目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《Oracle Database SQL Language Reference》
2、参考书籍:《PostgreSQL中文手册》
3、EDB Postgres Advanced Server User Guides,点击前往
4、PostgreSQL数据库仓库链接,点击前往
5、PostgreSQL中文社区,点击前往
6、Oracle Real Application Testing 官网首页,点击前往
7、Oracle 21C RAT Testing Guide,点击前往
8、Oracle Database 19c:Real Application Testing Overview,点击前往
9、数据库回放白皮书 11g,点击前往
10、论文四 原文:Consistent Synchronization Schemes for Workload Replay
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
Oracle数据库数据库回放功能之论文四翻译及学习
- 文章快速说明索引
- 摘要
- 1. 介绍
- 2. 一致的同步
- 2.1 不一致的类型
- 2.2 一致的同步方案
- 2.3 一致方案的范围
- 2.3.1 总排序
- 2.3.2 基于提交依赖的排序
- 2.3.3 基于对象依赖关系的排序
- 2.3.4 基于碰撞依赖的排序
- 2.3.5 使用更细粒度对象的研究
- 3. 高效实施
- 3.1发现依赖关系
- 3.2 实施细节
- 4 实验评价
- 5. 相关工作
- 6. 结论
- 7. 引用

文章快速说明索引
学习目标:
目的:接下来这段时间我想做一些兼容Oracle数据库Real Application Testing (即:RAT)上的一些功能开发,本专栏这里主要是学习以及介绍Oracle数据库功能的使用场景、原理说明和注意事项等,基于PostgreSQL数据库的功能开发等之后 由新博客进行介绍和分享!
学习内容:(详见目录)
1、Oracle数据库数据库回放功能之论文四翻译及学习
学习时间:
2024年02月07日 09:54:26
学习产出:
1、Oracle数据库数据库回放功能之论文四翻译及学习
2、CSDN 技术博客 1篇
注:下面我们所有的学习环境是Centos7+PostgreSQL15.0+Oracle19c+MySQL5.7
postgres=# select version();version
-----------------------------------------------------------------------------PostgreSQL 15.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.1.0, 64-bit
(1 row)postgres=##-----------------------------------------------------------------------------#SQL> select * from v$version; BANNER BANNER_FULL BANNER_LEGACY CON_ID
--------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- ----------
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production 0Version 19.3.0.0.0SQL>
#-----------------------------------------------------------------------------#mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.19 |
+-----------+
1 row in set (0.06 sec)mysql>
摘要
Oracle Database Replay 最近在 Oracle 11g 中引入,作为测试关系数据库系统的新颖工具 [9]。它包括记录生产系统中数据库服务器上运行的工作负载,然后在测试系统中的数据库服务器上重放它。工作负载重放的一个关键功能是同步 synchronization,它可以真实地再现真实的工作负载。它是一种对构成工作负载的重放请求 强制执行特定排序 的机制。与捕获的工作负载相比,它会影响请求并发级别以及重放结果的一致性。在本文中,我们定义了一致重放同步方案的类别,并首次研究了它们涵盖的范围以及它们所呈现的权衡。我们将迄今为止提出的唯一方案 [9](在 Oracle 11g Release1 中实现的方案)置于上述范围内,并表明它是粗粒度的,并且比必要的限制更多,通常会强制独立调用之间的依赖关系。
通过强制执行不必要的等待,它会降低可能的并发级别并降低性能。为了克服这些缺点,我们确定了范围内的最佳方案;它比同类产品的粒度更细,并且在不同的权衡之间取得了适当的平衡:它对重放的调用强制执行部分排序,从而最大限度地减少所需的等待次数并最大化并发级别,而不会影响重放结果的一致性。我们在 Oracle 11g 第 2 版中实施了这一新方案。我们的实验表明,对于主要的工作负载类别,它比现有方案能产生更好的质量重放。
1. 介绍
中国有句老话,“好客不换店,好店不换客”,这表明即使是对运作良好的东西进行微小的修改通常也是有风险的。这句话所表达的常识体现在,当涉及到大规模信息系统的变化时,坚决不情愿。
虽然安全,但这种保守和谨慎的做法阻碍了发展。需要进行更改以保持信息系统的最新性和竞争力;因此,需要进行广泛的测试以降低相关风险。通常,更改首先在测试系统上实施,并通过回归和压力测试进行验证。最后,在成功结束所有测试后,更改也会在生产系统上实施。测试的质量决定了将变更应用到生产系统后出现的问题的严重性和数量。执行大部分生产代码并在测试系统上产生实际负载的测试在为时已晚之前发现问题的成功率更高。
不幸的是,生成适当的合成工作负载来测试大规模应用程序是一个非常困难的问题[10]。尝试使用手动编写或工具生成的脚本或模拟模型来模拟生产系统场景已被证明是不充分、耗时且基本上无效的[9]。理想的情况是让测试系统承受实际的生产工作负载。在数据库系统上重放真实的工作负载可以对大规模数据库应用程序进行此类测试。我们将使用术语 数据库重放 或 工作负载重放 来描述此类测试。
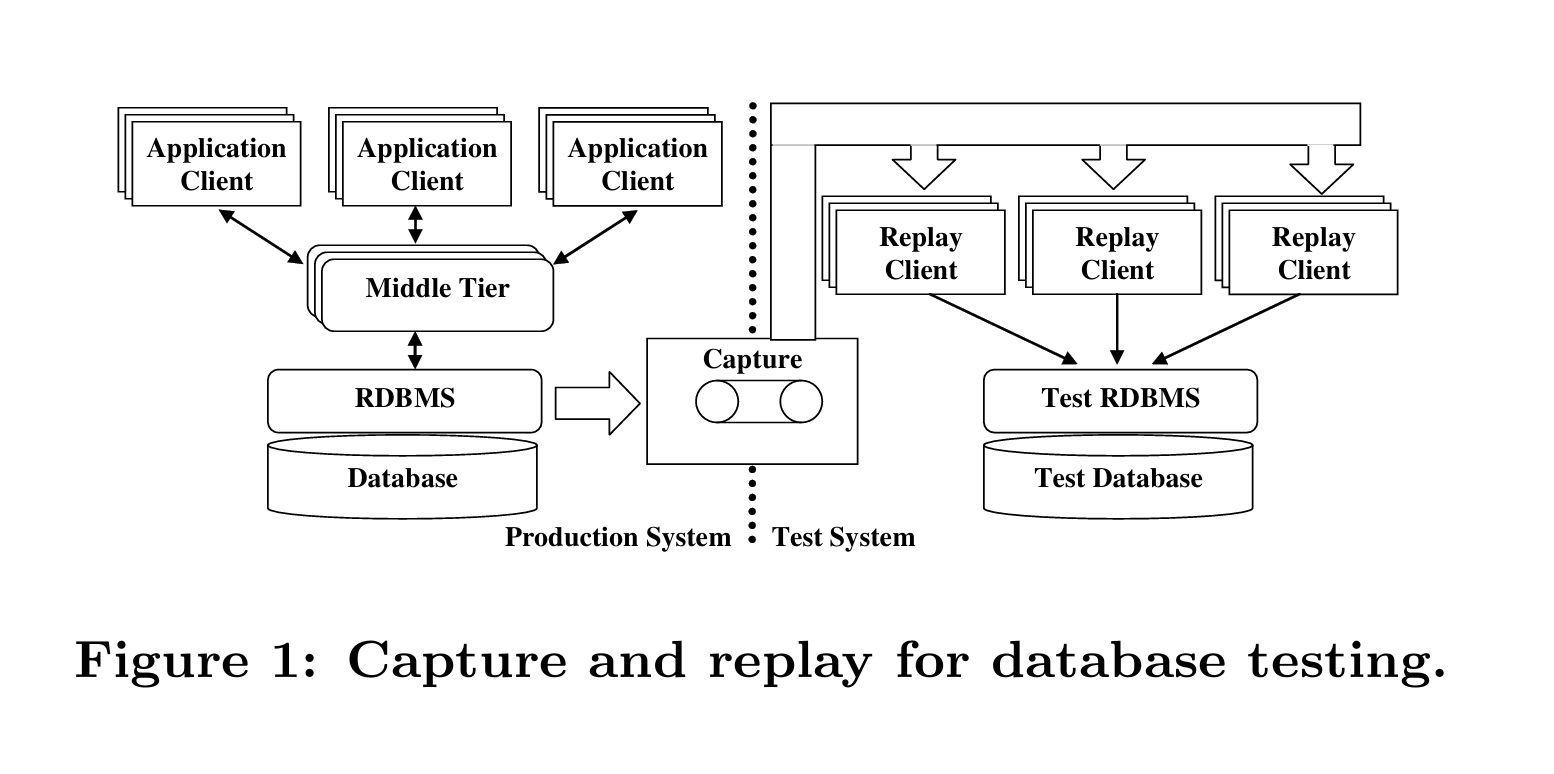
