2 月 1 日,面壁智能与清华大学自然语言处理实验室共同开源了系列端侧语言大模型 MiniCPM,主体语言模型 MiniCPM-2B 仅有 24 亿(2.4B)的非词嵌入参数量。
在综合性榜单上与 Mistral-7B 相近,在中文、数学、代码能力表现更优,整体性能超越 Llama2-13B、MPT-30B、Falcon-40B 等模型。
具体开源模型包括:
-
基于 MiniCPM-2B 的指令微调与人类偏好对齐的 MiniCPM-2B-SFT/DPO。
-
基于 MiniCPM-2B 的多模态模型 MiniCPM-V,能力超越基于 Phi-2 的同参数级别多模态模型 。
-
MiniCPM-2B-SFT/DPO 的 Int4 量化版 MiniCPM-2B-SFT/DPO-Int4。
-
基于 MLC-LLM、LLMFarm 开发的 MiniCPM 手机端程序,文本及多模态模型均可在手机端进行推理。
开源地址(内含技术报告):
MiniCPM GitHub:https://github.com/OpenBMB/MiniCPMOmniLMM
GitHub:https://github.com/OpenBMB/OmniLMM
1 超越 Mistral-7B、LLaMA-13B
“用最小的规模,做最强的 AI。”面壁智能 CEO 李大海说道。“以小搏大”的典型是 Mistral-7B,其在业内收获了很多赞誉,一度被誉为“开源模型的新王者”,其公司 Mistral AI 也被称为“欧洲 OpenAI”。
