
什么是 QAnything?
QAnything(Question and Answer based on Anything)是一个本地知识库问答系统,旨在支持多种文件格式和数据库,允许离线安装和使用。使用QAnything,您可以简单地删除本地存储的任何格式的文件,并获得准确、快速和可靠的答案。QAnything目前支持的知识库文件格式包括:PDF(pdf) , Word(docx) , PPT(pptx) , XLS(xlsx) , Markdown(md) , Email(eml) , TXT(txt) , Image(jpg,jpeg,png) , CSV (csv)、网页链接(html)等。
主要功能
- 数据安全,支持全程不插网线安装使用。
- 跨语言QA支持,中英文QA自由切换,无论文档语言如何。
- 支持海量数据QA,两阶段检索排序,解决大规模数据检索的退化问题;数据越多,性能越好。
- 高性能生产级系统,可直接部署用于企业应用。
- 人性化,无需繁琐配置,一键安装部署,即用即用。
- 多知识库QA支持选择多个知识库进行问答
软件架构
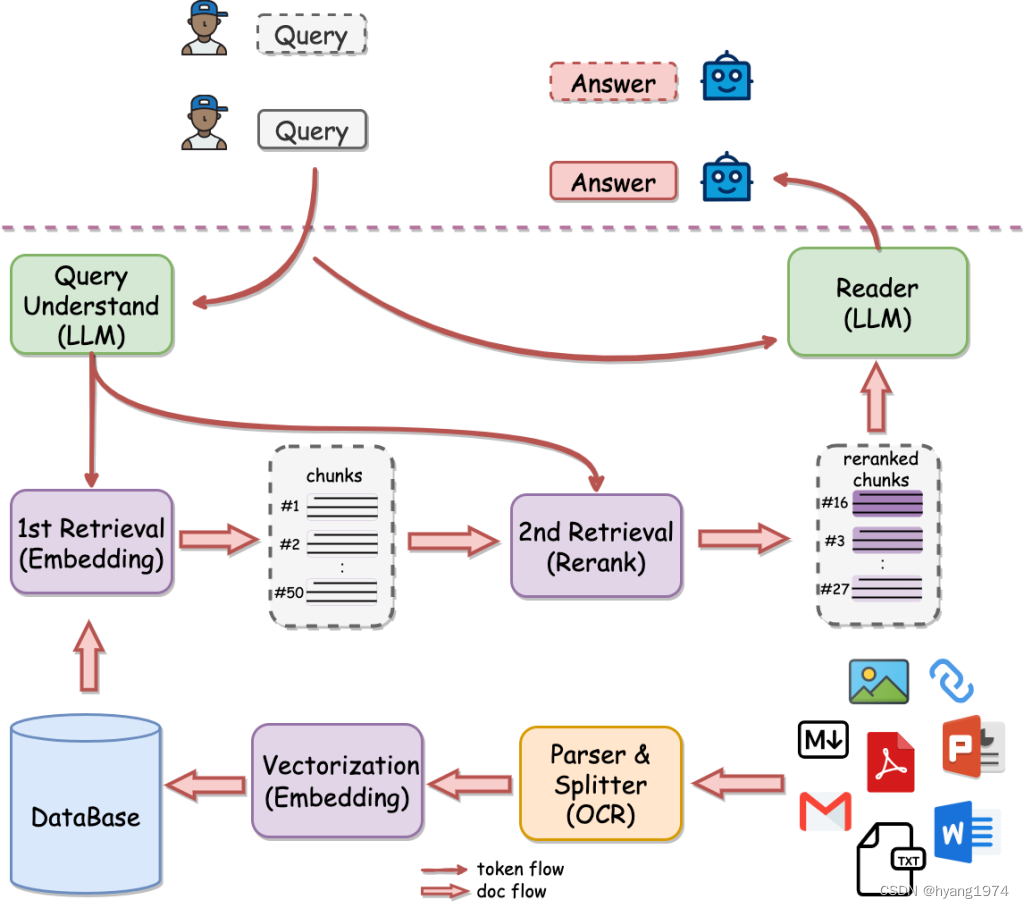
部署QAnything详细步骤
QAnything目前已经在Github开源,开源项目地址:GitHub - netease-youdao/QAnything: Question and Answer based on Anything.
