1.配置服务器ssh免密登录,否则后面启动会报错:尝试通过SSH连接到主机出现认证错误的提示

配置服务器ssh免密登录:
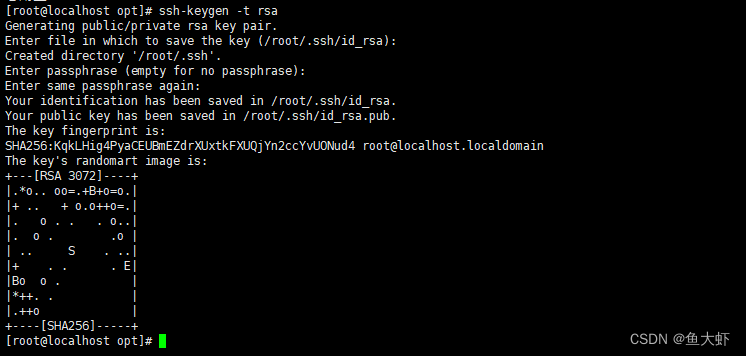
1.生成SSH密钥对(如果尚未生成):
执行下面的命令生成密钥对,一直回车即可
ssh-keygen -t rsa出现下面的提示说明生成成功了:
2.第二步,将公钥添加到
~/.ssh/authorized_keys文件:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys添加成功后我们查看 ~/.ssh/authorized_keys 文件中是否有密钥对
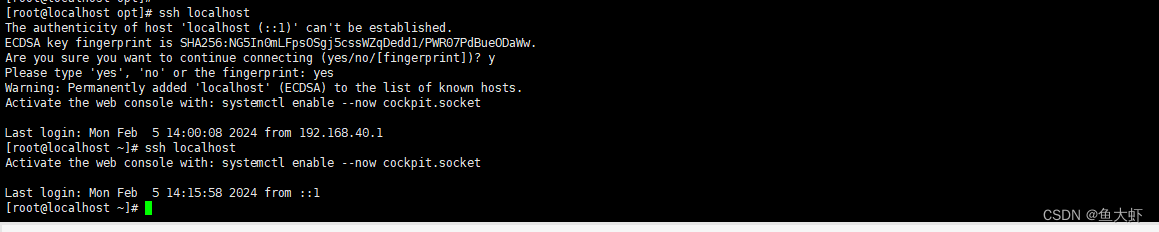
3.使用命令重启ssh服务sudo systemctl restart sshd4.使用ssh localhost测试是否可以直接连接到本机
ssh localhost如果出现是否继续连接的提示输入 yes 回车即可,再次验证则直接登录,出现下面的图示则说明配置成功

2.关闭防火墙
#查看防火墙状态systemctl status firewalld #关闭防火墙systemctl stop firewalld#设置开机禁用防火墙systemctl disable firewalld.service
3.安装JDK(jdk8以上,我这里用的1.8最新的)
jdk下载地址:Java Downloads | Oracle
网盘链接:百度网盘百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百度网盘即可享受免费存储空间![]() https://pan.baidu.com/s/1fB5ib4GPz_0JSO3ncvVI4Q 提取码: besp
https://pan.baidu.com/s/1fB5ib4GPz_0JSO3ncvVI4Q 提取码: besp
安装步骤不再赘述,请参考:Centos 配置 Java JDK开发环境_centos wget 安装 jdk-8u333-CSDN博客
4.安装Hadoop 3.3.6 伪分布式安装方式
1.hadoop下载地址: https://archive.apache.org/dist/hadoop/common/
最新版的就是3.3.6版本
2.把jdk和Hadoop安装包都上传到服务器 /opt 目录下
解压:
tar -zxvf jdk-8u401-linux-x64.tar.gz tar -zxvf hadoop-3.3.6.tar.gz环境变量配置:在 /etc/profile 文件中加入以下环境变量:vim /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_401 export PATH=$PATH:$JAVA_HOME/binexport HADOOP_HOME=/opt/hadoop-3.3.6 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin如图所示:
执行命令使配置生效:
source /etc/profile检验配置:java -version 以及 hadoop version 命令查看
修改 Hadoop 配置文件:
编辑 Hadoop 配置文件,主要是core-site.xml,hdfs-site.xml,和 mapred-site.xml。
进入到hadoop目录配置下:以下的操作都是在该目录下进行
cd /opt/hadoop-3.3.6/etc/hadoop编辑 core-site.xml:下面是我虚拟机的ip地址
fs.defaultFS: 指定HDFS的默认文件系统URI
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.40.132:9000</value>
</property>

