本次分享的是慕尼黑工业大学(TUM) Dominik Durner,Viktor Leis,和 Thomas Neumann 于 2023 年 7 月发表在 PVLDB(Volume 16 No.11) 的论文:
Exploiting Cloud Object Storage for High-Performance Analytics。
DB:https://umbra-db.com/
论文地址:https://www.vldb.org/pvldb/vol16/p2769-durner.pdf
概述:
🌟 ...Our experiments show that even without caching, Umbra with integrated AnyBlob achieves similar performance to state-of-the-art cloud data warehouses that cache data on local SSDs while improving resource elasticity...
我们的云原生时序分析型数据库研发团队在这篇文章上受益匪浅,论文主要聚焦于如何在对象存储上进行高性能数据分析,其中一些结论为我们的工程实践提供了明确的指导方向。
AWS S3 背景介绍
- AWS S3 每 TB 存储成本为 23 美元每月,同时可以实现 11 个 9 的可用性。需要注意的是,最终费用还取决于调用的 API 次数以及跨 Region 的流量费用;
- 访问 S3 的带宽可达到 200 Gbps,这取决于实例的带宽。在原文的 Introduce section 中为 100 Gbps,但后文提到在 AWS C7 系列机型上,这一带宽可以跑满 200 Gbps。
论文中提到 AWS S3 面临以下挑战:
挑战 1:无法充分利用带宽;
挑战 2:存在网络 CPU 额外开销 (主要是 One-to-one thread mapping 带来的一些问题);
挑战 3:缺少多云支持。
🌟 这三个挑战重要程度刚好也是 1 > 2 > 3
云存储(对象存储)特征
云存储(对象存储)通常提供相对较低的延迟(根据负载大小在若干毫秒至数百毫秒之间)和较高的吞吐量(上限取决于 EC2 带宽,EC2 第 7 代机型上可高达 200 Gbps),适用于大规模数据的读取和写入。相比之下,Amazon Elastic Block Store(EBS)通常提供更低的延迟(个位毫秒级),但其吞吐量则低于云存储,通常相差一到两个数量级。
2.1 延迟
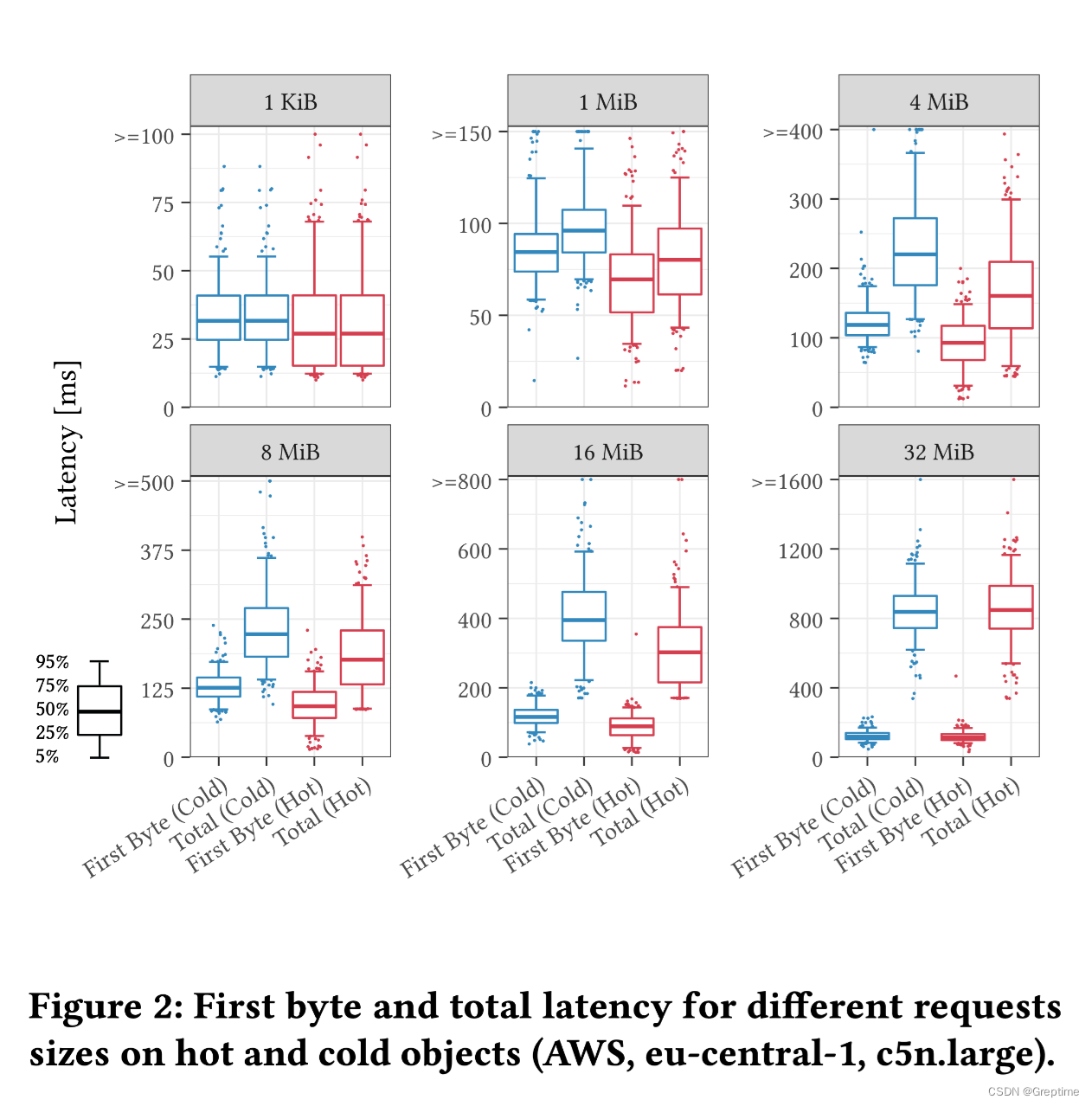
- 在小请求中,首字节延迟(First byte latency)是决定性的影响因素;
- 对于大请求,从 8 MiB 到 32 MiB 的实验显示,延迟随着文件大小呈线性增长,最终达到了单个请求的带宽限制;
- 在热数据方面,我们使用第一次请求和第二十次请求分别代表请求冷热数据的场景。在请求热数据的情境中,延迟通常更低。
🌟 对应到我们读取文件的场景中:
1. 读取平均大小小于 1 KiB 的 Manifest Files 的操作,可能需要约 30 ms(p50, Cold)/约 60 ms(p99,Cold)。
2. 读取 8 MiB 的 Parquet 文件,则需要约 240 ms(p50,Cold)/约 370 ms(p99,Cold)。
#### 2.1.1 吵闹的邻居(Noisy neighbors)
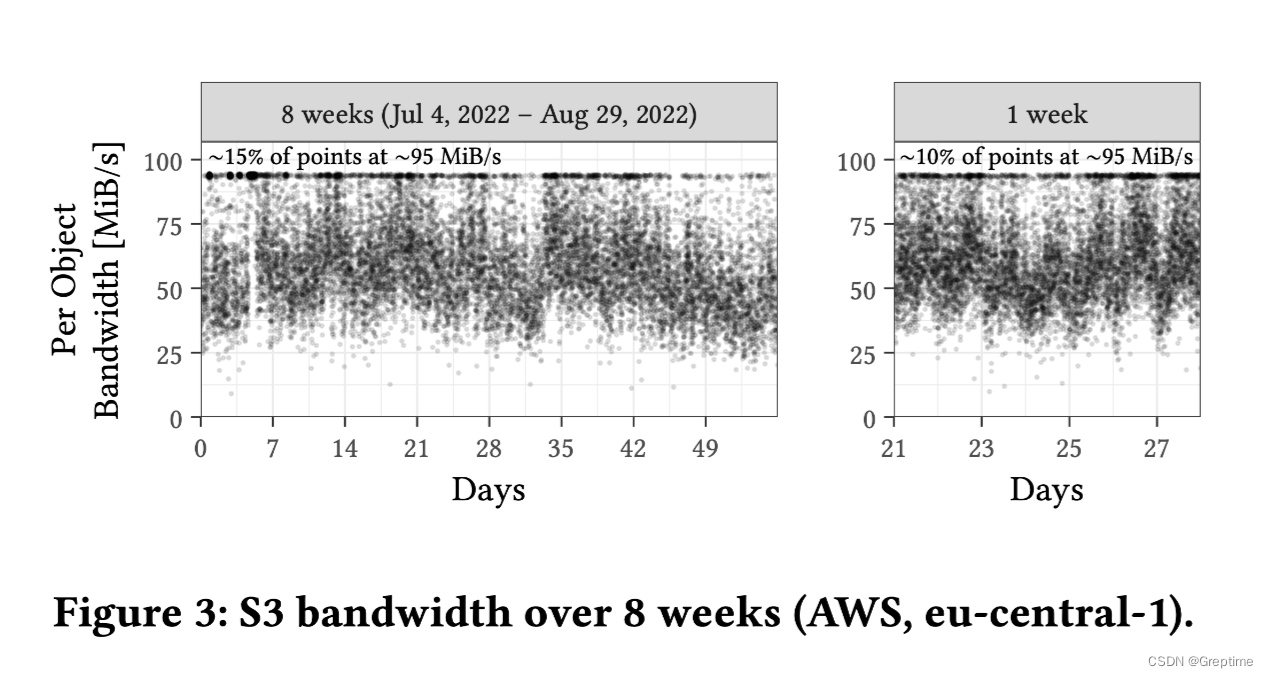
实验方法:单个请求 16 MiB
带宽(Bandwidth)的计算方式:总字节数/持续时间
- 对象带宽存在较大的变化,范围从约 25 到 95 MiB/s 不等
- 有相当数量的数据点(15%)位于最大值(~95 MiB/s)
- 中位数性能稳定在 55-60 MiB/s。
- 周末性能较高
2.1.2 不同云厂家的延迟
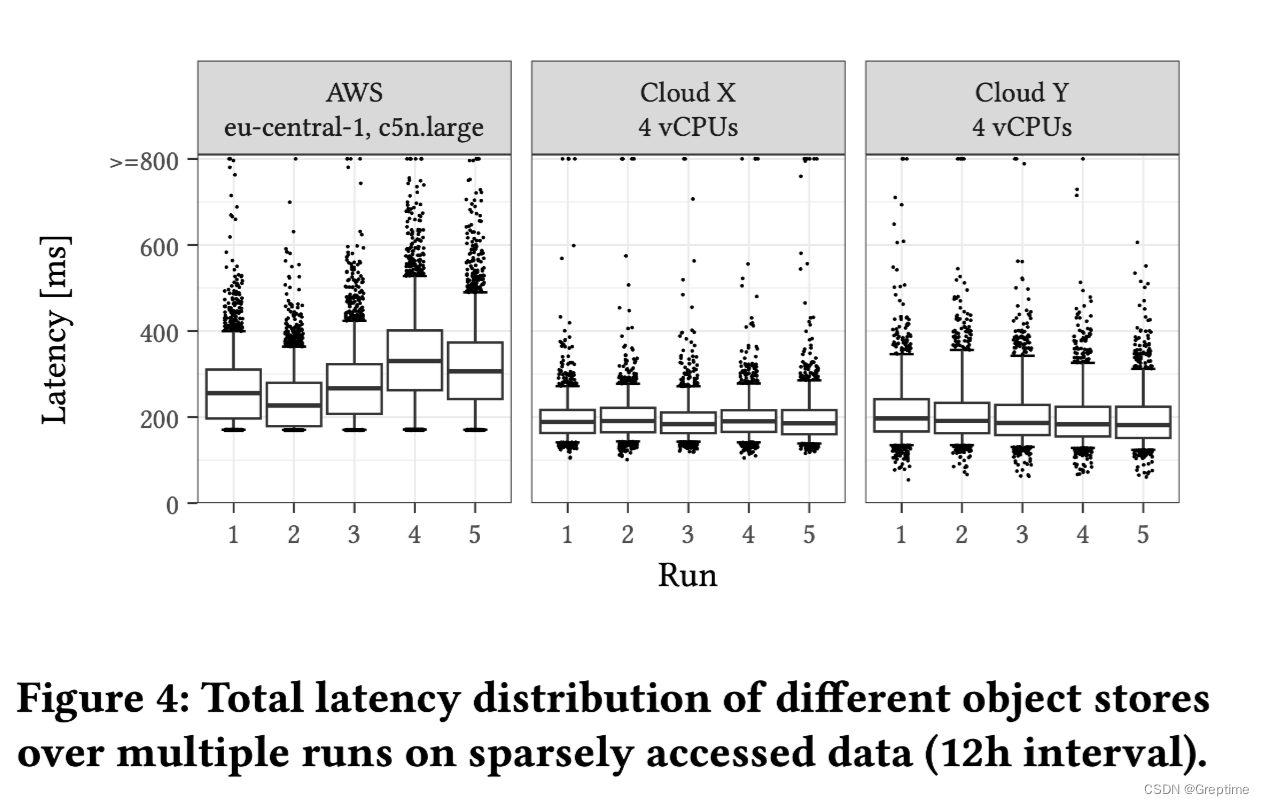
实验方法:单个文件 16 MiB,每次请求间隔 12 小时(以降低缓存对测试的影响)
1. S3 延迟最大;
2. S3 有“最小延迟”,即所有数据都比该数值高;
3. 与 AWS 相比,在低延迟范围内的异常值表明其他供应商不隐藏缓存效果。
我认为这和 S3 底层硬件和实现或许也有关系,整体硬件更老旧或者不同的缓存方案都会导致 2,3 两个情况。
2.2 吞吐量
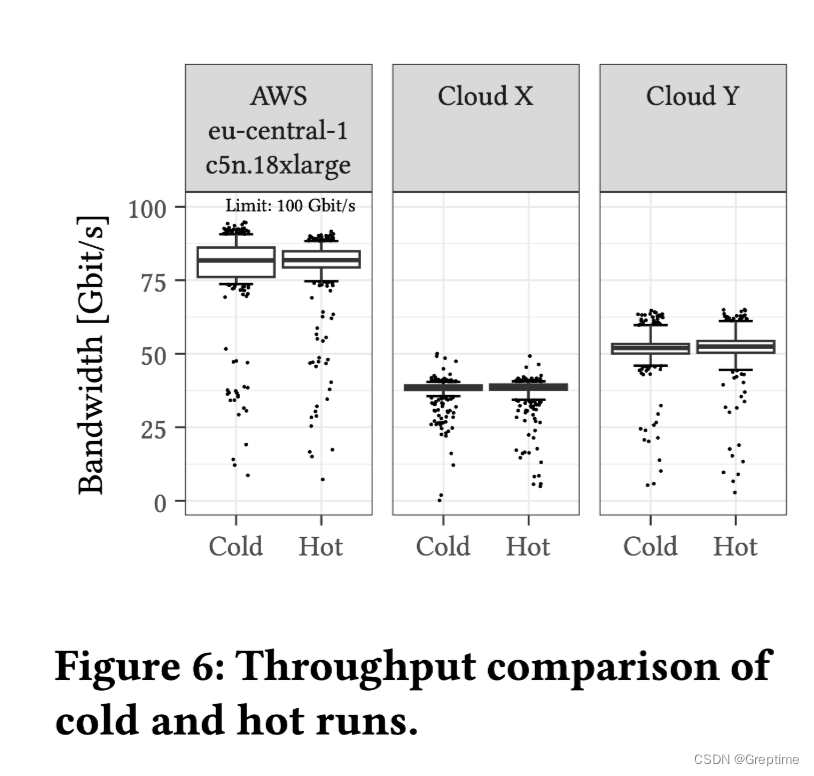
- 单个文件 16 MiB,256 个并行请求,达到最大吞吐量(100 Gbps)
- 随地域(Region)波动
