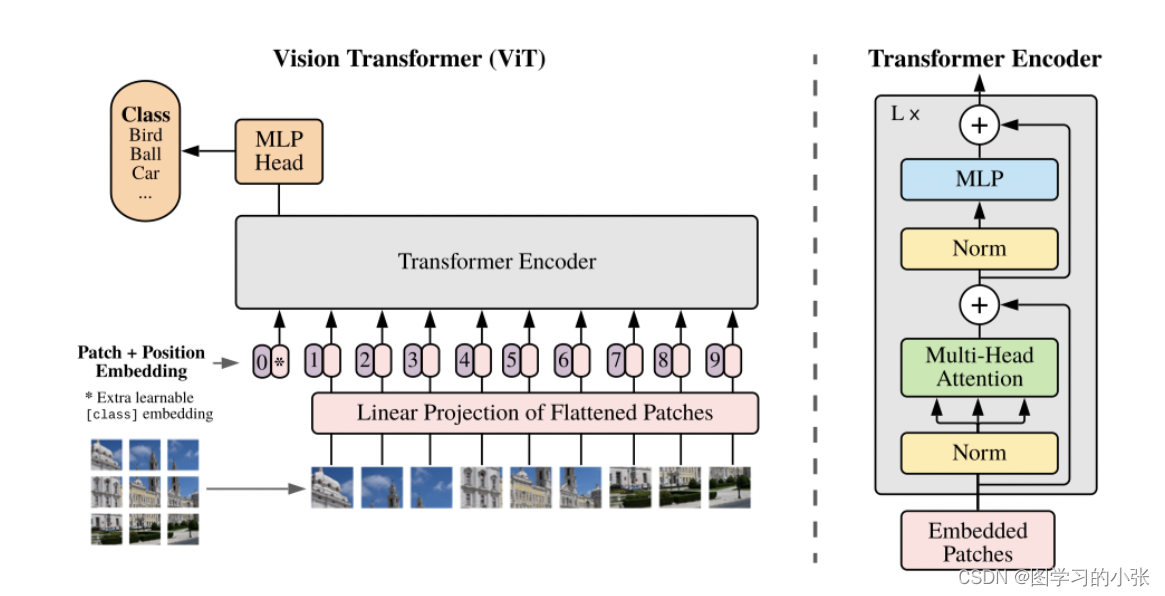
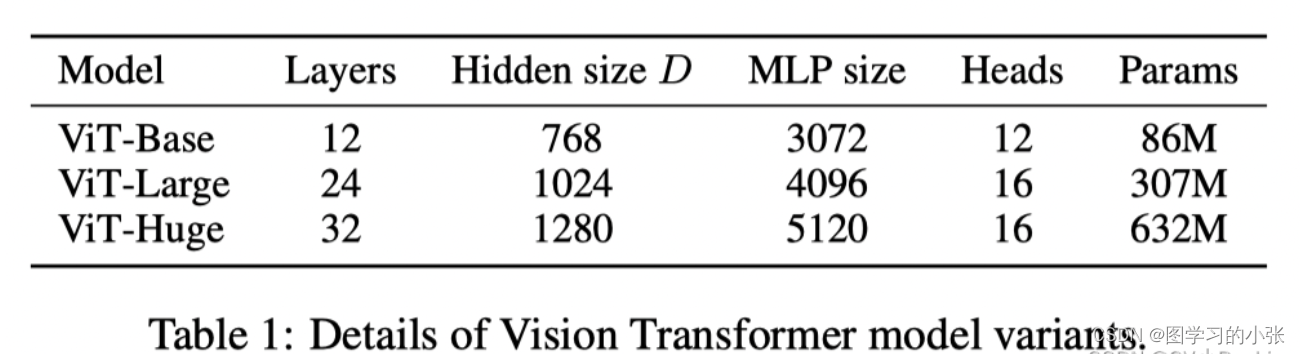
虽然 Transformer 架构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。我们表明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯变换器可以在图像分类任务上表现得非常好。当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,与最先进的卷积神经网络相比,Vision Transformer (ViT) 取得了出色的结果,同时需要更少的计算资源来训练。
visiontransformerVIT
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/674873.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

软件应用实例分享,电玩计时计费怎么算,佳易王PS5游戏计时器系统程序教程
软件应用实例分享,电玩计时计费怎么算,佳易王PS5游戏计时器系统程序教程
一、前言
以下软件教程以 佳易王电玩计时计费管理系统软件V17.9为例说明
软件文件下载可以点击最下方官网卡片——软件下载——试用版软件下载 点击开始计时后,图片…

python使用正则匹配判断字符串中含有某些特定子串及正则表达式详解
目录 一、判断字符串中是否含有字串
二、正则表达式
(一)基本内容
1.正则表达式修饰符——可选标志
2.正则表达式模式
(二)常见表达式函数 一、判断字符串中是否含有字串 in,not in
判断字符串中是否含有某些关…

hashmap的get原理
HashMap的 get() 方法用于根据给定的键获取对应的值。下面是HashMap的get()方法的大致原理: 首先,get() 方法会计算传入键的哈希码(hash code)。通过调用键对象的 hashCode() 方法来获取键的哈希码。 接下来,get() 方…