数据库重放最初是在 Oracle 11g [9] 中引入的。图 1 概述了其工作原理。生产系统中的数据库服务器上运行的真实工作负载(出现在图的左侧)以最小的开销记录,最好是在高峰时段。记录的工作负载(以下也称为捕获的工作负载)随后在测试系统的数据库服务器上重放,显示在图的右侧。重放这种真实的、通常很重且高度并发的工作负载对于测试目的具有巨大的潜力,包括回归和压力测试、调试和容量规划。
捕获的工作负载存储在多个捕获文件中。一个捕获文件对应于在生产系统上捕获期间处于活动状态的单个数据库连接。它存储通过相应连接在数据库服务器上发出的调用列表 the list of calls。重放工作负载涉及启动足够数量的客户端进程,这些进程读取适当的捕获文件并通过相应的连接在测试数据库服务器上发出记录的调用。目标是在重放期间重新创建与捕获期间相同数量的用户。
由于存在多个用户在数据库服务器上同时发出调用,因此能够真实再现真实工作负载的数据库重放的一个关键功能是同步,即对构成工作负载的重放调用强制执行特定排序的机制。所采用的同步方案强烈影响重放的以下重要属性:
- 请求并发:对来自不同重放客户端的特定调用强制排序不可避免地会导致等待。因此,它影响并发性。
- 结果一致性:重放期间数据提交和查询的顺序决定了重放数据库中返回或更新的数据。因此,重放的请求可能在完成的工作方面与捕获时的对应请求有所不同。
所有广泛使用的数据库管理系统(DBMS)都实现了一些并发控制机制来保证数据库的完整性[6,13,17]。这些机制中的大多数,包括两相锁定(2PL)及其变体,都是基于可串行性理论构建的[6]。这种机制确保它们生成的调度是可序列化的,即与由相同事务组成的串行调度等效(在串行计划中,事务在时间上不会重叠)。如果两个调度的单独调用读取和写入的值相同,则这两个调度是等效的。请注意,等效schedule可以是任何串行schedule。
不采用重放同步方案,只根据客户端的时间在重放期间简单地依赖并发控制机制来同步调用,这允许高并发性,类似于捕获期间的并发性,但会导致不一致的结果,即当调用争夺资源时,结果不确定。换句话说,调用分歧并且重放的工作负载看起来不再像捕获的工作负载,因为重放调度相当于任意串行调度,而不一定相当于捕获期间并发控制机制生成的调度。
另一方面,如果用于重放同步的方案对捕获的调用施加总排序,例如在捕获期间严格遵循这些调用的执行顺序,则重放期间返回或影响的数据将是一致的,即 ,与捕获期间相同,但与实际捕获的工作负载相比,工作负载的并发性将非常低,因为重放的工作负载本质上是序列化的。
理想的同步方案必须位于这两个极端之间。它应该对调用强制执行一些部分排序以保证一致性,同时还允许良好的并发潜力。请注意,重放同步方案不执行传统的并发控制,因为它的目标是重放一致性,而不是数据库完整性。因此,在本文的其余部分中,我们将理所当然地认为 DBMS 实现了一些额外的并发控制机制 [6, 13,17]。此外,我们将假设该机制提供快照隔离[6],这是几乎所有广泛使用的 DBMS 都支持的属性。
在之前的工作 [9] 中,提出了一种实用的同步方案,该方案对重放的请求强制执行部分排序,从而允许合理的并发级别,而不会出现数据分歧。在本文中,我们的目标是形式化现有重放同步方案的特征,发现新方案并提名最佳方案。下面,我们总结了我们的主要贡献:
-
一致方案的范围 ( Spectrum of consistent schemes):我们首次研究一致重放同步方案的范围。捕获和重放之间的结果一致性非常重要,因为它允许我们验证重放的工作负载是否与捕获的工作负载执行相同的工作。
-
现有方案在频谱中的位置 (Position of existing scheme within the spectrum):我们找到了迄今为止提出的唯一用于重放同步 [9] 的方案在上述频谱中的位置,并表明它是粗粒度的,并且比必要的限制更多,强制独立调用之间的依赖关系 。不必要的依赖关系可能会因等待时间增加而导致重放并发性降低。
-
高级方案的定义 ( Definition of an advanced scheme):当前的重放同步方案虽然在一些实际应用中足够,但仍有改进的空间。在本文中,我们提出了一种更细粒度的方案,可以在不同的权衡之间取得适当的平衡。它生成一个强制执行部分排序的计划,从而最大限度地减少来自不同客户端的调用之间所需的等待次数,并最大限度地提高并发级别,而不会影响重放一致性。我们的先进方案产生限制最少的调度,该调度仍然与捕获期间并发控制机制产生的调度等效。正如我们下面所解释的,它通过使用也在冲突可串行性理论中定义的一些类似的概念(例如,冲突依赖的概念)和构造(例如,依赖图)来实现这个目标[6]。 但是,它将它们用于不同的目的:确保重放一致性而不是事务可串行性
to ensure replay consistency rather than transaction serializability.。 -
高效实现 ( Efficient implementation):我们讨论了在数据库重放中有效实现一致同步方案的一些想法。我们的方法适用于已识别spectrum的所有方案,而不仅仅是高级方案。
-
实验评估 (Experimental evaluation):我们在 Oracle 11g 第 2 版中实现了新方案。我们针对前一个方案对其进行了实验评估并展示了结果。
本文的其余部分组织如下:在第 2 节中,我们研究一致同步方案的范围。在第 3 节中,我们描述了先进方案的有效实施。在第 4 节中,我们介绍了实验评估的结果。在第 5 节中,我们回顾了相关工作。最后,我们在第 6 节中进行总结。
2. 一致的同步
例行测试任何更改 都涉及 在测试系统上 运行某种形式的应用程序工作负载 并 验证正确性和性能。在数据库重放中,使用真实的工作负载;因此,可以通过比较两组结果来实现验证:在测试系统上运行捕获的工作负载的结果和在生产系统上运行相同工作负载时记录的原始结果。
为了使这种比较有意义,数据库重放必须保证重放工作负载的某些明确定义的行为;否则无法基于使用真实工作负载的事实进行验证。我们使用术语 重放一致性 来描述这种定义明确的行为。定性地讲,重放一致性意味着对数据库的每个重放请求必须执行与捕获期间相同的工作并操作相同的数据。只有这样才能比较捕获和重放的性能。
受到重放结果一致性重要性的启发,在本节中,我们研究重放期间可能发生的不一致类型,并定义一致性重放同步方案的类别。然后,我们确定这些方案涵盖的范围。最后,根据该spectrum点的特性,我们引入了一种用于工作负载重放的高级同步方案。
2.1 不一致的类型
让我们首先关注重放不一致的根源。它们也在其他地方进行过讨论[9];在这里,我们对它们进行分类,以帮助我们开发新的方法。首先,我们必须假设捕获开始时的初始数据库状态与重放开始时的初始状态相同,因为从任意状态开始实际上永远不会得到一致的结果。
