
目录
- 一. 并查集基本概念
- 处理过程
- 初始化
- 合并
- 查询
- 小结
- 二. 求并优化
- 2.1 按大小求并
- 2.2 按秩(高度)求并
- 2.3 路径压缩
- 2.4 类的实现代码
- 2.5 复杂度分析
- 三. 应用
- LeetCode 128: 最长连续数列
- LeetCode 547: 省份数量
- LeetCode 200: 岛屿数量
一. 并查集基本概念
以一个直观的问题来引入并查集的概念。
亲戚问题:有一群人,他们属于不同家族,同一个家族里的人互为亲戚,不同家族的人不是亲戚。随机指定两个人,问他们是否有亲戚关系。
以下图3个不相交的集合表示3个家族,当询问两个人是否有亲戚关系时,也就是问两个元素是否在同一个集合中,例如3-7有亲戚关系,3-4没有亲戚关系。
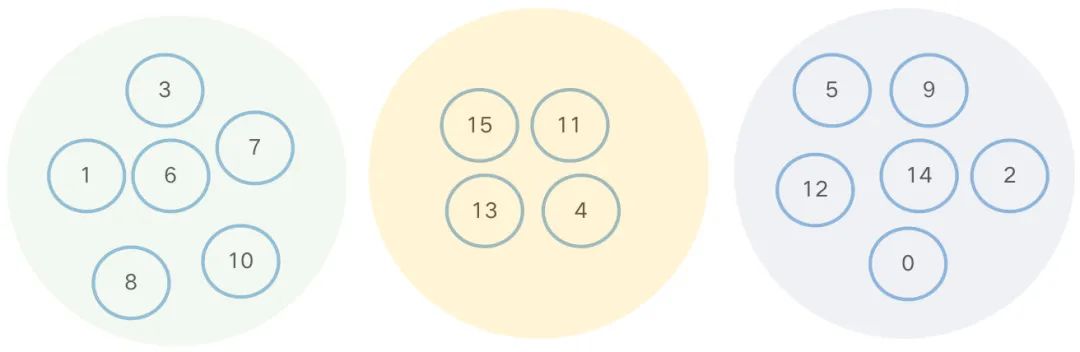
本章将介绍的并查集就是用来处理如上问题的数据结构。
通用描述如下,并查集是一种描述不相交集合的数据结构,若一个问题涉及多个元素,可划归不同集合,同属一个集合内的元素等价(即可用任意一个元素作为代表),不同集合内的元素不等价。
当我们问某些元素是否等价时,例如亲戚问题中问两人否互为亲戚关系时,就可以用不相交集来解决。
这类问题的初始状态通常是每一个元素构成一个单元素集合,后续通过合并操作将等价元素归入一个集合中。
因此处理过程中通常要用到查询(元素属于哪个集合,用于决定是否要执行合并)及合并集合的操作。
故此,不相交集也叫并查集,“不相交”描述的是问题对象构成集合之后不同集合不相交的状态,“并查”描述的是处理问题时的操作。本章中两种称呼都会出现。
本章余下内容,我们会以LeetCode 547: 省份数量问题来理解不相交集及其并查操作,该问题描述如下。
LeetCode 547. 省份数量有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。省份是一组直接或间接相连的城市,组内不含其他没有相连的城市。给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。返回矩阵中 省份 的数量。示例1:
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]]
输出:2示例2
输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]]
输出:3这是一个典型的不相交集问题。
如果我们能够通过矩阵信息将同一省份的城市都加入到同一个集合,那么最终这些不相交集合的数量就是省份数量。
容易思考出这样的处理过程:
-
一开始所有令城市为单元素集合。
-
遍历矩阵,将值为
1时的两个城市合并在一起得到一个2元素的集合。之后当某个单元素集合或者2元素集合要再与一个2元素集合合并时,我们需要判断这两个元素是否不在一个集合中,这需要一个查询元素所属集合的操作。 -
反复进行这样的查询合并操作,当结束矩阵遍历时,得到的集合都是不相交的的省份。
在查询操作中,我们容易想到以树的结构来实现,以根节点作为代表这个集合的代表元,每个元素指向一个父节点,循环地向上查询,一定能查询到根节点。
查询两个节点元素的根是否相同,即可知道他们是否属于同一集合。
由此我们初步构想出不相交集处理问题的主要过程:初始化、合并和查询。
处理过程
以树的语言来说明不相交集如何处理上述省份问题。
初始化
创建一个数组parent[],下标代表元素(树的节点),总长度即总元素个数,值为父节点下标,一棵树中只有根节点以自己为父节点。
开始时每个节点都是以自己为根的单节点树,即parent[x] = x。如下初始化过程通常在main方法或并查集类(UnionFind)的构造方法中完成。
// 初始化
int[] parent = new int[isConnected.length];
for(int i = 0; i < isConnected.length; i++) {parent[i] = i;
}假设输入如下,一共有6个城市{0, 1, 2, 3, 4, 5},isConnected\[i][j] = 1表示i与j直接相连。
// 输入矩阵M
{
{1, 0, 0, 0, 1, 0}, // 0-0, 0-4
{0, 1, 0, 0, 0, 1}, // 1-1, 1-5
{0, 0, 1, 1, 0, 1}, // 2-2, 2-3, 2-5
{0, 0, 1, 1, 0, 0}, // 3-2, 3-3