安装QAnything的系统要求
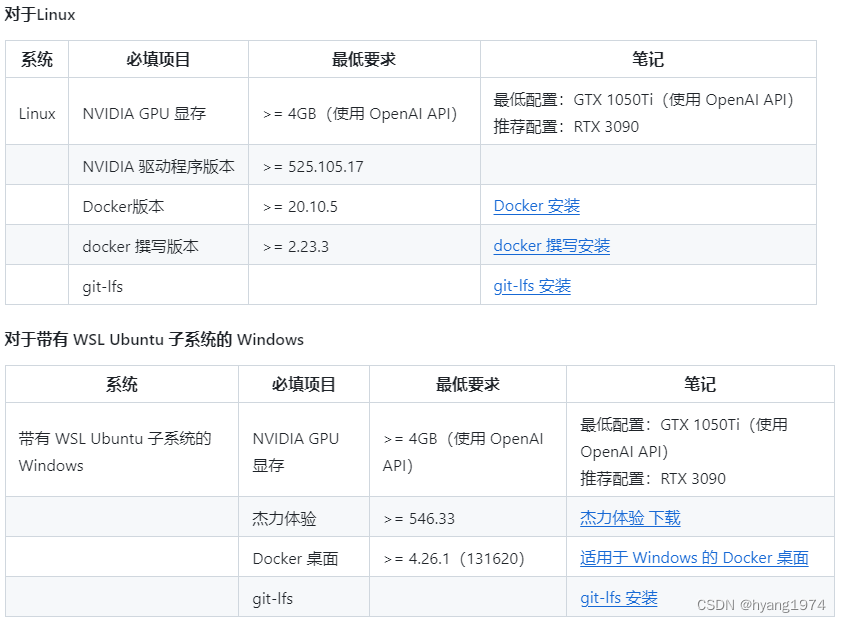
安装nVidia GPU driver
sudo apt-get update
Hit:1 http://us.archive.ubuntu.com/ubuntu jammy InRelease
Hit:2 http://packages.microsoft.com/repos/code stable InRelease
Hit:3 http://us.archive.ubuntu.com/ubuntu jammy-updates InRelease
Hit:4 http://security.ubuntu.com/ubuntu jammy-security InRelease
Hit:5 https://packages.microsoft.com/repos/vscode stable InRelease
Hit:6 http://us.archive.ubuntu.com/ubuntu jammy-backports InRelease
Reading package lists... Done我的系统用了RTX-4090,在Ubuntu 22.04上推荐使用nvidia-driver-535版本。
ubuntu-drivers devices
== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 ==
modalias : pci:v000010DEd00002684sv00001043sd000088E2bc03sc00i00
vendor : NVIDIA Corporation
driver : nvidia-driver-535-server-open - distro non-free
driver : nvidia-driver-535-open - distro non-free
driver : nvidia-driver-525 - distro non-free
driver : nvidia-driver-545 - distro non-free
driver : nvidia-driver-535 - distro non-free recommended
driver : nvidia-driver-545-open - distro non-free
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-525-open - distro non-free
driver : nvidia-driver-525-server - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtinsudo apt install nvidia-driver-535
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:dctrl-tools dkms libatomic1:i386 libbsd0:i386 libdrm-amdgpu1:i386 libdrm-intel1:i386 libdrm-nouveau2:i386libdrm-radeon1:i386 libdrm2:i386 libedit2:i386 libelf1:i386 libexpat1:i386 libffi8:i386 libgl1:i386libgl1-mesa-dri:i386 libglapi-mesa:i386 libglvnd0:i386 libglx-mesa0:i386 libglx0:i386 libicu70:i386 libllvm15:i386libmd0:i386 libnvidia-cfg1-535 libnvidia-common-535 libnvidia-compute-535 libnvidia-compute-535:i386libnvidia-decode-535 libnvidia-decode-535:i386 libnvidia-encode-535 libnvidia-encode-535:i386 libnvidia-extra-535libnvidia-fbc1-535 libnvidia-fbc1-535:i386 libnvidia-gl-535 libnvidia-gl-535:i386 libpciaccess0:i386libsensors5:i386 libstdc++6:i386 libvdpau1 libx11-6:i386 libx11-xcb1:i386 libxau6:i386 libxcb-dri2-0:i386libxcb-dri3-0:i386 libxcb-glx0:i386 libxcb-present0:i386 libxcb-randr0:i386 libxcb-shm0:i386 libxcb-sync1:i386libxcb-xfixes0:i386 libxcb1:i386 libxdmcp6:i386 libxext6:i386 libxfixes3:i386 libxml2:i386 libxnvctrl0libxshmfence1:i386 libxxf86vm1:i386 mesa-vdpau-drivers nvidia-compute-utils-535 nvidia-dkms-535nvidia-firmware-535-535.154.05 nvidia-kernel-common-535 nvidia-kernel-source-535 nvidia-prime nvidia-settingsnvidia-utils-535 pkg-config screen-resolution-extra vdpau-driver-all xserver-xorg-video-nvidia-535安装完成后重启系统,然后用命令nvidia-smi验证驱动安装成功与否。