该状态仅包括用户数据,并且对布局、索引、模式或任何其他物理数据库特性没有任何假设。
通过使用 DBMS 的标准功能(例如导出/导入或备份/恢复)来满足此要求相当简单。
做出上述假设后,我们可以根据相关结果的差异来源来识别两种类型的重放不一致:系统性和随机性(systematic and random)。我们在下面定义它们并随后给出一些示例:
-
系统不一致 (Systematic inconsistency):当两个 依赖于冲突(collision-dependent) 的调用之间的相对顺序发生变化时,这种类型的不一致以可再现的方式出现。假设DBMS保证快照隔离[6],如果(a)至少其中一个调用通过提交一些更改修改了数据库的状态,并且(b)两个调用都访问至少一个共同的数据库对象,则两个调用是冲突相关的。为了简单起见,除非另有说明,否则我们可以认为数据库对象仅仅是一个数据库表,因为我们关注的是关系数据库。对于更复杂的对象,例如视图,我们假设它们总是可以被分析到定义它们的基表。最后,对于细粒度类型的数据库对象(例如,块和行),需要更多的注意。我们将在2.3.5节详细介绍它们。
-
随机不一致(Random inconsistency):当调用取决于与运行时状态相关的某些值或条件时,这种类型的不一致会以任意巧合的方式出现。通常,导致随机不一致的调用是使用系统日期和时间的调用,或生成并使用随机数的调用。
示例1(系统不一致):这里,我们描述一个极端的、想象的情况,仅供说明之用。假设一家拥有 1,000,000 名美国员工的大型公司遭受了重大金融危机的打击。想象一下,公司财务主管执行如下所示的查询 Q1,以了解有多少美国员工为该公司工作以及他们的平均工资是多少。假设 DBMS 在相当长的时间(例如 1 秒)后响应,因为它评估超过一百万行的两个聚合函数(计数和平均值),并返回以下结果:1,000,000, $60,000。基于这一结果,公司首席执行官决定将除她本人之外的所有员工外包到印度。为此,她执行查询 Q2。
Q1: select count(*), avg(salary) from emp where country=‘USA’;
Q2: update emp set country=‘India’ where country=‘USA’ and job title<>‘CEO’;
为了便于说明,我们假设 Q2 自动提交其更改。在这种情况下,我们可以很容易地看出 Q1 和 Q2 是冲突相关的,因为 (a) Q2 通过更改表 emp 来修改数据库的状态,并且 (b) 它们都访问相同的数据库对象(表 emp)。
此外,假设数据库管理员正在计划对公司的系统进行更改,例如升级 DBMS 版本,但首先,他想要测试其对由 Q1 和 Q2 组成的工作负载的影响。为此,他在测试数据库上重放工作负载。重放期间执行 Q1 和 Q2 有两种可能的顺序:Q1→Q2 和 Q2→Q1(符号“→”表示 先行)。回想一下,第一个排序(Q1→Q2)是在捕获期间在生产系统上使用的。我们假设同步方案在重放期间选择第二个(Q2→Q1)。
Q2 执行后,表 emp 只存储一行,对应于一位美国员工,即 CEO。在 Q2 之后执行 Q1 返回 1,$600,000,假设 $600,000 是 CEO 的工资。此结果与 Q1 之前的捕获期间的结果不同。此外,在重放期间,Q1 结果的计算变得微不足道,因为聚合函数在单行上运行,而不是像捕获期间那样在一百万行上运行。因此,在重放期间,考虑到 emp 上的一些适当索引,Q1 的响应时间必须快几个数量级,例如 0.01 秒。显然,速度的提升不能归因于 DBMS 的升级。
总而言之,对两个依赖于冲突的调用使用不同的顺序会在捕获和重放之间产生系统不一致。正如预期的那样,结果不同。工作也不同,因此重放性能不能用作测试的更改将对生产系统产生什么影响的指标。
示例2(随机不一致):想象一下示例1的公司在2010年的财务状况有所恢复;因此,10 月份雇用了 100,000 名新员工,但 2010 年没有再雇用员工。当年 10 月份,首席执行官执行了如下所示的第三季度,以查看该月的新员工数量。在 Q3 中,函数to_char 将日期转换为具有某种给定格式的字符串,h_date 是表 emp 的一列,用于存储员工的雇用日期,sysdate 是返回系统日期的函数。假设Q3的结果为100,000,其响应时间为0.5秒。
Q3: select count(*) from emp where to char(h date,‘mmyyyy’)=to char(sysdate,‘mmyyyy’);
下个月,重放包含 Q3 的工作负载会产生与 Q3 不同的结果(0,因为 10 月之后没有新员工招聘)。此外,在这次重放期间,Q3 的响应时间要快得多(比如 0.01 秒),因为聚合函数 count 对空行组进行操作。在这种情况下,由于随机不一致而发生了分歧,因为 Q3 的结果取决于运行时的状态(在本例中为 sysdate 返回的日期)。
2.2 一致的同步方案
在上一小节中研究了重放不一致的根源之后,在本小节中,我们定义了用于工作负载重放的一致性同步方案类别。
让我们首先关注系统性的不一致。显然,它在重放期间的发生在很大程度上取决于所采用的同步方案,因为系统不一致的根源是冲突相关调用的顺序发生变化。因此,一致的重放同步方案的最低要求是确保冲突相关的调用始终以与捕获期间相同的顺序重放,以防止系统不一致。请注意,此顺序是由捕获期间在生产系统上运行的并发控制机制的调度所决定的。
现在让我们关注随机不一致。很容易观察到,这种不一致是某些捕获的调用的类型所固有的,这些调用取决于运行时的状态,如上所述。由于它归因于这些调用的性质而不是它们的顺序,因此同步无法解决相应的问题。为此目的,需要一些与所采用的同步方案正交的附加机械。总之,解决随机不一致问题就是关联和再现随机结果。
现有技术[9]通过捕获取决于生产系统的运行时状态的真实值(例如,调用Q3的sysdate的结果),然后使用这些记录的值来替换回放期间基于测试系统的运行时间状态生成的值,从而避免了这种情况。
在本文中,我们将理所当然地认为随机不一致不存在,因为我们的重点是同步方案,并且与它们正交的技术可以很好地解决它。
根据上面的观察,我们可以很容易地推断,通过避免系统和随机不一致的工作负载重放遵循与捕获期间执行的调度相同的调度,因为这样的重放保留了依赖于冲突的调用的相同顺序,并消除了所有可能的分歧源。
在了解了一致同步方案应该如何表现之后,我们给出了它们的正式定义。我们从一些在整篇论文中都会用到的符号开始:
- 设S表示给定工作负载中所有调用的集合,设a, b∈S是其中两个调用
