PostGIS学习教程二十一:最近领域搜索
注意:本节涉及的功能只在PostGIS2.0及更高的版本可用。
文章目录
- PostGIS学习教程二十一:最近领域搜索
- 一、什么是最近邻域搜索?
- 二、基于索引的KNN
一、什么是最近邻域搜索?
一个常见的空间查询是:“距离一个要素最近的是哪些要素?”
与距离查询不同,最近邻域搜索(Nearest Neighbour Search)没有限制候选几何图形在什么范围之内,任何距离的要素都将被接受,只要它们是最近的。这引出了关于传统的索引辅助查询的一个问题,这些查询需要一个搜索框,因此需要某种测量值来限定这个框。
执行最近邻域搜索的简单方法是按与要查询的几何图形的距离对候选表进行排序,然后获取最小距离对应的表记录。
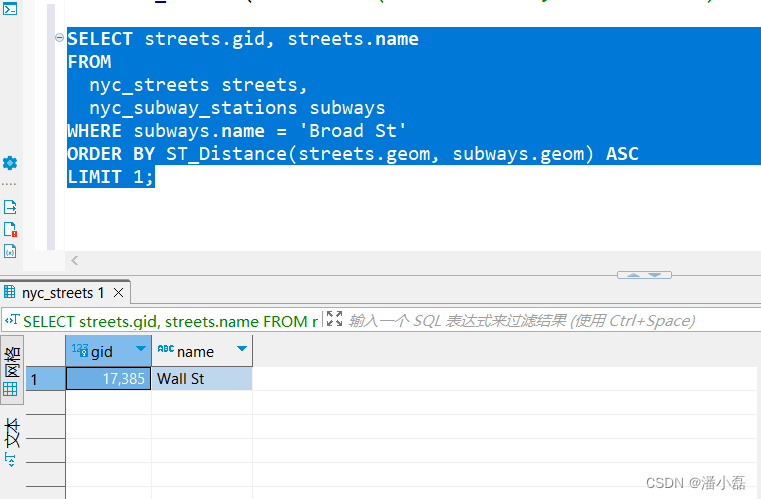
SELECT streets.gid, streets.name
FROMnyc_streets streets,nyc_subway_stations subways
WHERE subways.name = 'Broad St'
ORDER BY ST_Distance(streets.geom, subways.geom) ASC
LIMIT 1;
这种方法的问题是,它强制数据库计算查询几何图形和候选要素表中每个要素之间的距离,然后对它们进行排序。对于一个庞大的候选要素表,这不是一个合理的方法。
提高性能的一种方法是向搜索添加空间索引约束。这需要一个神奇的数字:我们可以在查询几何图形周围搜索的最小方框是什么?并且仍然可以找到至少一个候选几何图形?
如果启用计时,可以看到下面的方框辅助查询和上面的简单查询之间的性能差异。
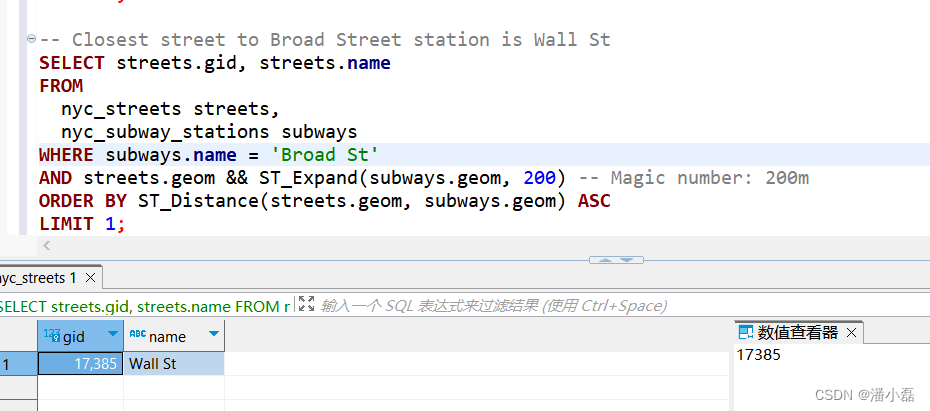
-- Closest street to Broad Street station is Wall St