nvidia-smi
安装docker
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc# Add the repository to Apt sources:
echo \"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get updatesudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose docker-compose-plugin为了方便docker的管理,我还另外安装portainer,可以通过web界面管理docker。
首先为Portainer创建数据保存volume:
docker volume create portainer下载并安装Portainer:
docker run -d \
-p 9000:9000 \
-p 9443:9443 \
--name portainer \
--restart=always \
-v /var/run/docker.sock:/var/run/docker.sock \
-v portainer:/data \
portainer/portainer-ce:latest安装完成后,就可以访问http://your_server_name:9000或者https://your_server_name:9443来管理docker。

安装git-fls
sudo apt-get install git-lfs部署QAnything
接下来正式开始部署QAnything。
下载QAnything
git clone https://github.com/netease-youdao/QAnything.git安装并运行QAnything
sudo bash ./run.sh -c local -i 0 -b default运行QAnything的主要脚本都在项目根目录下的run.sh文件里。该shell脚本的启动选项有如下多种方式,主要针对不同的系统配置和大语言模型。比如显卡显存较小的话,就推荐调用OpenAI API,推理在OpenAI的服务器发生。我的RTX-4090共24G现存,在这里悬着运行第二个选项,跑的是Qwen-7B-QAnything的语言模型。

第一步:检测环境
这部分的代码占了run.sh的绝大部分,主要功能是检测系统的基本配置,检测本地代码的版本,并推荐相应的网络模型和准备下载。主要脚本代码如下:
# 获取最新的远程仓库信息
git fetch origin master# 获取本地master分支的最新提交
LOCAL=$(git rev-parse master)
# 获取远程master分支的最新提交
REMOTE=$(git rev-parse origin/master)if [ $LOCAL != $REMOTE ]; then# 本地分支与远程分支不一致,需要更新print_important_notice
elseecho -e "${GREEN}当前master分支已是最新,无需更新。${NC}"
fillm_api="local"
device_id="0"
runtime_backend="default"
model_name=""
conv_template=""
tensor_parallel=1
gpu_memory_utilization=0.81# 解析命令行参数
while getopts ":c:i:b:m:t:p:r:h" opt; docase $opt inc) llm_api=$OPTARG ;;i) device_id=$OPTARG ;;b) runtime_backend=$OPTARG ;;m) model_name=$OPTARG ;;t) conv_template=$OPTARG ;;p) tensor_parallel=$OPTARG ;;r) gpu_memory_utilization=$OPTARG ;;h) usage ;;*) usage ;;esac
done# 获取大模型B数
if [ $llm_api = 'cloud' ]; thenmodel_size='0B'
elif [ $runtime_backend = 'default' ]; thenmodel_size='7B'
elseread -p "请输入您使用的大模型B数(示例:1.8B/3B/7B): " model_size# 检查是否合法,必须输入数字+B的形式,可以是小数if ! [[ $model_size =~ ^[0-9]+(\.[0-9]+)?B$ ]]; thenecho "Invalid model size. Please enter a number like '1.8B' or '3B' or '7B'."exit 1fi
fi
echo "model_size=$model_size"
model_size_num=$(echo $model_size | grep -oP '^[0-9]+(\.[0-9]+)?')gpu_id1=0
gpu_id2=0# 判断命令行参数
if [[ -n "$device_id" ]]; then# 如果传入参数,分割成两个GPU IDIFS=',' read -ra gpu_ids <<< "$device_id"gpu_id1=${gpu_ids[0]}gpu_id2=${gpu_ids[1]:-$gpu_id1} # 如果没有第二个ID,则默认使用第一个ID
fiecho "GPUID1=${gpu_id1}, GPUID2=${gpu_id2}, device_id=${device_id}"# 检查GPU ID是否合法