- 此外,假设存在以下谓词:如果在捕获期间a在b之前执行,则precedes(a, b)返回true,否则返回false
- Commit (a)返回true,如果通过提交一些更改来修改数据库状态,否则返回false
- Access common object(a, b)如果a和b共同访问数据库对象则返回true,否则返回false
- must wait(a, b)如果a必须等待b完成才能重放a则返回true,否则返回false
最后,让我们定义以下集合:

显然,以下关系对于这些集合成立:
Spre⊇Scom⊇Scol, and Spre⊇Sobj⊇Scol
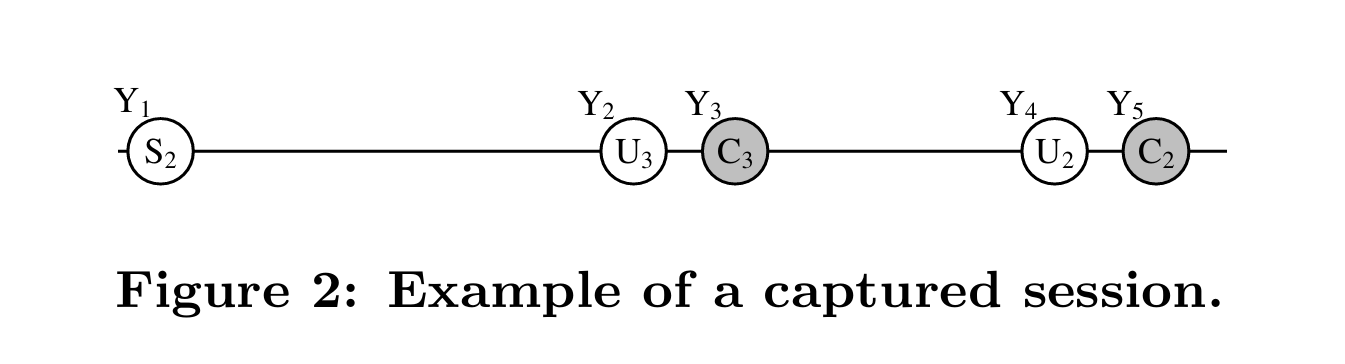
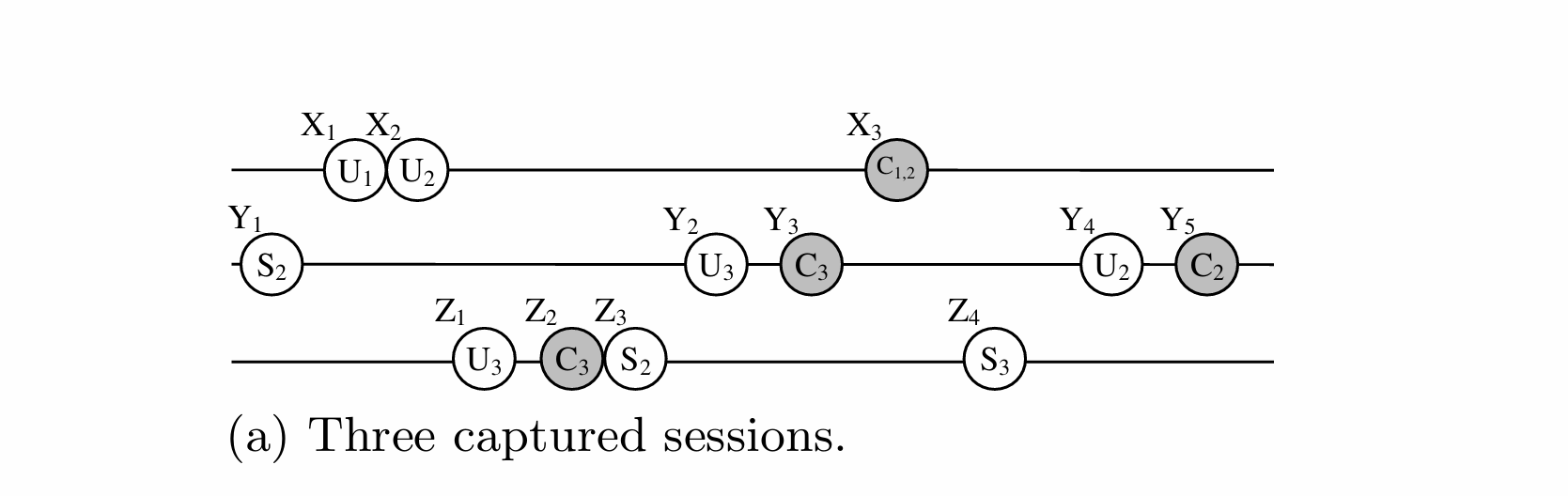
为了解释我们的符号,让我们举一些例子。假设某个捕获的会话 Y 包含五个调用:Y1-Y5(图 2)。横轴表示时间;因此,在捕获期间,Y1 在 Y2 之前执行,Y2 在 Y3 之前执行,依此类推。此外,假设三种类型的调用:选择、更新和提交,分别用字母 S、U 和 C 表示。为了更好地区分提交调用和非提交调用,我们对前者使用灰色(例如 Y3),对后者使用白色(例如 Y1)。每个调用都对一组对象进行操作,由字母 S、U 或 C 后面的下标表示。例如,Y1 从对象 2 选择一些结果,Y2 更新对象 3,而 Y3 提交对对象 3 的更改。
In our example, precedes(Y2, Y5), commit(Y3), and access common object(Y2, Y3) return true, but precedes(Y4,Y1), commit(Y1), and access common object(Y1, Y3) false.
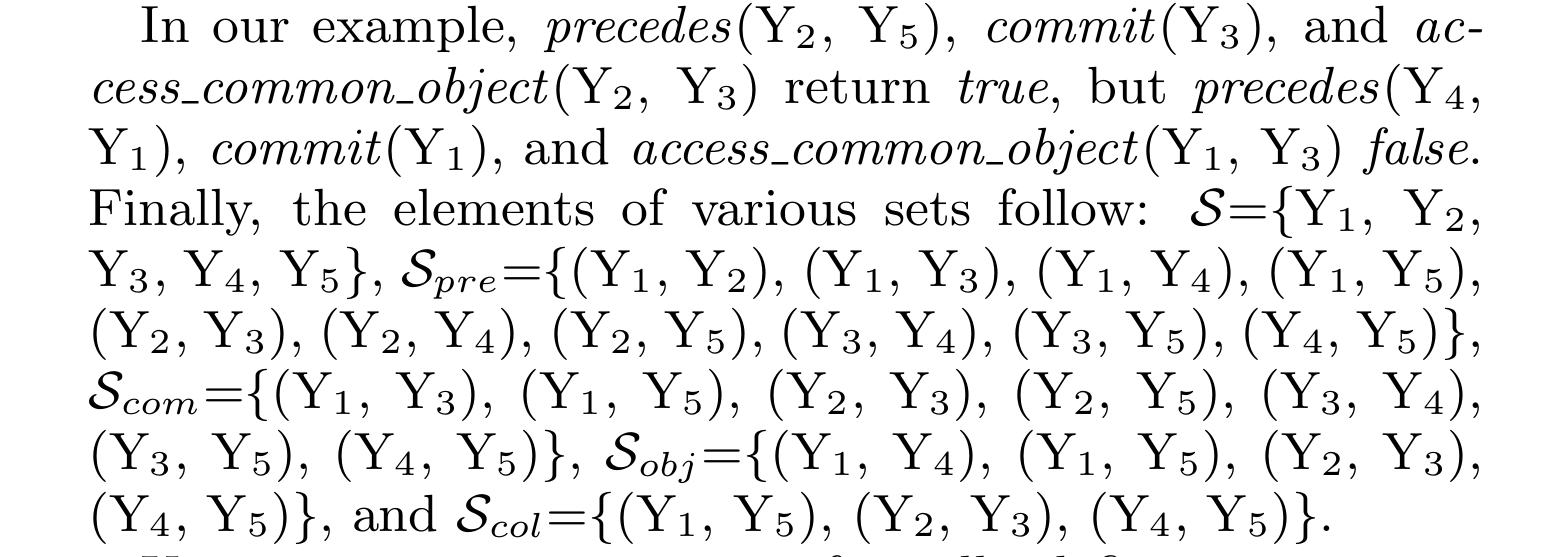
最后,各种集合的元素如下:
S={Y1, Y2,Y3, Y4, Y5},Spre={(Y1, Y2), (Y1, Y3), (Y1, Y4), (Y1, Y5),(Y2, Y3), (Y2, Y4), (Y2, Y5), (Y3, Y4), (Y3, Y5), (Y4, Y5)}Scom={(Y1, Y3), (Y1, Y5), (Y2, Y3), (Y2, Y5), (Y3, Y4),(Y3, Y5), (Y4, Y5)}, Sobj={(Y1, Y4), (Y1, Y5), (Y2, Y3),(Y4, Y5)}Scol={(Y1, Y5), (Y2, Y3), (Y4, Y5)}
使用我们的符号,我们可以正式定义一致的重放同步方案,如下所示。
定义(一致性规则 consistency rule):一个重放同步方案是一致的,如果满足一致性规则:
∀(a, b) ∈ S2((a, b) ∈ Scol ⇒ must wait(b, a))
2.3 一致方案的范围
从概念上讲,工作负载重放的一致性同步方案的主要工作如下:给定一对调用(a, b)∈S2,它必须决定其中一个是否必须等待另一个完成以保证一致性。
有三种可能的互斥决策:
Decision 1: must wait(a, b)
Decision 2: must wait(b, a)
Decision 3: (¬must wait(a, b)) ∧ (¬must wait(b, a))
如下所示,根据做出上述决策的策略的严格或宽松程度,我们可以将同步方案放置在一致方案范围内的相应位置。
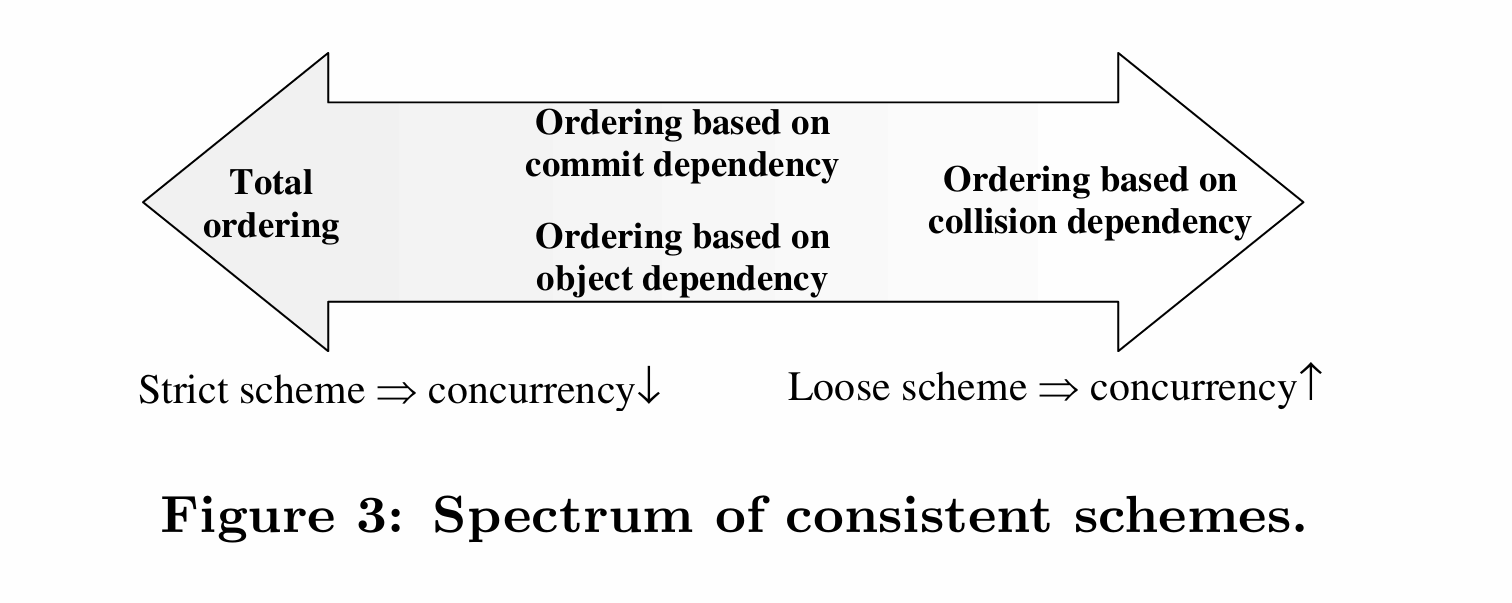
图 3 直观地展示了该范围。当我们在其中从左向右移动时,我们从更严格的计划转向更宽松的计划;因此,重放并发水平朝这个方向增加。最严格的方案(左侧)对构成工作负载的所有调用强制执行总排序。较宽松的方案会根据提交、对象或冲突依赖性强制执行某些部分排序。实际上,部分排序意味着可以同时发出两个或多个调用,而不必担心它们会在执行的工作类型方面相互影响。他们可能会争夺DBMS资源,这是我们需要测试的方面之一。下面,我们讨论频谱的不同点。
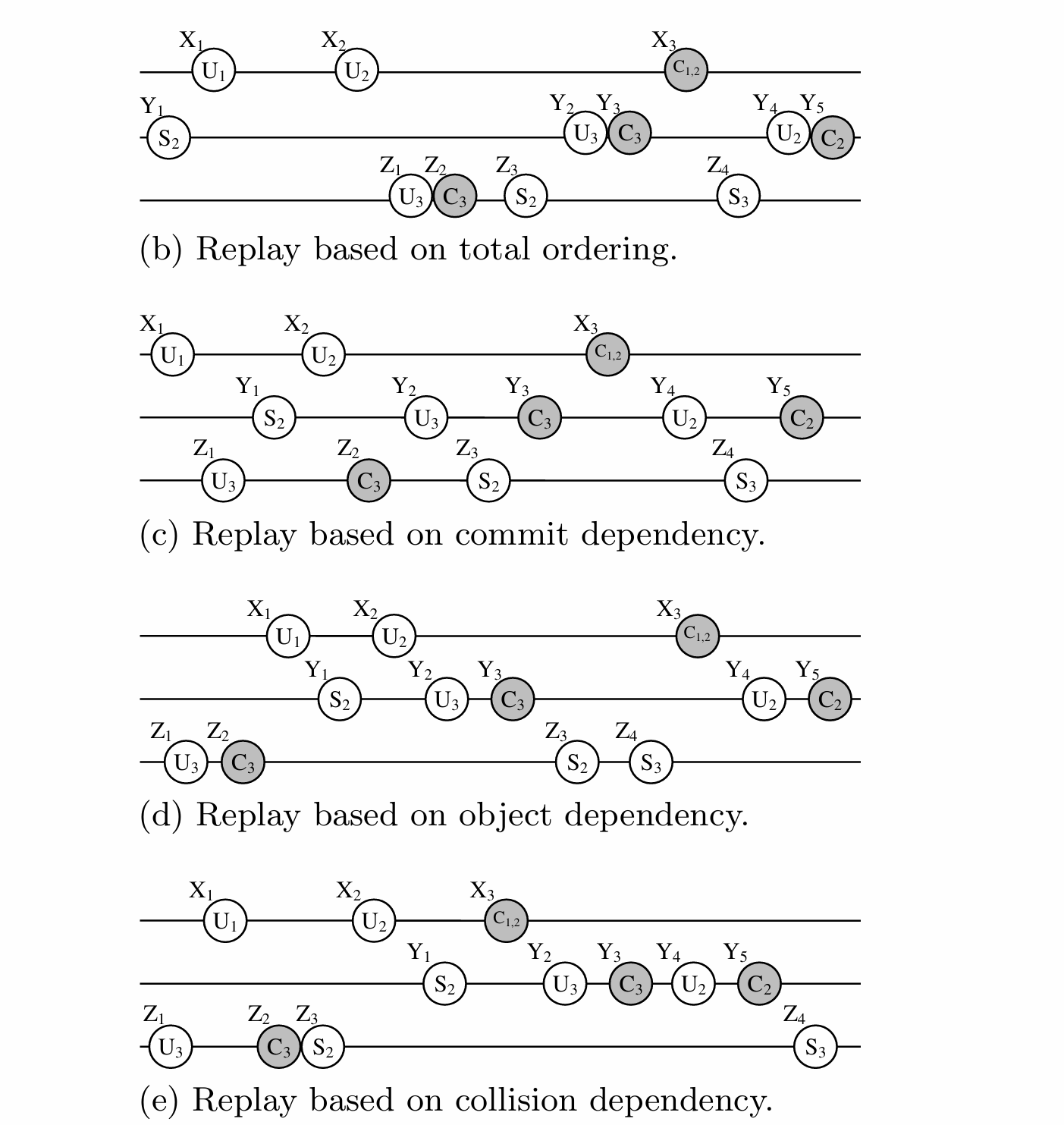
为了更好地解释范围内不同点之间的差异,让我们扩展图 2 的运行示例,并假设我们已捕获在生产系统上运行的三个并发会话,即 X、Y 和 Z(图 4(a))。然后,图 4(b)-4(e) 显示了使用不同同步方案重放这些会话的示例。我们在下面提供更多详细信息。
2.3.1 总排序
在构成捕获的工作负载的所有调用中强制执行特定的总排序(与捕获期间发生的排序完全相同)是避免系统不一致的最直接方法。通过在重放期间保留所有调用的原始顺序,基于全排序的同步方案保证它还保留冲突相关调用的顺序;因此,它是一致的。
形式上,此类方案强制执行总排序规则:
∀(a, b) ∈ S2((a, b) ∈ Spre ⇒ must wait(b, a)).
由于 Spre ⊇ Scol,如果 (a, b) ∈ Scol,则 (a, b) ∈ Spre。因此,通过强制执行全排序规则,此类同步方案也间接强制执行一致性规则。因此,它是一致的。
在我们的运行示例中,如果捕获的工作负载是图 4(a) 中的工作负载,则基于全排序的同步方案可能会生成如图 4(b) 中所示的重放工作负载。如果我们比较这两个工作负载,我们可以观察到,尽管某些调用在重放期间发生了时间转移,但它们的顺序仍然保持不变。
尽管一致,但基于全序的同步方案对于重放并发来说限制太大。实际上,由于在每对调用之间强制执行特定的顺序,因此这是可能的最严格的方案。此属性解释了为什么它出现在图 3 频谱内的第一个位置(左侧)。例如,在图 4(b) 的示例中,调用 X2 由于某种原因在重放期间延迟执行。不幸的是,基于全排序的同步方案必须将此延迟传播到所有后续调用,以便保留指定的排序。因此,即使调用 Z1、Y2 以及它们的所有后续调用(其中大部分与 X2 是冲突无关的)也必须等到 X2 完成。尽管这种同步方案保证了一致性,但它不允许实现实际的并发性。它仅用于说明目的。
2.3.2 基于提交依赖的排序
在描述了最严格的极端情况(基于全排序的方案)之后,让我们继续讨论更宽松的方案。强制执行某些部分排序的有前途的候选方案可以基于提交依赖性。该方案在 Oracle 11g 中可用,并且已在其他地方提出过 [9]。利用任何一对非提交调用都不会依赖于冲突的特性,基于提交依赖性的方案不会在非提交调用之间强制执行特定的顺序。另一方面,如果至少有一个调用通过提交一些更改来修改数据库的状态,它会在两个调用之间强制执行特定的顺序。
正式地,此类的方案强制执行提交依赖规则:
∀(a, b) ∈ S2((a, b) ∈ Scom ⇒ must wait(b, a)).