{1, 0, 0, 0, 1, 0}, // 4-0, 4-4
{0, 1, 1, 0, 0, 1}, // 5-1, 5-2, 5-5
}初始化后得到如下5棵单节点树(单元素集合)。

合并
接着遍历矩阵,执行合并。合并的依据是查询,对于x和y,如果find(x) = find(y),说明代表元相同,属于同一集合,不必合并。
若find(x) != find(y),将其合并,令parent[find(y)] = find(x)( 或parent[find(x)] = find(y) )。
从树的角度来看相当于把y挂在了x上(或把x挂在y上)。
我们现在先假设查询方法find(x)能够正常工作,该方法返回x所在树的的树根(所在集合的代表元),在接下来的「查询」小节中再给出find(x)的实现。
// 合并
public void union(int x, int y) {if(find(x) != find(y)){parent[find(y)] = find(x);}
}这里需要强调的是,代表元可以是集合中的任意一个元素,所以一开始选谁做根(代表元)是无关紧要的,
在遍历过程中对于每一次isConnected[i][j] = 1,都执行一次union(i, j),不断扩大集合。遍历结束时得到的每个集合都对应一个省份。
如下图,实际上输入矩阵前三行遍历完成后,我们就已经得到了最终的不相交集,此输入对应的输出为2,即原输入矩阵中存在2个省份。
※ 省份数量可以在union方法内添加一行代码(发生合并时令unionCount++)实现累计,最后以元素总数减去合并次数得到不相交集数量。
也可以在合并完成后对所有元素执行一次find(x),统计不同结果的个数得到。这不是本节的重点故不写出此过程。
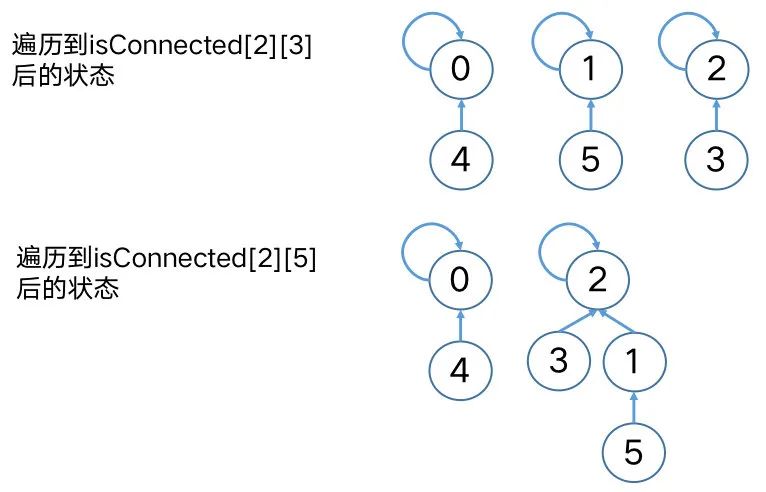
查询
在合并前需要查询元素所在树的根节点,由于不相交集都是一棵树,每一个节点x都以parent[x]指向其父节点,根的父节点为其自身,故可以用递归的方式查询一个节点的根节点。
// 查询
public int find(int x) {if(parent[x] == x){ // 只有根节点满足parent[x] = xreturn x;} else{return find(parent[x]); }
}小结
至此我们得到了典型的不相交集实现,主要方法find和union都只有数行代码,十分简洁。
前面我们以较为简单的输入分析了查询及合并的过程,若考虑集合元素较多的情形,我们将可能得到一棵较高的树,例如上述{1, 2, 3, 5}这个集合,连续地与单节点集合{6}, {7}, {8}执行union(6, 5), union(7, 5), union(8, 5)之后,将得到如下。
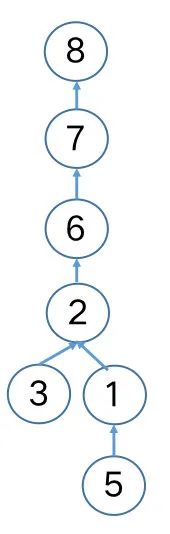
不难发现,简单直接的合并将有可能导致较高的树高,若再继续执行union(5, 9),首先进行的find(5)将会依次向父节点方向查询1, 2, 6, 7, 8,查询效率低下。
如果我们能将树的高度降低,例如除根节点外的所有节点直接挂在根节点下,那么find(x)的复杂度将为常数级。
沿着这个思路,下一节我们将介绍两种更好的求并方法,使得两棵树合并后得到的新树树高较小。
补充说明:寻找等价关系
在省份问题中,由于矩阵已给出等价信息,我们可以直接求并。
对于有的问题,开始时等价信息并不明显,需要先找到这样的等价关系,然后通过求并将初始的单元素集合合并成2元素集合。
例如LeetCode 128: 最长连续序列问题,可以用不相交集求解,但需要在开始时对 i 和 i+1 执行一次合并操作。具体过程请参考「例题」中的题解。
二. 求并优化
以目前的实现求解省份问题,我们已经发现,合并 x 和 y 所在树时,只是简单地将y所在树的根指向x所在树的根parent[find(y)] = find(x),最坏的情况下我们将得到一棵链状的树,较高的树高将导致较高的查询(及合并)复杂度。
一个显然的好做法是将一棵树除根外的所有节点都直接指向根节点,这样在查询任意一个节点时,都只需一步即可返回所在树的树根。因此我们希望以某种策略使合并后得到树高较小的树,下面我们将介绍两种改进的求并法。
2.1 按大小求并
若一棵树拥有越多的节点,其高度倾向于越高。因此在合并前先比较两棵树的大小,将较小树的根连接到较大树的根以完成合并。
代码需要添加保存集合(树)大小的数组和该数组的初始化内容。
如下代码在构造方法中初始化树大小数组size[]。
// 初始化