- AWS 75 Gbps (以下均为中位数)
- Cloud X 40Gbps
- Cloud Y 50Gbps
- 冷热数据差别不大
2.3 最佳请求大小

通过上图可以看出,最佳请求大小通常在 8-16 MiB。尽管 32 MiB 的价格更低一些,但在相同带宽下,其下载用时会比 16 MiB 高一倍,相比于 8-16 MiB 而言优势并不明显。
2.4 加密
作者到目前为止所有的实验都是基于非安全链接 HTTP 测得的。在这一节中,作者比较了开启 AES 和启用 HTTPS 后的吞吐量表现。

- HTTPS 需要 HTTP 2 倍 CPU 资源
- AES 只需要增加 30% CPU 资源
在 AWS,所有区域之间的流量,甚至在可用区之间的所有流量都由网络基础设施自动加密。在同一个位置(Location)内,由于 VPC 的隔离,没有其他用户能够拦截 EC2 实例和 S3 网关之间的流量,因此使用 HTTPS 是多余的。
2.5 慢请求
在实验中,我们观察到一些请求具有相当大的尾部延迟,甚至有些请求在没有任何通知的情况下丢失。为了应对这种情况,云供应商建议采用重新请求无响应的请求(request hedging)策略。
作者得到了一些慢请求的经验值,对于 16 MiB 大小的文件:
- 在经过 600 毫秒后,只有不到 5% 的对象尚未被成功下载;
- 第一个字节的延迟超过 200 毫秒的对象也不到 5%。
基于上述经验值,可以考虑对那些超过一定延迟阈值的请求进行重新下载的尝试。
