原生scrapy如何接入scrapy-redis,实现初步入局分布式
- 前言
- scrpy-redis分布式
- 碎语
- 实现流程
- 扩展
- 结束
前言
scrpy-redis分布式
下图是scrpy-redis官方提供的架构图,按我理解,与原生scrapy的差异主要是把名单队列服务器化,也是存储在redis服务中,从而实现分布式。(当然还有piplines采集结果数据的存储差异化,它也可以存储到redis中,实现数据存储分布式)
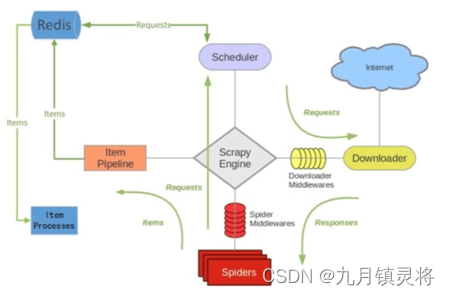
其实一套完整、健全的采集框架可以在scrapy-redis的基础上加入代理池服务,cookie池服务,数据存储服务等等,一般来说不会把解析流程放在采集时做,每个环节只做自己的事情,不要越界,所有后面还会有解析入库服务(听听就好,这套流程搞起来太麻烦了,一般开发都是直接scrapy项目集成搞定)。想法还是要有的,这套流程不只是解耦,更是为了监控和日志统计。
碎语
scrapy-redis分布式实现流程网上有很多教程,参考源码和博客教程后(看是看得懂,关键还是得实践),在这些基础上,整理出自己的实现经验。
实现流程
- 安装
scrapy-redis包
pip install scrapy-redis
sessting配置文件中添加下面配置信息
这是最基本的配置
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"# redis
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
# REDIS_ENCODING = 'utf-8'
# REDIS_PARAMS = {'password': 'redispasswordqwe'} # 如果有密码的话
- 采集脚本修改必要参数
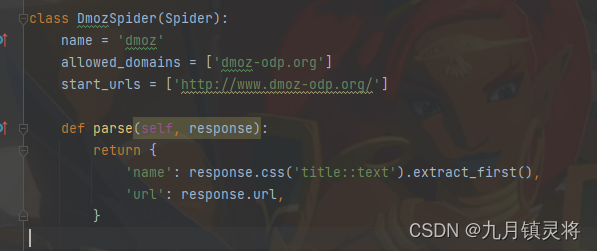
scrapy脚本的一般样式如下
接入scrapy-reids后的一般样式如下
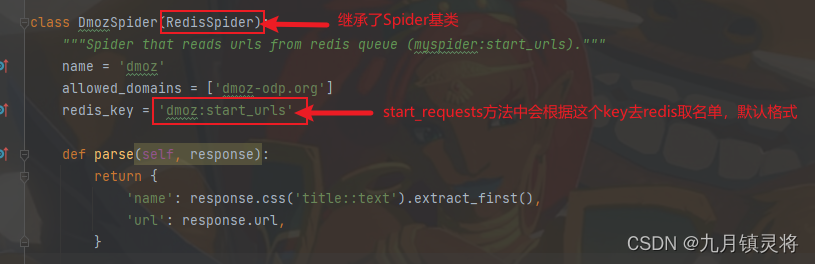
到一步其实我们就已经实现好代码层的改动了,只要运行成功就表示已经接入成功 - 往redis写入名单
运行后发现采集脚本的逻辑并没有执行,且程序一直在运行着,这是因为scrapy-redis会一直监听redis队列,只要往redis写入名单队列,scrapy-redis就会自动拿到名单并执行采集脚本的逻辑,所以这一步我们需要往redis写入对应的key的名单。
lpush dmoz:start_urls http://www.dmoz-odp.org/ # scrapy-redis的采用的start_urls是列表结构
原生命令or工具
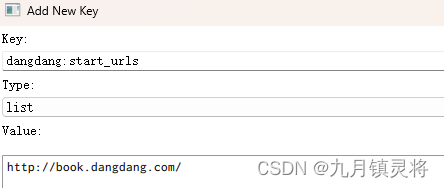
写入成功后就可以看到程序跑起来了。
扩展
使用scrapy-redis后,一般情况下在某个脚本编号下redis会生成三个key,分别是
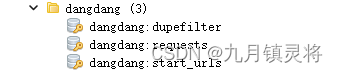
其中
start_urls是初始名单队列,使用的是列表数据结构dupefilter是去重队列,这个只有你开启了去重机制才会生成,默认是不开启的,使用的是集合数据结构requests是scheduler名单队列,我们知道所有名单都是由scheduler发送给调度器的,而scheduler的名单一般是两个来源,一个是初始名单队列;另一个是由Spider提取后发送到scheduler的,这一步就会生成这个key,并且它是有积分优先级机制的(priority),所以它使用的是有序集合数据结构
所有其实我们也可以直接生成requests名单队列,当然生成方式会相对复杂,这个后面分享分享~
结束
好了,分享就到这了,有啥错误的地方请指正~