int[] parent = new int[isConnected.length];
for(int i = 0; i < isConnected.length; i++) {parent[i] = i;
}
UnionFind uf = new UnionFind(parent);// UnionFind类(部分)
class UnionFind{private int[] parent;private int[] size; // 保存树的大小public UnionFind(int[] parent) {this.parent = parent;this.size = new int[parent.length];for (int i = 0; i < parent.length; i++) {this.size[i] = 1; // 初始时单节点树大小为1}}
}按大小求并。
// 该方法在UnionFind类中
public void union(int x, int y){int xRoot = find(x);int yRoot = find(y);// 根节点不同才求并if(xRoot != yRoot) {if(size[yRoot] <= size[xRoot]){parent[yRoot] = xRoot; // 较小者的根挂在较大者根上size[xRoot] += size[yRoot]; // 新树大小为原树大小之和} else {parent[xRoot] = yRoot;size[yRoot] += size[xRoot];}}
}2.2 按秩(高度)求并
有时,一棵大小较小的树反而高于较大的树,直接按高度求并比按大小求并能更准确地使每次合并后的新树高度较小。
另外,不同于按大小求并时每次合并均修改新树的大小信息,按高度求并时,新树的高度变化只发生在两棵树高度相等时,此时高度加1。
※ 关于名称:若程序中所有的求并操作都是通过本节方法实现,则可严格地称其为按高度求并。
但后续将介绍一种find()的优化版本,该优化版本在查询的同时也完成一部分合并操作,应用此版本的查询方法将导致某些时刻rank[root]与树的实际高度不相等,严谨起见,通常称作按“秩(rank)”求并。
详细内容在「路径压缩」一节叙述。
// 初始化
int[] parent = new int[isConnected.length];
for(int i = 0; i < isConnected.length; i++) {parent[i] = i;
}
UnionFind uf = new UnionFind(parent);// UnionFind类(部分)
class UnionFind{private int[] parent;private int[] rank; // 保存树秩public UnionFind(int[] parent) {this.parent = parent;this.rank = new int[parent.length];for (int i = 0; i < parent.length; i++) {this.rank[i] = 1; // 初始时单节点树的秩为1}}
}按秩(高度)求并。
// 该方法在UnionFind类中
public void union(int x, int y){int xRoot = find(x);int yRoot = find(y);// 根节点相同不影响结果,最终还是会得到根节点指向自己的结果// 在不同集合元素求并操作较多时,省去xRoot != yRoot的判断效率较高if(rank[yRoot] <= rank[xRoot]){parent[yRoot] = xRoot;} else {parent[xRoot] = yRoot;}// 当两棵树秩相等且为不同集合时,新树的高度加1// 注意,秩较小的树的秩无需更新,因为每次求一个元素所在集合的高度都会先找到该集合的树的根,// 秩较小的树在合并后其树根在新树中就不是树根了if(rank[xRoot] == rank[yRoot] && xRoot != yRoot){rank[xRoot]++; }
}对前述{1, 2, 3, 5}集合,连续地与单节点集合{6}, {7}, {8}执行union(6, 5), union(7, 5), union(8, 5),在应用按秩求并之后,将得到如下。
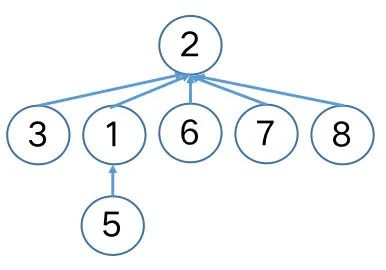
这样得到的树已经很理想了,但我们还会想,如果能将节点5也直接连到根节点2下,那将得到一个对于查询操作来说最完美的高度为2的树。