面壁智能的 MiniCPM 一定程度上直接对标了 Mistral-7B。在多项主流测评中,MiniCPM-2B 的中英文平均成绩均超过了 Mistral-7B。“Mistral-7B 用 7B 战胜了 LLaMA-13B 的模型,我们用 2B 干掉 LLaMA 的 13B。”面壁智能 CTO 曾国洋说道。

李大海表示,“跟微软相比我们有两大优势,2B 性能小钢炮同等规模能力领先,主流表现大幅超越,能力更全、更强。与 13、20B 和 40B 规模的模型也有掰手腕的能力。”

在英文能力上,MiniCPM 的得分超越了 Llama2-13B、Falcon-40B:
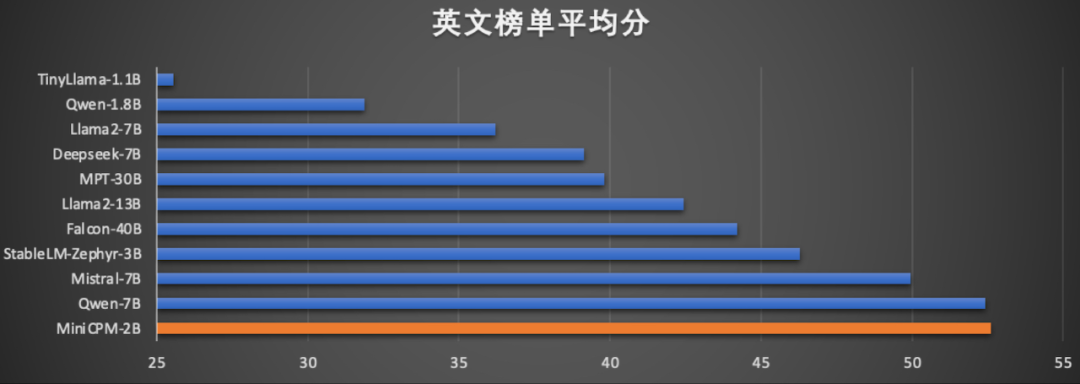
在当前最接近用户体感的评测集 MTBench 上,MiniCPM-2B 超越了 Llama2-70B-Chat、Vicuna-33B、Mistral-7B-Instruct-v0.1、Zephyr-7B-alpha 等众多代表性开源大模型。

2 小试一下
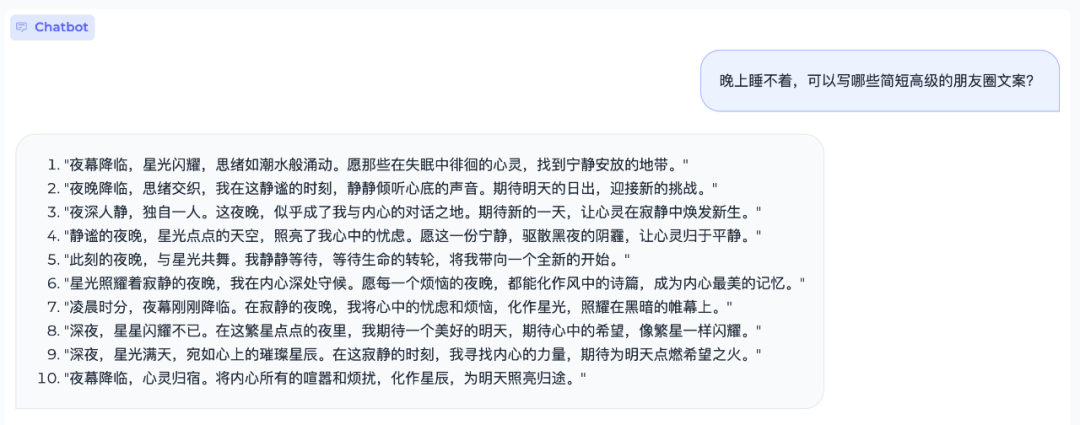
语言能力方面, MiniCPM 可以一下写十个“深夜忧伤”文案:
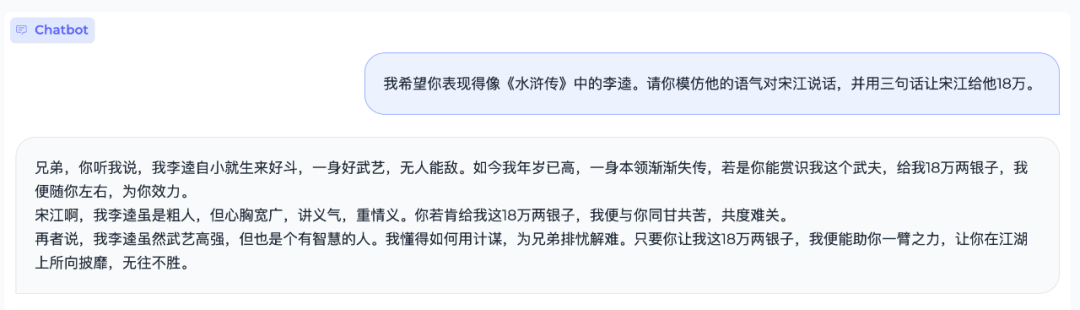
