1. openai-whisper
这应该是最快的使用方式了。安装pip install -U openai-whisper,接着安装ffmpeg,随后就可以使用了。模型清单如下:

第一种方式,使用命令行:
whisper japanese.wav --language Japanese --model medium
另一种方式,使用python调用:
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3",initial_prompt='以下是普通话的句子。')
print(result["text"])
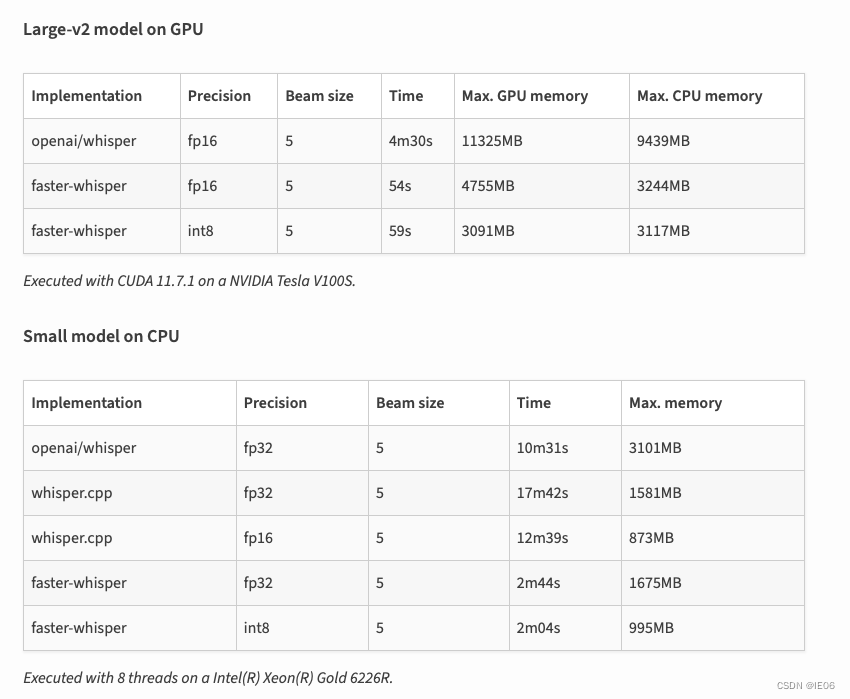
2. faster-whisper
安装也一样:pip install -U faster-whisper,速度对比:
3. whisper-jax
在GPU上的加速版本
首先安装库:
pip install jax jaxlib git+github.com/sanchit-gandhi/whisper-jax.git datasets soundfile librosa
调用代码为:
from whisper_jax import FlaxWhisperPipline
import jax.numpy as jnp
pipeline = FlaxWhisperPipline("openai/whisper-tiny", dtype=jnp.bfloat16, batch_size=16)
%time text = pipeline('test.mp3')
4. whisper-openvino
在intel系列的cpu上加速的版本:
安装库:pip install git+https://github.com/zhuzilin/whisper-openvino.git
调用方法:whisper carmack.mp3 --model tiny.en --beam_size 3
 方法)


 MySQL数据乱码的一些情况)




:自动化部署SpringBoot项目)









![[SWPUCTF 2021 新生赛]Do_you_know_http](http://pic.xiahunao.cn/[SWPUCTF 2021 新生赛]Do_you_know_http)
![BUUCTF-Real-[PHPMYADMIN]CVE-2018-12613](http://pic.xiahunao.cn/BUUCTF-Real-[PHPMYADMIN]CVE-2018-12613)