
小伙伴们,顺序表的增删改查已经学会了,今天我们学习比顺序表还难“亿”点点的链表,也需要增删改查。跟顺序表一样,还是需要创建三个文件SList.h,SList.c和test.c,然后做一些准备工作,具体文件的说明跟顺序表一样,忘了的小伙伴们可以去看一下哦。好了,进入单链表的学习吧。
1. 链表的概念及结构
 在链表⾥,每节“⻋厢”是什么样的呢?
在链表⾥,每节“⻋厢”是什么样的呢?

struct SListNode
{int data; //节点数据struct SListNode* next; //指针变量⽤保存下⼀个节点的地址
};
typedef int SLTDataType;//修改别名
//链表是由节点组成
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;//typedef struct SListNode SLTNode;void SLTPrint(SLTNode* phead);//phead是第一个节点SList.c
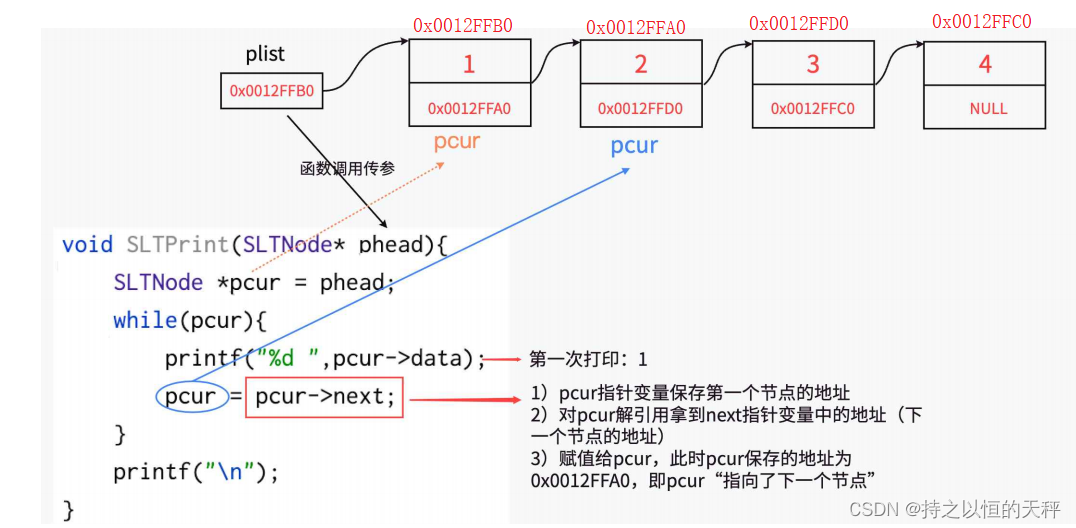
void SLTPrint(SLTNode* phead) {SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->data);pcur = pcur->next;}printf("NULL\n");
}test.c
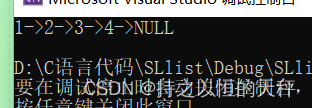
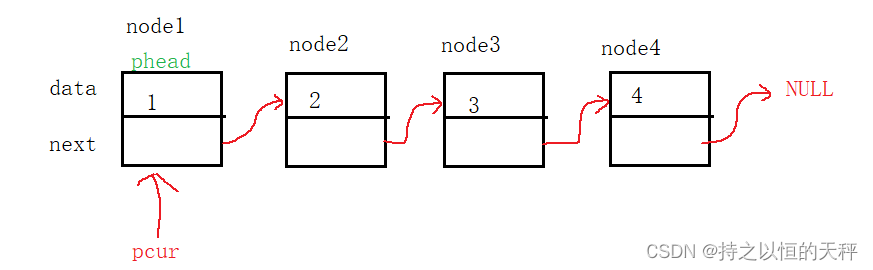