SELECT streets.gid, streets.name
FROMnyc_streets streets,nyc_subway_stations subways
WHERE subways.name = 'Broad St'
AND streets.geom && ST_Expand(subways.geom, 200) -- Magic number: 200m
ORDER BY ST_Distance(streets.geom, subways.geom) ASC
LIMIT 1;
这种方法的问题在于200米这个神奇的数字,如果在200米内没有道路呢?我们可能不会得出结果:因为虽然总会有一个近邻要素,但它可能不在200米之内。
二、基于索引的KNN
“KNN"代表"K nearest neighbours(K近邻)”,其中"K"是要寻找的结果的数量。
KNN是一种基于纯空间索引的近邻搜索方法。通过在索引中上下移动,搜索可以在不指定任何半径的情况下找到最近的候选几何图形,因此该技术适用于具有高度变量数据密度的大表,并且具有很高的性能。
注意:KNN功能仅在PostgreSQL 9.1和PostGIS 2.0或更高版本上可用。
KNN系统的工作原理是评估PostGIS的R-Tree索引中几何图形边界框之间的距离。
由于索引是使用几何图形的边界框构建的,因此任何不是点的几何图形之间的距离都将不精确:它们将是几何图形边界框之间的距离,而不是几何图形之间的距离。
基于索引的KNN查询的语法在查询的ORDER BY子句中放置了一个特殊的"基于索引的距离运算符",在本例中使用了"<->"运算符。有两种基于索引的距离运算符:
<-> —— 表示边界框中心之间的距离
<#> —— 表示边界框边界之间的距离
基于索引的距离运算符的一侧必须是字面几何值。可以使用返回为单个几何图形的子查询代替,也可以使用一个WKT几何图形代替。