if ! [[ $gpu_id1 =~ ^[0-9]+$ ]] || ! [[ $gpu_id2 =~ ^[0-9]+$ ]]; thenecho "Invalid GPU IDs. Please enter IDs like '0' or '0,1'."exit 1
fiupdate_or_append_to_env "GPUID1" "$gpu_id1"
update_or_append_to_env "GPUID2" "$gpu_id2"# 获取显卡型号
gpu_model=$(nvidia-smi --query-gpu=gpu_name --format=csv,noheader,nounits -i $gpu_id1)
# nvidia RTX 30系列或40系列
gpu_series=$(echo $gpu_model | grep -oP 'RTX\s*(30|40)')
if ! command -v jq &> /dev/null; thenecho "Error: jq 命令不存在,请使用 sudo apt update && sudo apt-get install jq 安装,再重新启动。"exit 1
fi
compute_capability=$(jq -r ".[\"$gpu_model\"]" scripts/gpu_capabilities.json)
# 如果compute_capability为空,则说明显卡型号不在gpu_capabilities.json中
if [ -z "$compute_capability" ]; thenecho "您的显卡型号 $gpu_model 不在支持列表中,请联系技术支持。"exit 1
fi
echo "GPU1 Model: $gpu_model"
echo "Compute Capability: $compute_capability"if ! command -v bc &> /dev/null; thenecho "Error: bc 命令不存在,请使用 sudo apt update && sudo apt-get install bc 安装,再重新启动。"exit 1
fiif [ $(echo "$compute_capability >= 7.5" | bc) -eq 1 ]; thenOCR_USE_GPU="True"
elseOCR_USE_GPU="False"
fi
echo "OCR_USE_GPU=$OCR_USE_GPU because $compute_capability >= 7.5"
update_or_append_to_env "OCR_USE_GPU" "$OCR_USE_GPU"# 使用nvidia-smi命令获取GPU的显存大小(以MiB为单位)
GPU1_MEMORY_SIZE=$(nvidia-smi --query-gpu=memory.total --format=csv,noheader,nounits -i $gpu_id1)OFFCUT_TOKEN=0
echo "===================================================="
echo "******************** 重要提示 ********************"
echo "===================================================="
echo ""# 使用默认后端且model_size_num不为0
if [ "$runtime_backend" = "default" ] && [ "$model_size_num" -ne 0 ]; thenif [ -z "$gpu_series" ]; then # 不是Nvidia 30系列或40系列echo "您的显卡型号 $gpu_model 部署默认后端FasterTransformer需要Nvidia RTX 30系列或40系列显卡,将自动为您切换后端:"# 如果显存大于等于24GB且计算力大于等于8.6,则可以使用vllm后端if [ "$GPU1_MEMORY_SIZE" -ge 24000 ] && [ $(echo "$compute_capability >= 8.6" | bc) -eq 1 ]; thenecho "根据匹配算法,已自动为您切换为vllm后端(推荐)"runtime_backend="vllm"else# 自动切换huggingface后端echo "根据匹配算法,已自动为您切换为huggingface后端"runtime_backend="hf"fifi
fiif [ "$GPU1_MEMORY_SIZE" -lt 4000 ]; then # 显存小于4GBecho "您当前的显存为 $GPU1_MEMORY_SIZE MiB 不足以部署本项目,建议升级到GTX 1050Ti或以上级别的显卡"exit 1
elif [ "$model_size_num" -eq 0 ]; then # 模型大小为0B, 表示使用openai api,4G显存就够了echo "您当前的显存为 $GPU1_MEMORY_SIZE MiB 可以使用在线的OpenAI API"
elif [ "$GPU1_MEMORY_SIZE" -lt 8000 ]; then # 显存小于8GB# 显存小于8GB,仅推荐使用在线的OpenAI APIecho "您当前的显存为 $GPU1_MEMORY_SIZE MiB 仅推荐使用在线的OpenAI API"if [ "$model_size_num" -gt 0 ]; then # 模型大小大于0Becho "您的显存不足以部署 $model_size 模型,请重新选择模型大小"exit 1fi