void SlistTest01() {//一般不会这样去创建链表,这里只是为了给大家展示链表的打印SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));node1->data = 1;SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));node2->data = 2;SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));node3->data = 3;SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));node4->data = 4;node1->next = node2;node2->next = node3;node3->next = node4;node4->next = NULL;SLTNode* plist = node1;SLTPrint(plist);//实参
}
2.插入数据
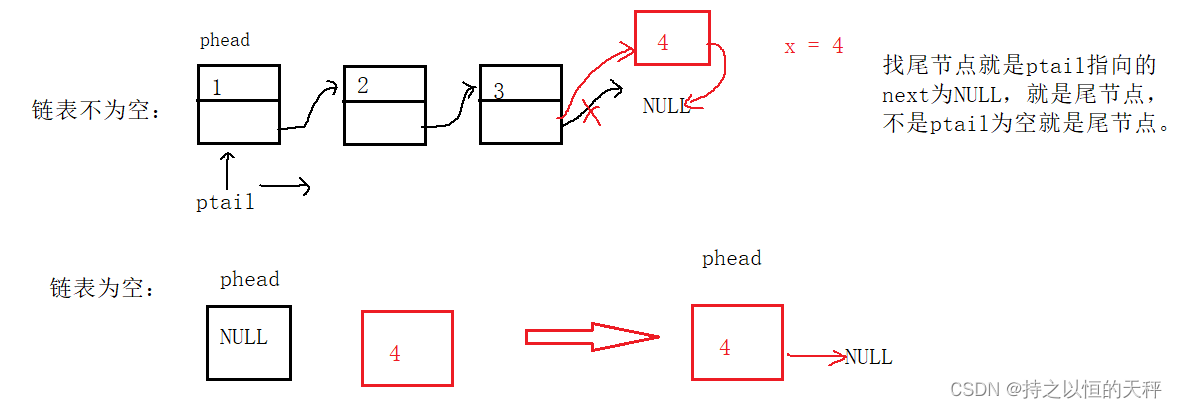
尾插:分为2种情况,链表为空和不为空,当链表为空的时候,如图所示,就是把新插入的数据的next指向NULL,然后新插入的4就作为第一个节点。当链表不为空的时候就让节点3的next指向新插入的节点4的data,然后next指向NULL。
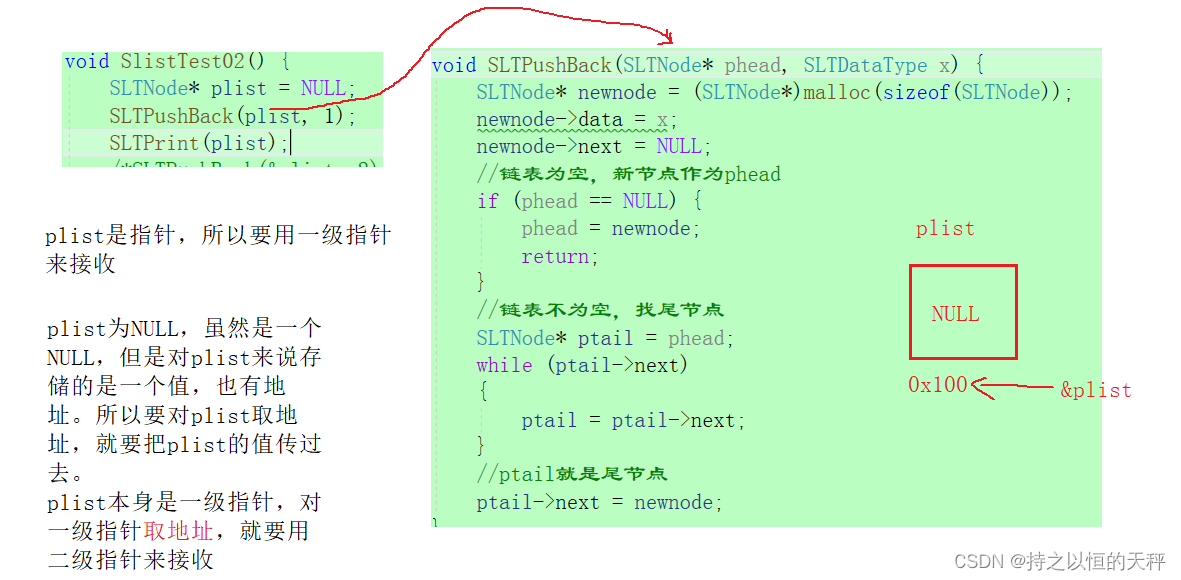
根据这个逻辑可能会有小伙伴们这样写。(我就直接画图解释,为了节省篇幅)

结果是NULL,不应该是1->NULL吗?解释如下(我可能说的不是很清楚,也不好理解,因为二级指针还没完全学懂,但是在这里的解释应该是没有问题的,厉害的小伙伴们可以自己想想看)
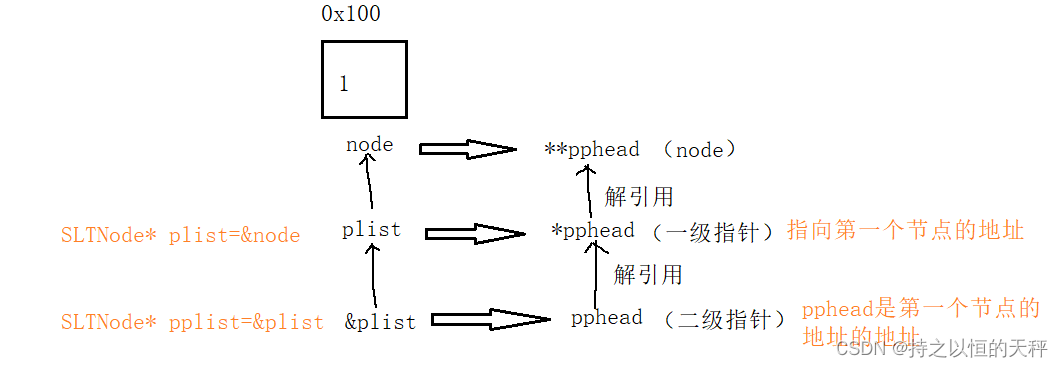
如果小伙伴们还不明白的话,可以这么理解:
OK,这么改就没有问题了,正确代码如下:
void SLTPushBack(SLTNode** pphead, SLTDataType x);
void SLTPushBack(SLTNode** pphead, SLTDataType x) {assert(pphead);//不能传空//SLTNode* newnode = SLTBuyNode(x);SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));newnode->data = x;newnode->next = NULL;//链表为空,新节点作为pheadif (*pphead == NULL) {*pphead = newnode;return;}//链表不为空,找尾节点SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}//ptail就是尾节点ptail->next = newnode;
}接下来试着测试一下
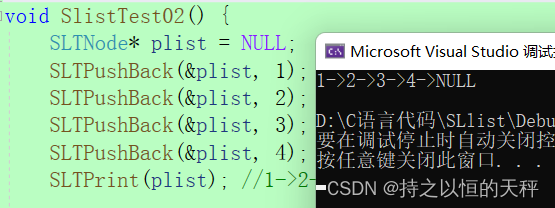
运行成功。插入操作都需要判断是否要申请新的节点,所以把申请节点写成一个函数,如下
SLTNode* SLTBuyNode(SLTDataType x) {SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL) {perror("malloc fail!");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}头插:也是2种情况,链表为空和不为空。不为空时就要把新节点的next指向phead,然后把原来第一个节点也就是phead的位置变成新节点,也就是新的头。为空的情况与尾插一样,把新节点指向phead,此时phead就是新的节点。(注意:图中是phead,与代码中不同,是因为图中的头不是pphead,只是为了方便理解,但是意思一样,具体的运行参考代码即可)