🌟 Amazon Performance Guidelines for Amazon S3.
https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance-guidelines.html
2.6 云存储数据请求模型
在研究中,作者注意到单个请求的带宽类似于访问 HDD 上的数据。为了充分利用网络带宽,需要大量并发请求。对于分析型工作负载而言,8-16 MiB 范围内的请求是具有成本效益的。他们设计了一个模型,用于预测达到给定吞吐目标所需的请求数量。
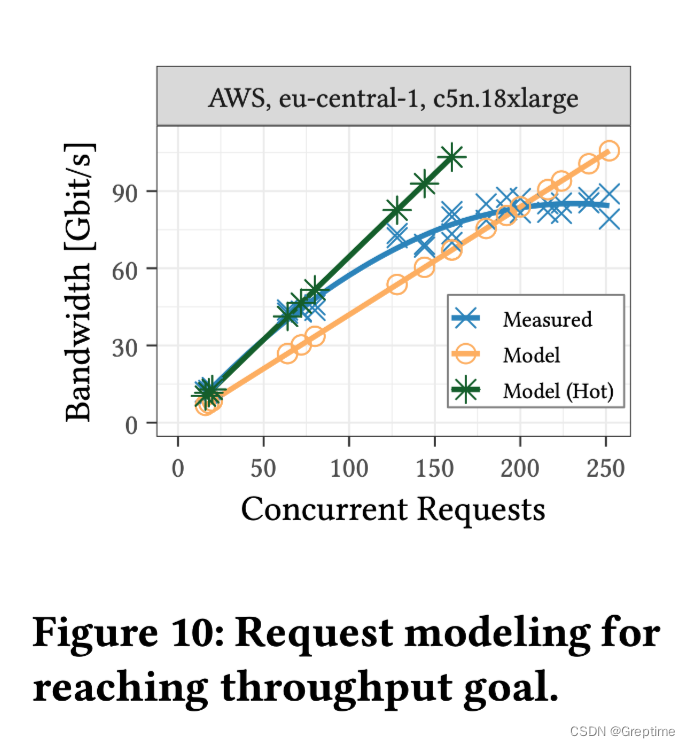
实验使用的计算实例(Instance)总带宽:100 Gbps,图中 Model(Hot)为之前实验中 25 分位(p25)延迟。
- baseLatency 的中位数约为 30 ms (Figure 2:1 KiB 试验得出);
- dataLatency 的中位数约为 20 ms/MiB,Cloud X 和 Cloud Y 更低 (12–15 ms/MiB) (Figure 2:16 MiB 中位数 - 基本延迟);
- S3 跑满 100 Gbps 需要 200-250 个并发请求;
- 数十几毫秒的访问延迟和单个对象的带宽约为 50 MiB/s,对象存储应该是基于 HDD 的(意味着以 ∼80 Gbps 从 S3 读取相当于同时访问约 100 个 HDD)。
AnyBlob
