SAM:如何使模型能够处理任意图像的分割任务?
- 核心思想
- 起始问题: 如何使模型能够处理任意图像的分割任务?
- 5why分析
- 5so分析
- 总结
- 子问题1: 如何编码输入图像以适应分割任务?
- 子问题2: 如何处理各种形式的分割提示?
- 子问题3: 如何快速生成准确的分割掩码?
- 子问题4: 如何应对分割提示的模糊性?
- 子问题5: 如何有效地训练SAM模型?
- 子问题6: 如何收集并利用大规模的分割掩码数据?
论文:https://arxiv.org/pdf/2304.02643.pdf
代码:https://github.com/facebookresearch/segment-anything
核心思想
"Segment Anything"模型是为了解决图片中对象识别和分割的问题提出的,它通过理解指令(Segment)和利用大量图片数据(Anything)来精确地标出图片中指定的对象。
- 你只要告诉它“找猫”,它就能在图片上精确地标出猫的位置。
- 为了让这个模型学会这么多东西,他们收集了超过一亿个这样的“标记”,覆盖了1100万张图片。
- 这个模型非常聪明,甚至不需要特别训练就能处理新的图片和任务。
针对“Segment Anything”项目的核心子问题,我们将进行5why分析来探索问题的根本原因,然后通过5so分析来探讨可能的解决方案及其潜在影响。以下是关于这个项目的一个核心子问题的示例分析。
起始问题: 如何使模型能够处理任意图像的分割任务?
5why分析
- Why 1: 为什么需要模型处理任意图像的分割任务?原因是因为现实世界中的应用场景非常多样,用户需要在不同的环境下识别和分割各种对象。
- Why 2: 这个需求为什么会导致挑战?原因是因为现有的分割模型通常针对特定类型的图像进行优化,缺乏足够的泛化能力。
- Why 3: 为什么现有模型缺乏泛化能力?原因是因为它们通常在有限的、特定的数据集上训练,没有被设计来理解和适应新的、未见过的图像类型或分割任务。
- Why 4: 这个原因背后的更深层次原因是什么?原因是数据收集和标注的高成本限制了数据集的规模和多样性。
- Why 5: 最根本的原因是什么?原因是缺乏一种有效的方法来自动化数据收集和增强模型的泛化能力。
5so分析
- So 1: 因此,我们可以通过开发一种新的模型架构和训练策略,使模型能够理解自然语言的提示并从大规模、多样化的数据集中学习。
- So 2: 这个解决方案会使模型能够零样本学习,即在未直接训练过的新任务上表现良好。
- So 3: 这个结果将极大扩展模型的应用范围,使其能够适应更广泛的实际场景和用户需求。
- So 4: 进一步的影响是促进计算机视觉领域的发展,开辟新的研究和应用方向。
- So 5: 最终,我们希望达到的目标是实现一个能够理解几乎任何图像分割任务的通用模型,提供高效、准确的分割结果,满足广泛的实际需求。