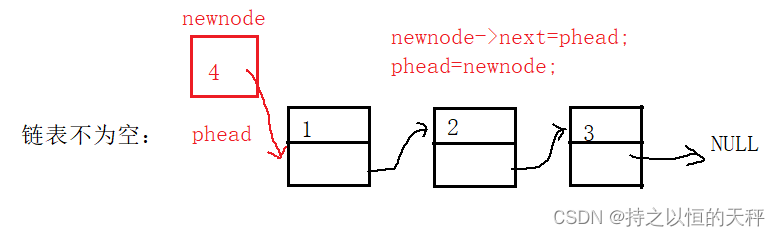
void SLTPushFront(SLTNode** pphead, SLTDataType x);
void SLTPushFront(SLTNode** pphead, SLTDataType x) {assert(pphead);SLTNode* newnode = SLTBuyNode(x);//newnode *ppheadnewnode->next = *pphead;*pphead = newnode;
}测试
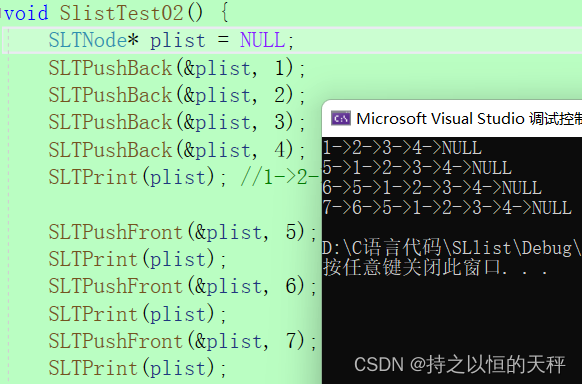
3.删除数据
尾删:当链表为空不能进行删除,不为空时分为2种情况,有多个节点和只有一个节点。
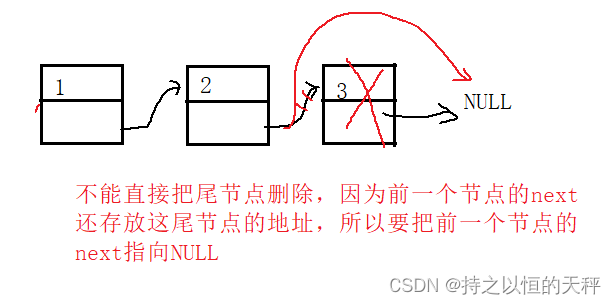
void SLTPopBack(SLTNode** pphead);
void SLTPopBack(SLTNode** pphead) {assert(pphead);//链表不能为空assert(*pphead);//链表不为空//链表只有一个节点/有多个节点if ((*pphead)->next == NULL) {free(*pphead);*pphead = NULL;return;}SLTNode* ptail = *pphead;SLTNode* prev = NULL;//prve是前驱节点while (ptail->next){prev = ptail;ptail = ptail->next;}prev->next = NULL;//销毁尾结点free(ptail);ptail = NULL;
}测试