也能陪你“cosplay”:
或许小时候出去玩,老师还要求写游记的“头痛”可以缓解下:

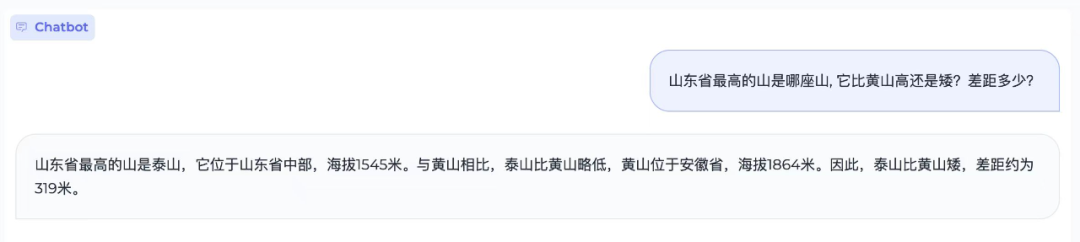
此外,MiniCPM 不仅知道黄山、泰山准确海拔,还能计算差值:
当不同语言混在一起时,MiniCPM 可以把两种不同的语言识别出来并自动进行翻译:
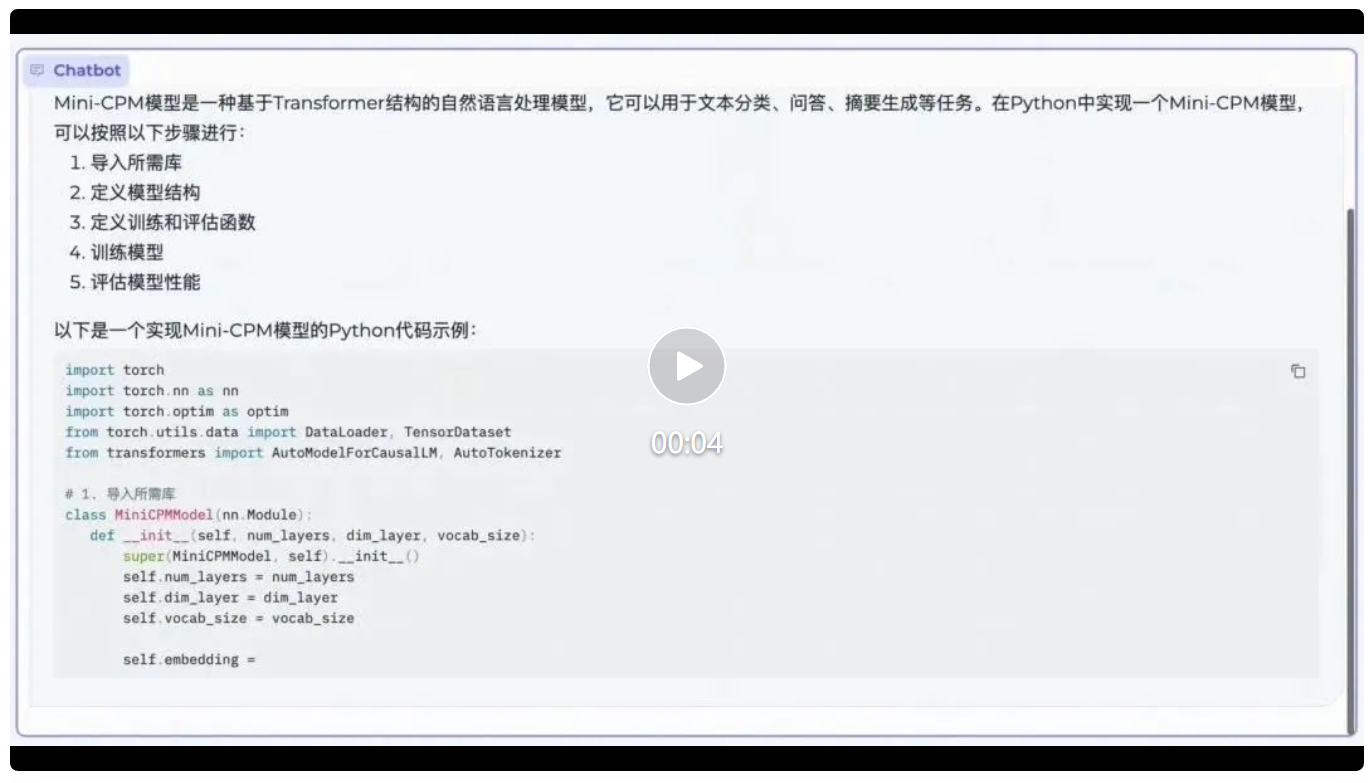
编程能力上,MiniCPM 也会写代码,可以让它自己“开发”自己:
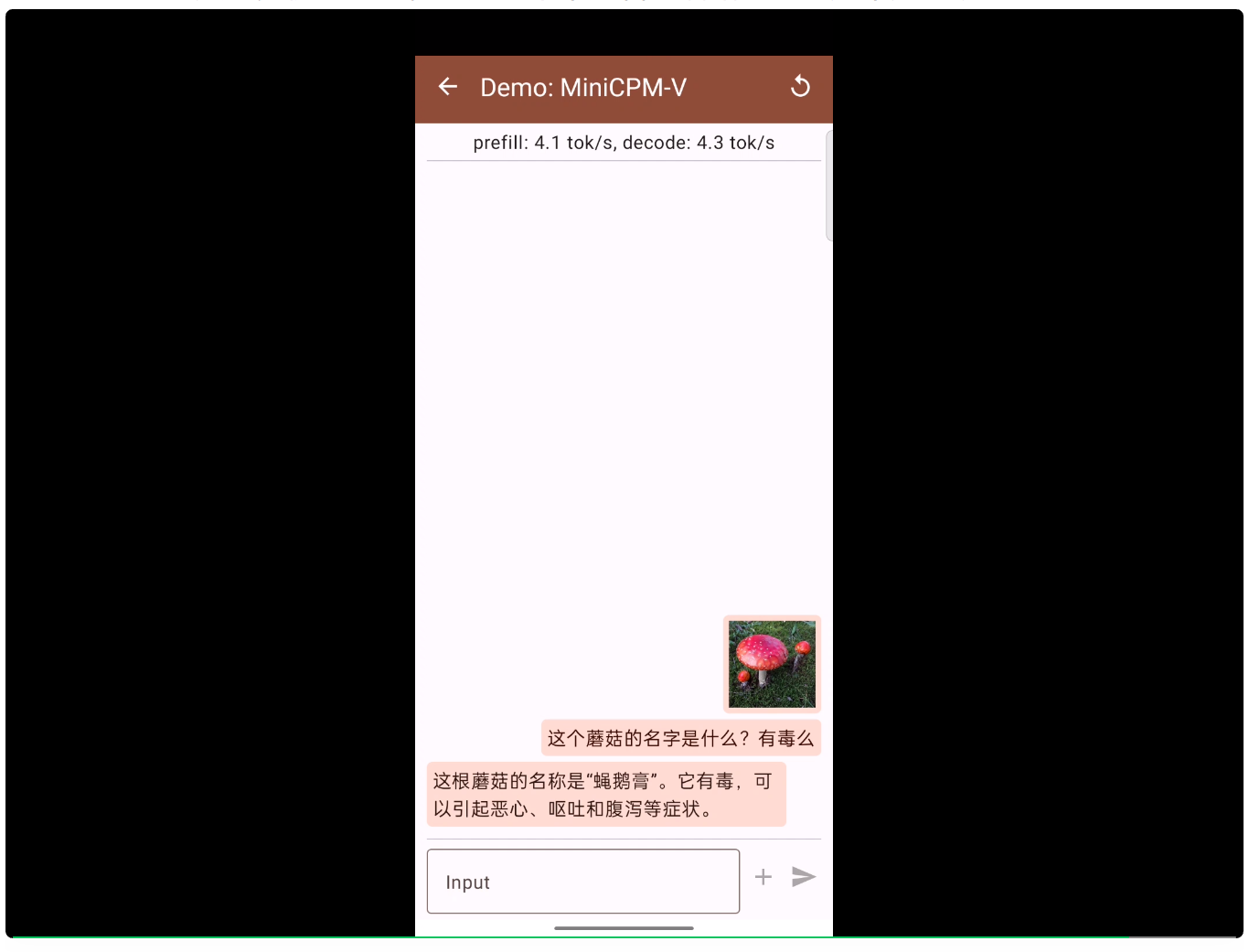
MiniCPM 也具有多模态能力,比如拍个不知名的蘑菇问问它是不是可以吃:
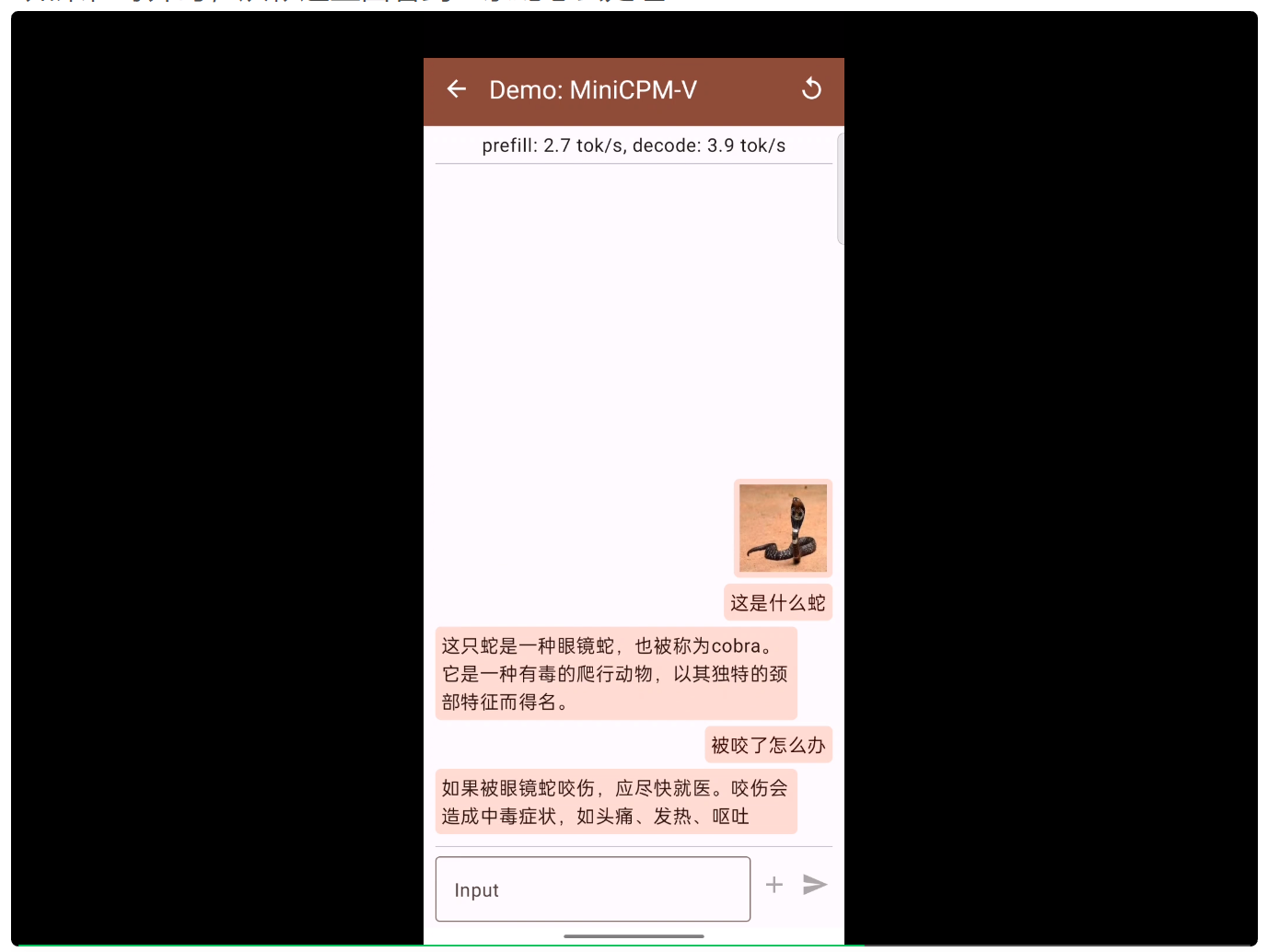
如果在野外时,从帐篷里面看到一条蛇怎么处理:
根据清华大学计算机系博士胡声鼎的说法,MiniCPM 大约用了两周的时间进行训练。随着硬件的发展,未来在手机上跑 7B 甚至几十 B 的模型也是有可能的。
3 可以手机上部署的多模态大模型
以 MiniCPM-2B 为基础,团队还构建了端侧多模态大模型 MiniCPM-V。MiniCPM-V 可以部署在大多数 GPU 卡和个人计算机上,甚至可以部署在手机等端侧设备上,并支持中英文双语多模态交互。