由于 Scom ⊇ Scol,如果 (a, b) ∈ Scol,则 (a, b) ∈ Scom。因此,通过强制执行提交依赖规则,此类同步方案也间接强制执行一致性规则。因此,它属于一致方案的范围(图 3)。
在我们的运行示例中,如果捕获的工作负载是图 4(a) 中的工作负载,则基于提交依赖性强制排序的同步方案可能会生成如图 4© 中所示的重放工作负载。在此示例中,我们可以观察到两个连续提交调用(灰色圆圈)之间的非提交调用(白色圆圈)之间没有特定的顺序。此属性允许更多的自由,因此在提交调用之间的时间段内实现了更好的并发级别。例如,在图 4© 中,调用 X2 在重放期间再次延迟执行。
图 4(b) 中也发生了同样的情况。不同的是,这一次,Z1 不必等待,因为它们都是非提交调用。因此,Z1 和 X2 在重放期间已重新排序。由于它们是碰撞无关的,因此这种重新排序不会损害一致性。请注意,类似的重新排序出现在两个提交调用之间的多个非提交调用中。在图 4© 的示例中,这包括调用 Y2 和 Z3,以及 Y4 和 Z4。
据我们所知,基于提交依赖性强制排序的同步方案是现有文献中迄今为止提出的唯一重放同步方案[9]。它可能比使用总排序的更松散,这解释了为什么我们将它放在图3的第二个位置,但它仍然比必要的更严格,因为它在决定它们的排序时没有考虑到一对调用访问的数据。因此,如果这些调用中至少有一个修改了数据库状态,则它会在访问完全不相交的数据集的调用之间强制执行等待,尽管此类调用是与冲突无关的。例如,在图 4© 的示例中,同步方案将在以下调用对之间强制执行等待,因为至少其中一个调用提交了一些更改:
must wait(Z2,X2), must wait(Z2, Y1), must wait(Z4, X3).
在此示例中,上述调用是与冲突无关的。通过强制执行不必要的等待,此类方案仍然可能会降低并发性和重放性能。
2.3.3 基于对象依赖关系的排序
遵循与基于提交依赖性的方案之一类似的一些逻辑,基于对象依赖性的方案形成另一类方案,其在构成捕获的工作负载的调用之间强制执行某些部分排序。他们利用的特性是,其成员访问不相交的对象集的任何调用对都是冲突无关的。因此,基于对象依赖性的方案从不强制执行此类调用对之间的特定顺序。另一方面,如果这些调用至少访问一个共同的数据库对象,它们会在两个调用之间强制执行特定的顺序。
正式地,此类的方案强制执行对象依赖规则:
∀(a, b) ∈ S2((a, b) ∈ Sobj ⇒ must wait(b, a)).
由于 Sobj ⊇ Scol,如果 (a, b) ∈ Scol,则 (a, b) ∈ Sobj 。因此,通过强制执行对象依赖规则,此类同步方案也间接强制执行一致性规则。因此,它是一致的。
在我们的运行示例中,如果捕获的工作负载是图 4(a) 中的工作负载,则基于对象依赖性强制排序的同步方案可能会生成图 4(d) 中的重放工作负载。在此示例中,我们可以观察到访问不相交的数据库对象集的调用之间没有特定的顺序。与全排序相比,此属性允许更多的自由度,因此可以实现更好的并发级别,因为它避免了一些不必要的延迟。例如,在重放期间(图 4(d)),虽然调用 Y1 和 X1 由于某种原因延迟开始,但这种延迟并没有影响调用 Z1 和 Z2,它们现在已成为第一个执行的调用。在重放期间可以将 Z1 和 Z2 与 X1 和 Y1 重新排序,因为前一组调用访问对象 3,而后一组调用分别访问对象 1 和 2。因此,基于对象依赖的方案永远不会在它们之间强制等待。在我们的示例中,对于其他冲突无关调用对(例如 Z4 和 X3,以及 Z3 和 Y3)也可以进行类似的重新排序。
使用基于对象依赖的排序的同步方案可能比使用总排序的同步方案更宽松,这解释了为什么我们将其放在频谱的右侧(图3),但它仍然比必要的更严格,因为它在决定提交和非提交调用的排序时不区分它们。因此,即使在非提交调用之间,如果它们访问共同的对象,它也会强制执行等待,尽管它们是冲突无关的;因此,它会产生一些不必要的等待(只读依赖项)。例如,在图 4(d) 中,同步方案在以下调用对之间强制执行等待,只是因为它们访问共同的对象:must wait(X2,Y1)、must wait(Z3, X2)。上述调用是非提交的,因此与冲突无关。通过强制执行不必要的等待,此类方案仍然会降低并发性并降低重放性能。
当要比较基于提交依赖性的重放同步方案和基于对象依赖性的重放同步方案中哪一种更严格时,答案取决于给定工作负载的属性。更详细地说,哪一个更严格取决于相应集合的大小之间的关系,即 |Scom| 和|Sobj|。集合包含的元素越多,相应的同步方案必须执行的等待时间就越长,因此就越严格。例如,如果对于给定的工作负载 |Scom| > |Sobj |,那么基于提交依赖的方案对于该工作负载来说更加严格。根据观察,在一般情况下,我们无法知道两者之间哪个方案更严格,在图3中,我们将基于提交依赖关系强制排序的方案与基于对象依赖关系强制排序的方案放置在横轴上的相同坐标上。
2.3.4 基于碰撞依赖的排序
到目前为止,我们提出的所有同步方案都比必要的更严格,因为它们强制在冲突无关的调用对之间强制等待。基于冲突依赖的方案通过直接执行一致性规则(第 2.2 节)克服了这个缺点。
在我们的运行示例中,如果捕获的工作负载是图 4(a) 中的工作负载,则基于冲突依赖性强制排序的同步方案可能会生成图 4(e) 中的重放工作负载。在此示例中,我们可以观察到调用 Y1(捕获期间的第一个调用)由于某种原因在重放期间延迟。然而,在它之前已经执行了大量其他调用,而无需等待它:X1、X2、Z1、Z2 和 Z3。如果排序基于提交依赖性,则 Z2 必须等待。如果排序基于对象依赖性,则 X2 和 Z3 必须等待。然而,此类方案不会遇到这些问题,因为它强制要求最少的等待次数,即仅在与冲突相关的调用之间强制执行。
前面的例子表明了松散方案的优点。实际上,正如我们上面所示,基于冲突依赖性对调用进行排序的方案是最宽松的方案(这解释了为什么我们将其放置在图 3 的频谱中的最右侧位置)。因此,它比现有文献(第 2.3.2 节)中提出的方案更有希望,因此也是我们选择的方案。我们在 Oracle 11g 第 2 版中实施了新方案,作为现有方案的替代方案。
2.3.5 使用更细粒度对象的研究
在上一小节中,我们提出了基于冲突依赖性强制排序的方案,并认为它们是一致方案范围内最宽松的方案。此外,在2.1节中,我们提到为了简单起见,我们认为数据库对象只是一个表。因此出现的问题是,如果我们使用更细粒度的对象(例如块或行),我们是否可以设计出更宽松的方案。
直观上,这种选择听起来很合理。考虑更细粒度的对象应该会减少依赖项的数量,因此可以产生一种方案,在调用之间强制执行更少的等待次数,从而在重放期间实现更高级别的并发性。不幸的是,这种直观上合理的方法在实践中行不通,因为它可能会产生系统的不一致。我们用一个反例来证明这一点。
反例(使用块或行):假设我们在示例 1 和 2(第 2.1 节)中描述的是同一家公司。设其数据库包含一个表emp,存储有关1,000,000名员工的信息,对应于R1-R1,000,000的1,000,000行。此外,考虑到在生产系统上,表 emp 由 20,000 个块 B1-B20,000 组成。让每个块适合 50 行;因此,它们都已满。此外,假设该公司收购了另一家同样拥有 1,000,000 名员工的公司。最后,假设两个查询 Q4 和 Q5,用 SQL 表示如下:
Q4: select avg(salary) from emp;
Q5: insert into emp (select * from acquired emp);
Q4 打印出所有员工的平均工资,而 Q5 将被收购公司的员工插入到第一家公司的表 emp 中。为简单起见,我们假设 Q5 自动提交其更改。在 Q5 之前执行 Q4 会聚合块 B1-B20,000 中的行 R1-R1,000,000。
此外,Q5 在 emp 中插入 1,000,000 个新行,例如 R1,000,001-R2,000,000。由于所有块 B1-B20,000 均已满,因此新行将进入新分配的块,例如 B20,001-B40,000。
如果我们考虑块级别的对象,则 Q4 和 Q5 是冲突无关的,因为它们访问不同的对象(前者访问块 B1-B20,000,而后者访问块 B20,001-B40,000)。同样,如果我们考虑行级别的对象,则 Q4 和 Q5 再次是冲突无关的,因为它们访问不同的对象(前者访问行 R1-R1,000,000,而后者访问 R1,000,001-R2,000,000)。在这两种情况下,基于冲突依赖性对调用进行排序的方案不会在重放期间强制这些调用之间等待。这会导致系统不一致,因为如果在重放期间重新排序 Q4 和 Q5,Q4 将聚合 2,000,000 行 (R1-R2,000,000),而不是在捕获期间聚合的 1,000,000 行。这种差异将影响第四季度的结果和表现。
显然,基于块级或行级依赖的方案不能保证一般情况下的一致性。理论上,识别查询之间重叠、动态确定其读取集以试图解决问题的解决方案是可能的。然而,我们坚信,由于其预期的高度复杂性,它们在实际系统中并不实用。因此,我们不再进一步调查它们。
3. 高效实施
Oracle Database Replay的第一个版本的体系结构已在之前的工作中进行了详细描述[9]。我们在第1节和图1中对其进行了简要总结。在本节中,我们通过解释我们在该工具的第二个版本中实现的扩展来扩展原始出版物中的描述,使其支持本文中提出的高级同步方案。
3.1发现依赖关系
Oracle Database Replay的工作原理如下:给定数量的进程,称为Replay客户机(图1),扫描捕获文件中记录的调用,并通过请求执行这些调用的足够数量的连接向测试数据库服务器发送适当的并发请求。通过这样做,重放客户端模拟捕获期间在生产系统上运行的应用程序和中间层。
为了确保重放结果的一致性,在执行调用 a 之前,测试数据库服务器首先根据所采用的同步方案识别 a 所依赖的所有其他调用,并强制等待 a 直到所有调用都完成。由于工作负载通常包含大量调用,因此动态搜索此类依赖项的计算成本可能非常昂贵。因此,由于重放期间时间至关重要,因此重放同步的有效实现需要以离线方式执行预处理算法,该算法提前构建调用之间的依赖关系图G。