具体算法设计:
-
灵活性 - 零样本学习(Zero-Shot Learning):
- 问题:当设计一个能够处理未见过任务的模型时,零样本学习成为一个核心问题。这要求模型能够理解广泛的任务描述并正确执行,即使它在训练期间没有看到过这些具体的任务。这种需求直接导致了需要开发一种解法来处理新的图像分布和任务,而不依赖于特定任务的训练数据。
- 零样本学习的解决方案 是使用Prompt Engineering,这是因为通过让模型学习理解自然语言指令,可以使模型在没有看到特定任务数据的情况下,对新的任务进行泛化。
-
实时性 - 发一个轻量级掩码解码器,快速响应:
- 问题: 为了使模型能够在实际应用中被实时使用(例如,在线图像编辑或实时图像分析),模型必须能够快速响应用户的指令。这导致了对一个既能支持灵活的提示又能实时输出分割掩码的模型架构的需求。
- 实时交互需求的解决方案 是开发一个具有快速响应能力的模型架构,其中包括一个高效的图像编码器和一个轻量级的掩码解码器,能够迅速生成分割掩码。
跟语言大模型一样,需要给 SAM 模型一个prompt提示,这个提示可以是一个点(point),也可以是几个点(points),也可以是一个框(box),也可以是一个文本(text),而SAM就根据prompt提示分割目标物体,就像下面这样:
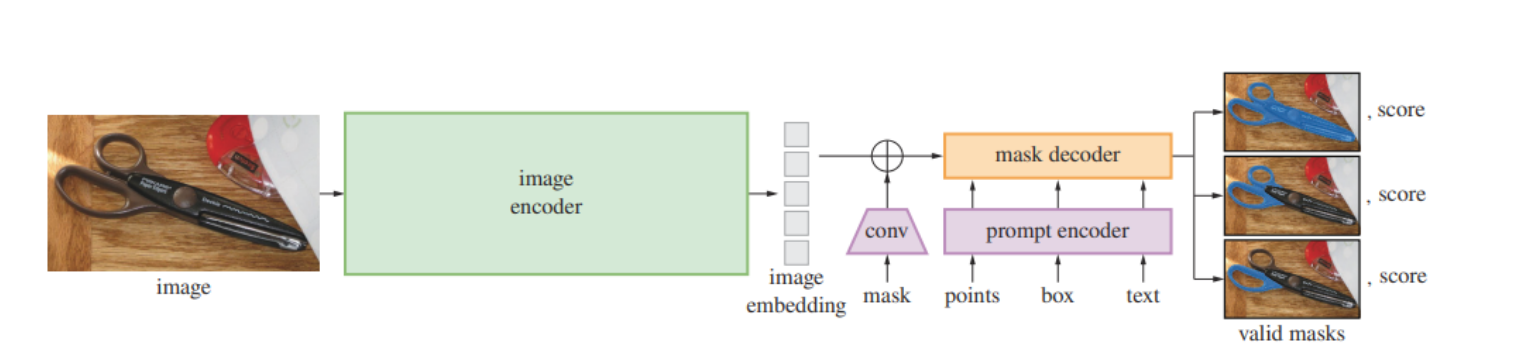
- SAM的概览图,一个重量级的图像编码器输出图像嵌入,然后可以被多种输入提示高效查询以产生对象掩码,实现了摊销的实时速度(50毫秒以下)。
- 对于可以对应多个对象的模糊提示,SAM能输出多个有效的掩码以及相关的置信分数。
- 准确性 - 给深度学习模型喂大规模、多样化训练数据:
- 问题: 为了训练一个能广泛适用于各种图像和任务的模型,需要大量的、多样化的训练数据。鉴于现有的数据集无法满足这一需求,因此产生了如何有效收集这种数据的问题。
- 大规模、多样化数据收集的解决方案 是构建一个“数据引擎”,利用模型辅助的方法来高效生成和收集训练数据。
补充一下,解码器、掩码解码器、分割掩码:
-
解码器是一种算法或模型组件,它的任务是从某种编码的数据中重构或解释信息。在机器学习和深度学习中,解码器通常用于将编码的表示(例如,一个深度神经网络中间层的输出)转换为更容易理解或更有用的格式(如文本、图像等)。
-
掩码解码器是一种特殊类型的解码器,专门设计用于生成图像的分割掩码。在图像分割任务中,掩码解码器接收图像的编码表示(通常由图像编码器产生)和可能的其他信息(如分割任务的指令),并输出一个或多个分割掩码。这些掩码精确地指示图像中的特定区域,如哪些像素属于特定的对象或背景。
-