elif [ "$GPU1_MEMORY_SIZE" -ge 8000 ] && [ "$GPU1_MEMORY_SIZE" -le 10000 ]; then # 显存[8GB-10GB)# 8GB显存,推荐部署1.8B的大模型echo "您当前的显存为 $GPU1_MEMORY_SIZE MiB 推荐部署1.8B的大模型,包括在线的OpenAI API"if [ "$model_size_num" -gt 2 ]; then # 模型大小大于2Becho "您的显存不足以部署 $model_size 模型,请重新选择模型大小"exit 1fi
elif [ "$GPU1_MEMORY_SIZE" -ge 10000 ] && [ "$GPU1_MEMORY_SIZE" -le 16000 ]; then # 显存[10GB-16GB)# 10GB, 11GB, 12GB显存,推荐部署3B及3B以下的模型echo "您当前的显存为 $GPU1_MEMORY_SIZE MiB,推荐部署3B及3B以下的模型,包括在线的OpenAI API"if [ "$model_size_num" -gt 3 ]; then # 模型大小大于3Becho "您的显存不足以部署 $model_size 模型,请重新选择模型大小"exit 1fi
elif [ "$GPU1_MEMORY_SIZE" -ge 16000 ] && [ "$GPU1_MEMORY_SIZE" -le 22000 ]; then # 显存[16-22GB)# 16GB显存echo "您当前的显存为 $GPU1_MEMORY_SIZE MiB 推荐部署小于等于7B的大模型"if [ "$model_size_num" -gt 7 ]; then # 模型大小大于7Becho "您的显存不足以部署 $model_size 模型,请重新选择模型大小"exit 1fiif [ "$runtime_backend" = "default" ]; then # 默认使用Qwen-7B-QAnything+FasterTransformerif [ -n "$gpu_series" ]; then# Nvidia 30系列或40系列if [ $gpu_id1 -eq $gpu_id2 ]; thenecho "为了防止显存溢出,tokens上限默认设置为2700"OFFCUT_TOKEN=1400elseecho "tokens上限默认设置为4096"OFFCUT_TOKEN=0fielseecho "您的显卡型号 $gpu_model 不支持部署Qwen-7B-QAnything模型"exit 1fielif [ "$runtime_backend" = "hf" ]; then # 使用Huggingface Transformers后端if [ "$model_size_num" -le 7 ] && [ "$model_size_num" -gt 3 ]; then # 模型大小大于3B,小于等于7Bif [ $gpu_id1 -eq $gpu_id2 ]; thenecho "为了防止显存溢出,tokens上限默认设置为1400"OFFCUT_TOKEN=2700elseecho "为了防止显存溢出,tokens上限默认设置为2300"OFFCUT_TOKEN=1800fielseecho "tokens上限默认设置为4096"OFFCUT_TOKEN=0fielif [ "$runtime_backend" = "vllm" ]; then # 使用VLLM后端if [ "$model_size_num" -gt 3 ]; then # 模型大小大于3Becho "您的显存不足以使用vllm后端部署 $model_size 模型"exit 1elseecho "tokens上限默认设置为4096"OFFCUT_TOKEN=0fifi
elif [ "$GPU1_MEMORY_SIZE" -ge 22000 ] && [ "$GPU1_MEMORY_SIZE" -le 25000 ]; then # [22GB, 24GB]echo "您当前的显存为 $GPU1_MEMORY_SIZE MiB 推荐部署7B模型"if [ "$model_size_num" -gt 7 ]; then # 模型大小大于7Becho "您的显存不足以部署 $model_size 模型,请重新选择模型大小"exit 1fiOFFCUT_TOKEN=0
elif [ "$GPU1_MEMORY_SIZE" -gt 25000 ]; then # 显存大于24GBOFFCUT_TOKEN=0
fiupdate_or_append_to_env "OFFCUT_TOKEN" "$OFFCUT_TOKEN"if [ $llm_api = 'cloud' ]; thenneed_input_openai_info=1OPENAI_API_KEY=$(grep OPENAI_API_KEY .env | cut -d '=' -f2)# 如果.env中已存在OPENAI_API_KEY的值(不为空),则询问用户是否使用上次默认值:$OPENAI_API_KEY,$OPENAI_API_BASE, $OPENAI_API_MODEL_NAME, $OPENAI_API_CONTEXT_LENGTHif [ -n "$OPENAI_API_KEY" ]; thenread -p "Do you want to use the previous OPENAI_API_KEY: $OPENAI_API_KEY? (yes/no) 是否使用上次的OPENAI_API_KEY: $OPENAI_API_KEY?