-- Closest 10 streets to Broad Street station are ?
SELECTstreets.gid,streets.name
FROMnyc_streets streets
ORDER BYstreets.geom <->(SELECT geom FROM nyc_subway_stations WHERE name = 'Broad St')
LIMIT 10;-- Same query using a geometry EWKT literalSELECT ST_AsEWKT(geom)
FROM nyc_subway_stations
WHERE name = 'Broad St';
-- SRID=26918;POINT(583571 4506714)SELECTstreets.gid,streets.name,ST_Distance(streets.geom,'SRID=26918;POINT(583571.905921312 4506714.34119218)'::geometry) AS distance
FROMnyc_streets streets
ORDER BYstreets.geom <->'SRID=26918;POINT(583571.905921312 4506714.34119218)'::geometry
LIMIT 10;
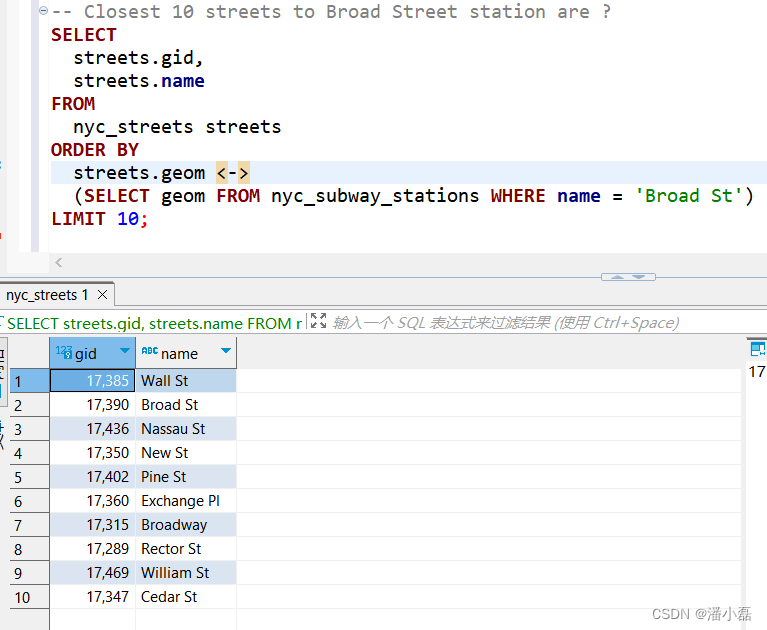
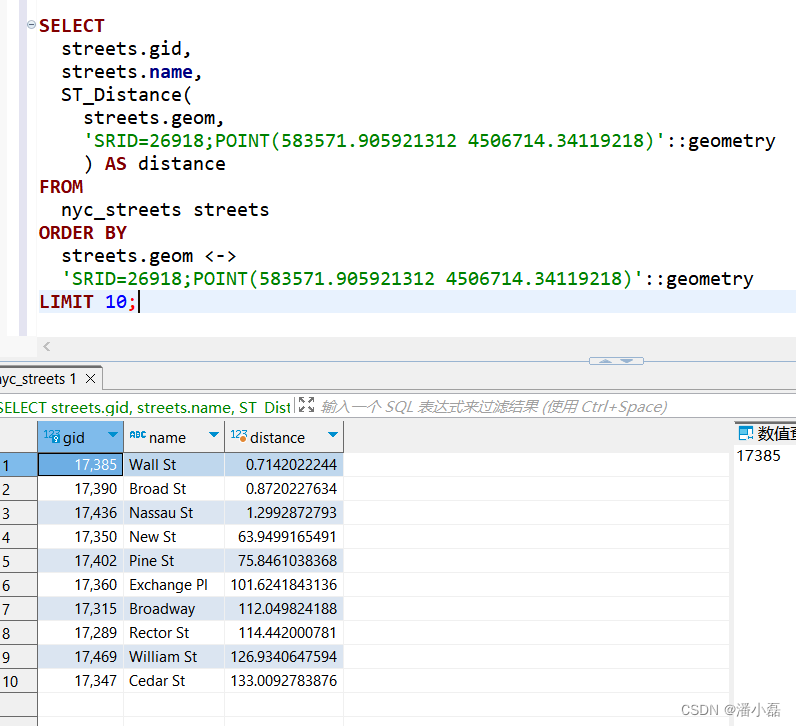
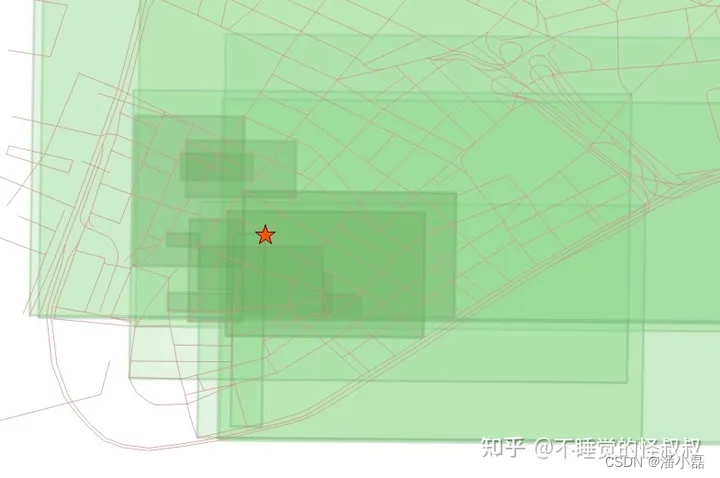
第二个查询的结果显示了对非点几何图形的基于空间索引的查询看上去有多奇怪。Wall St(华尔街)在我们的结果集中仅排名第三,尽管从Broad St车站到Wall St的绝对距离仅仅只有0.714米!