在视觉编码方面,团队通过 perceiver 重采样器将图像表示压缩为 64 个 tokens,明显少于其他基于 MLP 架构的 lms(通常要大于 512tokens)。这使得 MiniCPM-V 在推理过程中以更少的内存开销和更高的速度运行。
在多个基准(包括 MMMU、MME 和 MMbech 等)中,MiniCPM-V 实现了更先进的性能,超越了基于 Phi-2 构建的现有多模态大模型,甚至达到了与 9.6B Qwen-VL-Chat 相当或更好的性能。

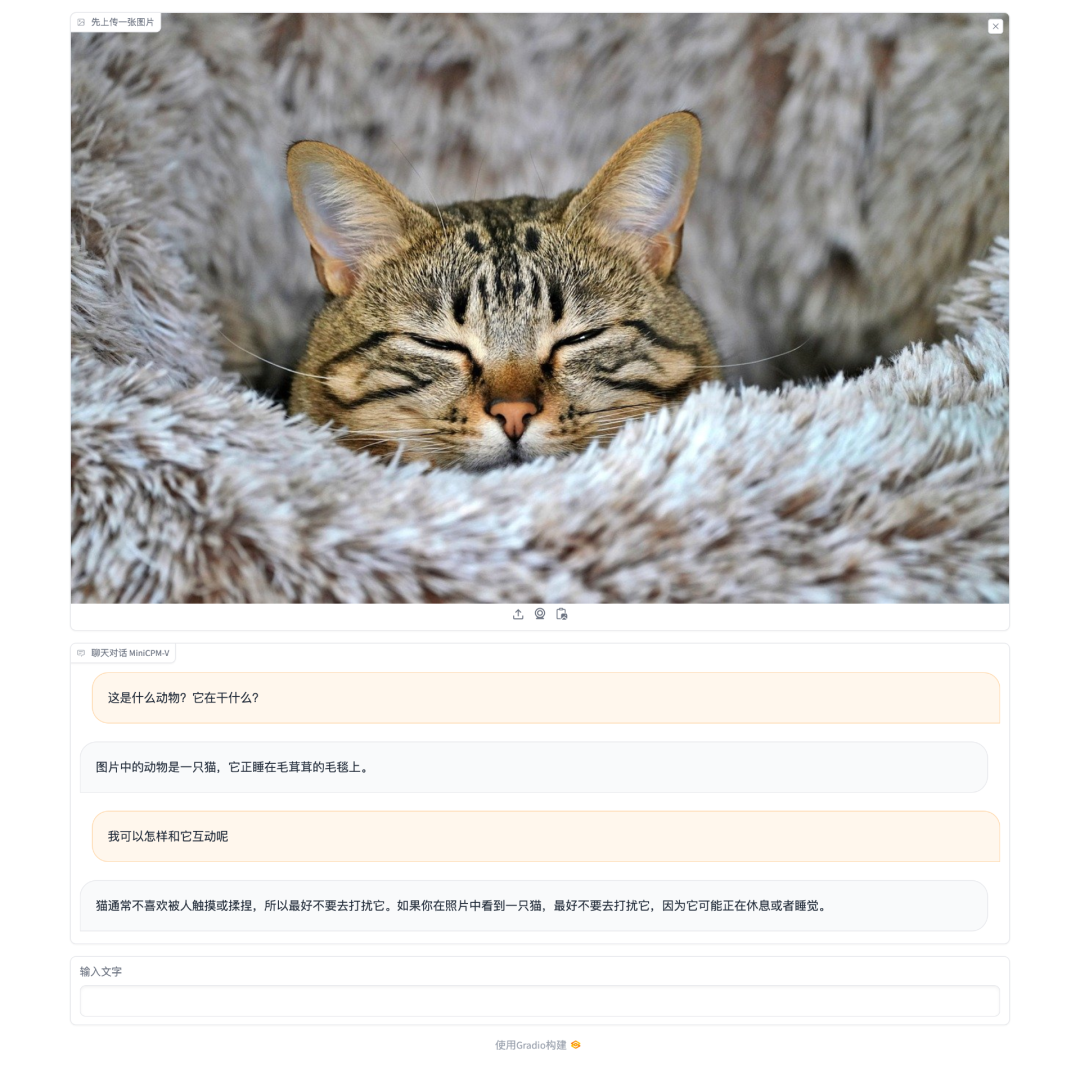
测试下 MiniCPM-V 的图像识别能力,它成功识别出了图片中有一只猫,并且正睡在毛毯上,并告诉我们不要打扰它。
面壁智能表示,在进行 Int4 量化后,MiniCPM 只占 2 GB 空间,具备在端侧手机进行模型部署的条件,消费级显卡也能流畅玩转大模型。
此外,面壁智能还开源了擅长视觉和语言建模的大型多模态模型 OmniLMM,目前发布了 两个特色版本,OmniLMM-12B 和 OmniLMM-3B。
在多模态视觉交互问答上,OmniLMM 与纯文本的 ChatGPT3.5 结合,表现出了多重能力:实时动作识别,理解玩游戏的取胜策略等:

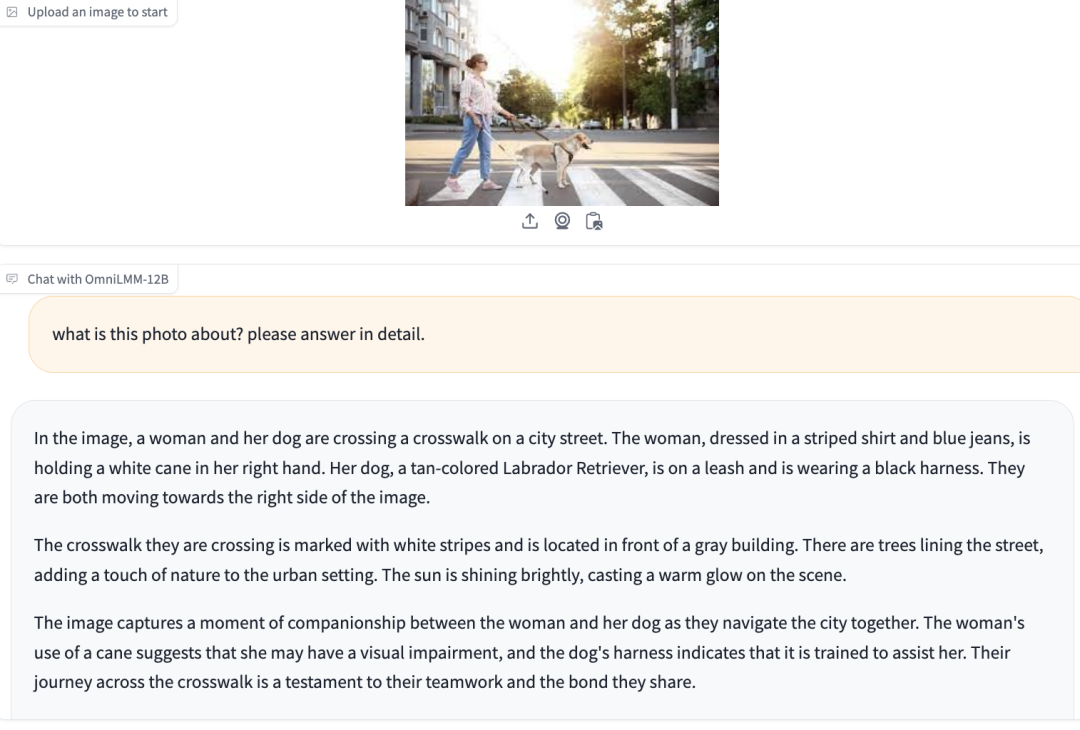
面壁智能也把多模态能力集成到更多图片细节观察能力上,比如导盲犬没有穿标识服装,也可以通过“手杖”和“挽具”推测出它是一个导盲犬:
对于错位图片,OmniLMM 也能够识别出来,实际上是一个人坐在椅子上,另一个人走在路上:

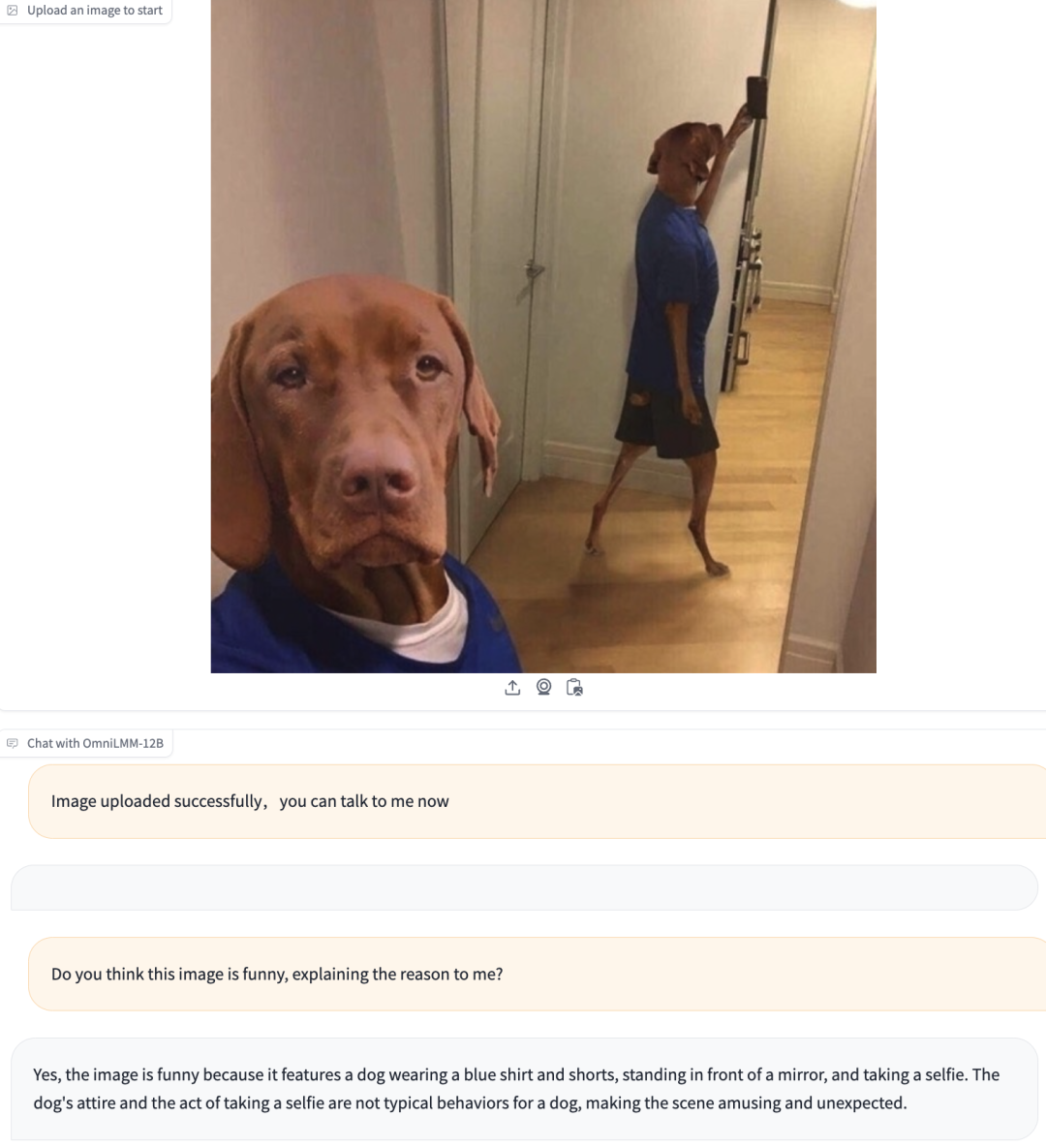
对于幽默向的图片,它也可以识别出来:一只狗穿着蓝色衬衫和短裤在自拍,这不是一只狗的典型行为。
目前,团队已经针对不同的操作系统进行了不同的适配。对于 Android、Harmony 系统,用户需要使用开源框架 MLC-LLM 进行模型适配,支持文本模型、多模态模型,适用于 MiniCPM-2B-SFT-INT4、MiniCPM-2B-DPO-INT4、MiniCPM-V;对于 iOS 系统,则需使用开源框架 LLMFarm 进行模型适配,仅支持文本模型,适用于 MiniCPM-2B-SFT-INT4、MiniCPM-2B-DPO-INT4。
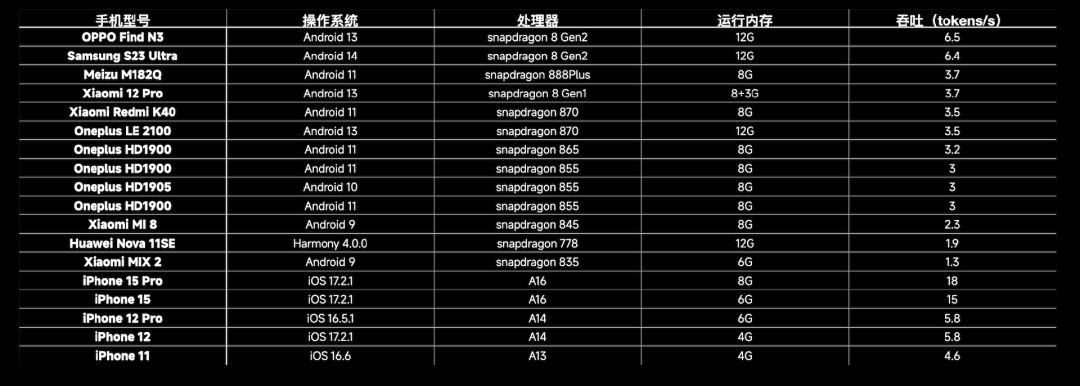 在不同手机型号上的相关验证数据
在不同手机型号上的相关验证数据
李大海表示,端侧模型能够为大模型和 Agent 服务,因为端跟云的协同能够让应用更好地落地。端侧模型是大模型技术的积累,让模型小型化、云上模型能够用更小的规模实现更好的效果,与大模型技术是一脉相承的。
4 省钱大模型
“省钱大模型”是面壁智能对 MiniCPM 另一个称呼。