(yes/no) 回车默认选yes,请输入:" use_previoususe_previous=${use_previous:-yes}if [ "$use_previous" = "yes" ]; thenneed_input_openai_info=0fifiif [ $need_input_openai_info -eq 1 ]; thenread -p "Please enter OPENAI_API_KEY: " OPENAI_API_KEYread -p "Please enter OPENAI_API_BASE (default: https://api.openai.com/v1):" OPENAI_API_BASEread -p "Please enter OPENAI_API_MODEL_NAME (default: gpt-3.5-turbo):" OPENAI_API_MODEL_NAMEread -p "Please enter OPENAI_API_CONTEXT_LENGTH (default: 4096):" OPENAI_API_CONTEXT_LENGTHif [ -z "$OPENAI_API_KEY" ]; then # 如果OPENAI_API_KEY为空,则退出echo "OPENAI_API_KEY is empty, please enter OPENAI_API_KEY."exit 1fiif [ -z "$OPENAI_API_BASE" ]; then # 如果OPENAI_API_BASE为空,则设置默认值OPENAI_API_BASE="https://api.openai.com/v1"fiif [ -z "$OPENAI_API_MODEL_NAME" ]; then # 如果OPENAI_API_MODEL_NAME为空,则设置默认值OPENAI_API_MODEL_NAME="gpt-3.5-turbo"fiif [ -z "$OPENAI_API_CONTEXT_LENGTH" ]; then # 如果OPENAI_API_CONTEXT_LENGTH为空,则设置默认值OPENAI_API_CONTEXT_LENGTH=4096fiupdate_or_append_to_env "OPENAI_API_KEY" "$OPENAI_API_KEY"update_or_append_to_env "OPENAI_API_BASE" "$OPENAI_API_BASE"update_or_append_to_env "OPENAI_API_MODEL_NAME" "$OPENAI_API_MODEL_NAME"update_or_append_to_env "OPENAI_API_CONTEXT_LENGTH" "$OPENAI_API_CONTEXT_LENGTH"elseOPENAI_API_BASE=$(grep OPENAI_API_BASE .env | cut -d '=' -f2)OPENAI_API_MODEL_NAME=$(grep OPENAI_API_MODEL_NAME .env | cut -d '=' -f2)OPENAI_API_CONTEXT_LENGTH=$(grep OPENAI_API_CONTEXT_LENGTH .env | cut -d '=' -f2)echo "使用上次的配置:"echo "OPENAI_API_KEY: $OPENAI_API_KEY"echo "OPENAI_API_BASE: $OPENAI_API_BASE"echo "OPENAI_API_MODEL_NAME: $OPENAI_API_MODEL_NAME"echo "OPENAI_API_CONTEXT_LENGTH: $OPENAI_API_CONTEXT_LENGTH"fi
fiecho "llm_api is set to [$llm_api]"
echo "device_id is set to [$device_id]"
echo "runtime_backend is set to [$runtime_backend]"
echo "model_name is set to [$model_name]"
echo "conv_template is set to [$conv_template]"
echo "tensor_parallel is set to [$tensor_parallel]"
echo "gpu_memory_utilization is set to [$gpu_memory_utilization]"update_or_append_to_env "LLM_API" "$llm_api"
update_or_append_to_env "DEVICE_ID" "$device_id"
update_or_append_to_env "RUNTIME_BACKEND" "$runtime_backend"
update_or_append_to_env "MODEL_NAME" "$model_name"
update_or_append_to_env "CONV_TEMPLATE" "$conv_template"
update_or_append_to_env "TP" "$tensor_parallel"
update_or_append_to_env "GPU_MEM_UTILI" "$gpu_memory_utilization"# 检查是否存在 models 文件夹,且models下是否存在embed,rerank,base三个文件夹
