感谢如此优秀的开源工作,仓库链接 Qwen-VL
权重分为 Qwen-VL && Qwen-VL-Chat,区别文档稍后介绍
训练过程
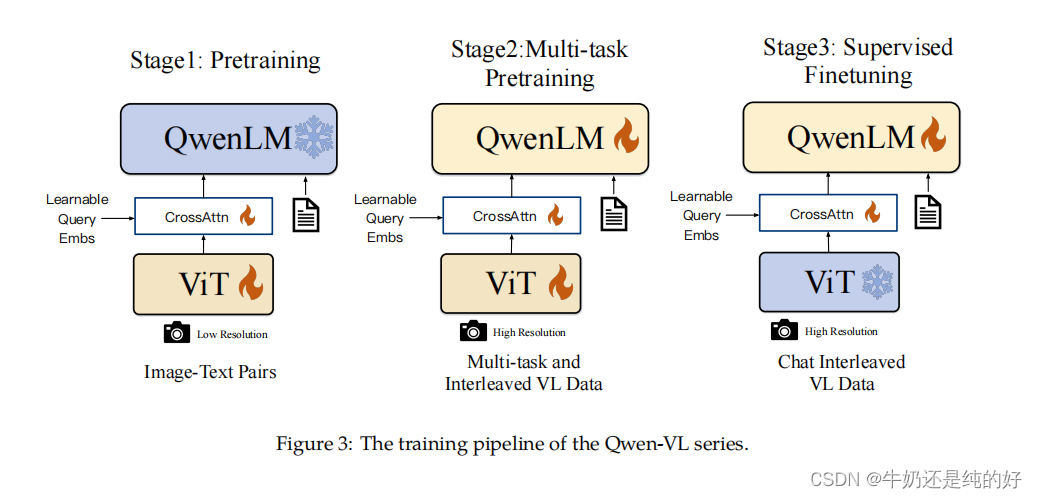
- 在第一阶段中主要使用224X224分辨率训练,训练数据主要来源是公开数据集,经过清洗,数据总量大约是1.4B,中文数据和英文j训练目标是视觉语言和文本语言对齐。使用的loss函数是交叉熵,训练过程:给定一个输入(例如图像or文本),预测整个词表中作为next token的概率(The language model, given an input (such as an image and some initial text), predicts the probability of each token in the vocabulary being the next token in the sequence.),实际标签转换为one-hot, 然后使用交叉熵损失函数计算两个的差(The actual distribution is represented by the true next token in the training data. In practice, this is often converted into a one-hot encoded vector, where the actual next token has a probability of 1, and all others have a probabil
)
)






![壹[1],Xamarin开发环境配置](http://pic.xiahunao.cn/壹[1],Xamarin开发环境配置)





:多元关系架构)