请记住,所有计算都是在边界框上完成的。地铁站点的边界框就是该点本身,因此是准确的。但是街道的边界框和街道线串几何图形本身是不一样的,最近的前十条街道的边界框是这样的:
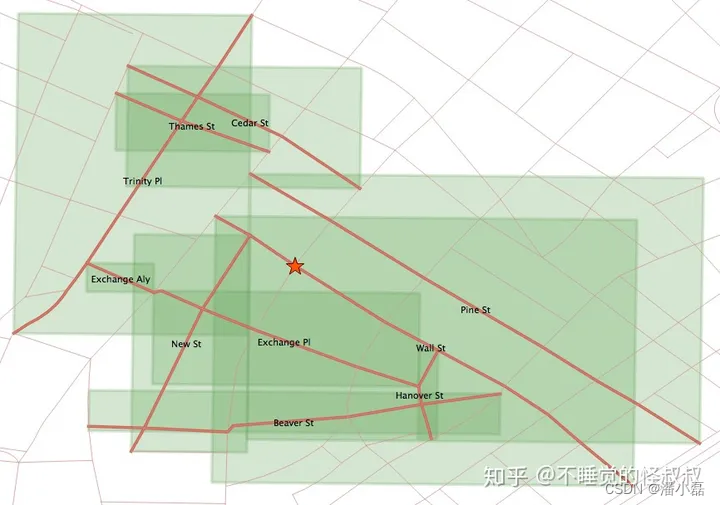
我们可以看到车站正好落在华尔街的线串上,并且在华尔街的边界框中。但是这个索引顺序是由"<->"操作符控制的,它计算边界框中心之间的距离。边界框中心如下:
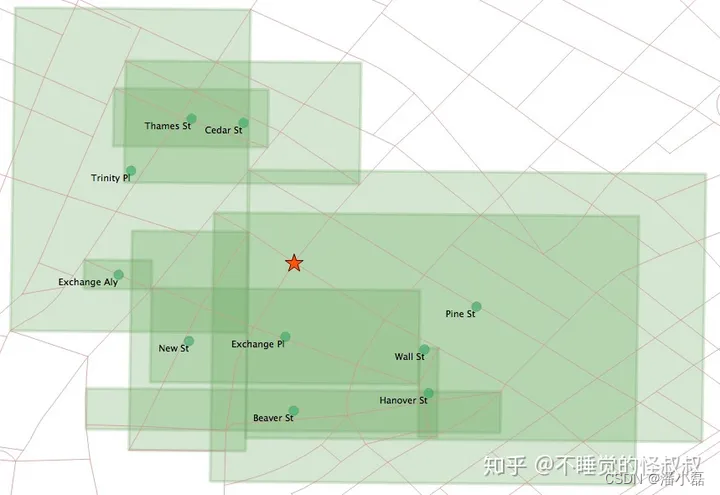
现在很清楚为什么华尔街没有作为我们搜索结果的第一个记录出现了。因为华尔街边界框的中心确实比Exchange Place(交易所)的边界框的中心离Broad St车站更远。
那么"<#>"运算符呢?如果我们计算边界框边界之间的距离,车站就会落在华尔街边界框内,车站与华尔街的边界框之间的距离为0,所以它作为返回结果的第一个条目返回对吗?
-- Closest 10 streets to Broad Street station are ?
SELECTstreets.gid,streets.name
FROMnyc_streets streets
ORDER BYstreets.geom <#>'SRID=26918;POINT(583571.905921312 4506714.34119218)'::geometry
LIMIT 10;
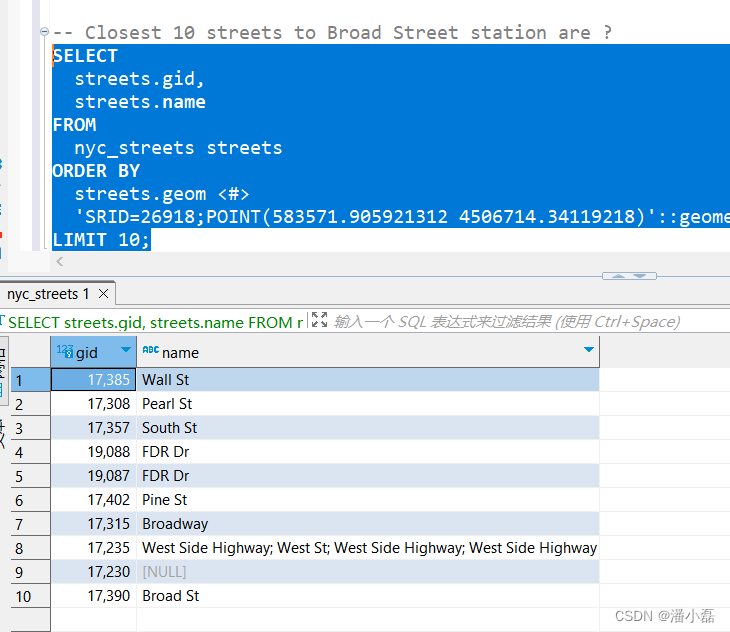
很遗憾,并不是。
有许多带有大的边界框的要素,这些边界框也与车站重叠,所以车站与它们的边界框的距离也为0。。。那到底该怎么搞?
