现在咱们要一起创建您的第一个机器学习模型啦!

选择建模数据
你的数据集包含太多变量,让你无法理解,甚至无法很好地打印出来。你如何将这大量的数据减少到你能理解的程度?
我们将从直觉上选择几个变量。后续课程将向你展示自动优先选择变量的统计技术。
为了选择变量/列,我们需要查看数据集中所有列的列表。可以通过DataFrame的columns属性来完成(下面的代码的最后一行)。
import pandas as pdmelbourne_file_path = './melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns上述代码中的数据集样本,可以从我的《政安晨:机器学习快速入门(一)》文章上方的立即下载中获取到(下载后,解压到工作目录中使用)。
政安晨:机器学习快速入门(一){基于Python与Pandas}![]() https://blog.csdn.net/snowdenkeke/article/details/136046028
https://blog.csdn.net/snowdenkeke/article/details/136046028 
准备好后,执行上述代码如下:

# 墨尔本的数据中存在一些缺失值(一些房屋的某些变量没有记录)。
# 我们将在以后学习如何处理缺失值
# 爱荷华数据在你使用的列中没有缺失值。
# 所以我们现在将选择最简单的选项,从我们的数据中排除房屋。
# 现在不用太担心这个,放心使用:dropna 删除缺失值(将na视为“不可用”)。melbourne_data = melbourne_data.dropna(axis=0)选择数据子集的方法有很多种。
在Pandas的官方文档中,会更深入地介绍这些方法,但现在我们先关注两种方法。
1)点符号法,用来选择“预测目标”;
2) 使用列列表进行选择,用来选择“特征”。
选择预测目标
先来一段说明:
{-->
在进行预测任务时,首先需要选择一个预测目标。预测目标可以是一个连续的数值,也可以是一个分类标签。
如果预测目标是一个连续的数值,那么预测任务被称为回归任务。回归任务的目标是通过输入变量的值来预测一个连续的输出变量的值。例如,预测房屋价格或股票价格就是回归任务。
如果预测目标是一个分类标签,那么预测任务被称为分类任务。分类任务的目标是通过输入变量的值来预测一个离散的分类标签。例如,预测一封电子邮件是垃圾邮件还是非垃圾邮件就是分类任务。
在选择预测目标时,需要考虑以下几个因素:
-
数据集中可用的变量:首先需要查看数据集中可用的变量。根据可用的变量,可以选择一个与目标相关的变量作为预测目标。
-
预测任务的目的:需要明确预测任务的目的是什么。是为了预测某种数值,还是为了分类某种标签。
-
数据的性质:还需要考虑数据的性质。如果数据是连续的,那么回归任务可能更合适。如果数据是离散的,那么分类任务可能更合适。
选择预测目标是进行预测任务的重要一步。正确选择预测目标可以提高预测模型的准确性和可用性。
--> }