G 是有向无环图 (DAG),表示组成工作负载的调用之间的偏序。这些调用是 G 的顶点。根据所采用的同步方案,如果 Must wait(b, a) 为真,则有向边从顶点 a 开始并在顶点 b 结束。在我们的问题中使用依赖图类似于冲突可串行性理论中类似图的使用[6]。然而,与后者不同的是,我们的图在设计上是非循环的。此外,我们用它来解决另一个问题:重放一致性,而不是事务可串行性。
算法 BuildDependencyGraph 以伪代码形式展示了我们高效的预处理算法,该算法计算工作负载重放的依赖关系图。它的输入是包含捕获的工作负载的调用集 S。其输出是依赖图 G。
最初,算法将 G 的顶点设置为 S(第 1 行),并将 G 的边初始化为空集(第 2 行)。然后,它枚举S中潜在依赖的所有候选调用对,以便识别G的边。为此,它访问S中的每个调用a,按照存储a的捕获文件的标识符cfa和捕获期间开始执行a的开始执行时间 ta (第3行)排序。然后,它搜索a可能依赖的所有其他调用b。
上述 b 搜索的直接实现将详尽地枚举工作负载的所有可能调用。由于这些调用的数量通常非常大,因此详尽的方法是不切实际的。为了克服这个缺点,下面我们提出了一些属性,基于这些属性,我们的算法可以通过提前预测 同步方案不需要在特定的调用对上工作 来修剪其搜索空间。

属性 1(避免在同一捕获文件 capture file 中搜索):存储在特定捕获文件中的所有调用都是通过生产系统上的同一连接发送到数据库服务器的调用。通过同一连接进入数据库服务器的任何内容都应该以相同的方式重放。这种行为以更真实的方式模仿数据库所看到的生产工作负载。回想一下,重放期间的调用重新排序试图在来自不同执行线程的请求之间实现更好的并发性,而不是改变来自同一线程的调用的自然顺序,因为后一种更改会修改重放期间用户的行为。因此,尽管可能,但不建议对存储在同一捕获文件中的调用进行重新排序。
基于此属性,BuildDependencyGraph 不会搜索存储在同一捕获文件中的依赖调用;因此,对于每个调用 a,它都会扫描每个捕获文件 cf(第 4 行),但会跳过存储 a 的文件 cfa(第 5-7 行)。
属性 2(将搜索限制在一定范围内):对于除 cfa 之外的每个文件 cf,我们的算法都会扫描其中存储的调用(第 12 行)。正如我们下面所解释的,它不是对整个文件执行耗时的扫描,而是将搜索空间限制在特定的调用范围内。
令 ta 为捕获期间执行 a 的时间,a.previous 为调用文件 cfa 中 a 的前一个调用(如果 a 是 cfa 中的第一个调用,则 a.previous 调用可以为 NULL)。此外,让 b0 和 b∞ 是我们的算法默认存在于 cf 中的两个人工调用,假设 tb0=0 且 tb∞=∞。他们分别扮演cf中第一个和最后一个调用的角色。它们不会重放,而仅用于更轻松地处理边界情况,如下所述。
此外,令 RecallDependency(第 9 行)为返回 cf 中的调用(例如 bmin)的方法,a.previous 调用必须等待该调用。如果存在这样的调用,则它是唯一的(基于下面的属性 3),并且 BuildDependencyGraph 一定已经在之前的迭代中找到了它,因为它处理按开始执行时间排序的调用(第 3 行)。否则,如果 a.previous 调用为 NULL,或者这样的调用不存在,则 RecallDependency 返回 b0,即上面定义的人工调用。
最后,设 FindFirstCallAfterGivenTime(第 10 行)为返回 cf 中第一个调用(例如 bmax)的方法,使得 ta < tbmax(bmax 是 cf 中在 a 之后执行的第一个调用)。如果这样的调用不存在,则该方法返回 b∞。
根据前面的定义,以下优先级成立:bmin→a.previous_call→a→bmax。因此,我们的算法(第 12 行)足以将 cf 中 a 需要等待的候选调用视为仅属于范围 (bmin, bmax) 的调用。请注意,上述范围两侧都是开放的。因此,不包含bmin和bmax,即使bmin=b0、bmax=b∞也有效。
属性 3(按相反时间顺序搜索并在第一个匹配处停止):对于它生成的每个候选对,例如 (a, b),BuildDependencyGraph 调用方法 ApplyRule(第 13 行)。根据它所采用的同步方案,ApplyRule 结合了对 predicates 的某些适当子集的评估,commit 和 access common object(在第 2.2 节中定义)。它返回一个决策,可以是决策 1、2 或 3(这三个选项已在第 2.3 节中定义),指示各个调用 a 和 b 之间是否需要特定的排序。请注意,ApplyRule 是我们算法中唯一依赖于特定同步方案的部分。除此之外,我们的算法足够通用,适用于我们在上一节中描述的所有一致同步方案。
如果ApplyRule返回Decision 1,则调用a必须等待b;因此,算法在 G 的边中添加边 b→a(第 16 行)。我们认为,在找到 b(a 必须等待的 cf 中的调用)之后,我们的算法不需要继续搜索 cf 中 b 之前的 a 所依赖的其他调用;a 将在所有这些之后间接执行,因为它将在 b 之后显式执行,并且根据属性 1,所有这些都将在 b 之前执行。因此,对其中任何一个强制执行显式等待都是多余的。此观察结果解释了属性 3,基于该属性,BuildDependencyGraph 按相反的启动执行时间顺序在 cf 中搜索,并在找到第一个匹配项后停止搜索。BuildDependencyGraph 实现了反向启动执行时间顺序搜索,如下所示:它使用 cf 中位于 bmax 之前的调用来初始化 b(第 11 行)。这是具有最大启动执行时间的调用,属于属性 2 定义的范围。
只要ApplyRule(第13行)返回决策3,表明a和b是独立的,算法就会向后迭代,将cf中旧b之前的调用视为b的新值(第22-24行)。找到第一个匹配项(第 15-18 行)后,算法将找到的标志设置为 TRUE。这会强制算法退出第 12 行的循环,从而中断搜索。
到目前为止,我们已经解释了当 ApplyRule 返回决策 1 或 3 时会发生什么。
决策 2 意味着调用 b 必须等待 a。在我们的设置中,这样的结果是不可能的,因为我们的算法访问的每个调用 b 都属于属性 2 定义的范围,并且根据定义,该范围内的所有调用必须在捕获期间在 a 之前执行。在决策 2 的不可能情况下(第 19-21 行),我们的算法为了完整性而引发错误。
属性 4(修剪 G 中的边):在枚举所有必需的调用对并构造图 G 后,BuildDependencyGraph 最终调用方法 Reduce(第 29 行)。Reduce 修剪 G 中的一些冗余边。更详细地说,它计算 G [5] 的传递约简,它是 G 的子图,具有最少的边数,并表示与 G 相同的偏序。由于 G 是 DAG ,它的传递约简是唯一的并且可以在线性时间内找到[14]。通过利用传递性的特性,这种优化最大限度地减少了 G 中的边数,从而减少了重放客户端必须强制执行的等待次数。
3.2 实施细节
现在让我们提供更多的实现细节,主要关注我们在 Oracle Database Replay 第二版中必须进行的修改,以使其支持基于冲突依赖的同步方案。下面,我们分别研究每一步的执行。
捕获:在捕获期间,Oracle Database Replay 存储一致重放工作负载所需的一些元数据,例如 SQL 文本、绑定值、计时信息和系统更改编号 (SCN)。(SCN 是一个顺序计数器,精确识别 ORACLE 数据库中的某个时刻。SCN 通过提交进行推进) 最重要的是,在新版本中,它还存储调用访问的对象的标识符以及相应的访问类型(读或写)。额外的元数据使我们的算法能够根据一致性规则(第 2.2 节)决定两个调用是否冲突。请注意,我们已经使用 DBMS 内核中的回调实现了工作负载记录;因此,所有必需的元数据都很容易获得。
出于性能原因,Oracle Database Replay 在打开游标调用期间,每个游标仅存储我们上面描述的附加元数据一次。为了避免不必要的冗余,它不会在每次游标执行时一次又一次地显式存储它。相反,在这种情况下,它只存储光标编号,这足以在后续步骤中需要时检索相关信息。
最后,请注意,工具存储的上述对象标识符始终引用基表,即使与相应游标关联的 SQL 文本引用复杂视图也是如此。此属性保证 Oracle Database Replay 不会丢失任何依赖项。
预处理:在预处理期间,Oracle 数据库重放会生成许多线程,每个线程都会解析许多捕获文件,收集捕获期间存储的信息,并使用重放步骤所需的元数据填充适当的结构和内部表。在新版本中,它还填充了一个附加表:
DEPENDENCIES(file_id, call_ctr, object id, RW, scn, pc_scn)
该表为调用访问的每个对象存储一行。该信息对于识别同步期间的冲突是必要的。
- 列 file_id 保存存储给定调用的捕获文件的标识符
- call_ctr 是一个计数器,用于标识捕获文件中给定调用的序列号
- 对象 id 保存给定调用访问的对象的标识符
- RW 存储相应的访问类型
- scn 保存给定调用执行开始时数据库的 SCN
- pc_scn 保存 post-commit SCN,即给定调用提交其更改后生成的新 SCN。如果给定的调用是非提交的,则 pc_scn 就等于 scn
Oracle Database Replay 使用 DEPENDENCIES 中的原始数据来构建我们在上一小节中讨论的依赖图 G。为此,我们在 PL/SQL 中实现了算法 BuildDependencyGraph(第 3.1 节)。在描述算法概要的伪代码中,我们使用了时间的抽象概念来对调用进行排序并确定优先级。
我们的目的是使伪代码尽可能通用。但在我们的特定实现中,我们使用call_ctr 作为捕获文件中调用排序的时间度量。此外,我们使用 scn 和 pc_scn 来对不同捕获文件之间的调用进行排序。由于 SCN 是一个顺序计数器,用于标识 ORACLE 数据库中的某个时刻,因此它非常适合确定优先级。
