文章目录
- 一、496、下一个更大元素 I
- 二、503、下一个更大元素II
- 三、完整代码
所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。
一、496、下一个更大元素 I
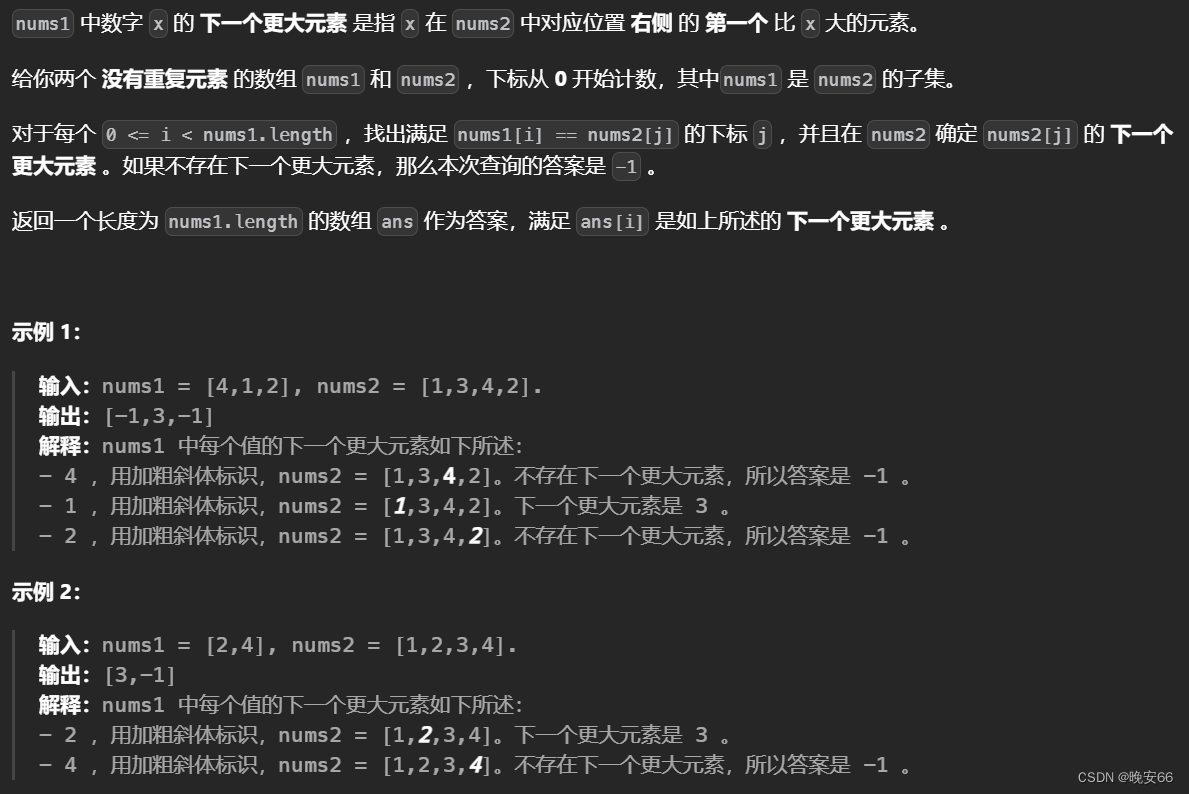
思路分析:本题思路和【算法与数据结构】739、LeetCode每日温度类似。如果用暴力破解法时间复杂度需要 O ( m ∗ n ) O(m*n) O(m∗n),其中 m m m和 n n n分别是两个数组的长度。单调栈只需要 O ( n + m ) O(n+m) O(n+m)的时间复杂度。相较于739题,本题需要找到nums1元素在nums2数组中的位置,那么我们可以利用unordered_map,查找和增删效率是最高的【算法与数据结构】算法与数据结构知识点:
unordered_map<int, int> umap; // key:下标元素,value:下标for (int i = 0; i < nums1.size(); i++) {umap[nums1[i]] = i;}
然后利用739题的单调栈思路,遍历nums2数组。每当当前遍历元素大于栈顶元素,并且nums2数组的元素在nums1中存在(umap.count(nums2[st.top()]) > 0就是统计数量,大于零说明nums2[st.top()]元素存在),我们找到栈顶元素在nums1中的下标,在结果数组中根据下标修改其值:
for (int i = 0; i < nums2.size(); i++) { while (!st.empty() && nums2[i] > nums2[st.top()]) {if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素,count函数计算数量int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标result[index] = nums2[i];}st.pop();}st.push(i); // 插入数组的下标}
程序如下:
// 496、下一个更大元素 I
class Solution {
public:vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {vector<int> result(nums1.size(), -1);stack<int> st;unordered_map<int, int> umap; // key:下标元素,value:下标for (int i = 0; i < nums1.size(); i++) {umap[nums1[i]] = i;}for (int i = 0; i < nums2.size(); i++) { while (!st.empty() && nums2[i] > nums2[st.top()]) {if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素,count函数计算数量int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标result[index] = nums2[i];}st.pop();}st.push(i); // 插入数组的下标}return result;}
};
复杂度分析:
- 时间复杂度: O ( n ) O(n) O(n)。
- 空间复杂度: O ( n ) O(n) O(n)。
二、503、下一个更大元素II
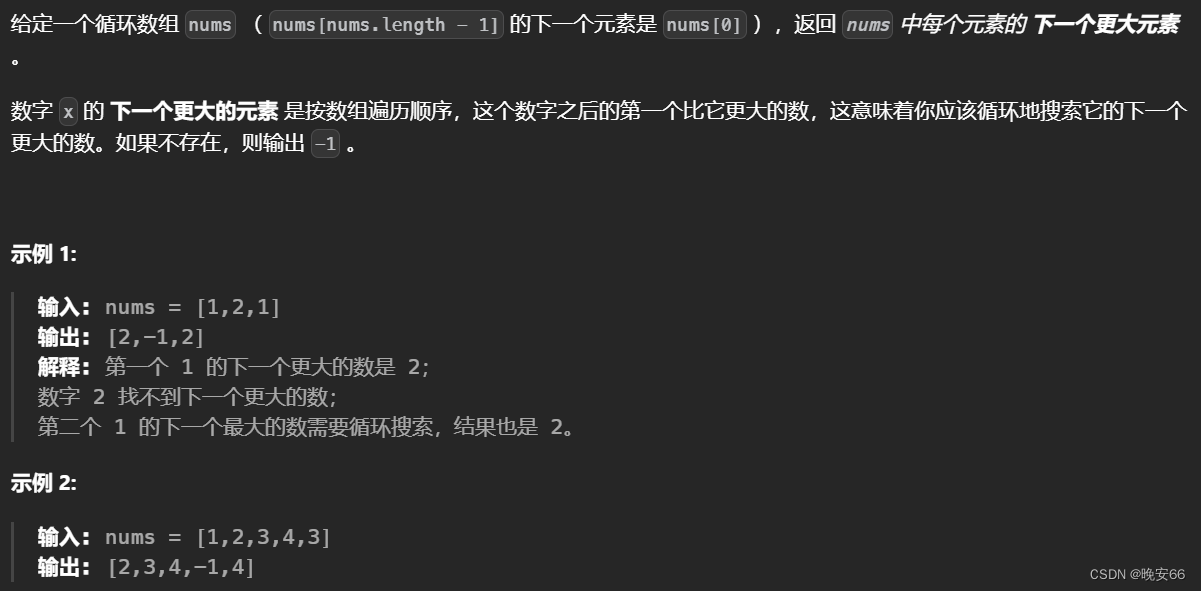