实际上只需在find()方法中修改一行代码,就可以让find()在查询根节点的同时执行一部分合并动作。
例如在 union(6, 5) 时,会执行 find(5),此时让5在寻找其所在树的根节点的过程中,实时地让令其到根节点路径上的所有节点都指向根节点,就能实现对该路径节点与根节点的再次合并(指同一集合内节点指向的改变而非集合合并),结果使得原路径被压缩,所以改进后的查询操作也称作带路径压缩的查询。
2.3 路径压缩
只需改动else时的动作,将递归的find[parent[x]]赋值给parent[x],就可以让当前查找的节点到根节点路径上所有的节点都指向根节点,如下。
// 带合并的路径压缩查找
public int find(int x) {if(parent[x] == x){return x;} else{// 将递归查找父节点的结果作为当前节点的父节点// 每次回归都返回当前节点的父节点(已经被赋值为根节点了,所以每次都返回根节点)return parent[x] = find(parent[x]); }
}对前述{1, 2, 3, 5}集合,连续地与单节点集合{6}, {7}, {8}执行union(6, 5), union(7, 5), union(8, 5),在应用带路径压缩的查询和按秩求并之后,将得到如下。
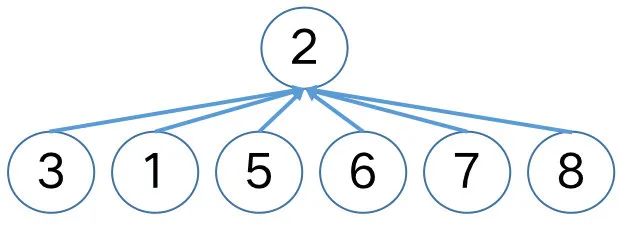
5指向2发生在union(6, 5)时(其内调用find(5)时),注意到find()方法并未修改树的高度,也即此时的rank[2] = 3,但树的高度已经变为2了。
因此在应用带路径压缩的查询和按秩求并后,rank[root]记录的数字是树真实高度的一个上界,这就是通常用“秩”而非“高度“来描述的原因。
2.4 类的实现代码
通过上述对实际问题处理过程的讲解,我们已经给出了能够处理集合代表元查询及合并问题的不相交集数据结构。
在按大小或按秩(高度)求并时,需要新建保存大小或秩(高度)信息的数组。
现给出如下包含直接求并,按大小求并,按秩(高度)求并,直接查询,带路径压缩查询等方法的实现。
实际使用时只需按需选择一种求并和一种查询方法即可,按秩求并 + 带路径压缩查询的组合在多数情况下是效率较高的选择。
class UnionFind{private int[] parent;private int[] rank; // 按秩求并和按大小求并选择其中一种即可private int[] size;public UnionFind(int[] parent) {this.parent = parent;this.rank = new int[parent.length];this.size = new int[parent.length];for (int i = 0; i < parent.length; i++) {this.rank[i] = 1;this.size[i] = 1;}}/*** 直接求并*/public void unionDirect(int x, int y) {if(find(x) != find(y)){parent[find(y)] = find(x);}}/*** 按大小求并*/public void unionBySize(int x, int y){int xRoot = find(x);int yRoot = find(y);// 根节点不同才求并if(xRoot != yRoot) {if(size[yRoot] <= size[xRoot]){parent[yRoot] = xRoot;size[xRoot] += size[yRoot];} else {parent[xRoot] = yRoot;size[yRoot] += size[xRoot];}}}/*** 按秩求并*/public void union(int x, int y){int xRoot = find(x);int yRoot = find(y);// 根节点相同不影响结果,最终还是会得到根节点指向自己的结果// 在不同集合元素求并操作较多时,省去xRoot != yRoot的判断效率较高if(rank[yRoot] <= rank[xRoot]){parent[yRoot] = xRoot;} else {parent[xRoot] = yRoot;}// 当两棵树秩相等且为不同集合时,新树的高度加1// 