总之,我们的 PL/SQL 实现通过从 DEPENDENCIES 中选择适当的行来执行对存储在捕获文件(BuildDependencyGraph,第 3-4 行)中的调用的扫描。它根据对象 id 和 RW 列中的相应值测试两个调用是否发生冲突(第 13 行)。每当它发现两个调用之间发生冲突时(第 15-18 行),它就会在另一个表 DEP_GRAPH(file_id, call_ctr, dep_file_id, dep_call_ctr) 中插入一个新行。DEP_GRAPH 实现了 G;其中的一行表示两个调用之间的依赖关系。该对 (file_id, call_ctr ) 唯一标识第一个调用,该调用存储在捕获文件中带有 id file_id 的位置 call_ctr 中。同样,pair对 (dep_file_id, dep_call_ctr) 唯一标识第二个。
重放:在重放期间,数据库服务器可以访问表 DEP_GRAPH。因此,它知道需要强制执行哪些依赖项。因此,它会阻止需要等待其他调用的调用,直到后者被执行。
我们实现不同同步方案的经验,一种基于提交,一种基于冲突依赖,验证了我们的期望,即实现前者需要更少的工作。对于该方案,在服务器中维护一个中央 SCN 时钟,存储重放期间已执行的调用中最大的 SCN,足以有效地跟踪所有依赖关系,而无需具体化 G。SCN-clock与模拟时钟类似,它是由特定事件提前的。在重放的情况下,这些事件是提交操作。因此,在基于提交依赖的方案中,服务器通过简单地阻止所有记录的SCN大于时钟当前值的新调用来强制一致性,直到其他一些调用将时钟推进到它们的SCN,或大于该值。有关更多详细信息,请参阅其他地方[9]。权衡是显而易见的:我们选择为 Oracle Database Replay 第一个版本实现更严格但更简单的方案,并在第二个版本中实现高级方案。
4 实验评价
在第 2 节中,我们研究了一致同步方案的范围,并认为基于冲突依赖性强制排序的方案是最细粒度的方案;因此,期望最大限度地提高并发水平和相关的重放性能。我们在 Oracle 11g 第 2 版(Oracle 11g Release 2)中实现了这个新方案。为了验证我们的论点,我们通过实验将其与现有文献 [9] 中提出的唯一对应方案(即基于 提交依赖性commit dependency 强制排序的方案)进行了比较。回想一下,这个方案是在 Oracle 11g 中引入的。在本节中,我们将介绍实验评估的结果。
请注意,我们已将基于总排序或对象依赖性的评估方案排除在外。原因是这些方案的实际意义较小。正如我们在第 2.3.1 节中已经提到的,前一种类型的方案不允许实际的并发性,并且仅出于说明目的而提出。同样,正如我们在第 2.3.3 节中所解释的,后一种类型的方案在只读调用之间创建依赖关系。需要此属性来避免获取读取锁的 DBMS 中出现死锁。对死锁的解释超出了本文的范围。
硬件:我们在两台运行 Linux 2.6.9 的机器上运行了我们的实验。机器 A 具有 4 GB 物理内存和 2 个 3 GHz Intel Xeon CPU,每个 CPU 具有 6 MB 缓存大小。机器B更强大:它拥有 32 GB 物理内存和 8 个 2.53 GHz Intel Xeon CPU,每个 CPU 具有 8 MB 缓存大小。
工作负载场景:我们尝试了不同的工作负载和各种捕获/重放场景。所有结果都是一致的。下面,我们描述最具代表性的内容。由于篇幅限制,我们省略了其余部分。
更详细地,我们展示了与三个不同基准测试生成的工作负载相关的结果:TPC-C [4]、Swingbench [11] 和真实应用程序 (RA),我们将在下面解释其特征:
- TPC-C 是数据库文献中广泛引用的基准。它描绘了一家批发供应商,拥有多个地理分布的销售区和相关仓库。它以仓库数量作为输入参数。在我们的实验中,我们将其设置为10,这是一个常用的值。
- Swingbench 是一个旨在对数据库服务器进行压力测试的基准测试。它模拟来自同时下订单的客户的工作负载。我们已将 Swingbench 配置为生成 100 个并发会话。
- 最后,RA 是一个基准,它使用我们正在合作的真实公司的应用程序生成的工作负载。该公司的代理商使用该应用程序根据考虑客户历史和个人资料的公式对不同服务进行报价。在我们的实验中,我们使用了来自上述应用程序的 100 个并发会话。
请注意,在为上述所有基准测试的输入参数选择值时,我们的主要目标是在机器 A 上创建相当大但仍可管理的负载(在捕获期间 CPU 平均繁忙 97%)。
我们可以将我们使用的基准测试生成的工作负载分为两个不同的类别。RA 的工作负载以读取为主,因为只有 3.3% 的调用是提交调用。TPC-C 和 Swingbench 的工作负载以提交为主,因为它们包含的提交调用百分比分别达到 62% 和 36%。在 TPC-C 的情况下,提交调用的百分比如此之高,因为大多数更新调用都使用自动提交。
我们在此处介绍的实验中使用的主要场景如下:我们首先捕获了上述三种工作负载的 32 分钟不同组合,同时它们在机器 A 上运行的数据库服务器上执行。然后, 我们在机器 B 上运行的数据库服务器上重放了捕获的工作负载。我们的场景模拟了非常常见的现实情况。应用程序正在中等规模的生产系统(如机器 A)上运行,数据库管理员计划将其部署在功能更强大的机器(如机器 B)上。在实施升级之前,管理员使用数据库重放来估计与升级相关的预期性能增益。
此外,我们使用了三种不同的重放模式:相同、快速和最快。我们用一个例子来解释它们的含义。想象一下两个连续的调用 a 和 b 存储在同一个捕获文件中,这样 a→b。让 ta 和 tb 分别表示捕获期间执行 a 和 b 的时间。此外,令 t’a 为重放期间执行 a 的时间,da 为其执行的持续时间。然后,对于每种模式,b成为重放期间执行候选的时间t’b由以下公式给出:
Same mode: t′b = t′a + max(tb − ta, da)fast mode: t′b = t′a + max((tb − ta)/2, da)fastest mode: t′b = t′a + da.
- 第一个公式意味着在相同模式下重放会尝试在重放期间重现捕获期间观察到的相同调用速率
- 同样,在快速模式下重放会尝试使该速率加倍
- 最后,在最快模式下重放尝试以可能的最大速率一个接一个地重放所有调用,即在连续调用之间不留任何间隙
请注意,在前面的描述中,我们已经强调了每种不同的模式都试图达到给定的速率。在实践中实现它取决于调用执行的持续时间以及由所采用的同步方案强制执行的任何额外等待。
结果分析:首先,我们提出了一组关于 读取 主导的工作负载(由 RA 生成的工作负载)的实验。我们使用两种不同的同步方案在三种不同的模式下重放捕获的工作负载。请注意,这两种方案是一致的;因此,根据设计,它们可以重现捕获的工作负载,而不会出现任何数据或结果差异。
由于这两种模式产生相同的结果,因此我们通过关注性能指标来比较它们:图5显示了每次重放的运行时间,图6显示了相应的吞吐量(即每秒的平均事务数),图7显示了提交调用在获得提交日志文件上的锁之前必须等待的总时间。
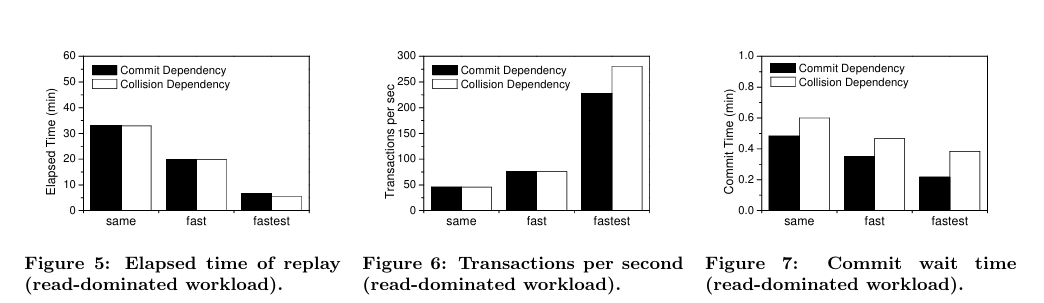
所有图形均包含三组,每组两列。每组对应一种重放模式:左侧为相同模式,中间为快速模式,右侧为最快模式。一对列对应于每种模式:黑色列代表基于提交依赖的同步方案,而白色列代表基于冲突依赖的同步方案。
从这些图表得出的主要结论是,两种方案都能为读取主导的工作负载生成高质量的重放。回想一下,机器 A 上的原始捕获持续时间为 32 分钟。图 5 表明,两种方案都能够在相同模式下理想地同步重放,因为它们实现了与捕获期间相同的调用速率,并且也使重放在 32 分钟后完成。在其他两种模式下,他们设法通过减少调用之间的时间来加快重放速度,更好地利用机器 B 的额外计算能力。因此,所用时间会减少(图 5),吞吐量会增加(图 6)。在相同和快速模式下,两种方案表现得同样好,但在最快模式下,我们的新方案(基于碰撞依赖的方案)比现有方案性能提高了近 23%。这个结果表明,即使提交的数量是相对较小的特定工作负载,collision-based同步仍然可以获得一些好处,因为它执行更少的等待和管理增加并发的水平,推动负载机器B高水平(平均CPU使用率达到47%,而同样数量的计划根据提交的依赖是40%),揭示管理员升级机器的真正潜力。
至于提交等待时间(图 7),它们相当低,因为提交数量很少,并且提交日志文件上没有太多争用。基于提交依赖的方案的等待时间更短,因为它以序列化的方式发出所有提交调用。请注意,在这种情况下,提交的发出是串行的,但完成不是串行的;因此,仍然存在一些争论,尽管规模较小。快速和最快模式下的等待时间会减少,因为两种方案都在这些模式上强制执行更短的等待时间(回想一下为不同模式计算 t′b 的公式)。
为了更好地揭示我们新方案的潜力,我们进一步尝试了以 提交 为主导的工作负载。为此,我们将之前的工作负载与 TPC-C 和 Swingbench 生成的工作负载混合在一起。由此产生的工作量会更重并且以提交为主。图 8、图 9 和图 10 分别显示了以提交为主的工作负载的不同重放的运行时间、吞吐量和提交等待时间。
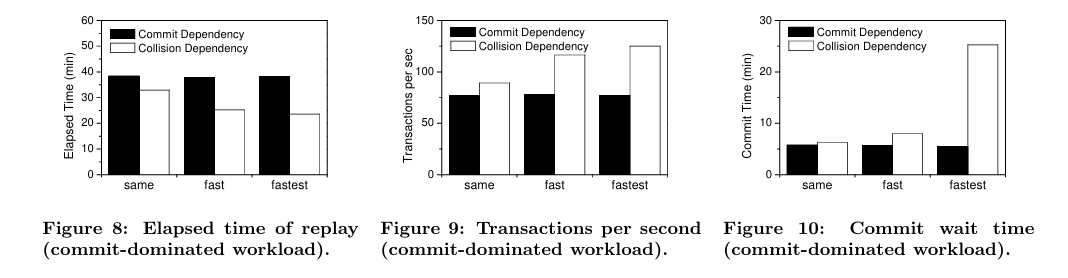
我们首先要指出的是,基于提交依赖的方案无法有效地驱动以提交为主导的工作负载的重放。请注意,每个图中所有黑柱的高度大致相同,这表明即使在相同的模式下,相应的方案也已经饱和。尽管单个请求从机器 B 的增强能力中获得了一些好处,但通过平均保留资源的时间较短,该方案无法提高并发级别以减少工作负载的运行时间。请注意,在图 8 中,基于提交依赖关系的方案的运行时间在所有模式下约为 38 分钟。这个时间甚至比捕获时间(32 分钟)还要长。
我们的新方案不会遇到同样的问题。它能够在相同模式下在大约 32 分钟内重放工作负载,并成功在快速和最快模式下进一步加速工作负载,提高并发水平并将吞吐量增加 40%(图 9)。通过这样做,它生成更快、质量更好的重放,因为它将机器B驱动到更高的负载水平(平均CPU使用率达到45%,而基于提交依赖的方案的相同数字为35%),从而向管理员揭示了升级的真正潜力,而不仅仅是总体资源消耗的改进。关于提交等待时间(图 10),我们可以观察到,在这一系列实验中,与图 7 中的相应时间相比,它有所增加。