您可以使用点表示法提取变量。这个单独的列存储在Series中,它类似于一个只有单列数据的DataFrame。我们将使用点表示法选择我们要预测的列,这个列被称为预测目标。
按照惯例,预测目标称为y。所以我们需要的代码是将墨尔本数据中的房价保存为:
y = melbourne_data.Price选择“特征”
我们模型中输入的列(后来用于进行预测)称为“特征”。在我们的案例中,这些将是用于确定房屋价格的列。有时,除了目标列之外,您将使用所有列作为特征。其他时候,您可能只需要较少的特征。
现在,我们将只使用几个特征来构建模型。以后您将看到如何迭代和比较使用不同特征构建的模型。
我们通过在括号内提供列名的列表来选择多个特征。列表中的每个项都应该是一个字符串(带引号)。
示例如下:
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']根据惯例,这些数据被称为X。
X = melbourne_data[melbourne_features]让我们快速回顾一下我们将使用的数据,使用describe方法和head方法来预测房价,head方法显示前几行数据。
X.describe()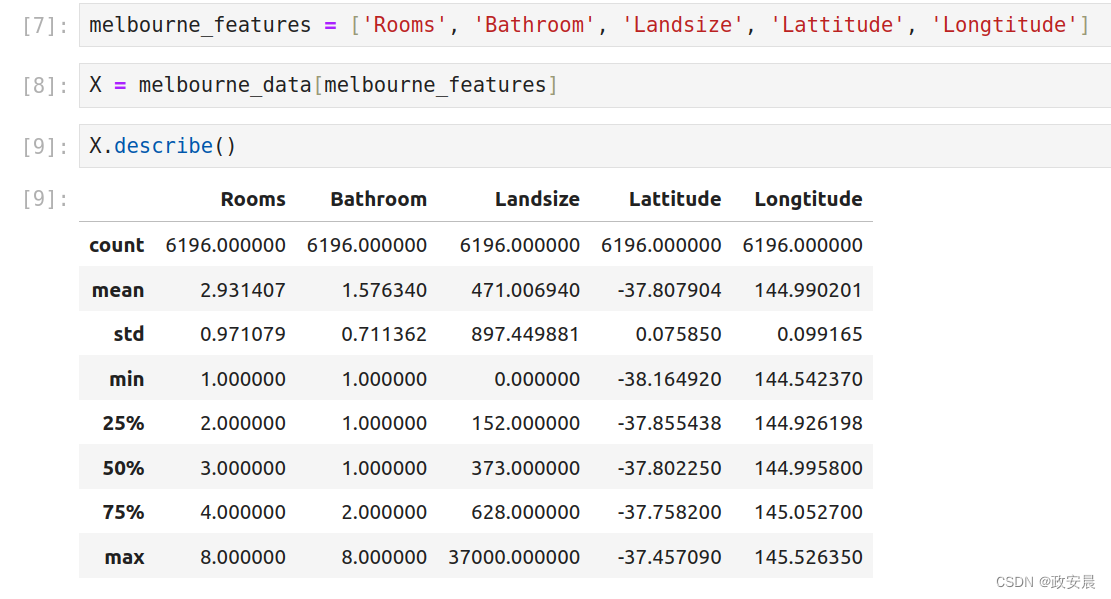
X.head()
使用这些命令对数据进行可视化检查是数据科学家工作的重要部分。您经常会发现数据集中令人惊讶且值得进一步检查的地方。
建立您自己的模型
您将使用scikit-learn库来创建您的模型。在编码时,该库的写法是sklearn,正如您在示例代码中看到的那样。
Scikit-learn是用于建模通常存储在DataFrames中的数据类型的最流行的库。
咱们还是用点篇幅介绍下一:
Scikit-learn是一个基于Python的开源机器学习库,提供了丰富的机器学习算法和工具集。它建立在NumPy、SciPy和matplotlib库的基础上,为用户提供了一种简单而有效的方法来进行数据预处理、特征选择、模型评估和模型选择。
以下是一些scikit-learn库的主要功能:
-
数据预处理:scikit-learn提供了一系列数据预处理工具,如标准化、归一化、缩放、向量化、二值化等。这些工具能够将原始数据转换为适合机器学习算法处理的格式。
-
特征选择:scikit-learn提供了多种特征选择方法,如基于统计方法的特征选择、基于模型的特征选择、递归特征消除等。这些方法可以帮助用户在训练模型之前选择最相关的特征,从而提高模型的性能。
-
模型评估:scikit-learn提供了多种模型评估方法,如交叉验证、网格搜索、学习曲线、混淆矩阵等。这些方法能够帮助用户评估模型的性能,选择最佳的参数和超参数,并了解模型的泛化能力。
-
模型选择:scikit-learn提供了多种机器学习算法,如线性模型、决策树、随机森林、支持向量机、朴素贝叶斯、神经网络等。用户可以根据问题的性质和数据的特征选择合适的模型进行训练和预测。
-