注意,秩较小的树的秩无需更新,因为每次求一个元素所在集合的高度都会先找到该集合的树的根if(rank[xRoot] == rank[yRoot] && xRoot != yRoot){rank[xRoot]++; }}/*** 直接查找*/public int findDirect(int x) {if(parent[x] == x){return x;} else{return findDirect(parent[x]); }}/*** 带路径压缩的查找*/public int find(int x) {if(parent[x] == x){return x;} else{// 将递归查找父节点的结果作为当前节点的父节点// 每次回归都返回当前节点的父节点(已经被赋值为根节点了,所以每次都返回根节点)return parent[x] = find(parent[x]); }}
}无需大小/秩数组空间的技巧
如果元素的表示不涉及负数(在本章例子中用非负整数来表示元素,这也是通常的做法)的话,可以用一个小技巧来节省大小或秩(高度)数组的开销。
在以前的说明中,初始化集合时,我们令每一个元素的父节点指向自己,即parent[x] = x,表示这是根节点。
本技巧以parent[x] = -1表示根节点,并以parent[x]是否为负数来判断x是否为根节点。
需要注意的是,因其为负数,在两棵树比较大小或秩(高度)时,值越小,则大小或秩(高度)越大。
在按大小求并时,size[root]的更新方法不变,但在按高度求并时,新树高度增高1时令rank[root]--。
应用此技巧,给出如下完整实现。
同样地,实际使用时只需按需选择一种求并和一种查询方法即可,按秩求并 + 带路径压缩查询的组合在多数情况下是效率较高的选择。
class UnionFind2{private int[] parent;public UnionFind2(int[] parent) {this.parent = parent;}/*** 直接求并*/public void unionDirect(int x, int y) {if(find(x) != find(y)){parent[find(y)] = find(x);}}/*** 按大小求并*/public void unionBySize(int x, int y){int xRoot = find(x);int yRoot = find(y);// 根节点不同才求并if(xRoot != yRoot) {if(parent[xRoot] <= parent[yRoot]){ // 负数比较,较小者树较大parent[xRoot] += parent[yRoot];parent[yRoot] = xRoot;} else {parent[yRoot] += parent[xRoot];parent[xRoot] = yRoot;}}}/*** 按秩求并*/public void union(int x, int y){int xRoot = find(x);int yRoot = find(y);// 负数比较,秩更小者树更高,将小秩树挂到大秩树上// 在不用负数技巧的版本中,由于根节点相同不影响结果,考虑到在不同集合元素求并操作较多时,省去xRoot != yRoot的判断能提高效率// 但在这个版本中,必须要执行xRoot != yRoot的判断,否则当两个同集合元素比较时,将使得parent[xRoot] = xRoot。// 也即原为一个负数的parent[xRoot]的值变成了一个非负数(xRoot),将导致程序错误if(xRoot != yRoot) {if(parent[xRoot] <= parent[yRoot]){parent[yRoot] = xRoot;} else {parent[xRoot] = yRoot;}// 当两棵树秩相等根节点不同时,新树的高度增高1(负数表示,减1)if(parent[xRoot] == parent[yRoot]){parent[xRoot]--; }}}/*** 直接查找*/public int findDirect(int x) {if(parent[x] < 0){ // 只有代表元满足 parent[x] < 0return x;} else{// 将递归查找父节点的结果作为当前节点的父节点// 每次回归都返回当前节点的父节点(已经被赋值为根节点了,所以每次都返回根节点)return findDirect(parent[x]); }}/*** 带路径压缩的查找*/public int find(int x) {if(parent[x] < 0){ // 只有代表元满足 parent[x] < 0return x;} else{parent[x] = find(parent[x]); // 将递归查找父节点的结果作为当前节点的父节点return parent[x]; // 每次回归都返回当前节点的父节点(已经被赋值为根节点了,所以每次都返回根节点)}}