AnyBlob 是作者自行设计的通用对象存储库,支持访问不同云服务商的对象存储服务。与现有的 C++ S3 库相比,AnyBlob 采用了 `io_uring` 接口,并去除了一对一线程映射的限制。最终结果显示 AnyBlob 有着更高的性能并且 CPU 使用有所降低。然而,我认为主要原因可能就是现有 C++ S3 库质量太差了,说不定是实习生糊的。
域名解析策略
除此之外,AnyBlob 中还有一些可圈可点的地方。作者观察到,系统为每个请求解析域名会带来相当大的延迟开销。
1. 缓存多个 Endpoint 的 IPs:将多个 Endpoint 的 IP 地址缓存,并通过调度请求到这些 IPs,基于统计信息更换那些性能明显下降的端点。
2. 基于 MTU:不同 S3 节点具有不同的最大传输单元(MTU)。其中,一些 S3 节点支持使用最大 9001 字节的巨型帧(Jumbo frames),这可以显著降低 CPU 开销。
3. MTU 发现策略:通过对目标节点 IP 进行 ping,并设置 Payload 数据大于 1500 字节且 DNF(do not fragment),以确定是否支持更大的 MTU。
集成云存储
在这一部分,作者介绍了他们是如何集成云存储的。总体而言,这些想法实际上都是趋同的,具体的实现细节还是要看各家工程实践的。

自适应
如果处理请求数据速度较慢,则减少下载线程(及任务)数量并增加请求线程(及任务)数量。
性能评估
5.1 数据下载性能

作者将查询分为了两类,检索密集型(retrieval-heavy)和计算密集型:
1. 检索密集型的代表:Q 1, 6, 19 ,其特点是 In-Memory 和 Remote 之间的性能差异是一个常数倍数。