if [ ! -d "models" ] || [ ! -d "models/embed" ] || [ ! -d "models/rerank" ] || [ ! -d "models/base" ]; thenecho "models文件夹不完整 开始克隆和解压模型..."echo "===================================================="echo "******************** 重要提示 ********************"echo "===================================================="echo ""echo "模型大小为8G左右,下载+解压时间可能较长,请耐心等待10分钟,"echo "仅首次启动需下载模型。"echo "The model size is about 8GB, the download and decompression time may be long, "echo "please wait patiently for 10 minutes."echo "Only the model needs to be downloaded for the first time."echo ""echo "===================================================="echo "如果你在下载过程中遇到任何问题,请及时联系技术支持。"echo "===================================================="# 记录下载和解压的时间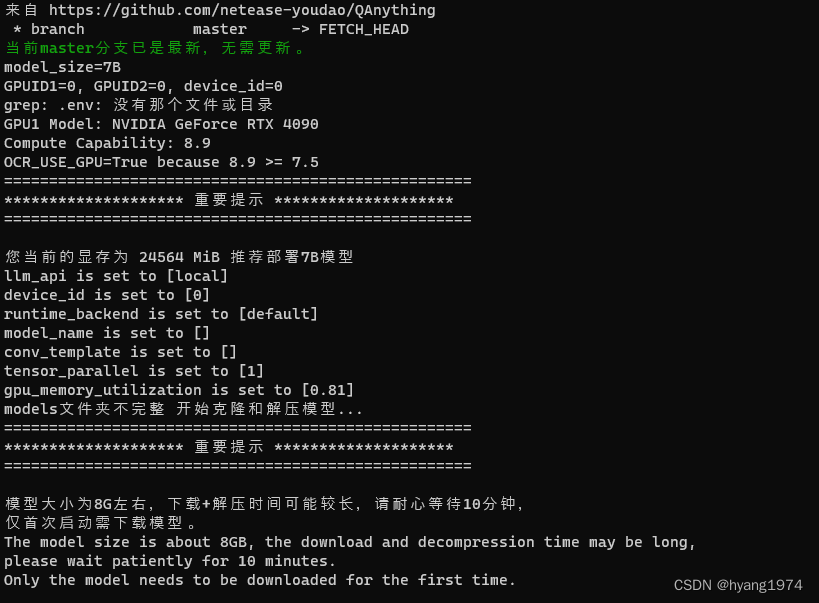
第二步:下载模型
模型下载的主要脚本代码如下。如果已经下载过网络模型,则不会再次下载。
# 如果存在QAanything/models.zip,不用下载if [ ! -f "QAnything/models.zip" ]; thenecho "Downloading models.zip..."echo "开始下载模型文件..."git lfs installgit clone https://www.modelscope.cn/netease-youdao/QAnything.gitd_end_time=$(date +%s)elapsed=$((d_end_time - d_start_time)) # 计算经过的时间(秒)echo "Download Time elapsed: ${elapsed} seconds."echo "下载耗时: ${elapsed} 秒."elseecho "models.zip already exists, no need to download."echo "models.zip已存在,无需下载。"fi# 解压模型文件# 判断是否存在unzip,不存在建议使用sudo apt-get install unzip安装if ! command -v unzip &> /dev/null; thenecho "Error: unzip 命令不存在,请使用 sudo apt update && sudo apt-get install unzip 安装,再重新启动"exit 1fiunzip_start_time=$(date +%s)unzip QAnything/models.zipunzip_end_time=$(date +%s)elapsed=$((unzip_end_time - unzip_start_time)) # 计算经过的时间(秒)echo "unzip Time elapsed: ${elapsed} seconds."echo "解压耗时: ${elapsed} 秒."# 删除克隆的仓库# rm -rf QAnything
elseecho "models 文件夹已存在,无需下载。"
ficheck_version_file() {local version_file="models/version.txt"local expected_version="$1"# 检查 version.txt 文件是否存在if [ ! -f "$version_file" ]; thenecho "QAnything/models/ 不存在version.txt 请检查您的模型文件是否完整。"exit 1fi# 读取 version.txt 文件中的版本号local version_in_file=$(cat "$version_file")# 检查版本号是否为 v2.1.0if [ "$version_in_file" != "$expected_version" ]; thenecho "当前版本为 $version_in_file ,不是期望的 $expected_version 版本。请更新您的模型文件。"exit 1fiecho "检查模型版本成功,当前版本为 $expected_version。"
}check_version_file "v2.1.0"
echo "Model directories check passed. (0/8)"
echo "模型路径和模型版本检查通过. (0/8)"
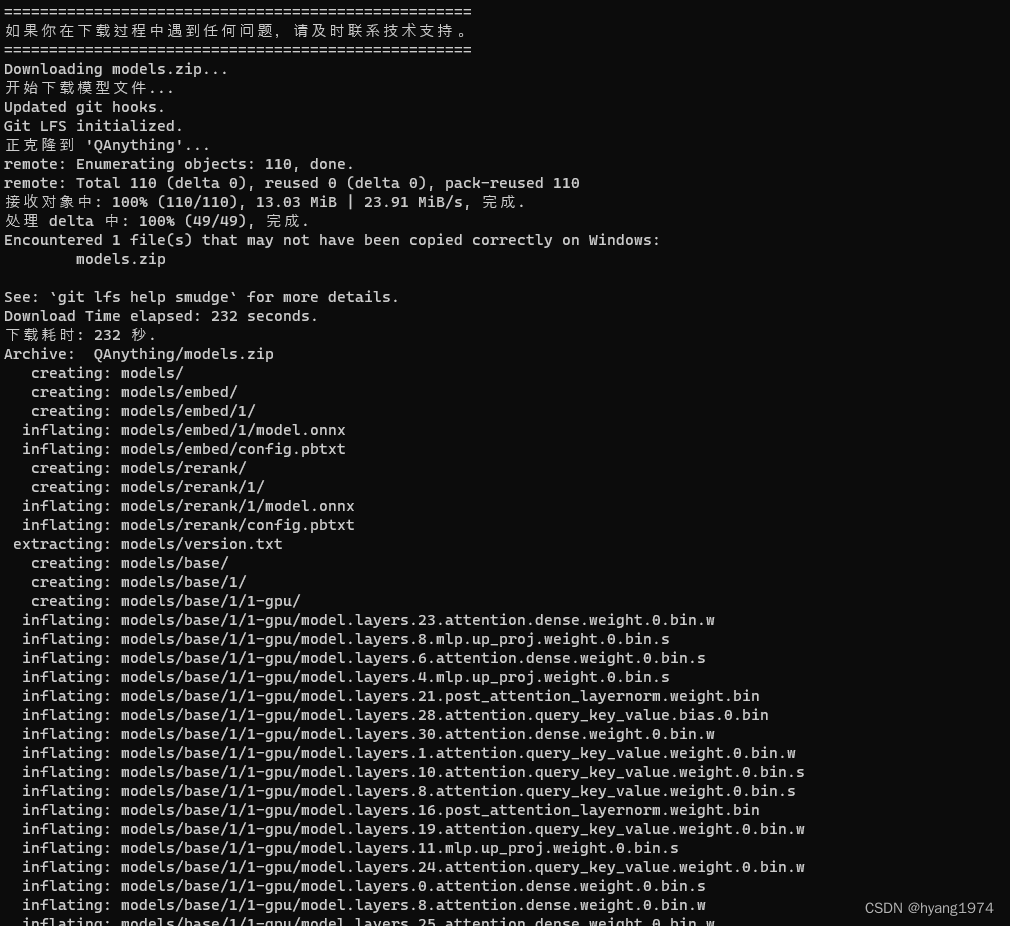
下载和部署QAnything docker
