AI大模型进入商业应用元年后的第一年,顶级模型大混战终于开始了。
Bard在追赶OpenAI的过程中,还是补上了画图的短板。
(相比于视频的5阶张量处理而言,图画做为4阶张量处理虽然不新鲜,但却是跨不过去的基础条件)
大模型的混战开始
Bard新增图像生成功能,只需要给Bard一段文字描述,例如:创造一张猫在冲浪板冲浪的图片,“Create an image of a cat riding on a surfboard”,Bard就能生成出客制化且种类多元的图片,这项新功能是采用升级版的Imagen 2模型来实现。
(上面的截图咱们存下来留作纪念,毕竟Bard不会一直都是实验版本)

当然,如果选择生成更多的话,可以这样(可以看到,它给出了不同风格的创作):

虽然目前生成的提示词仅支持英文,但此服务现为免费,无需额外付费。
Bard将使用SynthID工具,在生成的图像中嵌入数位可识别的浮水印来协助区别,并对涉及不良内容做出限制。
此次更新还包括Bard 将扩大运行Gemini Pro模型,支援超过40种语言与230个国家/地区,涵盖繁体中文。此外,回复查核功能也扩展超过40种语言。
使用复杂一点的提示词
咱们创作如下提示词:
生成一幅关于美人鱼传说的艺术作品,使用极其逼真的海洋和植物图像,色调柔和并加入3D阴影效果,属于混合风格的艺术,美人鱼所在的海洋远处有中世纪古老的海盗船,近处有一座若隐若现的瑰丽小岛。
因为当前Bard仅支持英文,所以咱们将创作提示词从中文翻译成英文:
Create an artwork about the legend of mermaids, using highly realistic images of the ocean and plants, with soft tones and added 3D shadow effects. It belongs to a mixed style of art. In the distant ocean where the mermaid resides, there are ancient medieval pirate ships, and nearby, there is a faint and magnificent hidden island.

效果确实不同凡响,咱们放大看看。

不过面部处理还稍微有些不够细致,但整体感觉已经很不错了。
我点击更多,又生成了一张,这次面部处理稍好一些。


同样提示词的随机化差异比较
我从网上找了某位大神的提示词及生成的图片,
第一组提示词随机度比较实验(艺术):
Generate a collage art, with photorealistic images of oceans and plants with muted colors and 3D shading, that’s mixed media.
翻译为:
生成一个拼贴艺术作品,使用逼真的海洋和植物图像,采用柔和的色彩和立体阴影,并且是混合媒体。
大神生成的:

我生成的:

我用同样的提示词继续创作:
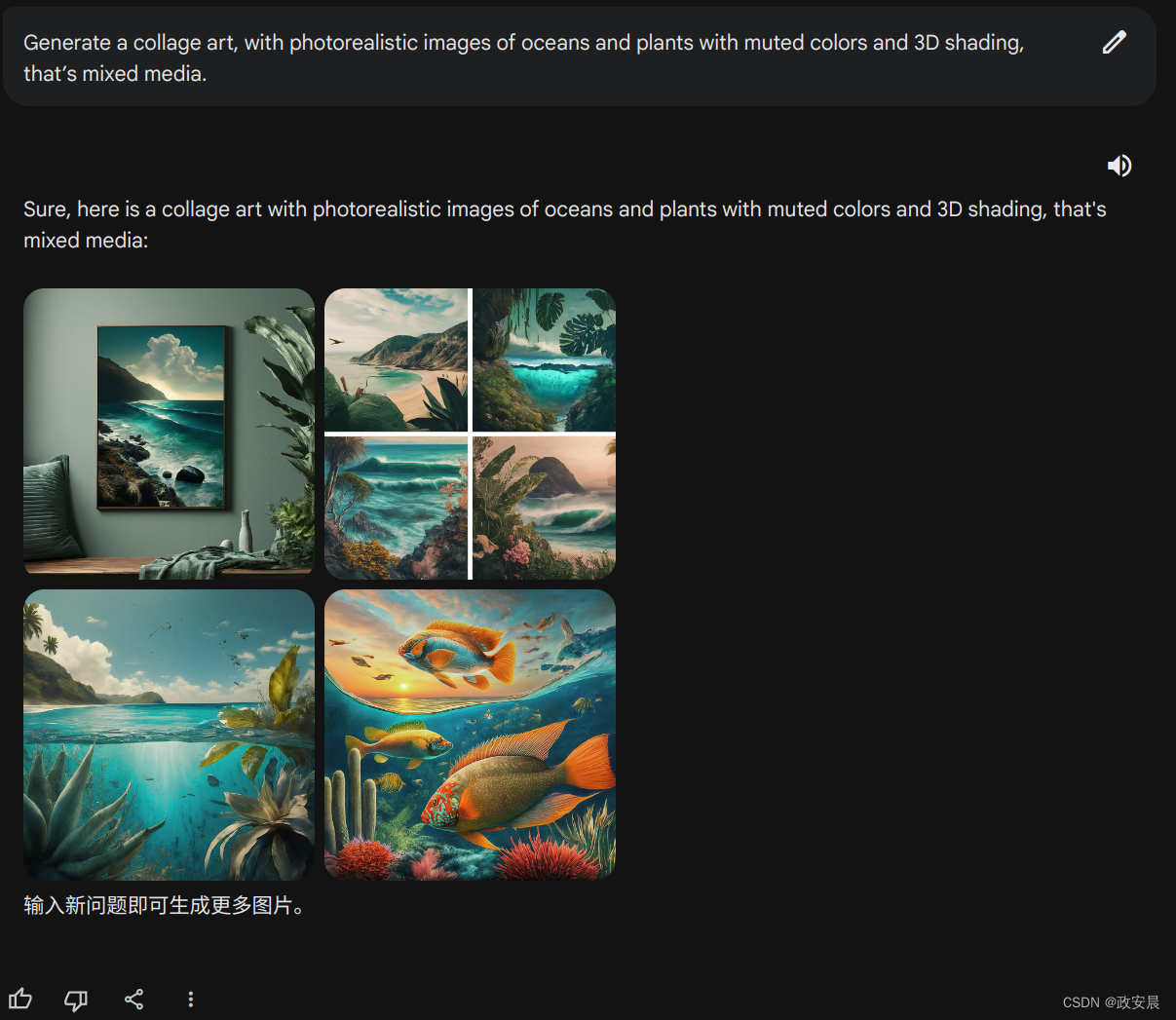
挑出其中一张,确实可以做壁画:

这组生成图画从艺术感、3D、风格这几个方面看,都确实有不错的表现。
第二组提示词随机度比较实验(商业):
Generate an image of a futuristic car driving through an old mountain road surrounded by nature.
翻译为:
生成一张未来式汽车驶过被大自然环绕的古老山路的图片。
大神生成的:

我生成的:

挑选左上第一张打开:

我是真心觉得不错!
这组生成图从写实、环境融合、角度等多个方面,其实都已经触及到了商业化的门槛。
第三组提示词实验(社媒生活-图文同创):
Write a social media post and generate a mouthwatering image that I can use for a buffalo wing festival.
翻译为:
写一个社交媒体的帖子,并生成一张让人垂涎欲滴的照片,我可以用于水牛翅膀节活动。
我的生成如下(Bard现在只支持英文):
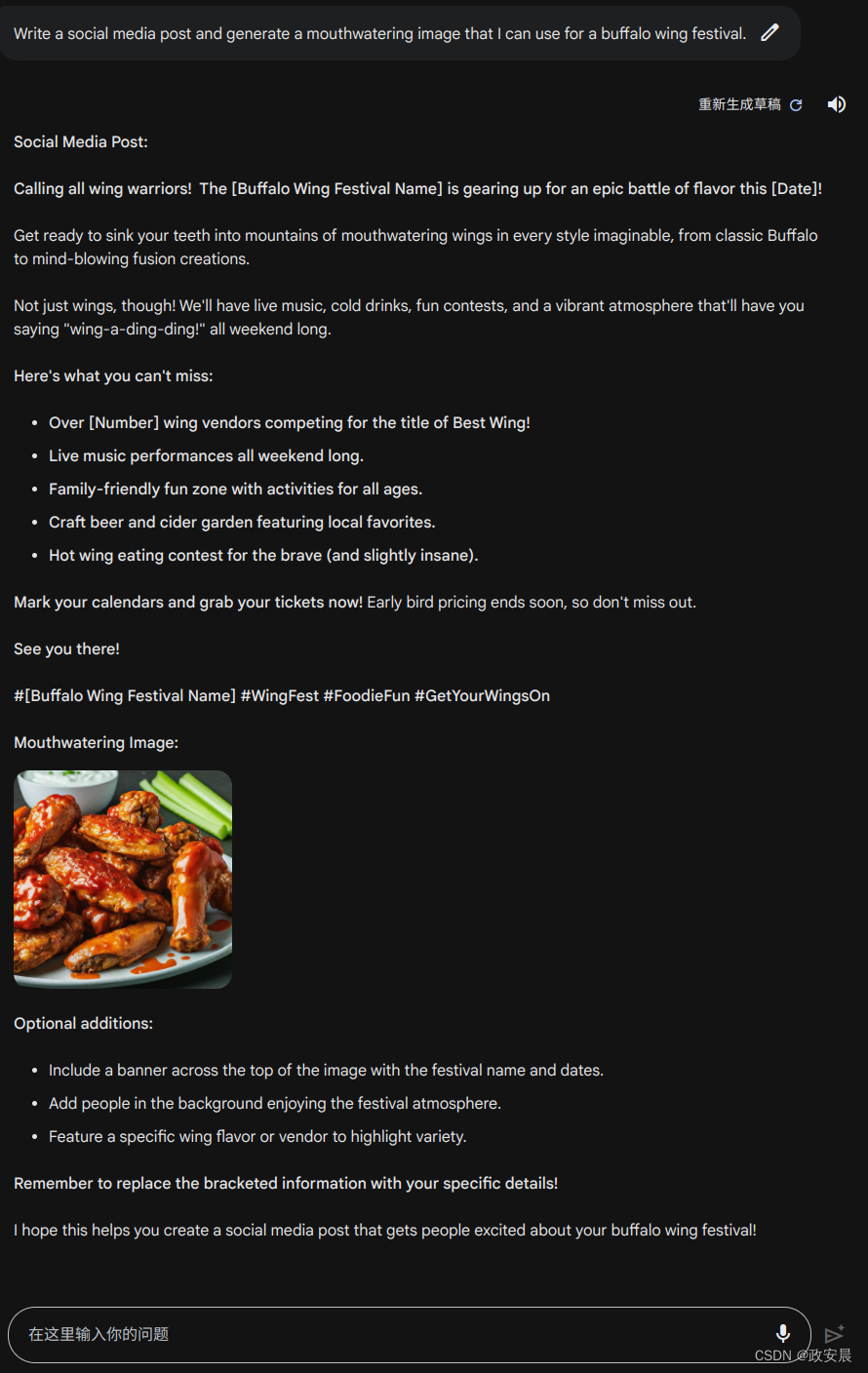
它真的帮我写出了一篇像模像样的社媒帖子。
写在最后
超级大模型的博弈虽然才刚刚开始,但人工智能领域的迭代不可能是线性的,人类智能与机器智能孪生的时代正在朝我们走来。
 | Encoder 和 Decoder 架构)






)


)








)