目录
一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量
3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐)
3.2.2 方式二:concatenate
3.2.3 方式三:使用hive的archive归档
3.2.4 方式四:hadoop getmerge
一、小文件产生的原因
- 数据源本身就包含大量的小文件,例如api,kafka消息管道等。
- 动态分区插入数据的时候,会产生大量的小文件,从而导致map数量剧增;;
- reduce 数量越多,小文件也越多,小文件数量=ReduceTask数量*分区数;
- hive中的小文件是向 hive 表中导入数据时产生;
向 hive 中导入数据的几种方式:
(1)直接向表中插入数据
insert into table t_order2 values (1,'zhangsan',88),(2,'lisi',61);这种方式每次插入时都会产生一个小文件,多次插入少量数据就会出现多个小文件,故这种方式生产环境基本不使用;
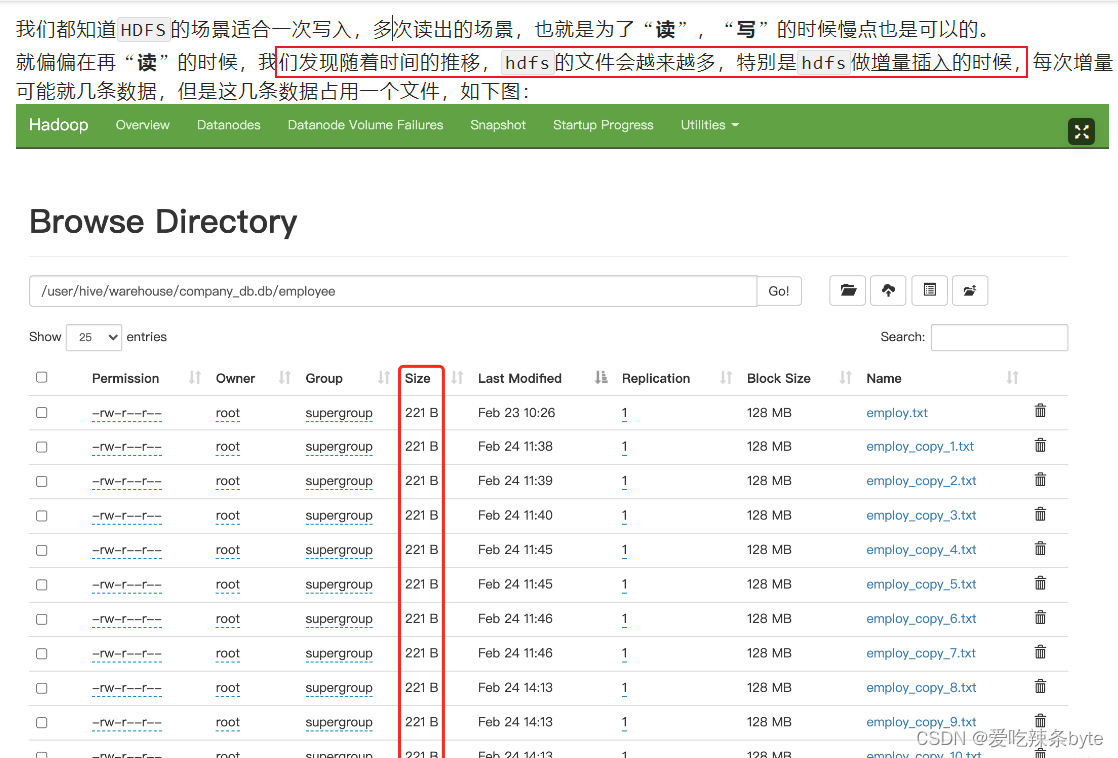
(2)通过load方式加载数据
-- 导入文件
load data local inpath "/opt/module/hive_data/t_order.txt" overwrite into table t_order;
-- 导入文件夹
load data local inpath "/opt/module/hive_data/t_order" overwrite into table t_order;使用 load方式可以导入文件或文件夹,当导入一个文件时,hive表就有一个文件,当导入文件夹时,hive表的文件数量为文件夹下所有文件的数量;
(3)通过查询方式加载数据
insert overwrite t_order select oid,uid from t_order2这种方式是生产环境中经常用的,也是最容易产生小文件的方式。insert 导入数据时会启动MR任务,MR-reduce的个数与输出文件个数一致。
因此,hdfs的文件数量= reduceTask数量* 分区数,有些fetch本地抓取任务(例如:简单的 select * from tableA)仅有map阶段,那此时文件个数 = mapTask数量*分区数
二、小文件的危害
小文件通常是指文件大小要比HDFS块大小(一般是128M)还要小很多的文件。
-
NameNode在内存中维护整个文件系统的元数据镜像、其中每个HDFS文件元数据信息(位置、大小、分块等)对象约占150字节,如果小文件过多会占用大量内存,会直接影响NameNode性能。相对的,HDFS读写小文件也会更加耗时,因为每次都需要从NameNode获取元信息,并与对应的DataNode建立pipeline连接。
- 从 Hive 角度看,一个小文件会开启一个 MapTask,一个 MapTask开一个 JVM 去执行,这些任务的启动及初始化,会浪费大量的资源,严重影响性能。
三、小文件的解决方案
小文件的解决思路主要有两个方向:1.小文件的预防;2.已存在的小文件合并
3.1 小文件的预防
通过调整参数进行合并,在 hive 中执行 insert overwrite tableA select xx from tableB 之前设置如下合并参数,即可自动合并小文件。
3.1.1 减少Map数量
在Map前进行输入合并,从而减少mapper任务的数量。
- 设置map输入时的合并参数:
#执行Map前进行小文件合并
#CombineHiveInputFormat底层是 Hadoop的 CombineFileInputFormat 方法
#此方法是在mapper中将多个文件合成一个split切片作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认#每个Map最大的输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256*1000*100; -- 256M
#一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100*100*100; -- 100M
#一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100*100*100; -- 100M- 设置map端输出时和reduce端输出时的合并参数:
#设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
#设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
#设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000; -- 256M
#当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000; -- 16M- 启用压缩(小文件合并后,也可以选择启用压缩)
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
#设置压缩方式是snappy
set parquet.compression = snappy;
3.1.2 减少Reduce的数量
#reduce的个数决定了输出的文件的个数,所以可以调整reduce的个数控制hive表的文件数量,
#通过设置reduce的数量,利用distribute by使得数据均衡的进入每个reduce。