# 检查是否存在用户文件
if [[ -f "$user_file" ]]; then# 读取上次的配置host=$(cat "$user_file")read -p "Do you want to use the previous host: $host? (yes/no) 是否使用上次的host: $host?(yes/no) 回车默认选yes,请输入:" use_previoususe_previous=${use_previous:-yes}if [[ $use_previous != "yes" && $use_previous != "是" ]]; thenread -p "Are you running the code on a remote server or on your local machine? (remote/local) 您是在远程服务器上还是本地机器上启动代码?(remote/local) " answerif [[ $answer == "local" || $answer == "本地" ]]; thenhost="localhost"elseread -p "Please enter the server IP address 请输入服务器公网IP地址(示例:10.234.10.144): " hostecho "当前设置的远程服务器IP地址为 $host, QAnything启动后,本地前端服务(浏览器打开[http://$host:5052/qanything/])将远程访问[http://$host:8777]上的后端服务,请知悉!"sleep 5fi# 保存新的配置到用户文件echo "$host" > "$user_file"fi
else# 如果用户文件不存在,询问用户并保存配置read -p "Are you running the code on a remote server or on your local machine? (remotelocal) 您是在云服务器上还是本地机器上启动代码?(remote/local) " answerif [[ $answer == "local" || $answer == "本地" ]]; thenhost="localhost"elseread -p "Please enter the server IP address 请输入服务器公网IP地址(示例:10.234.10.144): " hostecho "当前设置的远程服务器IP地址为 $host, QAnything启动后,本地前端服务(浏览器打开[http://$host:5052/qanything/])将远程访问[http://$host:8777]上的后端服务,请知悉!"sleep 5fi# 保存配置到用户文件echo "$host" > "$user_file"
fiif [ -e /proc/version ]; thenif grep -qi microsoft /proc/version || grep -qi MINGW /proc/version; thenif grep -qi microsoft /proc/version; thenecho "Running under WSL"elseecho "Running under git bash"fiif docker-compose -p user -f docker-compose-windows.yaml down |& tee /dev/tty | grep -q "services.qanything_local.deploy.resources.reservations value 'devices' does not match any of the regexes"; thenecho "检测到 Docker Compose 版本过低,请升级到v2.23.3或更高版本。执行docker-compose -v查看版本。"fidocker-compose -p user -f docker-compose-windows.yaml up -ddocker-compose -p user -f docker-compose-windows.yaml logs -f qanything_localelseecho "Running under native Linux"if docker-compose -p user -f docker-compose-linux.yaml down |& tee /dev/tty | grep -q "services.qanything_local.deploy.resources.reservations value 'devices' does not match any of the regexes"; thenecho "检测到 Docker Compose 版本过低,请升级到v2.23.3或更高版本。执行docker-compose -v查看版本。"fidocker-compose -p user -f docker-compose-linux.yaml up -ddocker-compose -p user -f docker-compose-linux.yaml logs -f qanything_local# 检查日志输出fi
elseecho "/proc/version 文件不存在。请确认自己位于Linux或Windows的WSL环境下"
fi
下载并运行docker
当看到最后这条打印消息的时候,整个的部署工作就已经成功了。这时候通过Portainer可以看到总共部署了5个docker container:milvus-etcd-local,milvus-minio-local,milvus-standalone-local,mysql-container-local和qanything-container-local。
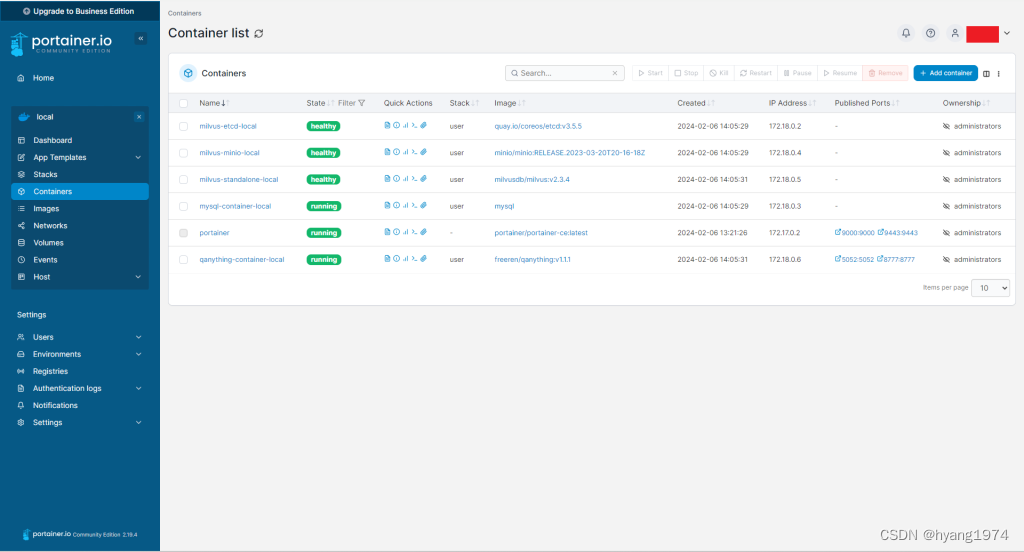
这时候访问上述红框里的URL就可以使用QAnything了。下面的视频是我部署的QAnything的使用demo。我给它输入了一个Tesla Model Y的用户手册,然后就可以向它问各种Model Y的使用问题啦。
如果想体检QAnything的私有化部署和它的各种功能,可以访问我私有化部署的服务器。服务器的地址如下,可以访问我的博文原文:万物皆可问 — 私有部署网易有道QAnything - HY's Blog
作者个人Blog(HY's Blog):https://blog.yanghong.dev











中文使用指南)
)

:关于auto_ptr的一切)


(2))
)