集成方法:scikit-learn还提供了多种集成方法,如Bagging、Boosting、随机森林、投票分类器等。这些方法可以组合多个基础模型,以产生更强大和稳定的模型。
除了上述功能外,scikit-learn还包含了一些实用工具,如数据集加载、特征工程、模型持久化等。此外,scikit-learn还具有可扩展性,并与其他Python库和工具集(如Pandas、matplotlib和TensorFlow)良好兼容,使用户能够更加灵活地开展机器学习工作。
总而言之,scikit-learn是一个功能强大且易于使用的机器学习库,适用于各种机器学习任务。无论你是机器学习初学者还是专业人士,scikit-learn都能为你提供丰富的工具和资源,帮助你构建和部署高效的机器学习模型。
好了,咱们现在开始构建模型,构建和使用模型的步骤如下:
定义:它将是什么类型的模型?决策树?其他类型的模型?还指定了该模型类型的其他参数。 拟合:从提供的数据中捕捉模式。这是建模的核心。 预测:就像它听起来的那样 评估:确定模型预测的准确度。
以下是使用scikit-learn定义决策树模型并使用特征和目标变量进行拟合的示例代码:
from sklearn.tree import DecisionTreeRegressor# Define model. Specify a number for random_state to ensure same results each run
melbourne_model = DecisionTreeRegressor(random_state=1)# Fit model
melbourne_model.fit(X, y)先别着急运行上述代码,您应该知道我要说什么吧:咱们现在要安装scikit-learn。
pip install scikit-learn
安装成功后,执行上述代码如下(咱们训练了一个模型):
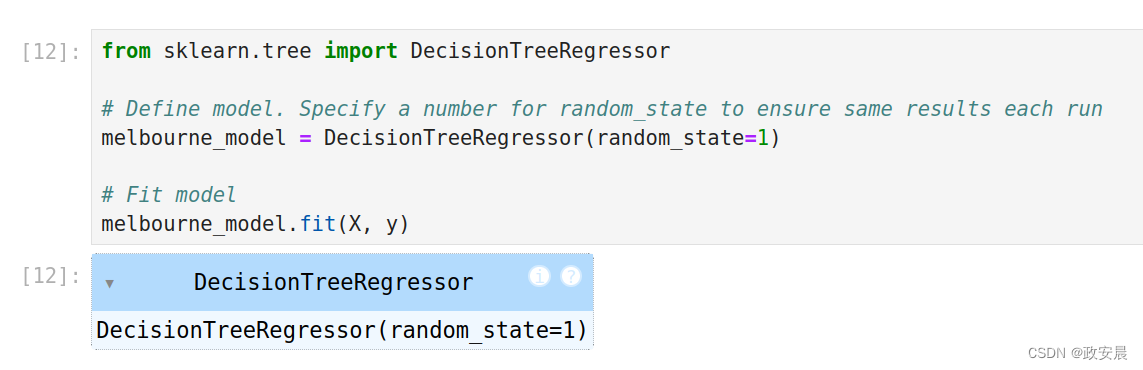
许多机器学习模型在模型训练中允许一定的随机性。为random_state指定一个数字可以确保在每次运行中得到相同的结果。这被认为是一种良好的做法。你可以使用任何数字,模型质量并不会在你选择的确切值上有实质性的影响。
现在我们有了一个已拟合的模型,我们可以用它来进行预测。
使用新模型预测
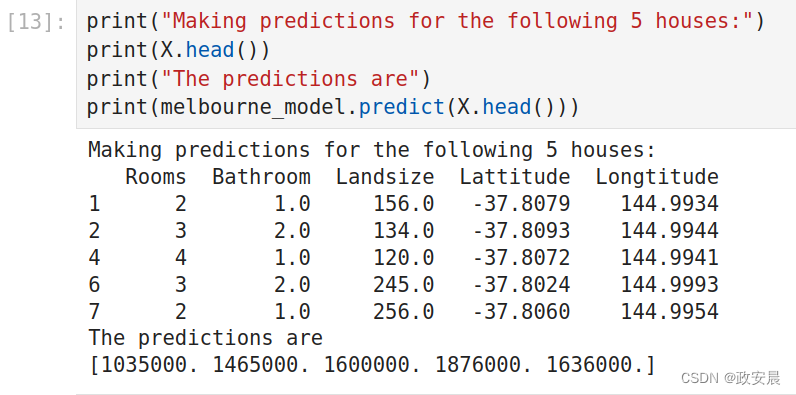
实际上,你可能更希望对新上市的房屋进行预测,而不是我们已经有价格的房屋。但是我们将对训练数据的前几行进行预测,以查看predict函数的工作原理。
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))预测结果如下:
告一段落
看吧,这么短的时间内,您就完成了一个模型,并利用它进行了预测,机器学习的模型原理您已经知道啦。
)



——多线程编程)
,分析高光谱曲线数据或时序数据)

loongnix下编译syncthing)






)
)