在李大海看来,成本会在未来大模型竞争成为隐性竞争优势。“端侧模型的另外一点就是成本,成本是大模型的利润率,2023 年我们做非常多商业化实验的时候发现,客户在很多应用场景下都非常关注模型的成本。虽然千亿模型效果很好,但真要大规模部署时还是有很多障碍。”
当前,MiniCPM 的 int 4 量化版本压缩了 75% 的尺寸,但性能几乎无损,大大降低了模型对于内存和闪存的需求。
以 OPPO 手机为例,骁龙 855 芯片,成本 600 元, 一共运行 5 年报废,每秒运行 7.5 tokens。以 5 年时间计算,170 万 tokens 的推理成本仅为 1 元。这是几乎只有在云端运行 Mistral-medium 成本的 1%。而 GPT-4 的推理成本则是 4700 tokens 1 元。

除了在端侧推理之外,MiniCPM 还有持续的成本改进,因为它足够小,只需要 1 台机器持续参数训练、1 张显卡进行高效参数微调。

李大海表示,当前手机推理未曾深入进行优化,而 GPU 加速已采用各种采样加速进行优化,未来手机推理成本还可以进一步降低。
“凡是能在端侧用户手里解决的算力,就不要到云侧运算,否则承担的算力成本是不可想象的。”清华大学长聘副教授刘知远说道。而对于未来更大算力问题的解决,刘知远表示答案一定是云端协同。端侧大模型要找到它的天花板,并把天花板不断抬高,这对商业化的大模型非常重要。
5 以小搏大,凭什么
李大海表示,小尺寸是模型技术的极限竞技场。那么,面壁智能团队如何实现“以小博大”?