思路分析:本题和496题不同之处在于从两个数组变成一个数组,然后数组是环形数组。针对环形数组,我们要比较大小,可以将环形数组复制一份,两个相同的数组扩充成一个新数组。然后在新数组上去做单调栈的操作。
程序如下:
// 503、下一个更大元素II-版本一
class Solution2 {
public:vector<int> nextGreaterElements(vector<int>& nums) {vector<int> nums1(nums.begin(), nums.end()); // 拼接一个新的numsnums.insert(nums.end(), nums1.begin(), nums1.end()); vector<int> result(nums.size(), -1); // 用新的nums大小来初始化result// 开始单调栈stack<int> st;st.push(0);for (int i = 1; i < nums.size(); i++) {while (!st.empty() && nums[i] > nums[st.top()]) {result[st.top()] = nums[i];st.pop();}st.push(i);}result.resize(nums.size() / 2); // 最后再把结果集即result数组resize到原数组大小return result;}
};
虽然这种写法比较直观,但是做了很多无用操作。resize函数是O(1)的操作,但扩充nums数组相当于多了一个O(n)的操作。其实也可以不扩充nums,而是在遍历的过程中模拟走了两边nums。例如我们改变索引的上界,然后令其做取nums.size()模的操作。
// 503、下一个更大元素II-版本二
class Solution3 {
public:vector<int> nextGreaterElements(vector<int>& nums) {vector<int> result(nums.size(), -1);stack<int> st;for (int i = 0; i < nums.size() * 2; i++) {// 模拟遍历两边nums,注意一下都是用i % nums.size()来操作while (!st.empty() && nums[i % nums.size()] > nums[st.top()]) {result[st.top()] = nums[i % nums.size()];st.pop();}st.push(i % nums.size());}return result;}
};
复杂度分析:
- 时间复杂度: O ( n ) O(n) O(n)。
- 空间复杂度: O ( n ) O(n) O(n)。
三、完整代码
# include <iostream>
# include <vector>
# include <unordered_map>.
# include <stack>
using namespace std;// 496、下一个更大元素 I
class Solution {
public:vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {vector<int> result(nums1.size(), -1);stack<int> st;unordered_map<int, int> umap; // key:下标元素,value:下标for (int i = 0; i < nums1.size(); i++) {umap[nums1[i]] = i;}for (int i = 0; i < nums2.size(); i++) { while (!st.empty() && nums2[i] > nums2[st.top()]) {if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素,count函数计算数量int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标result[index] = nums2[i];}st.pop();}st.push(i); // 插入数组的下标}return result;}
};// 503、下一个更大元素II-版本一
class Solution2 {
public:vector<int> nextGreaterElements(vector<int>& nums) {vector<int> nums1(nums.begin(), nums.end()); // 拼接一个新的numsnums.insert(nums.end(), nums1.begin(), nums1.end()); vector<int> result(nums.size(), -1); // 用新的nums大小来初始化result// 开始单调栈stack<int> st;st.push(0);for (int i = 1; i < nums.size(); i++) {while (!st.empty() && nums[i] > nums[st.top()]) {result[st.top()] = nums[i];st.pop();}st.push(i);}result.resize(nums.size() / 2); // 最后再把结果集即result数组resize到原数组大小return result;}
};// 503、下一个更大元素II-版本二
class Solution3 {
public:vector<int> nextGreaterElements(vector<int>& nums) {vector<int> result(nums.size(), -1);if (nums.size() == 0) return result;stack<int> st;for (int i = 0; i < nums.size() * 2; i++) {// 模拟遍历两边nums,注意一下都是用i % nums.size()来操作while (!st.empty() && nums[i % nums.size()] > nums[st.top()]) {result[st.top()] = nums[i % nums.size()];st.pop();}st.push(i % nums.size());}return result;}
};int main() {//vector<int> nums1 = { 4,1,2 };//vector<int> nums2 = { 1,3,4,2 };//Solution s1;//vector<int> result = s1.nextGreaterElement(nums1, nums2);vector<int> nums = { 1,2,3,4,3 };Solution2 s1;vector<int> result = s1.nextGreaterElements(nums);for (vector<int>::iterator i = result.begin(); i != result.end(); i++) {cout << *i << " ";}cout << endl;system("pause");return 0;
}
end