这是因为以提交为主的工作负载包含更多提交调用,因此会在提交日志文件上产生更多争用。对于基于冲突依赖性的方案,等待时间显着增加,尤其是在最快模式下。这表明它同时发出许多提交调用,这些调用是与冲突无关的。根据设计,基于提交依赖的方案无法做到这一点。请注意,随着队列中保留的提交调用数量的增加,提交等待时间会迅速增加。这解释了图 10 中最快模式下白色柱的显着高度。
总体而言,我们的结果验证了在重放以读取为主的工作负载时,新方案的表现与现有方案相同或略好。此外,在重放依赖于提交的工作负载时,它的性能远远优于现有的。由于粒度更细,它可以产生更好质量的重放,在相同模式下更好地再现测试机器上的工作负载,并在快速和最快模式下进一步加速。因此,它导致更具代表性和更可靠的测试,这一特性使其成为一致方案范围内的首选方案。
5. 相关工作
DBMS 中的并发控制和冲突可串行性的相关理论是与我们的工作相关的相当古老且经过充分研究的问题 [6,13,17]。该领域的算法使用了事务之间类似的依赖关系概念和类似的理论结构,例如冲突依赖图。尽管存在上述相似之处,但这两个问题有根本的不同。主要区别在于并发控制机制确保数据库完整性,而重放同步方案则保证重放一致性。总之,并发控制机制的任务是生成一个合法的调度来执行由竞争资源的事务组成的工作负载。如果调度保证数据库状态的完整性(例如,通过强制可串行化),那么它就是合法的。另一方面,重放同步机制不关注完整性,因此它们遵循不同的约束。他们不必生成任何合法的计划,而是必须生成与捕获期间在生产系统中实际执行的特定计划等效的计划。
另一个重要的区别是,并发控制机制是动态工作的,因为它们事先不知道整个工作负载,而重放同步方案可以以离线方式发现所有依赖关系,因为它们可以提前访问整个工作负载。因此,如果在他们维护的依赖图中检测到循环,前者可能必须回溯;对于后者来说,这种情况是不可能发生的。上述差异证明了工作负载重放需要不同同步方案的合理性。研究此类方案以及将已知理论应用于我们的新问题一直是本文的主要目的。
过去已经研究过记录和重放真实数据库工作负载,并且一些商业工具已经提供了此处描述的一些功能。其中,与我们的工作更接近的工具是Oracle Database Replay的第一个版本[9]。它在 Oracle 11g 中的实现使用一致的重放同步方案,该方案根据提交依赖性对调用进行排序。正如本文所示,该方案的限制比必要的多,留下了很大的改进空间。在本文中,我们的目标是首次研究所有一致重放同步方案的属性和权衡,形式化其特征,发现新方案,并提名最佳方案,我们已在 Oracle 11g 第 2 版中实现了这些方案。
同一类别的其他工具,包括 Quest Benchmark Factory for Databases [1] 和 Microsoft SQL Server Profiler [3],依赖 SQL 跟踪来记录数据库工作负载。这些方法的问题在于,SQL 跟踪在数据库服务器上增加了相当大的开销,并且不包含实现一致同步方案所需的事务信息。因此,他们的技术不适用于我们的问题。
iReplay 是用于数据库 QA、回归测试、性能测试等的下一代负载生成和分析工具。iReplay 被设计为真正的数据库重放,允许组织捕获其生产 SQL 工作负载的真实图像,然后重新创建该工作负载及其所有本机复杂性,以便在测试环境中进行分析。这种方法有效地消除了生产流量和模拟测试条件之间的差距,使组织能够更可靠地预测关键信息系统变化的影响,同时降低相关风险。
此外,还有另一个工具系列,包括 iReplay [2],它在网络级别实现捕获和重放。在捕获过程中,他们使用嗅探来记录进入 DBMS 的流量。在重放期间,它们会再现相同的流量。此类工具的一个显着缺点是它们是在 DBMS 之外构建的;因此,它们只能依赖在其入口点观察到的计时信息。换句话说,他们只知道请求何时到达 DBMS,但无法访问有关该请求实际执行时间、它表现出的依赖关系、分配给它的 SCN 或它访问的对象的信息。因此,在重放期间,他们无法应用我们在本文中讨论的频谱的任何同步方案。他们能做的最好的事情就是按照与捕获期间相同的顺序发出相同的调用。显然,这样的解决方案并不能保证在 DBMS 中执行期间保留相同的顺序。因此,这些工具不能保证重放一致性,而这一直是我们的主要关注点,并且它们不属于本文的讨论范围。
最后,其他几种算法会生成用于测试目的的合成数据或工作负载 [7,8,12,15,16]。不过,他们都没有研究同步重放生成的工作负载的问题,而这是我们的主要关注点。此外,我们的方法适用于在真实系统上捕获的工作负载。预计真实工作负载比合成工作负载更能代表数据库测试。
6. 结论
在本文中,我们首次对实际工作负载重放的一致同步方案进行了广泛的研究。我们定义了它们的类别,确定了它们覆盖的范围,并研究了该范围内各个点的属性和权衡。此外,我们表明,虽然在许多实际应用中足够,但迄今为止提出的唯一一致的重放同步方案[9]是粗粒度的,并且比必要的限制更多,强制独立调用之间的依赖关系。
为了克服这个缺点,我们确定了使用更细粒度的规则进行重放同步的理想方案。此外,我们描述了新方案的有效实施,并从理论上和实验上表明,对于主要的工作负载类别,它比现有方案产生更好的质量重放。
7. 引用
[1] Benchmark Factory for Databases. http://www.quest.com.
[2] iReplay: Database Workload Capture and Replay. http://www.exact-solutions.com/products/ireplay.
[3] SQL Server Profiler. http://msdn.microsoft.com.
[4] Transaction Processing Performance Council. TPC-C benchmark. http://www.tpc.org/tpcc/.
[5] A. V. Aho, M. R. Garey, and J. D. Ullman. The transitive reduction of a directed graph. SIAM J.Comput., 1(2):131–137, 1972.
[6] P. A. Bernstein, V. Hadzilacos, and N. Goodman. Concurrency Control and Recovery in Database Systems. Addison-Wesley, 1987.
[7] C. Binnig, D. Kossmann, E. Lo, and M. T. ¨ Ozsu. QAGen: generating query-aware test databases. In SIGMOD Conference, pages 341–352, 2007.
[8] M. Emmi, R. Majumdar, and K. Sen. Dynamic test input generation for database applications. In ISSTA, pages 151–162, 2007.
[9] L. Galanis, S. Buranawatanachoke, R. Colle, B. Dageville, K. Dias, J. Klein, S. Papadomanolakis, L. L. Tan, V. Venkataramani, Y. Wang, and G. Wood. Oracle database replay. In SIGMOD Conference, pages 1159–1170, 2008.
[10] G. R. Ganger. Generating representative synthetic workloads: An unsolved problem. In Int. CMG Conference, pages 1263–1269, 1995.
[11] D. Giles. Swingbench benchmark. http://www.dominicgiles.com/swingbench.html.
[12] J. Gray, P. Sundaresan, S. Englert, K. Baclawski, and P. J. Weinberger. Quickly generating billion-record synthetic databases. In SIGMOD Conference, pages 243–252, 1994.
[13] H. T. Kung and J. T. Robinson. On optimistic methods for concurrency control. ACM Trans. Database Syst., 6(2):213–226, 1981.
[14] T.-H. Ma and J. Spinrad. Cycle-free partial orders and chordal comparability graphs. Order, 8(1):49–61, 1991.
[15] M. Poess and J. M. Stephens. Generating thousand benchmark queries in seconds. In VLDB, pages 1045–1053, 2004.
[16] D. R. Slutz. Massive stochastic testing of SQL. In VLDB, pages 618–622, 1998.
[17] R. E. Stearns, P. M. L. II, and D. J. Rosenkrantz. Concurrency control for database systems. In FOCS, pages 19–32, 1976.








》】实验7-1-6 求一批整数中出现最多的个位数字(附测试点))
02)

之四十九:cairo编译(Windows、Linux、MacOS环境下编译))






牛客10-字符个数统计)