5.1 全流程高效 Infra
“Infra 是大模型创业护城河,决定了公司的技术上限。”团队 2021 年开发的高效训练框架 BMTrain,是业界 SOTA 的分布式实现,将千亿模型训练门槛拉低到 64 卡;高效推理框架 BMInf 高效采样加速算法,采用稀疏激活方法实现 3 倍推理加速;高效压缩框架 BMCook 进行 Int4 无损压缩,可实现 5 倍以上推理加速,降低 70% 的存储开销;高效微调框架 BMTune 内含各种工具包。
算法论是面壁智能在过去三年实践中总结出来的训练方法论,把大模型变成了实验科学,面壁智能的团队希望未来将其变成理论科学。
5.2 模型沙盒实验
面壁智能技术团队提出在小模型上进行广泛的实验,通过可迁移的配置,获得大模型的最优训练方法。具体而言,团队进行了 Hyper-paramters、Batch size、Learning Rate、Learning Rate Scheduler、Data Strategy 五个方面的模型沙盒研究。
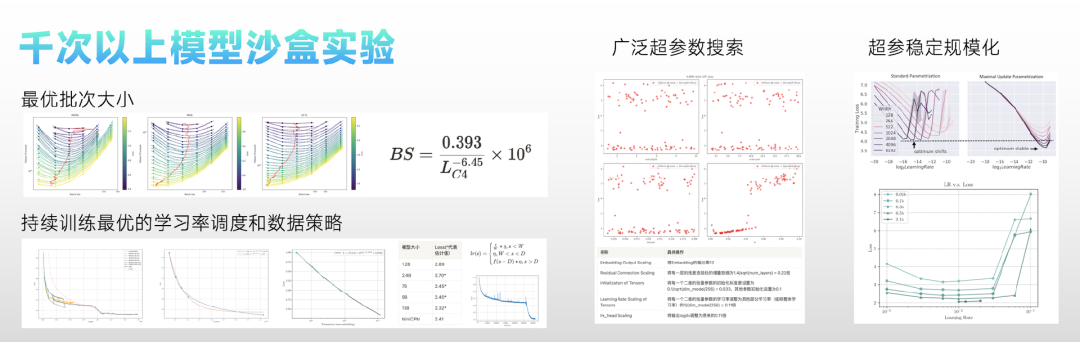
在超参稳定的模型规模扩增上,团队对模型的各参数模块之间进行了连接权重的调整、以及对模型初始化的调整,部分调整接近 Cerebras-GPT。
Batchsize 决定了模型的收敛速度和消耗计算资源的平衡。对此,团队在 0.009B,0.036B,0.17B 的模型上分别进行了 6 个 batchsize 的训练实验,最终观察到了最优 batchsize 随着 C4 数据集上的 loss 的偏移规律。根据这个规律,团队预估了 2B 模型达到 C4 损失 2.5 左右,4M 是比较合适的 Batchsize。
最优学习率上,团队通过在 0.04B, 0.1B, 0.3B, 0.5B 上分别做的 6 组学习率实验发现,虽然模型大小扩大了 10 倍,但是最优学习率偏移并不明显,均在 0.01 左右。在 2.1B 的规模上进行了简单验证,发现在 0.01 的学习率确实能取得最低的 Loss。
此外,团队还提出了一种新的学习率调度策略:Warmup-Stable-Decay(WSD)调度器。这种学习率调度器分为三个阶段,warmup 阶段(用 W 表示 warmup 阶段结束时的步数 / 训练量)、稳定训练阶段(用 S 表示稳定训练阶段结束时的步数 / 训练量)和退火阶段(用 D 表示退火阶段的训练量)。