}2.5 复杂度分析
应用按秩求并和带路径压缩查询的复杂度分析。
时间复杂度:严格的分析很复杂,省略。时间复杂度为O(αn),对于任何实际的问题,α通常不会超过5,n是程序初始时元素个数。
空间复杂度:取决于parent[] / size[] / rank[]数组所占空间,为O(n)。
三. 应用
在「处理过程」中我们介绍了应用不相交集处理问题的通用过程,对于不同的具体问题,各步骤的应用是灵活的。
在本节例题中我们将看到,同样是应用不相交集,对于LeetCode 128: 最长连续数列,只需在find()时以路径压缩方式合并,除给定初始时的等价关系用到主动合并(直接求并)外,不再调用union()。
在本章介绍的LeetCode 547: 省份数量中,等价关系在输入矩阵中是明显的,只需在isConnected[i][j] = 1时主动合并union(i, j)即可,find()中可以不带合并(路径压缩),当然也可以带路径压缩以提高效率。
在LeetCode 200: 岛屿数量中,其与省份数量问题的输入都是矩阵,但岛屿数量问题的初始时单节点元素是矩阵中的每一个“1”,而省份数量问题是列(或行)中的每一个元素。此外,前者还需小心处理边界条件。
LeetCode 128: 最长连续数列
public int longestConsecutiveUF(int[] nums) {if(nums.length < 2) {return nums.length;}UnionFind uf = new UnionFind(nums);for(int num : nums) {uf.union(num, num + 1);}int max = 1;for (int num : nums) {max = Math.max(max, uf.find(num) - num + 1);}return max;
}class UnionFind{// 用HashMap存储并查集Map<Integer, Integer> parents = new HashMap<>();// 输入数组arr,初始化并查集,同时完成对arr的去重public UnionFind(int[] arr) {for(int i : arr) {parents.put(i, i);}}// 带路径压缩的查找public int find(int x) {if(x == parents.get(x)) {return x;}int p = parents.get(x);parents.put(x, find(p));return parents.get(x);}// 直接求并public void union(int x, int y) {if(parents.containsKey(y)) {parents.put(x, y); // rootx指向rooty}}
}LeetCode 547: 省份数量
class Solution {// 按秩序合并的并查集// 初始化 > 遍历grid,对“1”的格子,考察其右侧及下侧的格子,分别执行合并,// 初始化时得到最初的岛屿总数islandsCount,按秩序合并,每次合并累计合并次数mergedCount// 最终岛屿数量等于islandsCount-mergedCount// 1. 初始化// parents[k] 将二维grid[i][j]映射到一维 k = i * COL + j// 初始化parents: grid[i][j] = 1时 parents[k] = k// 2. 