分割掩码是一个与原图像大小相同的图像,其中每个像素的值指示该像素属于图像中的哪个部分或对象。在最简单的形式中,分割掩码可以是二值的,即像素值为0表示该像素不属于目标对象,值为1表示属于目标对象。在更复杂的场景中,分割掩码可以有多个值,每个值代表图像中不同的对象或区域。
你有一张包含猫和狗的照片,你想分别标出猫和狗的位置。
- 图像编码器首先处理这张照片,提取出重要的视觉特征并将它们编码成一种密集的表示形式。
- 掩码解码器然后接收这个编码,加上一个指令(比如“找出所有的猫”),并工作于将编码转换为一个分割掩码,这个掩码准确地标示出图片中猫的位置。
- 分割掩码最终是一张与原图大小相同的图,但只有标示出猫的部分被标记为1(或其他非零值),其余部分为0,清晰地区分出猫和背景(以及狗,如果指令是分割出猫)。
优势在于能够快速并准确地响应复杂的图像分割请求,使之适用于实时交互场景,如在线图像编辑工具或实时监控系统中的对象识别和跟踪。
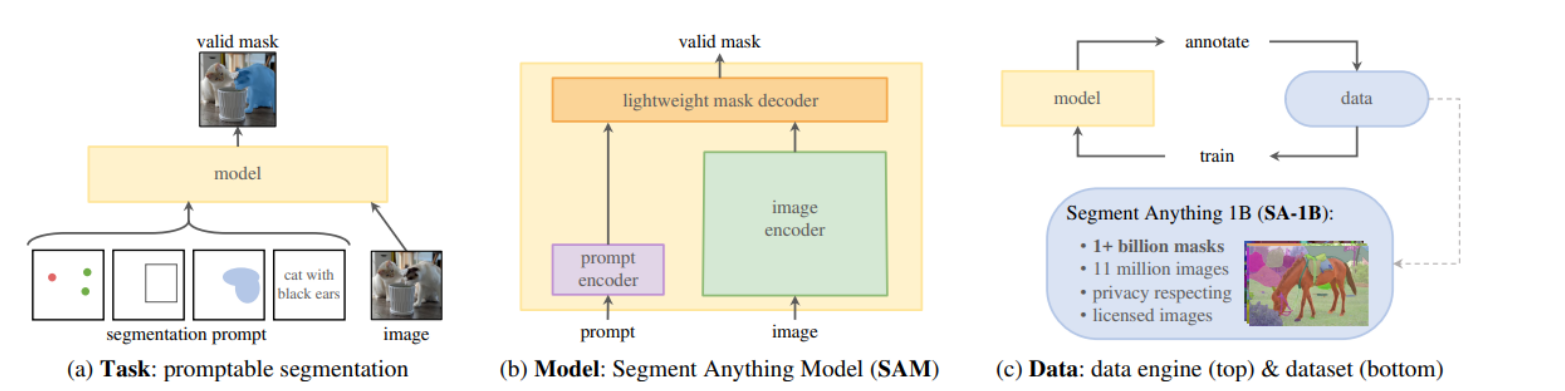
SAM 的设计取决于三个主要组件:
-
图1 (a) Task: promptable segmentation
- 展示了SAM模型的基本任务——可提示的图像分割。
- 图中展示了不同类型的提示(如点、框、文本)和模型如何根据这些提示生成有效的分割掩码。
-
图1 (b) Model: Segment Anything Model (SAM)
- SAM的三个主要组成部分:图像编码器、提示编码器和快速掩码解码器。
- 这表明了SAM的结构是怎样根据各种输入提示产生分割掩码的。
-
图1 © Data: data engine (top) & dataset (bottom)
- 数据引擎、大规模数据集。
- 顶部是SAM模型的数据引擎,说明了数据如何通过人工标注和模型训练来收集;
- 底部是SAM的数据集,SA-1B,它包含超过11M的图片和1B的分割掩码。
- 模型标注数据,再用标注好的数据用来优化模型,以此循环,迭代优化模型以及数据质量。

- 图3
- 展示了从单一模糊提示(绿圈)生成的三个有效掩码的例子。
- 这展示了SAM模型在处理模糊或多义性提示时能够生成多个有效选项的能力。
图3显示了SAM模型如何对一个给定的模糊提示(绿圈)生成多个有效的分割掩码。
在图像分割任务中,一个模糊的提示可能对应于图像中多个不同的对象。
例如,如果提示是图像中的一个点,那么这个点可能位于多个重叠物体的交叉点上,或者无法清楚地指明是指哪个物体。
在这种情况下,模型面临的挑战是如何解释这个模糊的提示并决定哪个对象应该被分割。
SAM模型采用的方法是生成多个可能的分割掩码,每个掩码代表了一个潜在的对象。
这样,即使一个提示可能对应于多个对象,SAM也能提供多个合理的分割选项,用户随后可以从中选择最合适的掩码。
这种方法提高了模型在处理不明确或多义性情况时的实用性和灵活性。
总结
SAM模型的逻辑结构。
子问题1: 如何编码输入图像以适应分割任务?
