1、新添参数说明
// Driver和Executor内存和CPU资源相关配置
--是否开启executor动态分配,开启时spark.executor.instances不生效
spark.dynamicAllocation.enabled=false
--配置Driver内存
spark.dirver.memory=5g
--driver最大结果大小,设置为0代表不限制,driver在拉取结果时,如果结果超过阈值会报异常
spark.driver.maxResultSize=0
--配置executor内存和cpu
spark.executor.memory=5g
spark.executor.cores=8
--executor额外内存,executor内存包括三个部分,heap、off-heap以及overhead,heap和off-heap用于存储executor上任务的执行结果块以及用作执行内存,overhead作为额外内存用于存储虚拟机的开销
spark.yarn.executor.memoryOverhead=6120
--配置executor实例个数,此种方式是固定资源分配方式
spark.executor.instances=25
--是否开启executor堆外内存,以及堆外内存的的大小
spark.memory.offHeap.enabled=true
spark.memory.offHeap.size=2048mb
--spark内存既可以用于存储也可以用于计算,计算内存和存储内存是软边界,这个参数用于设置存储内存的比例
spark.memory.fraction=0.4
// 序列化器相关配置,spark默认采用java序列化器,也提供kryoserializer的实现,后者的性能是前者的十倍,
spark.kryoserializer.buffer.max=2047mb
spark.kryoserializer.buffer=16384kb
//中间结果网络传输压缩,缓解内存和网络传输压力
spark.shuffle.compress=true
spark.rdd.compress=true
//开启spark任务推断,优化分区任务执行时间不均衡问题,避免严重拖后腿任务
spark.speculation=true
spark.speculation.interval=60s
spark.speculation.multiplier=1.3
spark.speculation.quantile=0.99
//网络通信超时和失败重试相关参数,避免网络质量差或不稳定导致的任务失败
spark.network.timeout=300
spark.shuffle.io.maxRetries=30
spark.shuffle.io.retryWait=10s
//spark对分区结果的大小做了2G的限制,超出了就会报too large dataframe异常,这时需要增加shuffle分区,缓解数据倾斜,但是如果数据本身是倾斜了,下面参数治标不治本,默认300
spark.sql.shuffle.partitions=500
//设置自动广播阈值,在大表join小表时可以将小表作为广播变量,存在内存中,提升join的性能
spark.sql.autoBroadcastJoinThreshold=-1
- 参数影响
- 什么时候需要将spark.dynamicAllocation.enable设置为false?
回答:spark默认按照128m来对文件进行分区,如果文件比较大,比如40G,分区多达300多个,采用动态分配策略,可能导致占用太多的集群资源,使得集群崩溃,如下对比图。
图1: 采用动态分配策略,executor实例数高达115个(第116另Driver)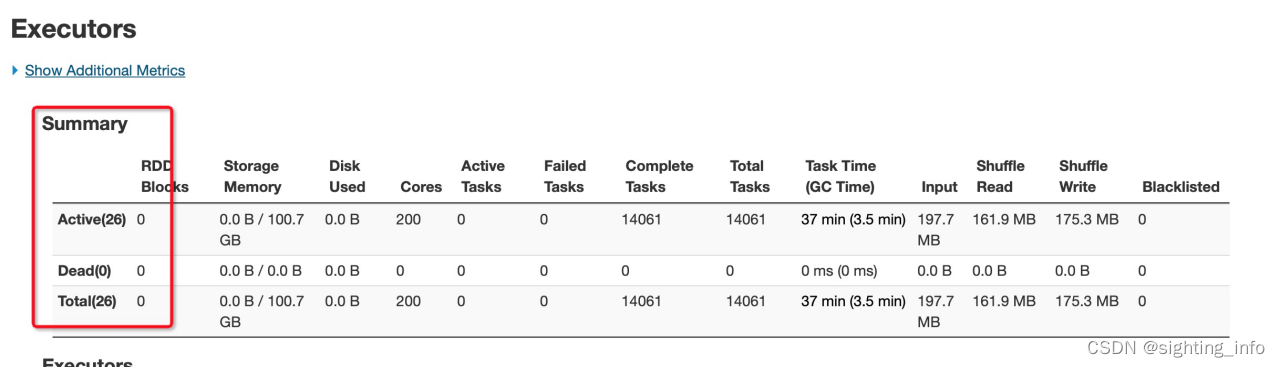
图2:采用静态分配策略,executor实例数固定为25个
- spark.memory.offHeap.enabled和spark.memory.offHeap.size的影响?
回答:在运行百万级别job_trsf_dim_chl_cust_spark_df任务时,使用默认配置参数,报直接内存不足异常,导致作业运行失败,如下图:

图3: 堆外内存不足导致任务运行失败
添加以上参数后作业运行成功。
- spark.kryoserializer.buffer大小的调整?
回答:当使用kryoserializer序列化器时,遇到Buffer大小不足,提示require ** but available等信息,需要调大上述参数。
第四、调大spark.sql.shuffle.partitions的目的?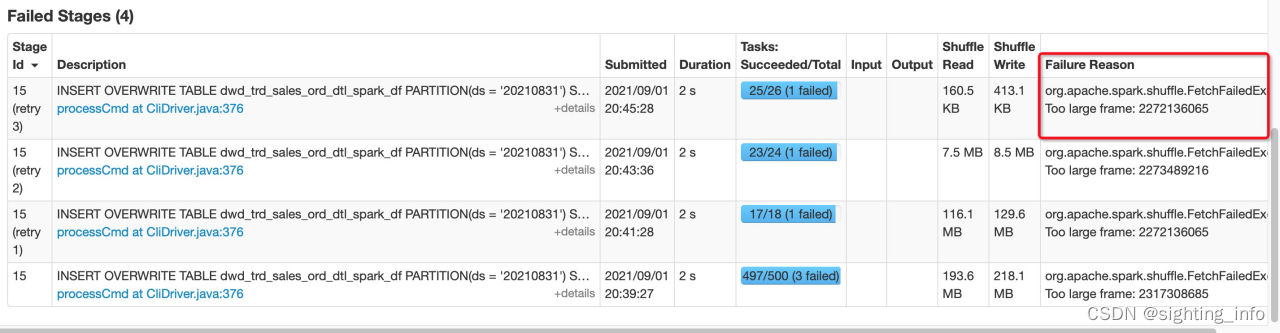
图4: 分区结果超过2G错误
回答:当出现如上图所示错误,很大程度是因为数据发生了倾斜,这时可以调整shuffle的分区,均衡分区中的数据,但如果数据本身是倾斜,只能自定义分区规则重写Spark Partitioner或进行SQL调优。
- 为什么要避免对大表进行select * 操作?
回答:因为Spark是以Client方式向Yarn提交作业,查询的结果会返回给Driver端,对一个40G的表进行全量查询,会导致Driver端崩溃,导致如下图所示的错误:
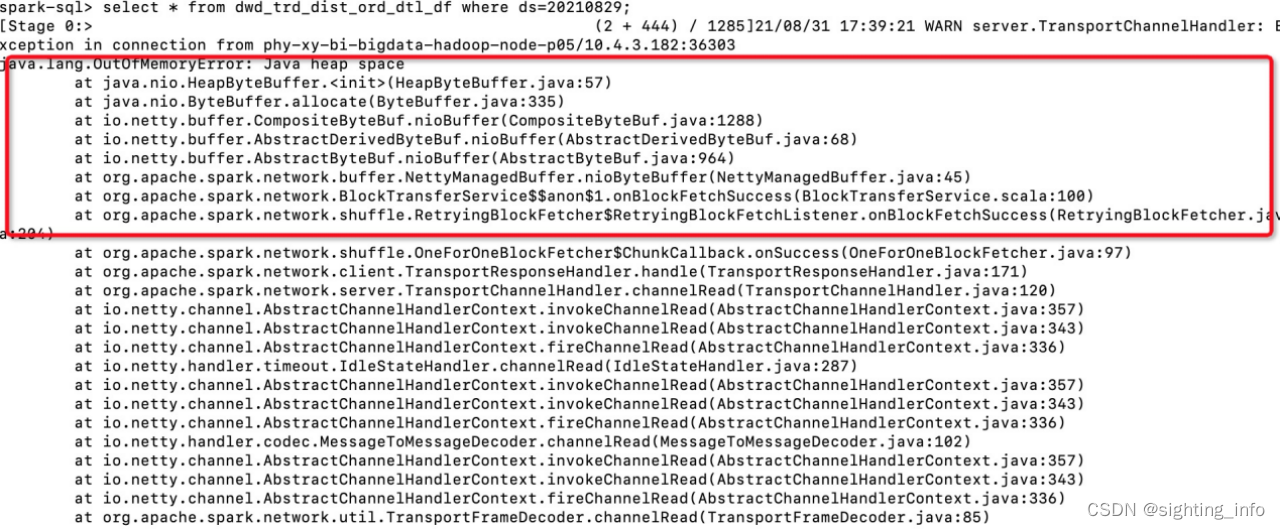
图5: Jave堆内存



)



)
:scrapy下载中间件实现动态切换User-Agent)
-- 网站开发中session、cache、cookie的区别)

)


——Tcp客户端判断与服务器断开连接的三种方法以及C#代码实现)


 #学习方法#其他)

(内含完整源码))