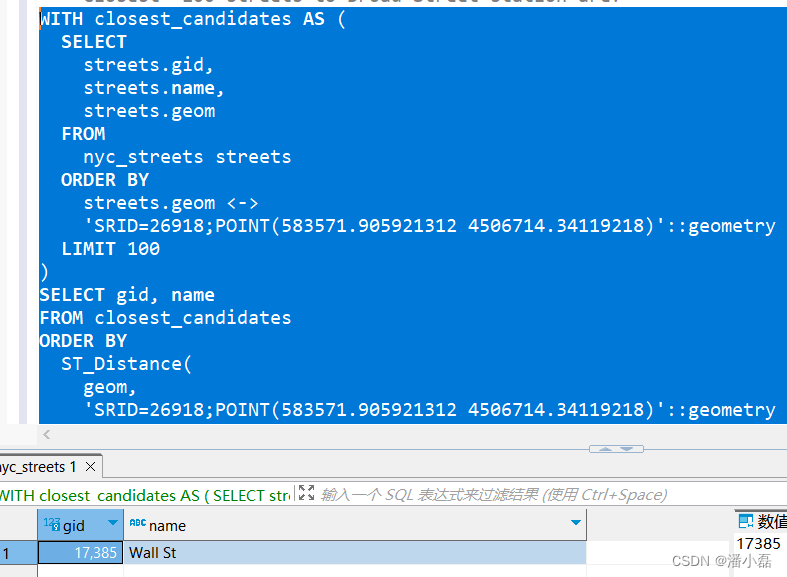
要获得高性能但精确的近邻计算,正确的方法是使用一个子查询提取前100个可能的结果(或者,如果你认为你的数据在分布上更均匀,则可以选择一个较小的数字),然后再计算所有这些结果与车站(Broad St)的真实距离,并从该结果集合返回最近的记录。
-- "Closest" 100 streets to Broad Street station are?
WITH closest_candidates AS (SELECTstreets.gid,streets.name,streets.geomFROMnyc_streets streetsORDER BYstreets.geom <->'SRID=26918;POINT(583571.905921312 4506714.34119218)'::geometryLIMIT 100
)
SELECT gid, name
FROM closest_candidates
ORDER BYST_Distance(geom,'SRID=26918;POINT(583571.905921312 4506714.34119218)'::geometry)
LIMIT 1;
请注意,在查询点表时,由于边界框与点完全相同,因此可以直接使用按空间索引排序的结果,而不必使用子查询。
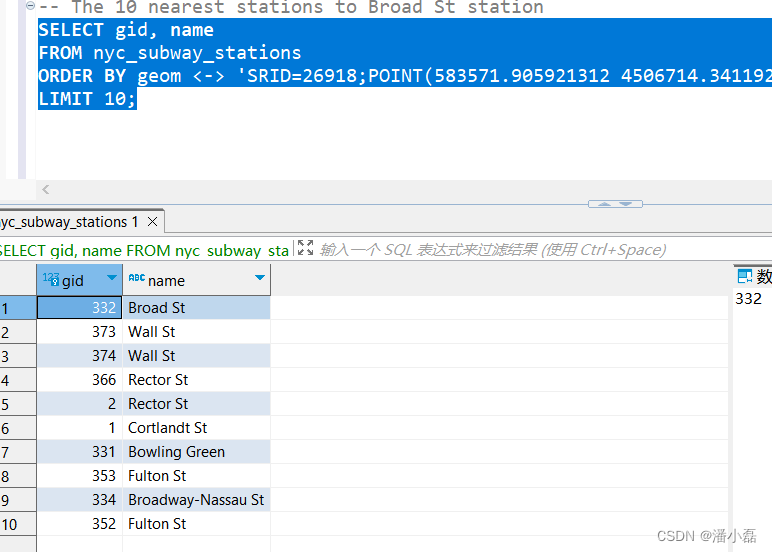
– The 10 nearest stations to Broad St station
SELECT gid, name
FROM nyc_subway_stations
ORDER BY geom <-> ‘SRID=26918;POINT(583571.905921312 4506714.34119218)’::geometry
LIMIT 10;