2. 计算密集型的代表:Q 9, 18,其特点是 In-Memory 和 Remote 之间的性能差异非常小。
5.2 不同存储的对比
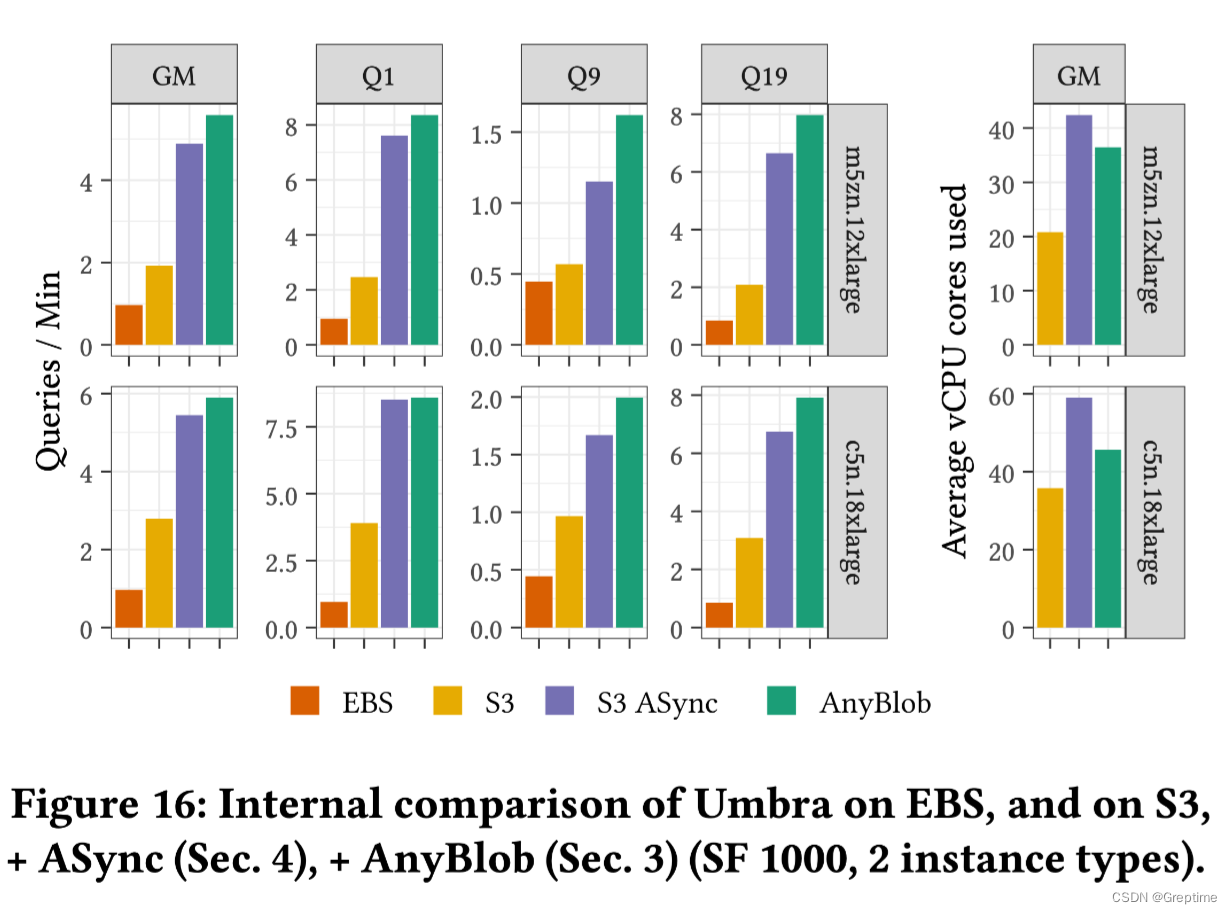
EBS 性能最差(这里应该是买了 gp2/3 丐版,1 Gib 左右带宽)。
5.3 扩展性
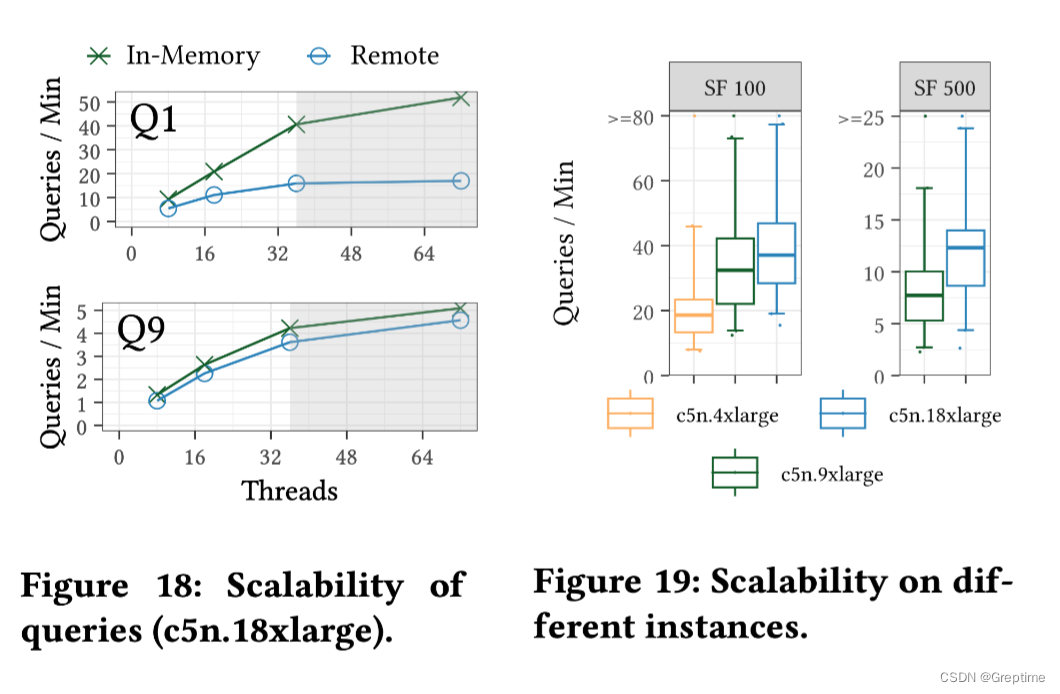
1. 检索密集型(Q1),瓶颈出现在网络带宽
2. 计算密集型(Q9),性能随着核心数量的增加而提高,远程 Umbra 版本的吞吐量几乎与内存版本相同。
5.4 End-To-End Study with Compression & AES
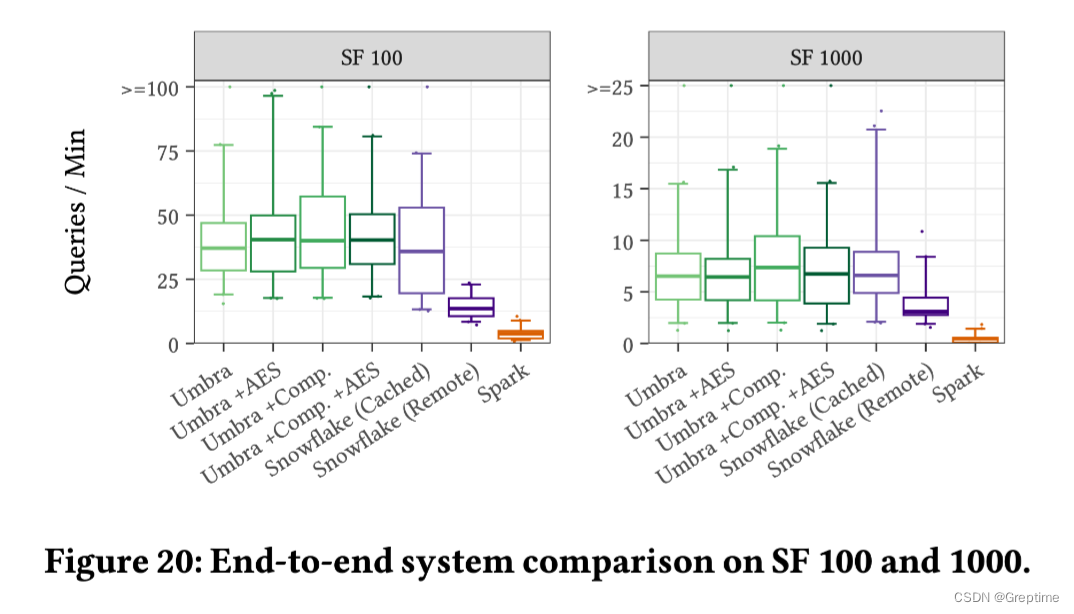
实验参数:比例因子(SF)为 100(∼100 GiB)和 1,000(∼1 TiB 的数据)
实验中用到的 Snowflake 为 large size,而 Umbra 使用了 EC2 的 c5d.18xlarge 实例,并且没有启用缓存。
总的来说,这个对比可能存在一些不够严谨的地方,比如没有提供 Snowflake 组更多的信息:
- 对于 L size Snowflake,可能存在超售限流的情况;
- Snowflake 组购买的可能是 Standard 丐版,这也可能影响实验结果。
不过另一个侧面也说明了:Benchmark marketing 的核心技术可能是统计学魔法 🧙(把没有击中缓存的那次查询藏到 p99 之后)。换句话说,单个查询跑 10 遍和跑 100 遍的 Benchmarking 优化工作量或许不在一个数量级 🥹。
- https://instances.vantage.sh/aws/ec2/c5d.18xlarge
- https://www.snowflake.com/legal-files/CreditConsumptionTable.pdf
关于 Greptime 的小知识:
Greptime 格睿科技于 2022 年创立,目前正在完善和打造时序数据库 GreptimeDB,格睿云 GreptimeCloud 和可观测工具 GreptimeAI 这三款产品。
GreptimeDB 是一款用 Rust 语言编写的时序数据库,具有分布式、开源、云原生和兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时降低长期存储成本;GreptimeCloud 可以为用户提供全托管的 DBaaS 服务,能够与可观测性、物联网等领域高度结合;GreptimeAI 为 LLM 量身打造,提供成本、性能和生成过程的全链路监控。
GreptimeCloud 和 GreptimeAI 已正式公测,欢迎关注公众号或官网了解最新动态!

官网:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/

)

:Cloud Alibaba介绍、Nacos服务注册、服务配置中心)









)


指针进阶)