- 子解法1: 使用Vision Transformer (ViT)作为图像编码器
- 之所以用ViT解法,是因为它能够处理高分辨率输入,并通过自注意力机制捕获图像的全局特征,这对于图像分割任务至关重要。
子问题2: 如何处理各种形式的分割提示?
- 子解法2: 设计灵活的提示编码器
- 之所以用灵活的提示编码器解法,是因为分割任务需要能够理解从简单的点和框到复杂的文本描述等各种提示形式,这要求提示编码器具有处理多种输入类型的能力。
子问题3: 如何快速生成准确的分割掩码?
- 子解法3: 创建快速掩码解码器
- 之所以用快速掩码解码器解法,是因为实时(50毫秒以下)应用要求模型必须在接收到输入提示后迅速生成分割掩码,以保证用户体验。
子问题4: 如何应对分割提示的模糊性?
- 子解法4: 预测多个可能的分割掩码
- 之所以用预测多个可能的分割掩码解法,是因为某些提示可能指向多个可能的对象,模型需要能够为单个提示生成多个合理的掩码。
子问题5: 如何有效地训练SAM模型?
- 子解法5: 模拟提示序列的预训练算法
- 之所以用模拟提示序列的预训练算法解法,是因为能模拟真实世界中的分割任务,通过在训练过程中提供各种假设的用户输入(即提示),来训练模型。
在预训练过程中,模型会尝试理解这些提示并产生对应的分割掩码。模型的输出会与真实的分割掩码(即ground truth)进行比较,并根据这些比较进行优化。
随着训练的进行,模型会越来越好地学习如何解释各种提示并生成高质量的分割掩码,这样在实际应用中,当用户提供一个提示时,模型就能够生成一个准确的分割掩码,即使这个提示在不同的情境下可能会引用到多个不同的对象。
子问题6: 如何收集并利用大规模的分割掩码数据?
- 子解法6: 构建数据引擎来自动化数据收集
- 之所以用构建数据引擎解法,是因为分割掩码数据通常不如图像数据那样容易获取,需要一个自动化系统来高效地收集和标注数据,模型标注数据,数据优化模型,循环。
任务是从一张充满人群的街景照片中,分割出特定穿红衣服的人:
- 图像编码器首先将输入图像编码成一个特征丰富的表示。
- 提示编码器接收一个文本提示“穿红衣服的人”,将其转换成模型可以理解的编码。
- 掩码解码器使用图像特征和提示编码快速生成可能的分割掩码。
- 如果提示指向多个穿红衣服的人,模型会生成多个掩码,每个掩码代表一个可能的红衣人物。
- 在预训练阶段,模型通过模拟真实世界的分割任务来学习如何处理各种复杂的提示。
- 利用数据引擎,模型能够在不需要人工标注的情况下,自动从成千上万的街景照片中收集和利用分割掩码数据。
)








— 片元半兰伯特着色器解析)




——OAuth2令牌管理策略)




