mysql> select * from employee inner join department on employee.job_id=department.部门编号;
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| id | name | job | salary | bonus | job_id | 部门编号 | 部门名称 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 | 1003 | 技术部 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 | 1003 | 技术部 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 | 1003 | 技术部 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 | 1003 | 技术部 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 | 1003 | 技术部 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 | 1001 | 行政部 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 | 1002 | 销售部 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 | 1004 | 管理部 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
left join外连接
mysql> select * from employee left join department on employee.job_id=department.部门编号;
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| id | name | job | salary | bonus | job_id | 部门编号 | 部门名称 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 | 1003 | 技术部 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 | 1003 | 技术部 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 | 1003 | 技术部 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 | 1003 | 技术部 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 | 1003 | 技术部 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 | 1001 | 行政部 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 | 1002 | 销售部 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 | 1004 | 管理部 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
right join外连接
mysql> select * from employee right join department on employee.job_id=department.部门编号;
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| id | name | job | salary | bonus | job_id | 部门编号 | 部门名称 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 | 1001 | 行政部 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 | 1002 | 销售部 |
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 | 1003 | 技术部 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 | 1003 | 技术部 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 | 1003 | 技术部 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 | 1003 | 技术部 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 | 1003 | 技术部 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 | 1004 | 管理部 |
| NULL | NULL | NULL | NULL | NULL | NULL | 1005 | 领导部 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
和where与and搭配使用
和where搭配使用
mysql> select * from employee right join department on employee.job_id=department.部门编号;
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| id | name | job | salary | bonus | job_id | 部门编号 | 部门名称 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 | 1001 | 行政部 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 | 1002 | 销售部 |
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 | 1003 | 技术部 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 | 1003 | 技术部 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 | 1003 | 技术部 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 | 1003 | 技术部 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 | 1003 | 技术部 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 | 1004 | 管理部 |
| NULL | NULL | NULL | NULL | NULL | NULL | 1005 | 领导部 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+mysql> select * from employee right join department on employee.job_id=department.部门编号 where em
ployee.id is not null;
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| id | name | job | salary | bonus | job_id | 部门编号 | 部门名称 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 | 1003 | 技术部 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 | 1003 | 技术部 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 | 1003 | 技术部 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 | 1003 | 技术部 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 | 1003 | 技术部 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 | 1001 | 行政部 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 | 1002 | 销售部 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 | 1004 | 管理部 |
+------+-----------+-----------------+--------+-------+--------+--------------+--------------+
和and搭配使用
mysql> select * from employee right join department on employee.job_id=department.部门编号 and employee.id is not null;
注:用where搭配是最保险的
自查询
- 原理:一张表起多个别名
- 使用inner join实现自查询
mysql> select t1.name '国家',t2.name '省区' from country t1 inner join country t2 on t1.id=t2.parent_id and t1.parent_id is null;
+--------+-----------+
| 国家 | 省区 |
+--------+-----------+
| 中国 | 陕西 |
| 中国 | 北京 |
| 中国 | 深圳 |
| 美国 | 华盛顿 |
| 美国 | 新加坡 |
+--------+-----------+
mysql> select t1.name '国家',t2.name '省区',t3.name '市区' from country t1 inner join country t2 inner join country t3 on t1.id=t2.parent_id and t1.parent_id is null and t2.id = t3.parent_id;
+--------+-----------+--------------+
| 国家 | 省区 | 市区 |
+--------+-----------+--------------+
| 中国 | 陕西 | 西安 |
| 中国 | 北京 | 北京市 |
| 美国 | 华盛顿 | 小华盛顿 |
| 美国 | 新加坡 | 小新加坡 |
+--------+-----------+--------------+
子查询
在 MySQL 中,子查询(也称为嵌套查询)是指在一个查询内部嵌套另一个完整的查询语句。子查询通常作为另一个查询的一部分,用于过滤、比较、或者提供补充信息。下面是一些常见的子查询用法:1. 作为条件的子查询:子查询可以用作 `WHERE` 或 `HAVING` 子句中的条件。SELECT column1FROM table1WHERE column2 = (SELECT column3 FROM table2 WHERE condition);这个子查询将根据在 `table2` 中满足条件的值,来过滤 `table1` 中的结果。2. 用于 `FROM` 子句的子查询:子查询可以作为另一个查询的结果集,被当作一个临时表一样处理。SELECT *FROM (SELECT column1, column2 FROM table1 WHERE condition) AS subquery;这个子查询将作为一个虚拟表,在外部查询中被引用。3. 用于比较的子查询:子查询可以用于与外部查询中的列进行比较。SELECT column1, column2FROM table1WHERE column2 > (SELECT AVG(column2) FROM table1);这个子查询将计算 `table1` 中 `column2` 列的平均值,并返回大于该平均值的行。子查询可以非常灵活地用于解决各种复杂的查询需求,但也要注意它们的性能开销。在使用子查询时,确保查询的效率和性能,以及对查询结果的正确性进行适当的测试和优化。
- 1.子查询是将一个查询语句嵌套再另一个查询语句中。内部嵌套其他select语句的查询,称为外查询或主查询
- 2.内层查询语句的查询结果,可以为外层查询语句提供查询条件
- 3.子查询中可以包含:in、not in、any、all、exists、not exists等关键字
- 4.还可以包含比较运算符:=、!=、>、<等
- 5.子查询的外部的语句可以是insert,update,delete,select中的任何一个
通过位置来分:select 后面:仅仅支持标量子查询from 后面:支持表子查询where 或having 后面:支持标量子查询(重要)\列子查询(重要)\行子查询(用的较少)exists 后面(相关查询):支持表子查询
mysql> select * from employee;
+------+-----------+-----------------+--------+-------+--------+
| id | name | job | salary | bonus | job_id |
+------+-----------+-----------------+--------+-------+--------+
| 101 | 麦当 | 后端研发 | 25000 | 5000 | 1003 |
| 102 | 咕咚 | 网络运维 | 15000 | 3000 | 1003 |
| 103 | 迪亚 | 测试工程师 | 12000 | 2000 | 1003 |
| 104 | 米龙 | 后端开发 | 20000 | 3500 | 1003 |
| 105 | 极光 | 前端开发 | 15000 | 2500 | 1003 |
| 106 | 村长 | 人力资源 | 10000 | 500 | 1001 |
| 107 | 五条人 | 销售工程师 | 14000 | 7000 | 1002 |
| 108 | 皇帝 | 董事长 | 30000 | 10000 | 1004 |
+------+-----------+-----------------+--------+-------+--------+mysql> select name,salary from employee where salary > (select avg(salary) from employee);
+--------+--------+
| name | salary |
+--------+--------+
| 麦当 | 25000 |
| 米龙 | 20000 |
| 皇帝 | 30000 |
+--------+--------+mysql> select * from (select name,salary from employee where job_id=1003) as subquery;#必须起别名,否则就会报错
+--------+--------+
| name | salary |
+--------+--------+
| 麦当 | 25000 |
| 咕咚 | 15000 |
| 迪亚 | 12000 |
| 米龙 | 20000 |
| 极光 | 15000 |
+--------+--------+mysql> select * from (select name,salary from employee where job_id=1003);#报错原因:没有起别名
ERROR 1248 (42000): Every derived table must have its own alias
导入sql表
mysql> source sql表的路径
eg:
mysql> source /root/myemployees.sql
python#flask# MySQL人口分布系统74626-计算机毕业设计项目选题推荐)






)







 | 环形聚类树状图)

)