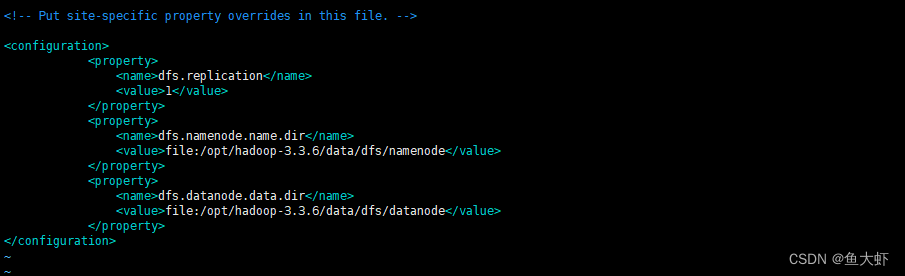
编辑 hdfs-site.xml:下面的 /opt/hadoop-3.3.6/data/dfs/datanode 文件夹需自行创建
dfs.replication: 指定数据块的副本数量。dfs.namenode.name.dir: 指定NameNode存储文件的本地目录。dfs.datanode.data.dir: 指定DataNode存储数据块的本地目录。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-3.3.6/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-3.3.6/data/dfs/datanode</value>
</property>
编辑 mapred-site.xml:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
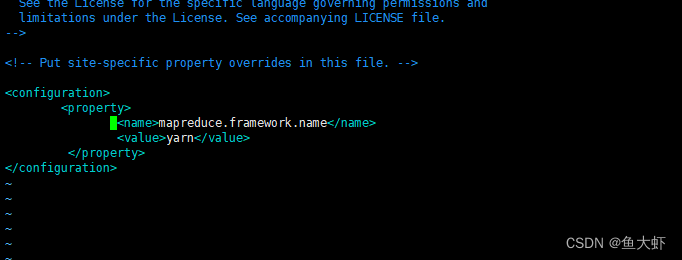
配置 Hadoop 环境:
vim hadoop-env.sh
export HDFS_SECONDARYNAMENODE_USER="root"
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
export JAVA_HOME=/opt/jdk1.8.0_401
export HADOOP_HOME=/opt/hadoop-3.3.6
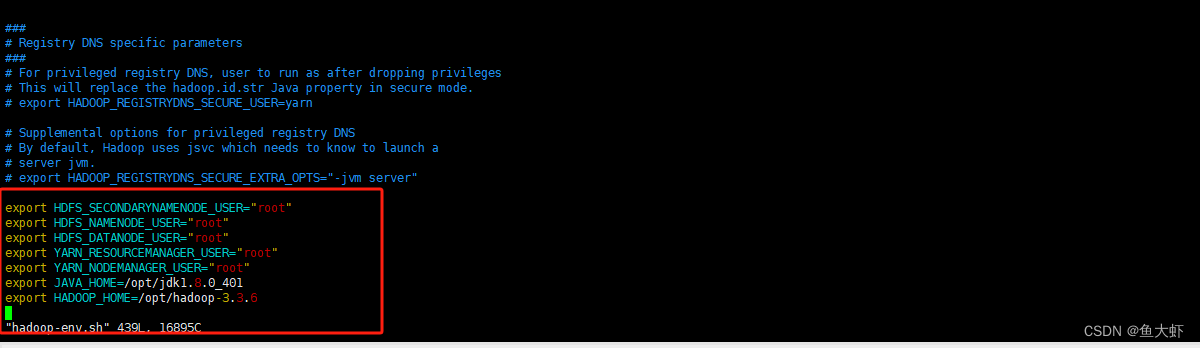
在Hadoop环境中,需要为各个角色(例如NameNode、DataNode等)指定相关的用户。如果不配置上面的各个角色,则启动会报下面的错误:

启动 Hadoop:
格式化 HDFS 文件系统:
hdfs namenode -format
出现下面的提示则说明格式化成功了

启动 Hadoop 伪集群:
start-dfs.sh
start-yarn.sh#重启 hadoop (先停止服务,再启动)
#直接在 /opt/hadoop-3.3.6/etc/hadoop 目录下执行 (自己的安装目录)
stop-dfs.sh
stop-yarn.sh
start-dfs.sh
start-yarn.sh
验证安装:
在浏览器中访问 Hadoop ResourceManager 界面:
http://ip:8088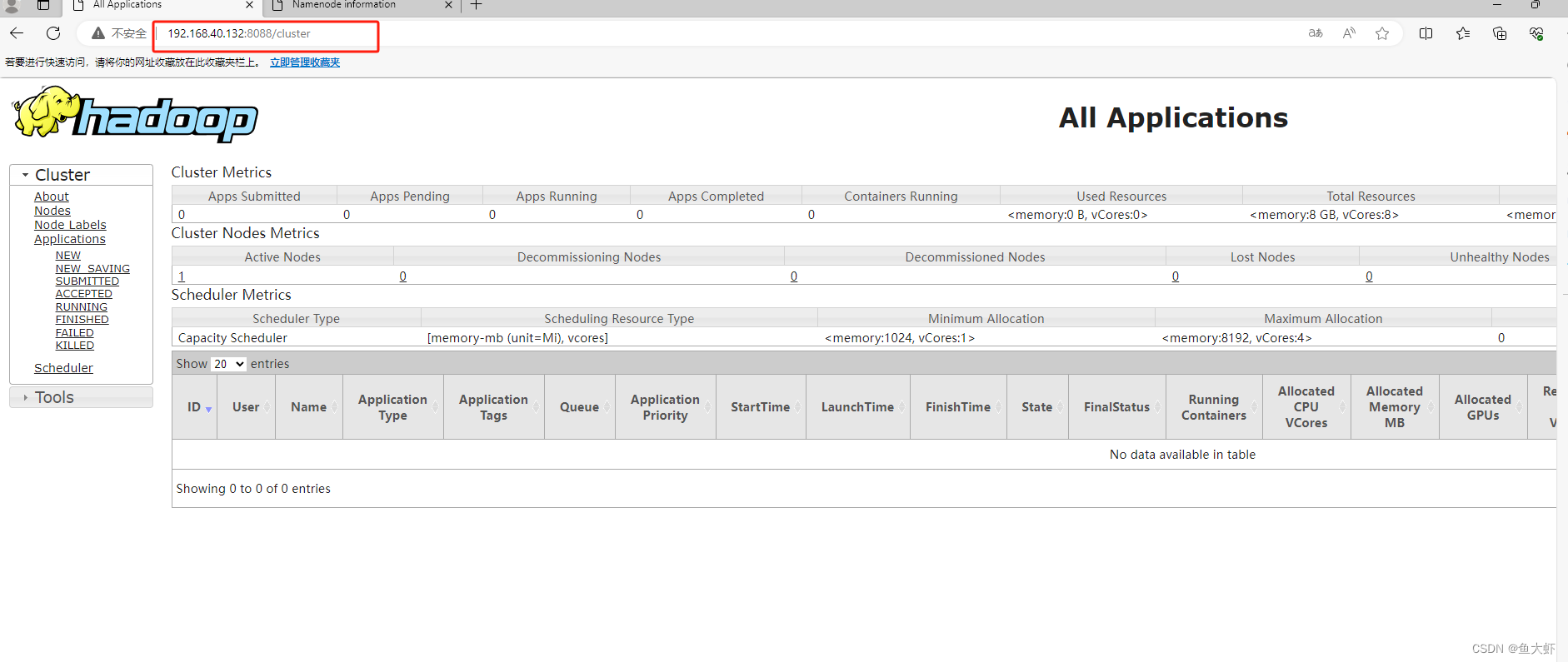