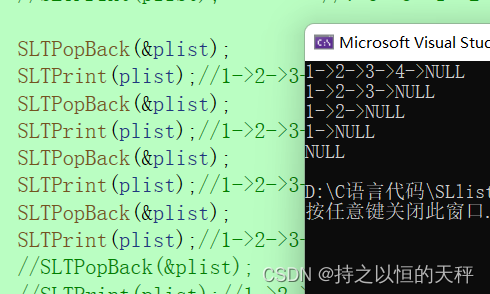
头删:先让头节点走向下一个节点,让第二个节点成为新的头节点,然后释放第一个节点
void SLTPopFront(SLTNode** pphead);
void SLTPopFront(SLTNode** pphead) {assert(pphead);//链表不能为空assert(*pphead);//让第二个节点成为新的头//把旧的头结点释放掉SLTNode* next = (*pphead)->next;free(*pphead);*pphead = next;
}测试
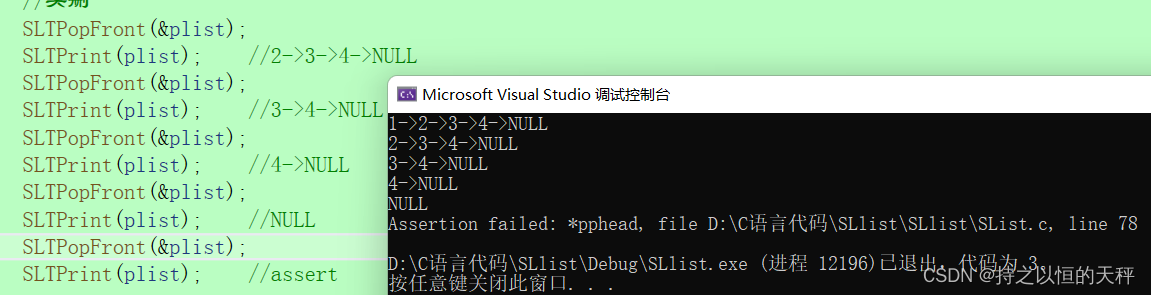
经过测试可知不能对空节点进行删除 。
4.查找数据
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x);
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x) {assert(pphead);//遍历链表SLTNode* pcur = *pphead;while (pcur) //等价于pcur != NULL{if (pcur->data == x) {return pcur;}pcur = pcur->next;}//没有找到return NULL;
}测试

5.指定位置之前插入数据
解决问题的关键就是找到pos的前驱节点prev。对prev,newnode,pos修改对应的指针连接即可。
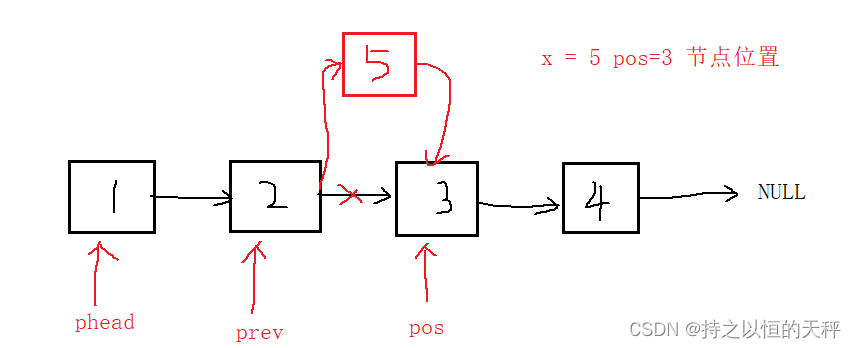