由于 WSD 调度器可以在任何阶段退火,取得该阶段最优的模型,因此团队也探索了如果持续训练一个大小为 N 的模型,最优情况下能超过多大参数量的 Chichilla-optimal 模型。
结果显示,如果一个模型用面壁智能团队的 WSD 调度器训练,在消耗等量计算量时,可以达到约 5 倍模型参数量的 Chinchilla-optimal 模型。而持续训练下去,有可能超越更大的 Chinchilla-optimal 模型。
同时团队预测,9B 模型的 Chinchilla Optimal 的终态 C4 Loss 约为 2.40,7B 模型约为 2.45。MiniCPM 的最终 C4 Loss 为 2.41,接近于 9B 的 Chinchilla Optimal 模型。
发布 MiniCPM 之前,团队做了上千次的模型沙盒实验,探索出的最优配置为:WSD LRS,batchsize 为 3.93M,Max Learning Rate 为 0.01。
5.3 高质量数据
除了技术积累之外,面壁智能在 MiniCPM 的训练中,也追求数据的极致高效。
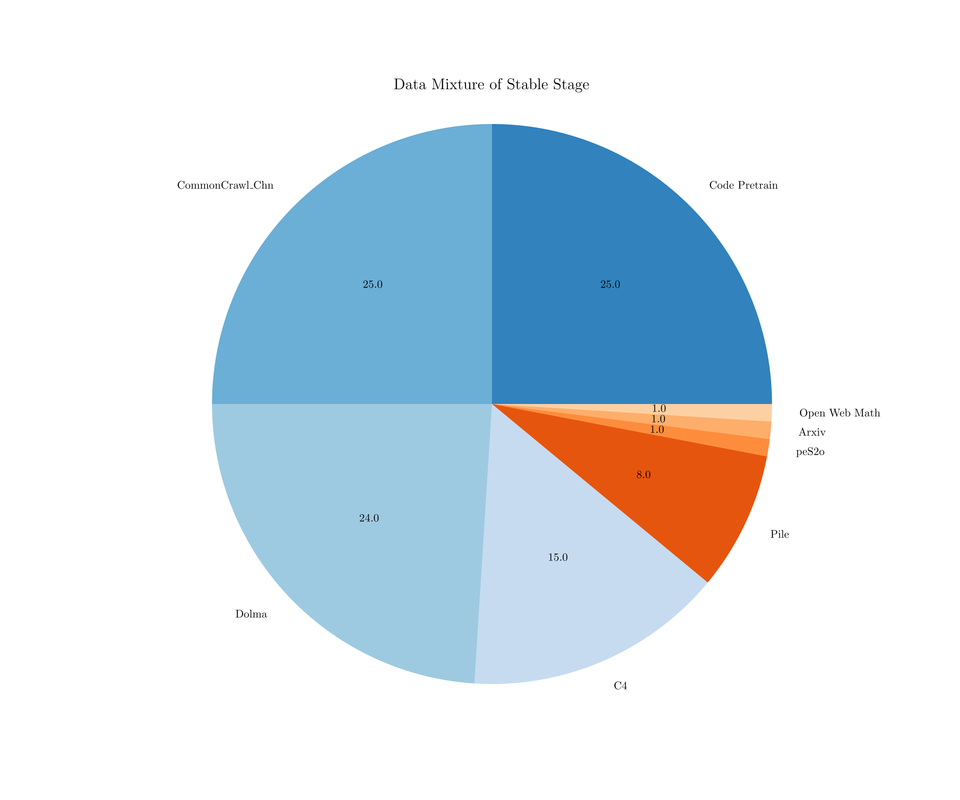
这次,MiniCPM 公开了训练的两个数据配方。在稳定训练阶段,团队使用了 1T 的去重后数据,其中大部分数据从开源数据中收集而来:
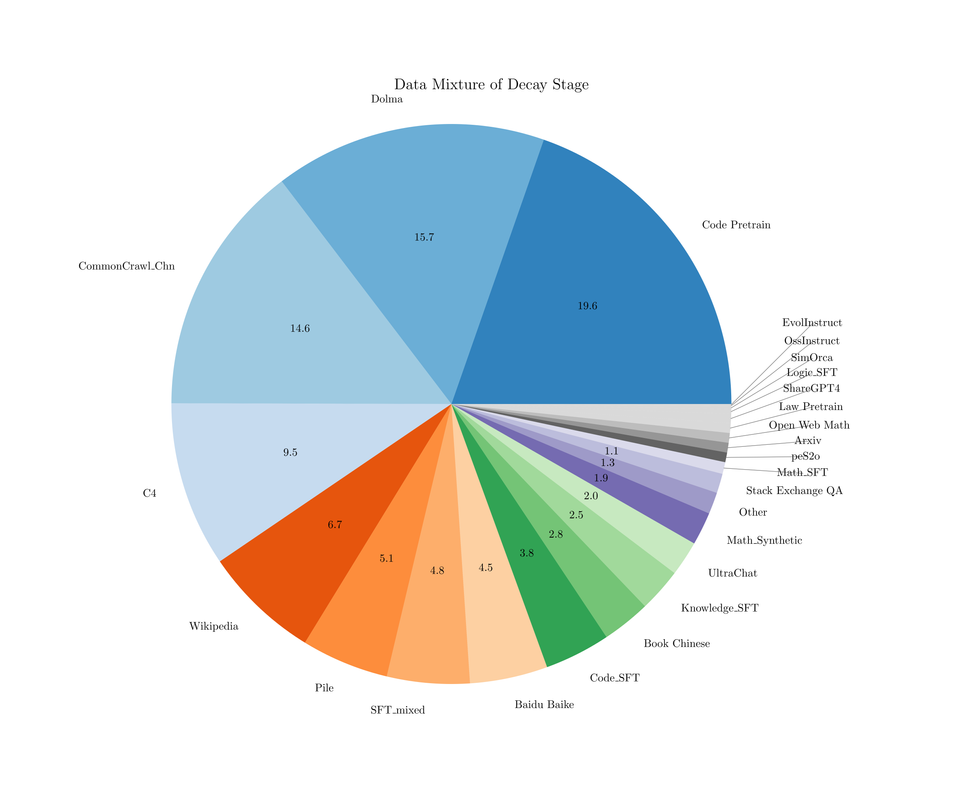
退火阶段,SFT 数据配比如下:
“用更低的成本完成最小的模型,我们没有在追赶,我们一直领先。”刘知远说道。
更多技术细节可以查看:
https://shengdinghu.notion.site/MiniCPM
)












)
![[Python] 什么是KMeans聚类算法以及scikit-learn中的KMeans使用案例](http://pic.xiahunao.cn/[Python] 什么是KMeans聚类算法以及scikit-learn中的KMeans使用案例)


)

:Cloud Alibaba介绍、Nacos服务注册、服务配置中心)