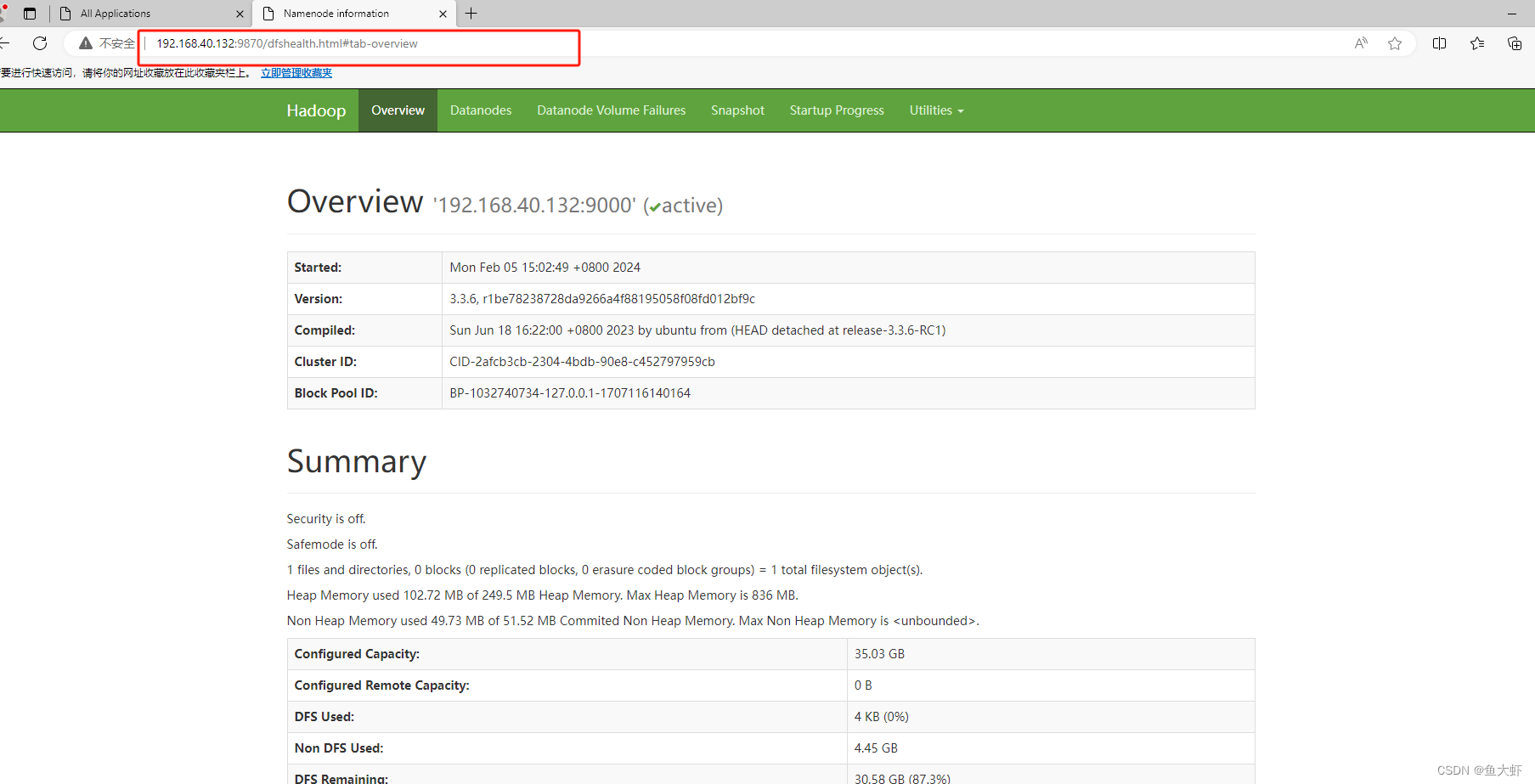
或者访问Hadoop DFS界面:
http://ip:9870
你还可以使用以下命令查看Hadoop集群的状态:
jps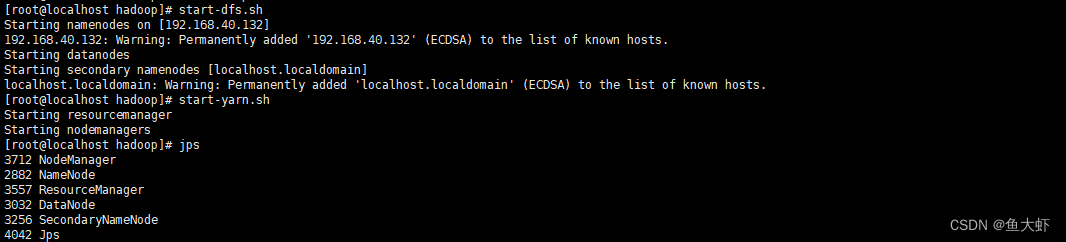
这应该显示一些Hadoop进程,包括NameNode,DataNode,ResourceManager等。
现在,你的Hadoop伪集群应该已经启动并运行了。请注意,这只是一个基本的配置,具体的配置和调整可能会根据你的需求有所不同。

)








,java实现)