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) {assert(pphead);assert(pos);//要加上链表不能为空,因为pos是链表里的有效节点//链表如果为空,pos也为空assert(*pphead);SLTNode* newnode = SLTBuyNode(x);//pos刚好是头结点if (pos == *pphead) {//头插SLTPushFront(pphead, x);return;}//pos不是头结点的情况SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev -> newnode -> posprev->next = newnode;newnode->next = pos;
}测试

6.指定位置之后插入数据
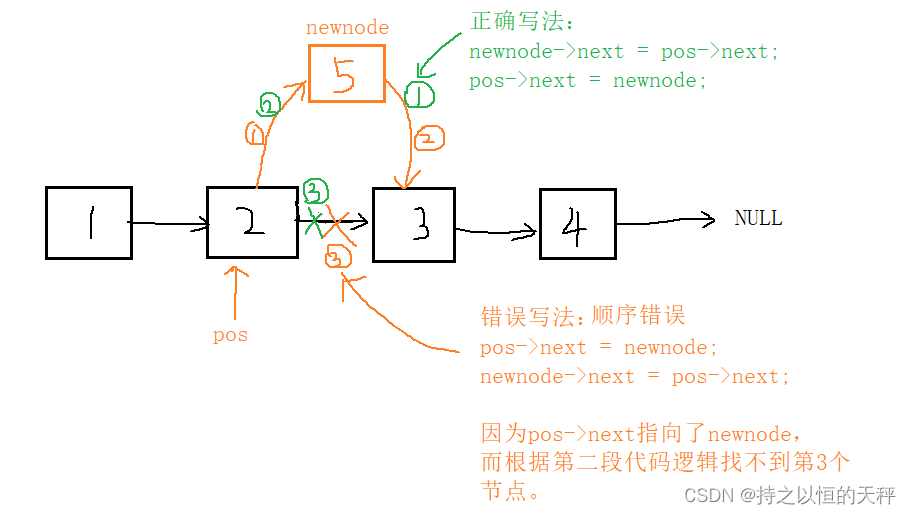
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
void SLTInsertAfter(SLTNode* pos, SLTDataType x) {assert(pos);SLTNode* newnode = SLTBuyNode(x);//pos newnode pos->nextnewnode->next = pos->next;pos->next = newnode;
}测试
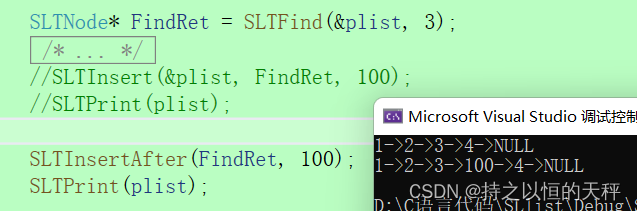
7.删除指定位置节点
void SLTErase(SLTNode** pphead, SLTNode* pos);
void SLTErase(SLTNode** pphead, SLTNode* pos) {assert(pphead);assert(*pphead);assert(pos);//pos刚好是头结点,没有前驱节点,执行头删if (*pphead == pos) {//头删SLTPopFront(pphead);return;}SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev pos pos->nextprev->next = pos->next;//先改方向,再释放节点free(pos);pos = NULL;
}测试
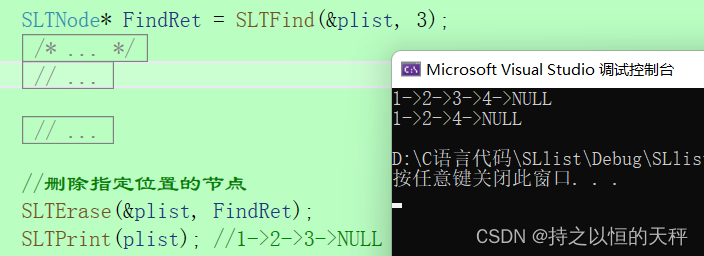
8.删除指定位置之后的节点
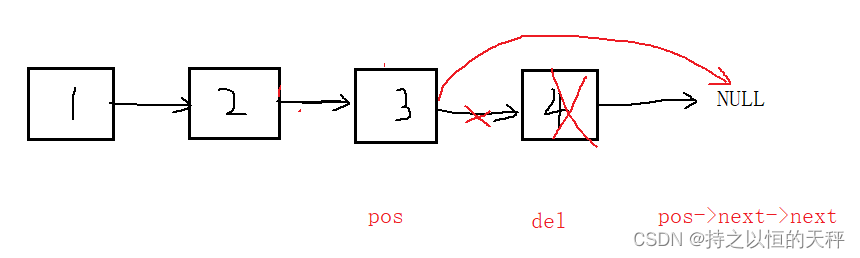
void SLTEraseAfter(SLTNode* pos);
void SLTEraseAfter(SLTNode* pos) {assert(pos);//pos->next不能为空assert(pos->next);//pos pos->next pos->next->nextSLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;
}8.销毁链表
void SListDesTroy(SLTNode** pphead);
void SListDesTroy(SLTNode** pphead) {assert(pphead);assert(*pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}OK,写到这里就是全部完成了。接下来介绍一下链表的分类
9.链表的分类
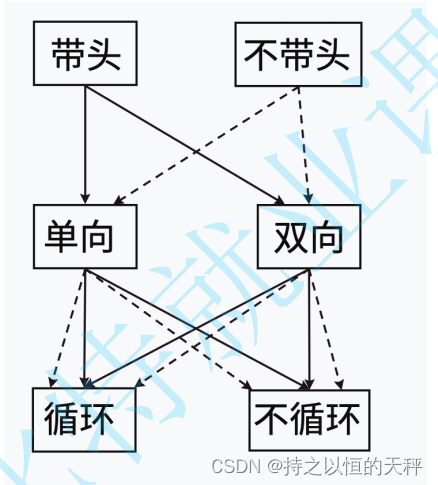
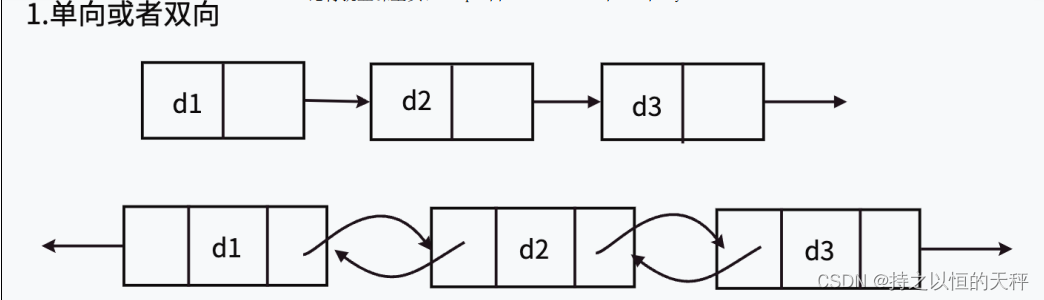
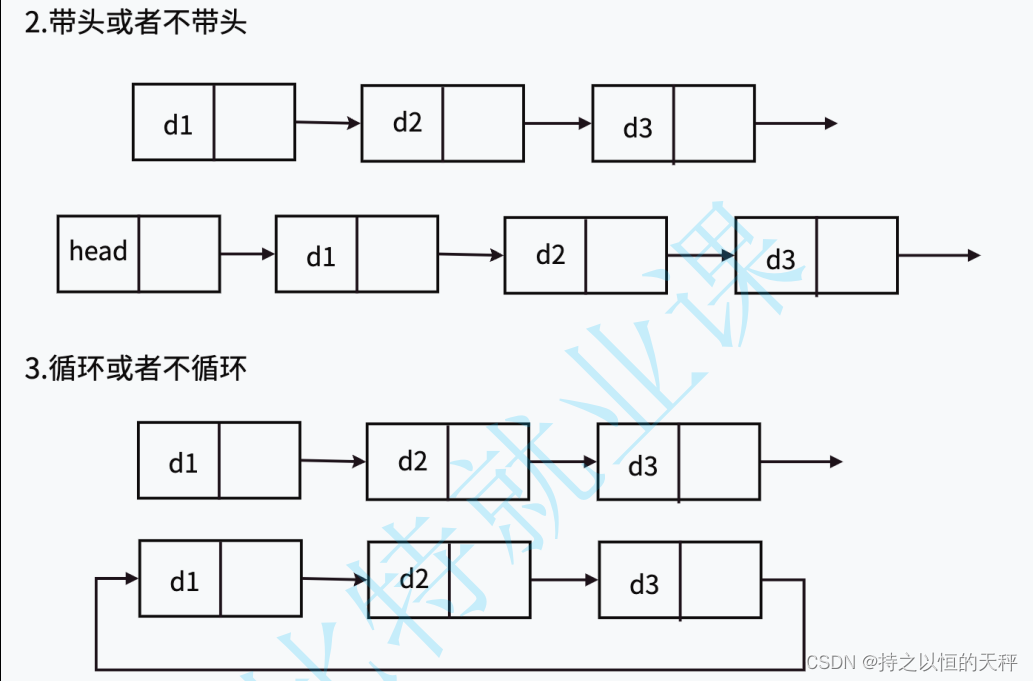



)
)



--- 组合式API之计算属性和侦听器)










——list模拟实现扩展)