遍历gridint islandsCount = 0;int mergedCount = 0;public int numIslands(char[][] grid) {int m = grid.length, n = grid[0].length;UnionFind uf = new UnionFind(grid);for(int i = 0; i < m; i++){for(int j = 0; j < n; j++){int landx = i * n + j;if(grid[i][j] == '1'){ // 以下两行,检测右侧和下侧是否联通,联通时合并之(用并列的if,在union中会检测是否属于同一集合)if(j < n - 1 && grid[i][j + 1] == '1') { // 右侧uf.union(landx, landx + 1);}if(i < m - 1 && grid[i + 1][j] == '1') { // 下侧uf.union(landx, landx + n);}}}}return islandsCount - mergedCount;}private class UnionFind{private int[] parents;private int[] rank;public UnionFind(char[][] grid){int m = grid.length, n = grid[0].length;this.parents = new int[m * n];this.rank = new int[m * n];for(int i = 0; i < m; i++){for(int j = 0; j < n; j++) {if(grid[i][j] == '1'){ // 针对单格岛,累计岛屿数量,赋值parents[k] rank[k]islandsCount++;int k = i * n + j;parents[k] = k;rank[k] = 1;}}}}// 带路径压缩的查找public int find(int x){if(parents[x] == x) return x;return parents[x] = find(parents[x]);}// 按秩合并public void union(int x, int y){int xRoot = find(x);int yRoot = find(y);if(xRoot != yRoot){mergedCount++; // 只有不属于一个集合时,合并才次数加1if(rank[yRoot] <= rank[xRoot]) parents[yRoot] = xRoot;// yRoot挂到xRoot上else parents[xRoot] = yRoot; // xRoot挂到yRoot上if (rank[xRoot] == rank[yRoot]) rank[xRoot]++; // 秩相同时才加1}}}}LeetCode 200: 岛屿数量
package com.yukiyama.leetcode;/*** 构成一个岛的1组成一个集合,岛与岛之间的关系是不相交集* 按行或列遍历,检查当前元素的右邻和下邻元素,通过合并将每一个1都放入相应的集合* 一开始每一个1都是一个单节点集合* 遍历的界是比行/列少1,i < row.length - 1, j < column.length - 1* @author lixueshan**/
public class LC200NumIslands {public static void main(String[] args) {LC200NumIslands demo = new LC200NumIslands();// char[][] grid = {{'1'}};// char[][] grid = {{'1', '1'}};char[][] grid = {{'1','1','0','0','0'},{'1','1','0','0','0'},{'0','0','1','0','0'},{'0','0','0','1','1'}};// char[][] grid = {{'1','1','1','1','0'},{'1','1','0','1','0'},{'1','1','0','0','0'},{'0','0','0','0','0'}};System.out.println(demo.numIslands(grid));}public int numIslands(char[][] grid) {// 初始化单节点集合。