#设置reduce的数量有两种方式,第一种是直接设置reduce个数
set mapreduce.job.reduces=10;#第二种是设置每个reduceTask的大小,Hive会根据数据总大小猜测确定一个reduce个数
set hive.exec.reducers.bytes.per.reducer=512*1000*1000; -- 默认是1G,这里为设置为5G#执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;insert overwrite table A partition(dt)
select * from B
distribute by cast(rand()*10 as int);解释:如设置reduce数量为10,则使用cast(rand()*10 as int),生成0-10之间的随机整数,根据【随机整数 % 10】计算分区编号,这样数据就会均衡的分发到各reduce中,防止出现有的文件过大或过小3.2 已存在的小文件合并
对集群上已存在的小文件进行定时或实时的合并操作,定时操作可在访问低峰期操作,如凌晨2点,合并操作主要有以下几种方式:
3.2.1 方式一:insert overwrite (推荐)
执行流程总体如下:
(1)创建备份表(创建备份表时需和原表的表结构一致)
create table test.table_hive_back like test.table_hive ;(2)设置合并文件相关参数,并使用insert overwrite 语句读取原表,再插入备份表
- 设置合并文件相关参数
使用 hive的merger合并参数,在正式 insert overwrite 之前做一个合并,合并的时候注意设置好压缩,不然文件会比较大。
- 合并文件至备份表中,执行前保证没有数据写入原表
#如果有多级分区,将分区名放到partition中
insert overwrite table test.table_hive_back partition(batch_date)
select * from test.table_hive;
ps:insert overwrite table test.table_hive_back 备份表的时候,可以使用distribute by 命令设置合并后的batch_date分区下的文件数据量
insert overwrite table 目标表 [partition(hour=...)] select * from 目标表
distribute by cast( rand() * 具体最后落地生成多少个文件数 as int);
insert overwrite:会重写数据,先进行删除后插入(不用担心如果overwrite失败,数据没了,这里面是有事务保障的);
distribute by分区:能控制数据从map端发往到哪个reduceTask中,distribute by的分区规则:分区字段的hashcode值对reduce 个数取模后, 余数相同的数据会分发到同一个reduceTask中。
rand()函数:生成0-1的随机小数,控制最终输出多少个文件。
# 使用distribute by rand()将数据随机分配给reduce,这样可以使得每个reduce处理的数据大体一致。 避免出现有的文件特别大, 有的文件特别小,例如:控制dt分区目录下生成100个文件,那么hsql如下:
insert overwrite table A partition(dt)select * from B
distribute by cast(rand()*100 as int);#cast(rand()*100 as int) 可以生成0-100的随机整数如果合并之后的文件竟然还变大了,可能是 select from的原数据是被压缩的,但是insert overwrite目标表的时候,没有设置输出文件压缩功能,解决方案:
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
#设置压缩方式是snappy
set parquet.compression = snappy;
(3)确认表数据一致后,将原表修改名称为临时表tmp,将备份表修改名称为原表
- 先查看原表和备份表数据量,确保表数据一致
#查看原表和备份表数据量
set hive.compute.query.using.stats=false ;
set hive.fetch.task.conversion=none;
SELECT count(*) FROM test.table_hive;
SELECT count(*) FROM test.table_hive_back ;- 将原表修改名称为临时表tmp,将备份表修改名称为原表
alter table test.table_hive rename to test.table_hive_tmp;
alter table test.table_hive_back rename to test.table_hive ;(4)查看合并后的分区数和小文件数量
正常情况下:hdfs文件系统上的table_hive表的分区数量没有改变,但是每个分区的几个小文件已经合并为一个文件。
#统计合并后的分区数
[atguigu@bigdata102 ~]$ hdfs dfs -ls /user/hive/warehouse/test/table_hive
#统计合并后的分区数下的文件数
[atguigu@bigdata102 ~]$ hdfs dfs -ls /user/hive/warehouse/test/table_hive/batch_date=20210608例如:

(5)观察一段时间后再删除临时表
drop table test.table_hive_tmp ;
ps:注意修改hive表名的时候,对应表的存储路径会发生变化,如果有新的任务上传数据到具体路径,需要注意可能需要修改。
3.2.2 方式二:concatenate
对于orc文件,可以使用hive自带的 concatenate 命令,自动合并小文件
#对于非分区表
alter table test concatenate;#对于分区表
alter table test [partition(...)] concatenate
#例如:alter table test partition(dt='2021-05-07',hr='12') concatenate;注意:
- concatenate 命令只支持 rcfile和 orc文件类型。
- concatenate命令合并小文件时不能指定合并后的文件数量,但可以多次执行该命令。
- 当多次使用concatenate后文件数量不变化,这个跟参数 mapreduce.input.fileinputformat.split.minsize=256mb 的设置有关,可设定每个文件的最小size。
3.2.3 方式三:使用hive的archive归档
每日定时脚本,对于已经产生小文件的hive表使用har归档,然后已归档的分区不能insert overwrite ,必须先unarchive
#用来控制归档是否可用
set hive.archive.enabled=true;#通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;#控制需要归档文件的大小
set har.partfile.size=256000000;#对表的某个分区进行归档
alter table test_rownumber2 archive partition(dt='20230324');#对已归档的分区恢复为原文件
alter table test_rownumber2 unarchive partition(dt='20230324');
3.2.4 方式四:hadoop getmerge
对于txt格式的文件可以使用hadoop getmerge命令来合并小文件。使用 getmerge 命令先合并数据到本地,再通过put命令回传数据到hdfs。
- 将hdfs上分区为pdate=20220815,文件路径为 /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/* 下载到linux 本地进行合并文件,本地路径为:/home/hadoop/pdate/20220815
hadoop fs -getmerge /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/* /home/hadoop/pdate/20220815;
- 将hdfs源分区数据删除
hadoop fs -rm /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/*
- 在hdfs上新建分区
hadoop fs -mkdir -p /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815
- 将本地合并后的文件回传到hdfs上
hadoop fs -put /home/hadoop/pdate/20220815 /user/hive/warehouse/xxxx.db/xxxx/pdate=20220815/*
参考文章:
HIVE中小文件问题_hive小文件产生的原因-CSDN博客
Hive教程(09)- 彻底解决小文件的问题-阿里云开发者社区
0704-5.16.2-如何使用Hive合并小文件-腾讯云开发者社区-腾讯云
)





)






)


:电子时钟(LED1602作为显示))

![[计算机网络]---网络编程套接字](http://pic.xiahunao.cn/[计算机网络]---网络编程套接字)