使用easyExcel 定义表头 字体 格式 颜色等,定义表内容,合计
HeadStyle 表头样式注解
HeadFontStyle 表头字体样式 HeadStyle(fillPatternType FillPatternTypeEnum.SOLID_FOREGROUND, fillForegroundColor 22)
HeadFontStyle(fontHeightInPoints 12)
以下为实现效果

python实现rdbms和neo4j的转换
python&neo4j 一、连接neo4j二、rdbms转换到neo4j三、常见报错<一>、ValueError: The following settings are not supported 一、连接neo4j
下载依赖库
pip install py2neo连接neo4j
from py2neo import Graph
graph Graph("bolt://localhost:7687", …

Unity BuffSystem buff系统
Unity BuffSystem buff系统 一、介绍二、buff系统架构三、架构讲解四、框架使用buff数据Json数据以及工具ShowTypeBuffTypeMountTypeBuffOverlapBuffShutDownTypeBuffCalculateType时间和层数这里也不过多说明了如何给生物添加buff 五、总结 一、介绍
现在基本做游戏都会需要些…

leetcode-3的幂
326. 3 的幂
题解:
要判断一个整数是否是3的幂次方,我们可以使用循环或递归的方法。首先,我们需要处理一些特殊情况,例如当n为0时,返回false;当n为1时,返回true。然后,我们可以通过…

【Nicn的刷题日常】之有序序列合并
1.题目描述 描述 输入两个升序排列的序列,将两个序列合并为一个有序序列并输出。 数据范围: 1≤�,�≤1000 1≤n,m≤1000 , 序列中的值满足 0≤���≤30000 0≤val≤30000 输入描述…


C++基础知识点预览
一.绪论: 1.1 C简史: 与C的关系: 被设计为C语言的继任者,C语言是一种过程型语言,程序员使用它定义执行特定操作的函数,而C是一种面向对象的语言,实现了继承、抽象、多态和封装等概念。C支持类&…

【RPA】智能自动化的未来:AI + RPA
伴随着人工智能(AI)技术的迅猛进步,机器人流程自动化(RPA)正在经历一场翻天覆地的变革。AI为RPA注入了新的活力,尤其在处理复杂任务和制定决策方面。通过融合自然语言处理(NLP)、机器…

从0开始学Docker ---Docker安装教程
Docker安装教程
本安装教程参考Docker官方文档,地址如下: https://docs.docker.com/engine/install/centos/
1.卸载旧版 首先如果系统中已经存在旧的Docker,则先卸载:
yum remove docker \docker-client \docker-client-latest…
【上】)
《学成在线》微服务实战项目实操笔记系列(P1~P83)【上】
史上最详细《学成在线》项目实操笔记系列【上】,跟视频的每一P对应,全系列12万字,涵盖详细步骤与问题的解决方案。如果你操作到某一步卡壳,参考这篇,相信会带给你极大启发。
一、前期准备
1.1 项目介绍 P2
To C面向…

C语言-----自定义类型-----结构体
结构体和数组一样,都是一群数据的集合,不同的是数组当中的数据是相同的类型,但是结构体中的数据类型可以不相同,结构体里的成员叫做成员变量
结构体类型是C语言里面的一种自定义类型,我们前面已经了解到过int,char,fl…

jvm垃圾收集器之七种武器
目录 1.回收算法
1.1 标记-清除算法(Mark-Sweep)
1.2 复制算法(Copying)
1.3 标记-整理算法(Mark-Compact)
2.HotSpot虚拟机的垃圾收集器
2.1 新生代的收集器
Serial 收集器(复制算法)
ParNew 收集器 (复制算法)
Parallel Scavenge 收集器 (复制…

熔断机制解析:如何用Hystrix保障微服务的稳定性
微服务与系统的弹性设计
大家好,我是小黑,在讲Hystrix之前,咱们得先聊聊微服务架构。想象一下,你把一个大型应用拆成一堆小应用,每个都负责一部分功能,这就是微服务。这样做的好处是显而易见的,更新快,容错性强,每个服务可以独立部署,挺美的对吧?但是,问题也随之而…

Win10系统备份的几种方案,以后不重装系统,备份系统恢复Backup,系统映像备份
Win10系统备份的几种方案
其实都不想重装系统,每次都不愿意去安装各种软件,麻烦,其实win10有几种备份的方案,可以参考一下。 如果下次出问题,我就将系统恢复到这个状态即可,真的不想重装系统,还…
)
Stable Diffusion 模型下载:Schematics(原理图)
文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十下载地址模型介绍
“Schematics”是一个非常个性化的LORA,我的目标是创建一个整体风格,但主要面向某些风格美学,因此它可以用于人物、物体、风景等。这次你会得到“连线”和“方案”…
|Chapter02:C#基础)
Unity学习笔记(零基础到就业)|Chapter02:C#基础
Unity学习笔记(零基础到就业)|Chapter02:C#基础 前言一、复杂数据(变量)类型part01:枚举数组1.特点2.枚举(1)基本概念(2)申明枚举变量(3ÿ…

Java毕业设计-基于ssm的仓库管理系统-第76期
获取源码资料,请移步从戎源码网:从戎源码网_专业的计算机毕业设计网站
项目介绍
基于ssm的游泳馆管理系统:前端jsp、jquery、bootstrap,后端 springmvc、spring、mybatis,集成游泳课程报名、游泳卡在线售卖、购物车、…