// 两层for遍历grid,令值为'1'的元素指向自己,islandNum++// land = i*CLOUMN+j;// parent[land] = land;int ROW = grid.length;int COLUMN = grid[0].length;int[] parent = new int[ROW * COLUMN];int[] rank = new int[parent.length];int islandsNum = 0;for (int i = 0; i < ROW; i++) {for (int j = 0; j < COLUMN; j++) {if(grid[i][j] == '1') {islandsNum++;int land = i * COLUMN + j;parent[land] = land;rank[land] = 1;}}}UnionFindLC200 uf = new UnionFindLC200(parent, rank);// 为方便处理边界情形,向grid矩阵最后一行下添加一行(全'0'),最后一列后添加一列(全'0')char[][] newGrid = new char[ROW + 1][COLUMN + 1];for (int i = 0; i < ROW; i++) {for (int j = 0; j < COLUMN; j++) {newGrid[i][j] = grid[i][j];}}for (int i = 0; i < COLUMN + 1; i++) {newGrid[ROW][i] = '0';}for (int j = 0; j < ROW + 1; j++) {newGrid[j][COLUMN] = '0';}// 合并集合。// 两层for遍历grid,探测下邻和右邻,执行按秩合并,每合并一次使islandNum--for (int i = 0; i < ROW; i++) { // 无需执行newGrid的最后一行for (int j = 0; j < COLUMN; j++) { // 无需执行newGrid的最后一列if(newGrid[i][j] == '1') {if(newGrid[i][j + 1] == '1') { // 探测右邻int landx = i * COLUMN + j;int landy = i * COLUMN + j + 1;uf.union(landx, landy);}if(newGrid[i + 1][j] == '1') { // 探测下邻int landx = i * COLUMN + j;int landy = (i + 1) * COLUMN + j;uf.union(landx, landy); }}}}return islandsNum - uf.getUnionCount();}
}class UnionFindLC200{private int[] parent;private int unionCount = 0;private int[] rank;public UnionFindLC200(int[] parent, int[] rank) {this.parent = parent;this.rank = rank;}/*** 按秩求并*/public void union(int x, int y){int xRoot = find(x);int yRoot = find(y);// if(xRoot != yRoot) {unionCount++;}if(rank[yRoot] <= rank[xRoot]){parent[yRoot] = xRoot;} else {parent[xRoot] = yRoot;}// 当两棵树秩相等且为不同集合时,新树的高度加1// 注意,秩较小的树的秩无需更新,因为每次求一个元素所在集合的高度都会先找到该集合的树的根if(rank[xRoot] == rank[yRoot] && xRoot != yRoot){rank[xRoot]++; }}/*** 带路径压缩的查找*/public int find(int x) {if(parent[x] == x){return x;} else{// 将递归查找父节点的结果作为当前节点的父节点// 每次回归都返回当前节点的父节点(已经被赋值为根节点了,所以每次都返回根节点)return parent[x] = find(parent[x]); }}public int getUnionCount() {return this.unionCount;}
}—END—

🦁 其它优质专栏推荐 🦁
🌟《Java核心系列(修炼内功,无上心法)》: 主要是JDK源码的核心讲解,几乎每篇文章都过万字,让你详细掌握每一个知识点!
🌟 《springBoot 源码剥析核心系列》:一些场景的Springboot源码剥析以及常用Springboot相关知识点解读
欢迎加入狮子的社区:『Lion-编程进阶之路』,日常收录优质好文
更多文章可持续关注上方🦁的博客,2023咱们顶峰相见!



——索引(Index)(3))

)
)


)




)
一)



